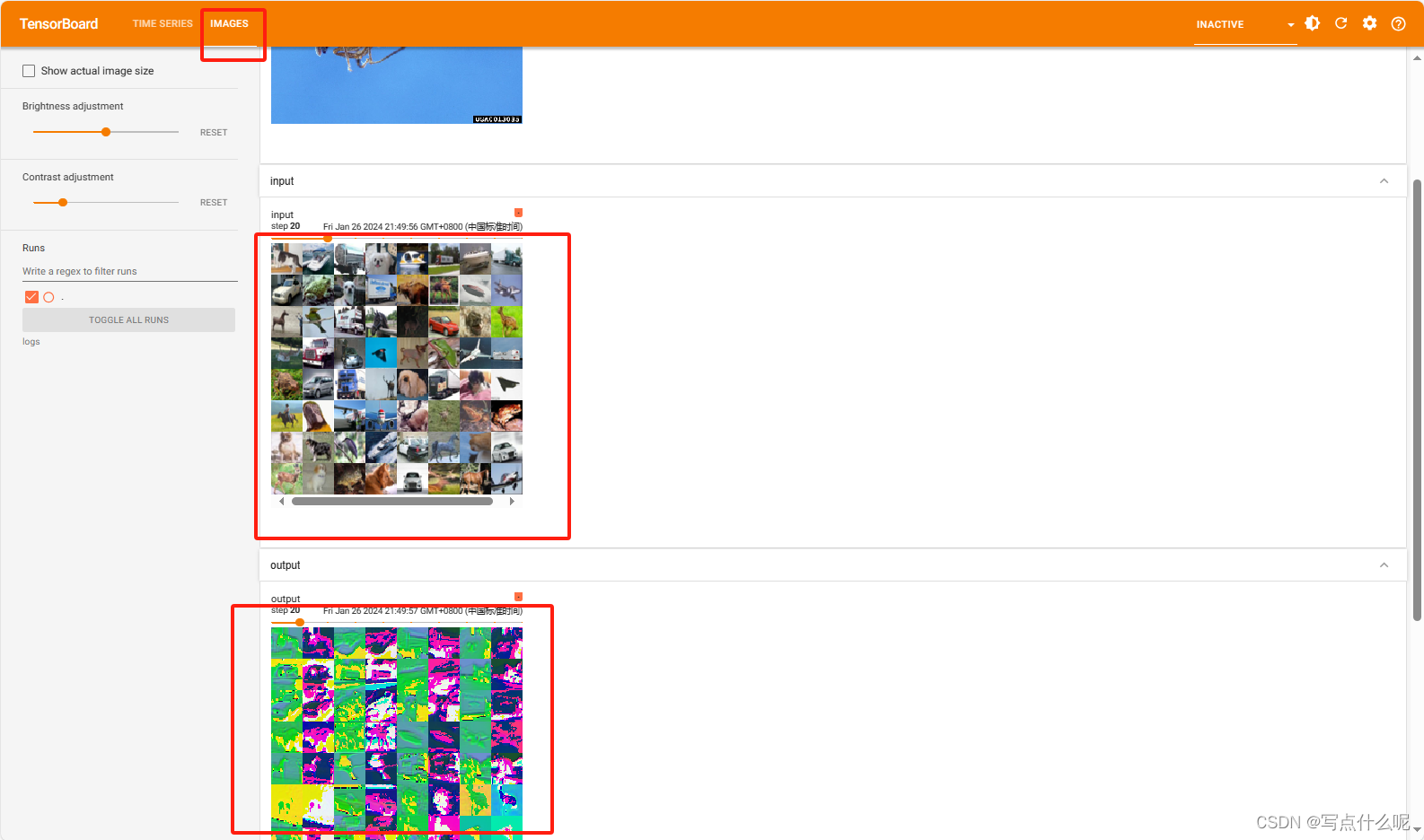
上篇:写给大数据开发,如何去掌握数据分析
就像说经济学家不炒股一样,有些数据开发不喜欢讲数据📊,就很离谱…自己不讲数据,不相信数据,别人也不敢用了~

所以找上级汇报,当然是汇报数据,优秀的领导人不需要下级的阿谀奉承,需要的是有数据支撑的独特内容。管理决策离不开数据支持,没有精确数据就没有正确管理。
1. 汇报的核心内容
首先,我们必须认识到,优秀的领导者不依赖下属的奉承,而是重视基于数据的独到见解。拍马屁的人很多,讲数据的寥寥。
例如,如果要汇报APP的市场表现,仅仅说“APP表现良好”是不够的。我们需要具体的数据来支持这一观点,比如:
- 激活用户数增长了20%;
- APP星级提升了15%;
- 留存达到了30%。
这些具体的数据可以帮助领导更好地理解产品的市场表现。

2. 上级与下级的信息差距
由于上级领导通常远离业务一线,他们可能对业务的基础数据缺乏直接的感受。(很多时候领导天天开会,自顾不暇,更不知道下面的人做了啥)
因此,下级在汇报时需要用数据来弥补这种信息差距。例如,通过展示以下SQL查询结果,我们可以向上级展示最近一个月内顾客投诉的增长趋势:
SELECT
Date
, COUNT(ComplaintID) AS NumberOfComplaints
FROM Complaints
WHERE Date BETWEEN '2023-01-01' AND '2023-01-31'
GROUP BY Date
ORDER BY Date;
要对自己的sql有自信,毕竟有些sql可是gpt都写不出来,自己写出来了,要相信自己
这个查询结果可以直观地展示出顾客投诉数量的日增长趋势,为上级提供了直接的数据支持。
3. 数据的具体要求
在汇报数据时,我们需要确保数据的准确性和来源的清晰性。
例如,如果我们使用Python进行数据分析,我们可能会编写如下代码来预处理数据,并确保数据的准确性:
import pandas as pd
# 加载数据
data = pd.read_csv('sales_data.csv')
# 数据清洗
data.dropna(inplace=True) # 删除缺失值
data = data[data['Sales'] > 0] # 删除销售额为负的记录
# 数据分析
monthly_sales = data.groupby('Month')['Sales'].sum()
print(monthly_sales)
通过这种方式,我们可以确保向上级汇报的销售数据是准确和可靠的。
(千万不要以为,搬运数据就不会有错,必须清洗之后的数据才是可用的,有些异常的值对数据影响很大,比如APP使用时长,有人使用个100小时,直接整个数据都跳动了)
4. 数据的创新与深度挖掘
在向上级汇报时,我们还需要展示我们的数据分析能力,通过创新的角度来分析数据(其实就是多维度分析…)。例如,我们可以使用Python来分析顾客投诉的主要原因,并将结果可视化:
import matplotlib.pyplot as plt
# 假设complaint_reasons是一个包含投诉原因的Pandas Series
complaint_reasons.value_counts().plot(kind='bar')
plt.title('Complaint Reasons Analysis')
plt.xlabel('Reason')
plt.ylabel('Number of Complaints')
plt.show()
通过这个图表,我们可以直观地向上级展示哪些原因导致了顾客的投诉,从而帮助上级做出针对性的改进措施。
5. 沟通数据的三个特征
- 数据准确翔实:确保汇报的数据不仅准确无误,还要具有代表性和时效性。
- 数据来源清晰:在汇报时,明确指出数据的来源,是否经过验证,以及采集和分析数据的方法。这增加了汇报内容的可信度。
- 数据可以质疑:准备好应对上级可能的质疑,这意味着你需要对数据的每个细节都了如指掌。例如,如果上级对某个数据点表示怀疑,你应该能迅速提供该数据的来源、采集时间、以及分析方法等信息。

例如,如果我们正在分析APP用户的活跃度和留存率,以下是一个例子,假设我们有一个用户登录记录表user_logins,包含用户ID和登录日期。
CREATE TABLE user_logins (
user_id INT,
login_date DATE
);
-- 示例
INSERT INTO user_logins (user_id, login_date) VALUES
(1, '2024-05-01'), (2, '2024-05-02'), (3, '2024-05-03'),
(4, '2024-05-04'), (5, '2024-05-05'), (1, '2024-06-01'),
(2, '2024-06-02'), (3, '2024-06-03'), (4, '2024-06-04'),
(5, '2024-06-05');
-- 计算活跃和留存
WITH first_login AS (
SELECT
user_id,
MIN(login_date) AS first_login_date
FROM
user_logins
GROUP BY
user_id
),
recent_logins AS (
SELECT
user_id,
COUNT(DISTINCT login_date) AS recent_logins_count
FROM
user_logins
WHERE
login_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
GROUP BY
user_id
)
SELECT
COUNT(DISTINCT rl.user_id) AS active_users,
COUNT(DISTINCT rl.user_id) * 100.0 / COUNT(DISTINCT fl.user_id) AS retention_rate
FROM
first_login fl
LEFT JOIN
recent_logins rl
ON
fl.user_id = rl.user_id
WHERE
fl.first_login_date <= DATE_SUB(CURDATE(), INTERVAL 30 DAY);
查询解释
- first_login: 找到每个用户的第一次登录日期。
- recent_logins: 统计最近一个月每个用户的登录次数。
- 最后,通过LEFT JOIN将两个表连接起来,计算出最近一个月的活跃用户数和留存率。
输出结果
该查询将输出两个值:
• active_users: 最近一个月的活跃用户数。
• retention_rate: 计算出的留存率(以百分比表示)。
如这样,有过程、有解释,面对领导的质问也不怕了
6. 案例研究:提升客户满意度
假设你是一家电商平台的数据开发(兼职做数据分析了,公司就是这样薅员工羊毛),需要向上级汇报关于提升客户满意度的分析结果。你可以采取以下步骤:
- 数据收集:使用SQL查询从数据库中提取最近六个月的客户服务记录和客户反馈数据。
- 数据分析:数据量少可以使用Python进行数据清洗和分析,识别客户不满意的主要原因。例如,你可能发现大部分不满意的客户都抱怨配送延迟。。
import pandas as pd
# 假设df是包含客户反馈的DataFrame
complaints_df = df[df['Feedback'] == 'Negative']
delay_complaints = complaints_df[complaints_df['ComplaintType'] == 'Delivery Delay']
delay_reasons = delay_complaints['Reason'].value_counts()
print(delay_reasons)
- 提出建议:基于数据分析的结果,提出具体的改进建议。例如,增加物流合作伙伴,优化配送路线等。
- 数据可视化:使用图表展示客户不满意的主要原因和建议的潜在影响,增强汇报的说服力。
通过这样详细而具体的数据分析和汇报,你不仅能够向上级清晰地展示问题所在,还能提供基于数据的解决方案,极大地提升汇报的效果
结论
数据是大数据开发向上沟通的命脉。通过提供准确、清晰来源的数据,以及通过创新的数据分析方法,大数据开发人员可以有效地向上级汇报,帮助企业做出更加明智的决策。












![[office] 快速提取出Excel 2010单元格括号内的文字信息 #知识分享#经验分享](https://img-blog.csdnimg.cn/img_convert/5c22f3b5ef2de8ef193b7744b4d623ef.jpeg)