目录
前言
题目和代码
L1-006 连续因子
L1-009 N个数求和
L2-004 这是二叉搜索树吗?
L2-006 树的遍历
L2-007 家庭房产
L4-118 均是素数
L4-203 三足鼎立
L2-002 链表去重
L2-003 月饼
L2-026 小字辈
L4-201 出栈序列的合法性
L4-205 浪漫侧影
前言
所有题目的代码都放在GitHub这个仓库https://github.com/zczjyq/zjou2024-.git里面了。
题目和代码
L1-006 连续因子
一个正整数 N 的因子中可能存在若干连续的数字。例如 630 可以分解为 3×5×6×7,其中 5、6、7 就是 3 个连续的数字。给定任一正整数 N,要求编写程序求出最长连续因子的个数,并输出最小的连续因子序列。
输入格式:
输入在一行中给出一个正整数 N(1<N<231)。
输出格式:
首先在第 1 行输出最长连续因子的个数;然后在第 2 行中按 因子1*因子2*……*因子k 的格式输出最小的连续因子序列,其中因子按递增顺序输出,1 不算在内。
输入样例:
630输出样例:
3
5*6*7
代码:
#include <iostream>
#include <cmath>
using namespace std;
int main() {
int n; // 要检查的数字
int start = 0; // 最长序列的起始数字
int maxLen = 0; // 最长序列的长度
int len; // 当前序列的长度
int current; // 当前的除数
int modifiedN; // 被修改后用于计算的n
cin >> n;
// 遍历所有可能的起始数字,这边只能用sqrt 或者 i < n / i, 用i * i < n 会超时
for (int i = 2; i < sqrt(n); i++) {
len = 0;
current = i;
modifiedN = n;
// 检查从i开始的连续整数是否能整除modifiedN
while (modifiedN % current == 0) {
len++;
modifiedN /= current;
current++;
}
// 更新找到的最长序列
if (len > maxLen) {
maxLen = len;
start = i;
}
}
// 如果没有找到任何可以整除n的连续整数序列
if (start == 0) {
start = n; // 序列就是n本身
maxLen = 1; // 长度为1
}
// 输出最长序列的长度
cout << maxLen << endl;
// 输出序列本身
for (int i = start, count = 1; count <= maxLen; i++, count++) {
if (count > 1) cout << "*";
cout << i;
}
}
整活代码:
#include<iostream>
int n,s,l,_,m,j;
int main(){std::cin>>n;for(int i=2;i<n/i;i++)
{l=0,j=i,_=n;while(_%j==0)l++,_/=j++;if(l>m)m=l,s=i;}
if(!s)s=n,m=1;_=1;std::cout<<m<<'\n'<<s;
for(int i=s+1;_<m;i++,_++)std::cout<<"*"<<i;}L1-009 N个数求和
本题的要求很简单,就是求N个数字的和。麻烦的是,这些数字是以有理数分子/分母的形式给出的,你输出的和也必须是有理数的形式。
输入格式:
输入第一行给出一个正整数N(≤100)。随后一行按格式a1/b1 a2/b2 ...给出N个有理数。题目保证所有分子和分母都在长整型范围内。另外,负数的符号一定出现在分子前面。
输出格式:
输出上述数字和的最简形式 —— 即将结果写成整数部分 分数部分,其中分数部分写成分子/分母,要求分子小于分母,且它们没有公因子。如果结果的整数部分为0,则只输出分数部分。
输入样例1:
5
2/5 4/15 1/30 -2/60 8/3
输出样例1:
3 1/3
输入样例2:
2
4/3 2/3
输出样例2:
2
输入样例3:
3
1/3 -1/6 1/8
输出样例3:
7/24代码:
#include <iostream>
#include <cstdio>
using namespace std;
// 定义一个求最大公约数的函数,使用递归方法
int gcd(int a, int b) {
return b ? gcd(b, a % b) : a;
}
int main() {
int n, fz_ans = 0, fm_ans = 1; // 初始化分子fz_ans为0,分母fm_ans为1,这是因为开始时没有任何分数相加
scanf("%d", &n); // 输入分数的个数
for (int i = 0; i < n; i++) {
int fz, fm;
scanf("%d/%d", &fz, &fm); // 输入每个分数的分子和分母
fz_ans = fz_ans * fm + fz * fm_ans; // 交叉相乘并相加,处理分数的加法
fm_ans = fm_ans * fm; // 分母相乘
int num = gcd(fz_ans, fm_ans); // 计算当前结果的最大公约数以简化分数
fz_ans /= num; // 简化分子
fm_ans /= num; // 简化分母
}
if (fm_ans == 1) {
printf("%d", fz_ans); // 如果分母为1,则只输出分子(整数)
} else if (fz_ans > fm_ans) {
printf("%d %d/%d", fz_ans / fm_ans, fz_ans % fm_ans, fm_ans); // 如果分子大于分母,输出带分数
} else {
printf("%d/%d", fz_ans, fm_ans); // 否则,输出真分数
}
return 0;
}
整活:
#include<iostream>
int n,z,y=1,x,m,_;
int gcd(int a,int b){return b?gcd(b,a%b):a;}
int main(){std::cin>>n;for(int i=0;i<n;i++)
scanf("%d/%d",&x,&m),z=z*m+x*y,y*=m,_=gcd(z,y),z/=_,y/=_;
if(y==1)std::cout<<z;else if(z>y)printf("%d %d/%d",z/y,z%y,y);
else printf("%d/%d",z,y);}
L2-004 这是二叉搜索树吗?
一棵二叉搜索树可被递归地定义为具有下列性质的二叉树:对于任一结点,
- 其左子树中所有结点的键值小于该结点的键值;
- 其右子树中所有结点的键值大于等于该结点的键值;
- 其左右子树都是二叉搜索树。
所谓二叉搜索树的“镜像”,即将所有结点的左右子树对换位置后所得到的树。
给定一个整数键值序列,现请你编写程序,判断这是否是对一棵二叉搜索树或其镜像进行前序遍历的结果。
输入格式:
输入的第一行给出正整数 N(≤1000)。随后一行给出 N 个整数键值,其间以空格分隔。
输出格式:
如果输入序列是对一棵二叉搜索树或其镜像进行前序遍历的结果,则首先在一行中输出 YES ,然后在下一行输出该树后序遍历的结果。数字间有 1 个空格,一行的首尾不得有多余空格。若答案是否,则输出 NO。
输入样例 1:
7
8 6 5 7 10 8 11
输出样例 1:
YES
5 7 6 8 11 10 8
输入样例 2:
7
8 10 11 8 6 7 5
输出样例 2:
YES
11 8 10 7 5 6 8
输入样例 3:
7
8 6 8 5 10 9 11
输出样例 3:
NO代码:
#include <iostream>
#include <vector>
using namespace std;
int n, flag;
int nums[1010];
vector <int> v;
void find(int l, int r) {
if (l > r) return ;
int tr = r, tl = l + 1;
if (!flag) {
while (tl <= r && nums[tl] < nums[l]) tl ++ ;
while (tr > l && nums[tr] >= nums[l]) tr -- ;
} else {
while (tl <= r && nums[tl] >= nums[l]) tl ++ ;
while (tr > l && nums[tr] < nums[l]) tr -- ;
}
if (tl - tr != 1) return;
find(l + 1, tr); find(tl, r);
v.push_back(nums[l]);
}
int main() {
cin >> n;
for (int i = 0; i < n; i ++ ) cin >> nums[i];
find(0, n - 1);
if (v.size() != n) {
flag = 1;
v.clear();
find(0, n - 1);
}
if (v.size() != n) cout << "NO";
else {
cout << "YES\n" << v.front();
for (int i = 1; i < v.size(); i ++ ) cout << " " << v[i];
}
}L2-006 树的遍历
给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列。这里假设键值都是互不相等的正整数。
输入格式:
输入第一行给出一个正整数N(≤30),是二叉树中结点的个数。第二行给出其后序遍历序列。第三行给出其中序遍历序列。数字间以空格分隔。
输出格式:
在一行中输出该树的层序遍历的序列。数字间以1个空格分隔,行首尾不得有多余空格。
输入样例:
7
2 3 1 5 7 6 4
1 2 3 4 5 6 7
输出样例:
4 1 6 3 5 7 2代码
#include <iostream>
using namespace std;
const int N = 3500;
int n;
int back[N], mid[N];
int res[N][N];
void build(int b_l, int b_r, int m_l, int m_r, int deep) {
if (b_l > b_r) return;
int pos = m_l, root = back[b_r];
res[deep][++res[deep][0]] = root;
while (mid[pos] != root) pos ++ ;
build(b_l, b_l + pos - 1 - m_l, m_l, pos - 1,deep + 1);
build(b_l + pos - m_l, b_r - 1, pos + 1, m_r, deep + 1);
}
int main () {
cin >> n;
for (int i = 1; i <= n; i ++ ) cin >> back[i];
for (int i = 1; i <= n; i ++ ) cin >> mid[i];
build(1, n, 1, n, 0);
for (int i = 0; res[i][0] != 0; i ++ ) {
for (int j = 1; j <= res[i][0]; j ++ ) {
if (i == 0) cout << res[i][j];
else cout << ' ' << res[i][j];
}
}
}整活:
#include<iostream>
#define I int
#define f(_)for(I i=1;i<=_;i++)
I n,b[35],m[35],r[35][35];
void y(I o,I _,I h,I A,I d){if(o>_)return;I p=h;r[d][++r[d][0]]=b[_];while(m[p]!=b[_])p++;
y(o,o+p-1-h,h,p-1,d+1);y(o+p-h,_-1,p+1,A,d+1);}
int main(){std::cin>>n;f(n)std::cin>>b[i];f(n)std::cin>>m[i];y(1,n,1,n,0);
for(I z=0;r[z][0];z++)f(r[z][0])std::cout<<(!z?"":" ")<<r[z][i];}L2-007 家庭房产
给定每个人的家庭成员和其自己名下的房产,请你统计出每个家庭的人口数、人均房产面积及房产套数。
输入格式:
输入第一行给出一个正整数N(≤1000),随后N行,每行按下列格式给出一个人的房产:
编号 父 母 k 孩子1 ... 孩子k 房产套数 总面积
其中编号是每个人独有的一个4位数的编号;父和母分别是该编号对应的这个人的父母的编号(如果已经过世,则显示-1);k(0≤k≤5)是该人的子女的个数;孩子i是其子女的编号。
输出格式:
首先在第一行输出家庭个数(所有有亲属关系的人都属于同一个家庭)。随后按下列格式输出每个家庭的信息:
家庭成员的最小编号 家庭人口数 人均房产套数 人均房产面积
其中人均值要求保留小数点后3位。家庭信息首先按人均面积降序输出,若有并列,则按成员编号的升序输出。
输入样例:
10
6666 5551 5552 1 7777 1 100
1234 5678 9012 1 0002 2 300
8888 -1 -1 0 1 1000
2468 0001 0004 1 2222 1 500
7777 6666 -1 0 2 300
3721 -1 -1 1 2333 2 150
9012 -1 -1 3 1236 1235 1234 1 100
1235 5678 9012 0 1 50
2222 1236 2468 2 6661 6662 1 300
2333 -1 3721 3 6661 6662 6663 1 100
输出样例:
3
8888 1 1.000 1000.000
0001 15 0.600 100.000
5551 4 0.750 100.000代码:
#include <iostream>
#include <algorithm>
#include <set>
using namespace std;
set<int> s;
struct node{
int num_house, area;
} nodes[20010];
struct ans{
int num = 100000, all_people, all_ho, all_area;
double num_h, area;
}res[10010];
int n, cnt, p[10010], st_a[10010], st_num[10010];
int find(int u) {
if (p[u] != u) p[u] = find(p[u]);
return p[u];
}
int main() {
cin >> n;
for (int i = 0; i < 10010; i ++ ) p[i] = i;
for (int i = 0; i < n; i ++ ) {
int num, f, m, k;
cin >> num >> f >> m >> k;
s.insert(num);
int a = find(num);
for (int j = 0; j < k; j ++ ) {
int c;
cin >> c;
if (c >= 0){
p[find(c)] = a;
s.insert(c);
}
}
if (f >= 0) p[find(f)] = a, s.insert(f);
if (m >= 0) p[find(m)] = a, s.insert(m);
cin >> nodes[num].num_house >> nodes[num].area;
}
for (auto t : s) {
int a = find(t);
if (!st_a[a]) {
st_a[a] = 1;
st_num[a] = cnt++;
}
res[st_num[a]].num = min(res[st_num[a]].num, t);
res[st_num[a]].all_area += nodes[t].area;
res[st_num[a]].all_people += 1;
res[st_num[a]].all_ho += nodes[t].num_house;
}
for (int i = 0; i < cnt; i ++ ) {
res[i].num_h = (double)res[i].all_ho / (double)res[i].all_people;
res[i].area = (double)res[i].all_area / (double)res[i].all_people;
}
sort(res, res + cnt, [](ans a, ans b) {
if (a.area == b.area) return a.num < b.num;
return a.area > b.area;
});
cout << cnt << endl;
for (int i = 0; i < cnt; i ++ ) printf("%04d %d %.3lf %.3lf\n", res[i].num, res[i].all_people, res[i].num_h, res[i].area);
}L4-118 均是素数
在给定的区间 [m,n] 内,是否存在素数 p、q、r(p<q<r),使得 pq+r、qr+p、rp+q 均是素数?
输入格式:
输入给出区间的两个端点 0<m<n≤1000,其间以空格分隔。
输出格式:
在一行中输出满足条件的素数三元组的个数。
输入样例:
1 35
输出样例:
10
样例解读
满足条件的 10 组解为:
2, 3, 5
2, 3, 7
2, 3, 13
2, 3, 17
2, 5, 7
2, 5, 13
2, 5, 19
2, 5, 31
2, 7, 23
2, 13, 17代码:
线性筛
#include <iostream>
#include <unordered_map>
using namespace std;
const int N = 1e5 + 10;
int m, n;
int primes[N], cnt, res;
bool st[N];
unordered_map<int , bool> h;
void get_primes(int n) {
for (int i = 2; i <= n; i ++ ) {
if (!st[i]) {
primes[cnt ++ ] = i;
h[i] = true;
}
for (int j = 0; n / primes[j] > i; j ++ ) {
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
bool check(int a, int b, int c) {
return h[a * b + c] && h[a + b * c] && h[a * c + b];
}
int main() {
cin >> n >> m;
get_primes(N - 1);
int start = 0;
while (primes[start] < n, start ++ );
for (int i = start; primes[i] <= m; i ++ ) {
for (int j = i + 1; primes[j] <= m; j++ ) {
for (int k = j + 1; primes[k] <= m; k ++ ) {
if (check(primes[i], primes[j], primes[k])) {
res ++ ;
}
}
}
}
cout << res;
}朴素法:
#include <iostream>
#include <unordered_map>
using namespace std;
const int N = 1e6 + 10;
int m, n;
int primes[N], cnt, res;
bool st[N];
unordered_map<int , bool> h; // 用于判断当前的数是不是质数
// 刷选指数
void get_primes(int n) {
for (int i = 2; i <= n; i ++ ) {
int flag = 1;
for (int j = 0; j < cnt && primes[j] <= i / primes[j]; j ++ ) {
if (i % primes[j] == 0) {flag = 0; break;}
}
if (flag) primes[cnt ++ ] = i, h[i] = true;
}
}
// 判断当前的rqp是否满足
bool check(int a, int b, int c) {
return h[a * b + c] && h[a + b * c] && h[a * c + b];
}
int main() {
cin >> n >> m;
get_primes(N - 1);
int start = 0;
while (primes[start] < n) start ++ ;
for (int i = start; primes[i] <= m; i ++ ) {
for (int j = i + 1; primes[j] <= m; j++ ) {
for (int k = j + 1; primes[k] <= m; k ++ ) {
if (check(primes[i], primes[j], primes[k])) {
res ++ ;
}
}
}
}
cout << res;
}整活:
#include<iostream>
#define f(_,n)for(int _=n;p[_]<=m;_++)
const int N = 1e6 + 10;
int m,n,p[N],c,r,t[N],f,s;
int main(){std::cin>>n>>m;for(int i=2;i<N;i++){f=1;
for(int j=0;j<c&&p[j]<=i/p[j];j++)if(i%p[j]==0){f=0;break;}
if(f)p[c++]=i,t[i]=true;}while(p[s]<n)s++;
f(i,s)f(j,i+1)f(k,j+1)if(t[p[i]*p[j]+p[k]]&&t[p[i]+p[j]*p[k]]&&t[p[i]*p[k]+p[j]])r++;
std::cout<<r;}L4-203 三足鼎立
当三个国家中的任何两国实力之和都大于第三国的时候,这三个国家互相结盟就呈“三足鼎立”之势,这种状态是最稳定的。
现已知本国的实力值,又给出 n 个其他国家的实力值。我们需要从这 n 个国家中找 2 个结盟,以成三足鼎立。有多少种选择呢?
输入格式:
输入首先在第一行给出 2 个正整数 n(2≤n≤105)和 P(≤109),分别为其他国家的个数、以及本国的实力值。随后一行给出 n 个正整数,表示n 个其他国家的实力值。每个数值不超过 109,数字间以空格分隔。
输出格式:
在一行中输出本国结盟选择的个数。
输入样例:
7 30
42 16 2 51 92 27 35
输出样例:
9
样例解释:
能联合的另外 2 个国家的 9 种选择分别为:
{16, 27}, {16, 35}, {16, 42}, {27, 35}, {27, 42}, {27, 51}, {35, 42}, {35, 51}, {42, 51}。
代码:
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long ll; // 使用long long类型以支持大整数处理
ll n, p, res; // n表示其他国家的数量,p是本国的实力值,res用于统计有效的结盟组合数量
ll nums[200010]; // 数组存储其他国家的实力值,注意数组大小是根据问题约束设定的
int main() {
// 输入处理
cin >> n >> p; // 读入国家数量和本国的实力值
for (int i = 0; i < n; i++) cin >> nums[i]; // 读入其他国家的实力值到数组中
// 对其他国家的实力值进行排序,以便高效地进行范围查询
sort(nums, nums + n);
for (int i = 0; i < n; i++) {
// 'l' 是第一个使得nums[i]和nums[l]之和不能击败本国的索引位置
int l = upper_bound(nums + i + 1, nums + n, p - nums[i]) - nums;
// 'r' 是第一个使得nums[i]和nums[r]之和可以击败本国的索引位置
int r = lower_bound(nums + i + 1, nums + n, p + nums[i]) - nums;
res += (r - l);
}
// 输出最终的结果
cout << res;
}
整活
#include<iostream>
#include<algorithm>
#define f for(int i=0;i<n;i++)
using namespace std;
long long n,p,r,s[200010];
int main(){cin>>n>>p;
f cin>>s[i];sort(s,s+n);f r+=(lower_bound(s+i+1,s+n,p+s[i])-upper_bound(s+i+1,s+n,p-s[i]));cout<<r;}L2-002 链表去重
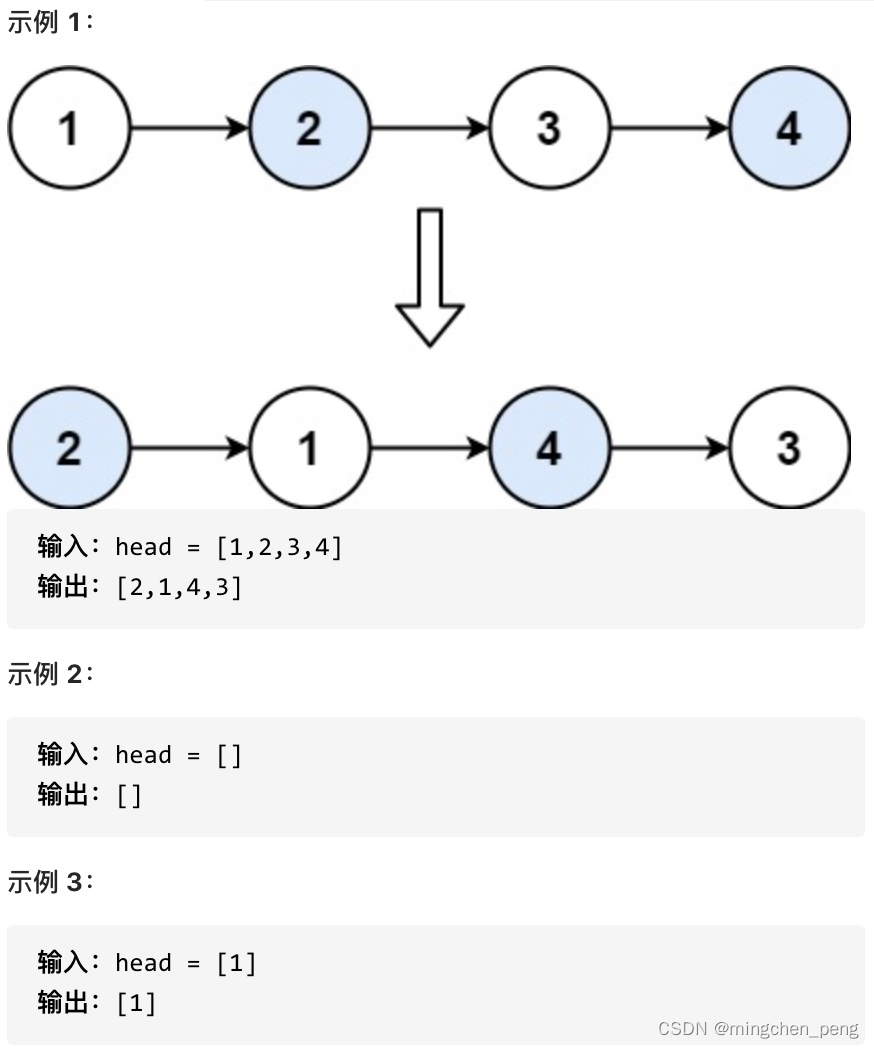
给定一个带整数键值的链表 L,你需要把其中绝对值重复的键值结点删掉。即对每个键值 K,只有第一个绝对值等于 K 的结点被保留。同时,所有被删除的结点须被保存在另一个链表上。例如给定 L 为 21→-15→-15→-7→15,你需要输出去重后的链表 21→-15→-7,还有被删除的链表 -15→15。
输入格式:
输入在第一行给出 L 的第一个结点的地址和一个正整数 N(≤105,为结点总数)。一个结点的地址是非负的 5 位整数,空地址 NULL 用 -1 来表示。
随后 N 行,每行按以下格式描述一个结点:
地址 键值 下一个结点
其中地址是该结点的地址,键值是绝对值不超过104的整数,下一个结点是下个结点的地址。
输出格式:
首先输出去重后的链表,然后输出被删除的链表。每个结点占一行,按输入的格式输出。
输入样例:
00100 5
99999 -7 87654
23854 -15 00000
87654 15 -1
00000 -15 99999
00100 21 23854
输出样例:
00100 21 23854
23854 -15 99999
99999 -7 -1
00000 -15 87654
87654 15 -1代码:
#include <iostream>
#include <unordered_map>
using namespace std;
const int N = 1e5 + 10;
unordered_map<int, int> dedup_hash;
unordered_map<string, int>h;
string head;
int n;
struct node {
string head, end;
int num;
}nodes[N], dedup[N], del[N];
int main() {
cin >> head >> n;
for (int i = 0; i < n; i ++ ) {
cin >> nodes[i].head >> nodes[i].num >> nodes[i].end;
h[nodes[i].head] = i;
}
string l = head, r = "-1";
int l_cnt = 0, r_cnt = 0;
int root = h[head];
while(1) {
if (!dedup_hash[abs(nodes[root].num)]) {
dedup_hash[abs(nodes[root].num)] = 1;
if (l_cnt != 0) dedup[l_cnt - 1].end = nodes[root].head;
dedup[l_cnt].head = nodes[root].head;
dedup[l_cnt].num = nodes[root].num;
// dedup[l_cnt].end = "-1";
l_cnt ++ ;
}
else {
if (r_cnt != 0) del[r_cnt - 1].end = nodes[root].head;
del[r_cnt].head = nodes[root].head;
del[r_cnt].num = nodes[root].num;
r_cnt ++ ;
}
if (nodes[root].end == "-1") break;
root = h[nodes[root].end];
}
for (int i = 0; i < l_cnt; i ++ ) {
if (i == l_cnt - 1) cout << dedup[i].head << ' ' << dedup[i].num << ' ' << "-1" << endl;
else cout << dedup[i].head << ' ' << dedup[i].num << ' ' << dedup[i].end << endl;
}
for (int i = 0; i < r_cnt; i ++ ) {
if (i == r_cnt - 1) cout << del[i].head << ' ' << del[i].num << ' ' << "-1" << endl;
else cout << del[i].head << ' ' << del[i].num << ' ' << del[i].end << endl;
}
}L2-003 月饼
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入格式:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
输出格式:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
输入样例:
3 20
18 15 10
75 72 45
输出样例:
94.50
代码:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1010;
int n;
double v, res;
struct node {
double v, w, p;
}nodes[N];
int main() {
cin >> n >> v;
for (int i = 0; i < n; i ++ ) cin >> nodes[i].v;
for (int i = 0; i < n; i ++ ) cin >> nodes[i].w;
for (int i = 0; i < n; i ++ ) nodes[i].p = nodes[i].w / double(nodes[i].v);
sort(nodes, nodes + n, [](node a, node b){
return a.p > b.p;
});
int idx = 0;
while (v && idx < n) {
if (v >= nodes[idx].v) {
v -= nodes[idx].v;
res += nodes[idx].w;
} else {
res += nodes[idx].p * v;
break;
}
idx ++ ;
}
printf("%.2lf", res);
}L2-026 小字辈
本题给定一个庞大家族的家谱,要请你给出最小一辈的名单。
输入格式:
输入在第一行给出家族人口总数 N(不超过 100 000 的正整数) —— 简单起见,我们把家族成员从 1 到 N 编号。随后第二行给出 N 个编号,其中第 i 个编号对应第 i 位成员的父/母。家谱中辈分最高的老祖宗对应的父/母编号为 -1。一行中的数字间以空格分隔。
输出格式:
首先输出最小的辈分(老祖宗的辈分为 1,以下逐级递增)。然后在第二行按递增顺序输出辈分最小的成员的编号。编号间以一个空格分隔,行首尾不得有多余空格。
输入样例:
9
2 6 5 5 -1 5 6 4 7
输出样例:
4
1 9代码:
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int n, nums[N], deep[N], max_deep = 1;
int dfs(int u) {
if (deep[u]) return deep[u];
deep[u] = dfs(nums[u]) + 1;
max_deep = max(max_deep, deep[u]);
return deep[u];
}
int main() {
cin >> n;
for (int i = 1; i <= n; i ++ ) {
cin >> nums[i];
if (nums[i] == -1) deep[i] = 1;
}
for (int i = 1; i <= n; i ++ )
if (!deep[i])
dfs(i);
cout << max_deep << endl;
bool flag = true;
for (int i = 1; i <= n; i ++ ) {
if (max_deep == deep[i]){
if (flag) cout << i;
else cout << ' ' << i;
flag = false;
}
}
}整活:
#include<iostream>
#define I int
#define f for(I i=1;i<=n;i++)
I n,m[100010],d[100010],_=1,g;
I D(I u){if(d[u])return d[u];d[u]=D(m[u])+1;_=std::max(_,d[u]);return d[u];}
I main(){std::cin>>n;f{std::cin>>m[i];if(m[i]==-1)d[i]=1;}
f if(!d[i])D(i);std::cout<<_<<'\n';f if(_==d[i])std::cout<<(g?" ":"")<<i,g = 1;}L4-201 出栈序列的合法性
给定一个最大容量为 m 的堆栈,将 n 个数字按 1, 2, 3, ..., n 的顺序入栈,允许按任何顺序出栈,则哪些数字序列是不可能得到的?例如给定 m=5、n=7,则我们有可能得到{ 1, 2, 3, 4, 5, 6, 7 },但不可能得到{ 3, 2, 1, 7, 5, 6, 4 }。
输入格式:
输入第一行给出 3 个不超过 1000 的正整数:m(堆栈最大容量)、n(入栈元素个数)、k(待检查的出栈序列个数)。最后 k 行,每行给出 n 个数字的出栈序列。所有同行数字以空格间隔。
输出格式:
对每一行出栈序列,如果其的确是有可能得到的合法序列,就在一行中输出YES,否则输出NO。
输入样例:
5 7 5
1 2 3 4 5 6 7
3 2 1 7 5 6 4
7 6 5 4 3 2 1
5 6 4 3 7 2 1
1 7 6 5 4 3 2
输出样例:
YES
NO
NO
YES
NO代码:
#include <iostream>
using namespace std;
int m, n, k; // 定义全局变量m, n, k,分别表示栈的最大容量,序列长度和测试用例数量
// 检查函数,用来检验是否能通过栈操作得到特定的输出序列
void check() {
int hh = -1; // 栈顶指针(栈顶元素的索引)
int cnt = 1; // 下一个将要推入栈的数字
int s[1010]; // 用于存储数字的栈
int nums[1010]; // 用来存储输入序列的数组
// 输入序列的数字
for (int i = 0; i < n; i++) {
cin >> nums[i];
}
// 处理输入序列中的每个数字
for (int i = 0; i < n; i++) {
int x = nums[i];
// 如果栈为空或当前数字大于等于计数器
if (hh == -1 || x >= cnt) {
// 将数字推入栈,直到达到当前数字
while (x >= cnt) {
s[++hh] = cnt++;
}
// 检查栈大小是否超过最大允许大小
if (hh + 1 > m) {
puts("NO");
return;
}
} else if (s[hh] != x) { // 如果栈顶数字与当前数字不匹配
puts("NO");
return;
}
// 从栈中弹出顶部元素
hh--;
}
// 如果所有数字都按规则处理完毕,输出"YES"
puts("YES");
}
int main() {
// 读入m, n, k的值
cin >> m >> n >> k;
整活:
#include<iostream>
#define R return
#define F for(int i=0;i<n;i++)
int m,n,k;bool C(){int h=-1,c=1,s[1010],v[1010],x;F std::cin>>v[i];F{x=v[i];
if(!h||x>=c){while(x>=c)s[++h]=c++;if(h+1>m)R 0;}else if(s[h]!=x)R 0;h --;}R 1;}
int main(){std::cin>>m>>n>>k;while(k--)puts(C()?"YES":"NO");}L4-205 浪漫侧影

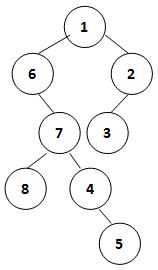
“侧影”就是从左侧或者右侧去观察物体所看到的内容。例如上图中男生的侧影是从他右侧看过去的样子,叫“右视图”;女生的侧影是从她左侧看过去的样子,叫“左视图”。
520 这个日子还在打比赛的你,也就抱着一棵二叉树左看看右看看了……
我们将二叉树的“侧影”定义为从一侧能看到的所有结点从上到下形成的序列。例如下图这棵二叉树,其右视图就是 { 1, 2, 3, 4, 5 },左视图就是 { 1, 6, 7, 8, 5 }。
于是让我们首先通过一棵二叉树的中序遍历序列和后序遍历序列构建出一棵树,然后你要输出这棵树的左视图和右视图。
输入格式:
输入第一行给出一个正整数 N (≤20),为树中的结点个数。随后在两行中先后给出树的中序遍历和后序遍历序列。树中所有键值都不相同,其数值大小无关紧要,都不超过 int 的范围。
输出格式:
第一行输出右视图,第二行输出左视图,格式如样例所示。
输入样例:
8
6 8 7 4 5 1 3 2
8 5 4 7 6 3 2 1
输出样例:
R: 1 2 3 4 5
L: 1 6 7 8 5
思路:
本题思路就是先按照中序以及后序遍历去建树,然后进行层序遍历。
代码:
C++代码:
#include <iostream>
#include <queue>
using namespace std;
const int N = 25;
int n, cnt, inorder[N], postorder[N], deep;
int res[N][N];
queue <int> q;
struct node {
int value, l = -1, r = -1;
}nodes[N];
int build(int inorder_l, int inorder_r, int postorder_l, int postorder_r) {
if (inorder_l > inorder_r) return -1; // 如果没有节点,则返回 -1
// 获取后序遍历的最后一个节点,也将是根节点
int root = postorder[postorder_r], idx = cnt ++ ;
nodes[idx].value = root;
int pos = inorder_l;
// 获取中序遍历,根节点所在位置
while (inorder[pos] != root) pos++;
// 构建左子树
nodes[idx].l = build(inorder_l, pos - 1, postorder_l, postorder_l + (pos - 1 - inorder_l));
// 构建右子树
nodes[idx].r = build(pos + 1, inorder_r, postorder_l + pos - inorder_l, postorder_r - 1);
return idx;
}
int main() {
// 输入
cin >> n;
for (int i = 1; i <= n; i ++ ) cin >> inorder[i];
for (int i = 1; i <= n; i ++ ) cin >> postorder[i];
// 建树
build(1, n, 1, n);
// 层序遍历
q.push(0);
while (!q.empty()) {
// 根据当前这层的数量来循环
for (int i = q.size(); i > 0; i -- ) {
int j = q.front(); q.pop();
// 每层的结果按照从左到右储存到res里面
res[deep][ ++ res[deep][0]] = nodes[j].value;
if (nodes[j].l != -1) q.push(nodes[j].l);
if (nodes[j].r != -1) q.push(nodes[j].r);
}
// 加深深度
deep ++ ;
}
// 格式化输出
cout << "R:";
for (int i = 0; i < deep; i ++ ) cout << ' ' << res[i][res[i][0]];
cout << endl << "L:";
for (int i = 0; i < deep; i ++ ) cout << ' ' << res[i][1];
cout << endl;
}