大家好,我是小麦,今天给大家分享一款免费,可用于对话场景的文本转语音工具。
阅读感悟
不知道大家在日常的学习、工作中是否有这样的一个情况,当我们阅读完一篇文章,很快就能读完,但印象不会很深;或者说在很多时候,对着电脑、手机看久了,眼睛很疲劳,希望能够通过听觉来接收我们文章的内容。我自己在时常阅读公众号文章,就很喜欢去听,而不是阅读的方式。逐渐发现听内容比阅读内容更容易吸收,而且能够极大的缓解我们的眼睛疲劳。
通过将视觉转为听觉,在很大程度上增加了我们的用户体验性,同时也能更好的帮助我们了解到文章的内容。例如我们在开车时,不方便阅读精彩的文章,这时候通过将视觉转为听觉,就可以了解到文章内容。
上面提到的问题,也很简单,无非就是将文本内容转成音频内容。市面上也有很多这样的技术,能够将文本转成音频。很多的大企业也提供了这样的开发能力,通过与平台对接,将我们自己产品的内容转换为音频内容。随着技术的发展,音频的模式也越来越丰富。例如支持音频人性别、音色、音频背景等方面的设置。
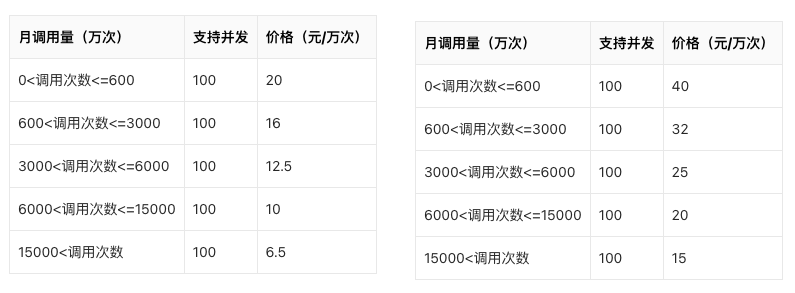
这些产品的功能虽然很强大,但需要具备一定的程序开发能力,对于不懂程序开发的用户来说,不是很友好。最重要的问题,当我们要生成很多的音频文件时,就需要付费使用,费用成本也不低。
ChatTTS是什么
今天要分享的内容就是ChatTTS,ChatTTS是什么呢?它又比其他的文章转音频有什么好处呢?
ChatTTS是一款基于对话场景下,经过优化,适用于自然、对话式文本转语音,并且是免费开源支持多种语言的工具。你可以将它嵌入到自己的程序中,同时你也可以使用官方的在线工具,直接使用。
用官方的描述,ChatTTS是什么。ChatTTS是专为对话场景设计的语音生成模型,特别适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。它支持中文和英文,通过使用大约100,000小时的中文和英文数据进行训练,ChatTTS在语音合成中表现出高质量和自然度。
如何使用
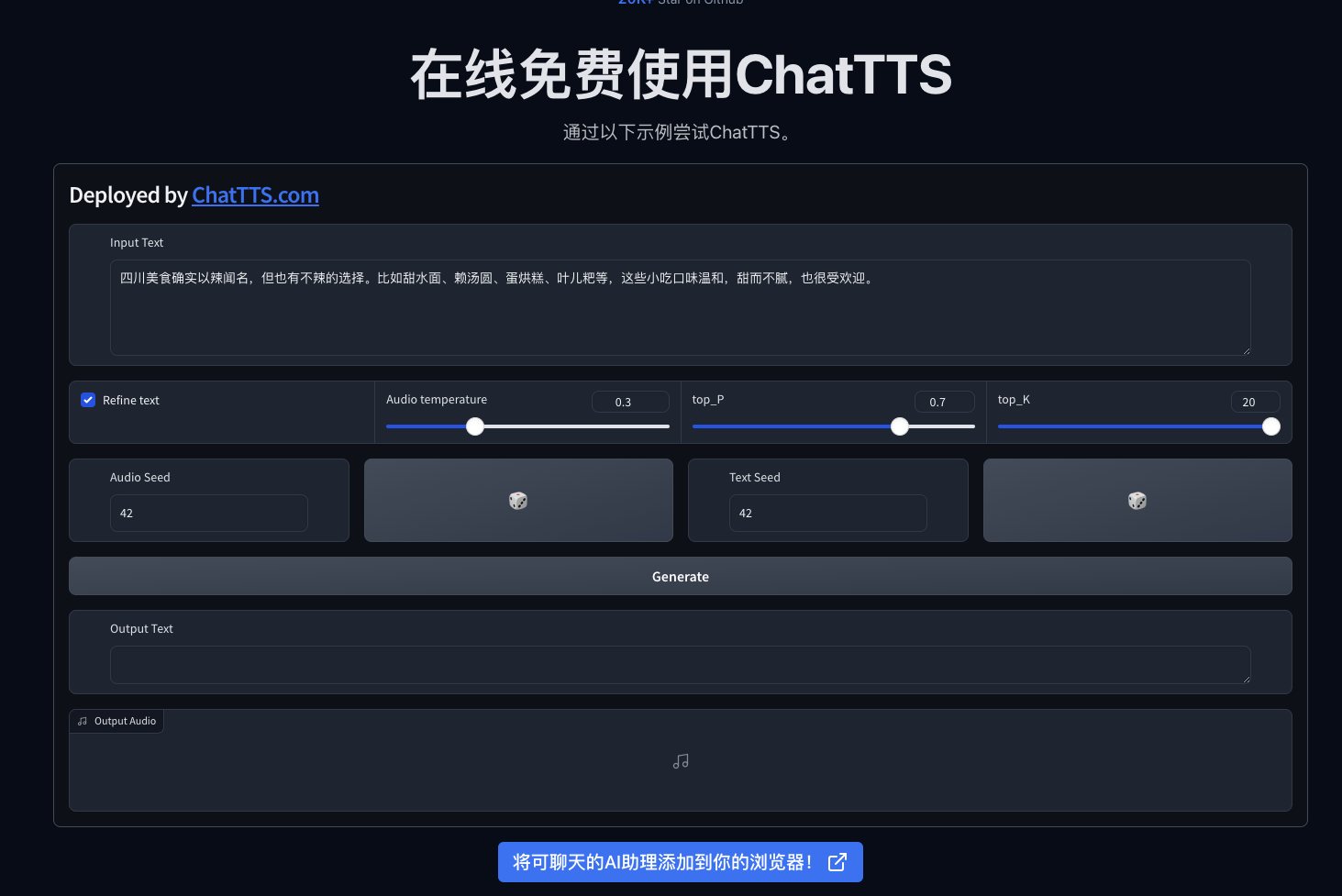
如果你是一个非编程人员,可以直接使用官网的在线语音生成工具就可以了。直接将需要转换成语音的文本贴如内容框,同时也可以针对生成的语音做一些调整,例如音速、音色等内容。生成好之后,点击页面的下载按钮,就可以把音频文件保存在本地,这样你就可以在其他地方使用了。

如果你是一名编程人员,希望能够继承到自己的产品中,这就需要你编程适当的代码才可以实现。不过这样非常的简单,官方也提供了代码示例,就短短的几行代码就可以做到。
1、从GitHub上下载代码
git clone https://github.com/2noise/ChatTTS
2、安装代码依赖
在开始之前,请确保已安装所需的软件包。您将需要torch和ChatTTS。如果尚未安装,可以使用pip安装。
pip install torch ChatTTS
3、导入所需要的库
在你的代码文件中导入必要的库。您将需要torch、ChatTTS和IPython.display中的Audio。
import torch
import ChatTTS
from IPython.display import Audio
4、初始化ChatTTS
创建ChatTTS类的实例并加载预训练模型。
chat = ChatTTS.Chat()
chat.load_models()
5、准备文本内容
定义要转换为语音的文本。将YOUR TEXT HERE替换为您想要的文本。
texts = ["你好,欢迎使用ChatTTS!"]
6、生成语音
使用infer方法从文本生成语音。设置use_decoder=True以启用解码器。
wavs = chat.infer(texts, use_decoder=True)
7、播放音频
使用IPython.display中的Audio类播放生成的音频。将采样率设置为24,000 Hz并启用自动播放。
Audio(wavs[0], rate=24_000, autoplay=True)
至此,整个程序的功能就实现了。可以通过下面完整代码,不难看出短短几行代码就能够将我们所需要的文本内容转成语音文件。
import torch
import ChatTTS
from IPython.display import Audio
# 初始化ChatTTS
chat = ChatTTS.Chat()
chat.load_models()
# 定义要转换为语音的文本
texts = ["你好,欢迎使用ChatTTS!"]
# 生成语音
wavs = chat.infer(texts, use_decoder=True)
# 播放生成的音频
Audio(wavs[0], rate=24_000, autoplay=True)
ChatTTS
可能你会产生一个疑问,市场上这么多的文字转语音工具,那ChatTTS有什么优势,或者说有什么特点呢?前面也提到了,该工具是免费开源,并且支持程序接入,同时也是支持在线使用。
具体的特点,来看看官网都是怎么说的呢。
1、多语言支持
ChatTTS 的一个关键特性是支持多种语言,包括英语和中文。这使其能够为广泛用户群提供服务,并克服语言障碍。
2、大规模数据训练
ChatTTS 使用了大量数据进行训练,大约有1000万小时的中文和英文数据。这样的大规模训练使其声音合成质量高,听起来自然。
3、对话任务兼容性
ChatTTS 很适合处理通常分配给大型语言模型LLMs的对话任务。它可以为对话生成响应,并在集成到各种应用和服务时提供更自然流畅的互动体验。
4、开源计划
项目团队计划开源一个经过训练的基础模型。这将使学术研究人员和社区开发人员能够进一步研究和发展这项技术。
5、控制和安全性
团队致力于提高模型的可控性,添加水印,并将其与LLMs集成。这些努力确保了模型的安全性和可靠性。
6、易用性
ChatTTS 为用户提供了易于使用的体验。它只需要文本信息作为输入,就可以生成相应的语音文件。这样的简单性使其方便有语音合成需求的用户。
使用感受
不管是在线工具,还是通过程序接入的方式,都整体体验了一次。效果相对还是不错的,对于生成内容比较多,又担心费用问题的群体可以考虑。其中还有一个亮点,它可以根据你文本的描述,生成对应的语言特色。
例如我在生成的文本中,提到了用四川话。最终生成的音频效果,就会带有四川话的特点。
本工具的分享就此结束,希望该工具的分享也对你有所帮助。







![[office] 快速提取出Excel 2010单元格括号内的文字信息 #知识分享#经验分享](https://img-blog.csdnimg.cn/img_convert/5c22f3b5ef2de8ef193b7744b4d623ef.jpeg)