目录
摘要
Abstract
文献阅读:应用于地表水总磷浓度预测的可解释CEEMDAN-FE-LSTM-Transformer混合模型
一、现有问题
二、提出方法
三、方法论
1、CEEMDAN(带自适应噪声的完全包络经验模式分解)
2、FE(模糊熵 )
3、 LSTM-Transformer
4、SHAP(特征选择与解释)
四、所提出的方法(CF-LT模型)
五、研究实验
1、数据集
2、评估指标
3、实验过程
4、实验结果
六、代码实现
总结
摘要
本周阅读的文献《Interpretable CEEMDAN-FE-LSTM-Transformer Hybrid Model for Predicting Total Phosphorus Concentrations in Surface Water》提出了一种用于预测地表水中总磷(TP)的浓度预测模型CF-LT,该模型融合了完全集成经验模态分解带自适应噪声(CEEMDAN)、模糊熵(FE)、长短期记忆(LSTM)网络与Transformer架构。首先利用CEEMDAN-FE对原始数据集进行预处理,通过将特征分解为多个固有模态函数(IMFs),并基于模糊熵值重组为高频、中频、低频和趋势成分,以反映数据的不同方面。其次,模型的LSTM部分与Transformer相结合,通过在编码器和解码器中嵌入Transformer的位置编码,增强了对输入数据时间序列依赖性的捕捉能力。CF-LT模型不仅提升了总磷浓度预测的精度,还通过SHAP方法提供了预测结果的可解释性,为理解影响地表水总磷浓度变化的主要驱动因素提供了科学依据,对水体富营养化管理和生态健康评估具有重要价值。
Abstract
The literature "Interpretable CEEMDAN-FE-LSTM Transformer Hybrid Model for Predicting Total Phosphorus Concentrations in Surface Water" read this week proposes a concentration prediction model CF-LT for predicting total phosphorus (TP) in surface water. This model integrates fully integrated empirical mode decomposition with adaptive noise (CEEMDAN), fuzzy entropy (FE), long short-term memory (LSTM) network, and Transformer architecture. Firstly, CEEMDAN-FE is used to preprocess the original dataset by decomposing features into multiple intrinsic mode functions (IMFs) and recombining them into high-frequency, intermediate frequency, low-frequency, and trend components based on fuzzy entropy values to reflect different aspects of the data. Secondly, the LSTM part of the model is combined with the Transformer, which enhances the ability to capture the temporal dependencies of input data by embedding the Transformer's position encoding in the encoder and decoder. The CF-LT model not only improves the accuracy of predicting total phosphorus concentration, but also provides interpretability of prediction results through the SHAP method, providing scientific basis for understanding the main driving factors affecting changes in total phosphorus concentration in surface water. It has important value for water eutrophication management and ecological health assessment.
文献阅读:应用于地表水总磷浓度预测的可解释CEEMDAN-FE-LSTM-Transformer混合模型Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water https://doi.org/10.1016/j.jhydrol.2024.130609
https://doi.org/10.1016/j.jhydrol.2024.130609
PDF:Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water (sciencedirectassets.com)
一、现有问题
在当前环境科学研究中,准确预测地表水中总磷(Total Phosphorus, TP)浓度面临着严峻挑战,这主要归因于磷的生物地球化学循环机制复杂性。湖泊等淡水系统中的磷输入量增加导致严重的富营养化问题,而传统机器学习模型在处理高维数据时易出现过拟合或欠拟合问题,且难以建立长期数据依赖关系以进行长期预测,限制了其预测效率与准确性。此外,这些“黑箱”模型在工程应用上缺乏透明度,限制了实际操作中的信任度和可解释性。
二、提出方法
提出了一种创新的混合模型——CEEMDAN-FE-LSTM-Transformer(CF-LT)模型,该模型结合了多种先进技术,包括完全集成经验模态分解自适应噪声、模糊熵、长短时记忆网络,以及Transformer架构。数据分频重构的引入有效地解决了以前的机器学习模型在面对高维数据时遇到的过度拟合和欠拟合问题,而注意力机制克服了这些模型在进行长期预测时无法建立数据之间的长期依赖关系的问题,目的在于提高预测总磷浓度的精确度与可解释性。
三、方法论
1、CEEMDAN(完全自适应噪声集合经验模态分解)
作为一种先进的时间序列分析方法,CEEMDAN通过在经验模态分解(EMD)过程中加入自适应噪声,有效减少了传统EMD中存在的模式混叠问题。它能将原始信号分解为一系列固有模态函数(IMFs),每个IMF代表信号的不同时间尺度特征,从而使得复杂信号的分析更加直观和准确。在本研究中,CEEMDAN用于处理来自泰湖三个监测站的每日水质数据,将总磷浓度与其他水质参数如水温、pH值、溶解氧等分离成不同频带的信号,为后续的特征重组和模型训练打下基础。

2、FE(模糊熵 )
此方法被用来评估时间序列的不确定性和复杂度,通过计算相邻数据点间相似度来反映时间序列的规律性。在CEEMDAN分解后,基于FE的结果对IMFs进行分类,将其分为高频、中频、低频和趋势成分,即IMFH、IMFM、IMFL和IMFT,这一步骤称为“分频重构”。这种重组方式不仅降低了数据的维度,还增强了数据的规律性,有助于模型学习关键特征。
3、 LSTM-Transformer
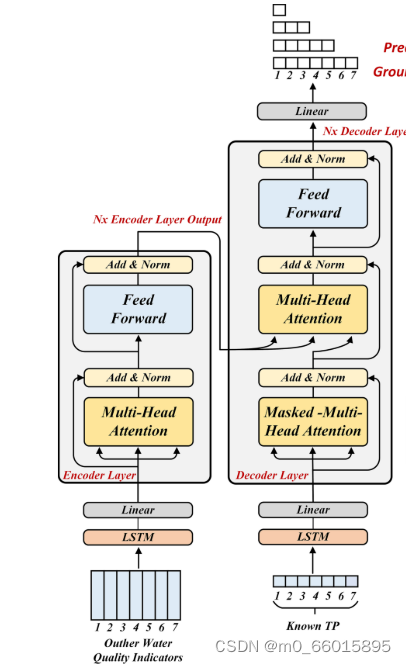
LSTM能够选择性地遗忘旧信息、存储新信息,并决定如何更新隐藏状态,特别适合处理如时间序列数据这类需要记住历史信息的任务。相较于传统的循环神经网络,Transformer通过自注意力(Self-Attention)机制,实现了序列数据中所有元素的相互依赖关系的并行计算,显著提高了模型处理长序列数据的能力和效率。它由编码器和解码器组成,编码器通过多头自注意力层捕捉输入序列的全局依赖,而解码器则在编码器输出的基础上预测序列的下一个元素。弥补了LSTM在处理长序列时的不足。模型中的编码器和解码器结构包含多头自注意力层和前馈网络,通过位置编码注入序列顺序信息。多头注意力的结构如下图所示:

其中K和V相同。当给定Q、K和V的相同组合时,模型应该学习不同的信息,例如捕获不同的子空间表示(短期和长期依赖)。多头注意力层使用h组线性投影变换Q、K和V。转换后的Q、K和V的h个集合是并行计算的。最终,这些h个注意力值的输出被组合,并且结果由另一线性投影生成。为了避免在解码过程中将未来知识泄漏到当前预测时间点,解码器层使用掩蔽多头注意力。
LSTM-Transformer模型,即在编码器和解码器中,LSTM的隐藏层被Transformer位置编码取代,以建立输入数据之间的时间依赖关系。
4、SHAP(特征选择与解释)
为了提高模型的可解释性,研究采用了Shapley Additive Explanations方法。SHAP基于博弈论的Shapley值概念,为每个特征分配一个贡献值,表明其对模型预测结果的影响程度。这种方法能够具体展示哪些输入特征对最终预测结果起到了决定性作用。SHAP value最大的优势是SHAP能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。
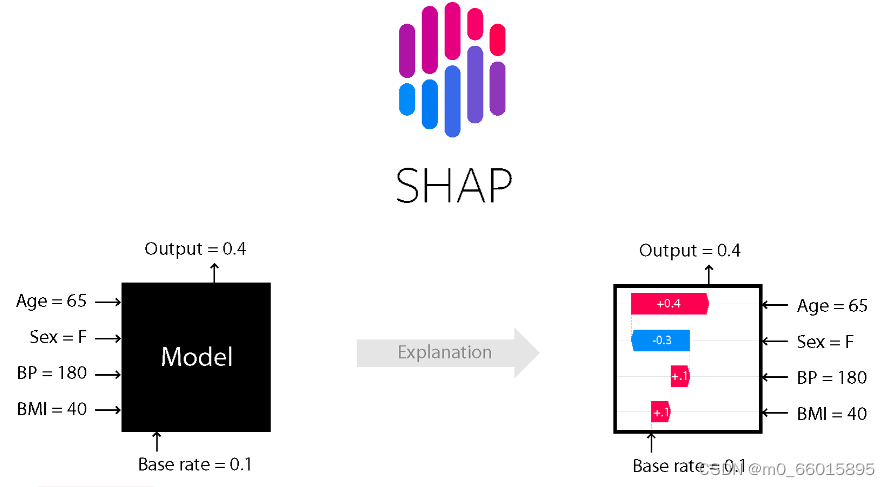
当我们进行模型的 SHAP 事后解释时,需要明确标记已知数据集(设有 M 个特征变量,n 个样本),原始模型 f,以及原始模型 f 在数据集上的所有预测值。贡献值计算:

四、所提出的方法(CF-LT模型)
CF-LT模型的构建结合了上述技术的优点,形成了一个多层次、多维度的数据处理与预测框架。首先,利用CEEMDAN对原始数据进行预处理,将复杂的高维数据分解为不同频率的IMFs及趋势项,再利用FE对这些IMFs进行分类重组,降低维度同时保留关键信息。其次,将重构后的特征输入到LSTM-Transformer混合架构中,其中LSTM层捕获短期时间依赖,而Transformer通过自注意力机制强化了长期依赖的学习能力。模型输入包括水温、pH值、溶解氧、化学需氧量、电导率、浊度、氨氮和总氮等多个水质参数。
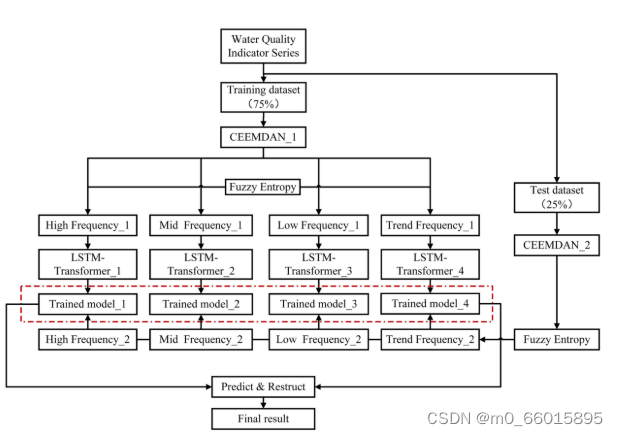
- 模型输入包含两个特征输入。编码器层包含水温(WT),pH值(PH),溶解氧(DO),化学需氧量(COD),电导率(EC),浊度(TU),铵(NH3-N)和总氮(TN)的数据,解码器层包含第一预测时间点之前七天的TP时间序列。
- 在通过LSTM和线性层之后,两个特征数据集分别被发送到编码器层和解码器层。
- 两个子层组成编码器层。多头注意力层计算输入特征的注意力矩阵,然后前馈层改变数据维度。最后,数据被输入到下一个编码器或解码器层。
- 三个子层构成解码器层。在掩蔽多头注意力层已经计算输入特征的注意力矩阵之后,多头注意力层从编码器层的输出建立注意力连接。前馈层将其传递到下一个解码器层或线性层以获得最终的模型输出。
- 最终,在训练数据集上确定每个频率的最佳模型,并用于从测试数据集获得预测。将所有频率的预测结果相加,以确保TP浓度的最佳预测。
五、研究实验
1、数据集
本研究的数据集来源于中国江苏省环境监测中心提供的泰湖流域三个国家水质监测站——姚巷桥、直湖港和观渡桥站的水质量监测数据。数据涵盖了从2015年1月1日至2020年12月31日的每日观测记录,涉及九个水质指标:水温(WT)、pH值、溶解氧(DO)、化学需氧量(COD)、电导率(EC)、浊度(TU)、氨氮(NH3-N)、总氮(TN)和总磷(TP)。
2、评估指标
模型的性能评估采用了几项关键指标:决定系数(R²),均方误差(MSE),以及平均绝对百分比误差(MAPE)。R²衡量模型预测值与实际值的拟合程度,接近1表示模型预测能力强;MSE衡量预测误差的平方和,值越小说明预测误差越小;MAPE则从百分比角度反映预测误差的大小,值越低意味着预测越准确。

3、实验过程
实验过程包括数据预处理、模型训练和测试。建立了一个完整的实验程序,以评估所提出的模型在不同的数据集和预测时间窗口的性能。首先,数据经过CEEMDAN-FE方法进行预处理,通过添加自适应噪声的完全集成经验模态分解去除信息干扰,提取多尺度信息,并利用模糊熵降低子信号的数量。接着,将处理后的数据按75%和25%的比例分为训练集和测试集。训练阶段,将预处理的训练数据集输入到LSTM-Transformer模型。使用反向传播和Adam优化器更新模型权重,并采用网格搜索来识别LSTMTransformer模块的最佳超参数,确保模型在不同预测时间窗口(7天、5天、3天、1天)下的性能最佳。
4、实验结果
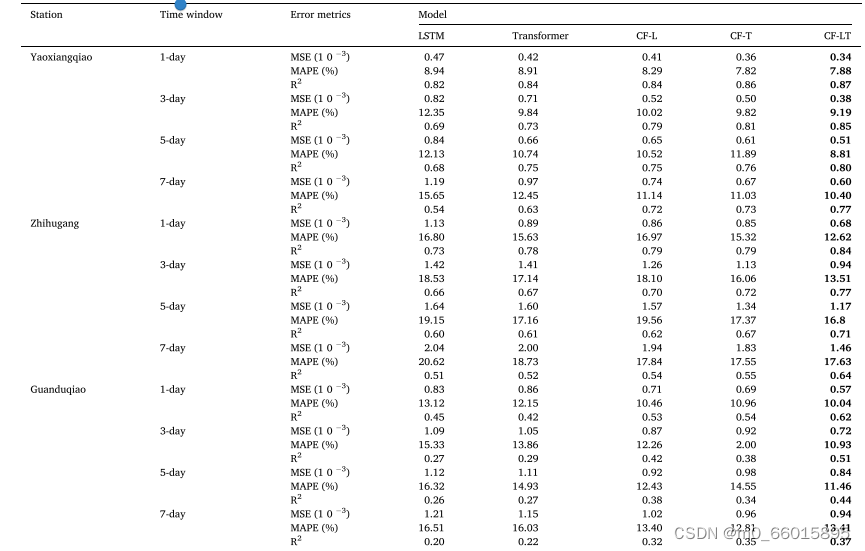
模型性能比较
将最佳训练模型应用于测试数据集,表总结了CF-LT、LSTM、Transformer、CF-L和CF-T模型在不同站点和不同预测时间窗下给出的TP浓度预测。所提出的CF-LT模型给出了所有三个评估指标的最佳结果。就R2而言,CF-LT模型的范围为0.37至0.87,而次佳的CF-L和CF-T模型分别为0.32-0.84和0.35-0.86。这表明,将LSTM的长期记忆与Transformer的注意力机制相结合,可以提高预测精度。将最差的LSTM和Transformer模型与CF-L和CF-T模型进行比较,MAPE的范围从8.94%-20.62%(LSTM)和8.91%-18.73%(Transformer)变为8.29%-19.56%(CF-L)和7.82%-17.55%(CF-T)。这些结果表明,数据分解和分频建模通过捕获更多隐藏在原始数据中的信息来显着提高预测准确性。
影响TP浓度预测的因素
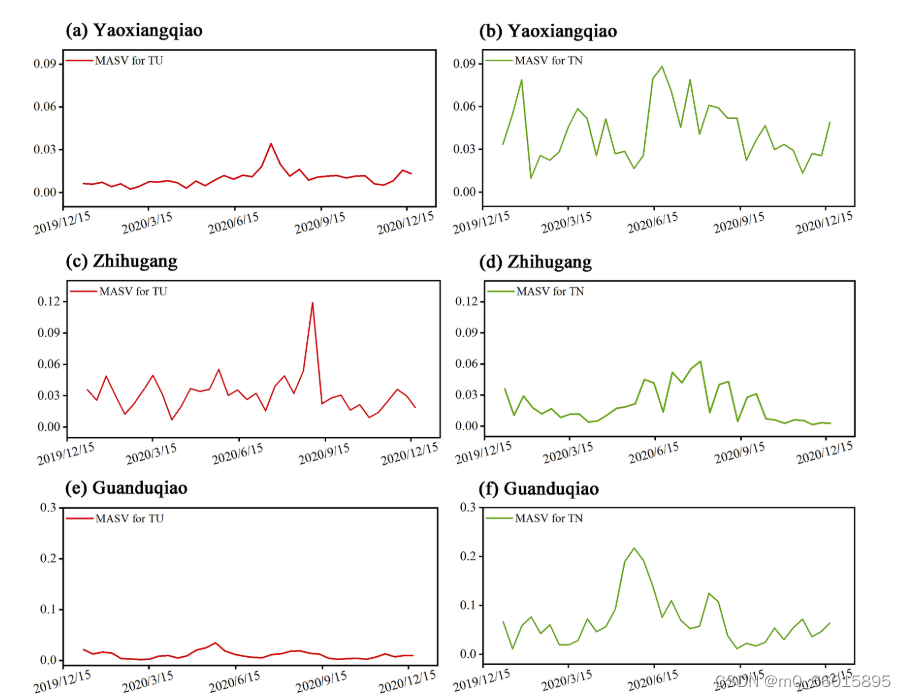
采用平均绝对SHAP值(MASV)量化输入特征(WT、PH、DO、COD、EC、TU、TN、NH3-N、TP)对TP预测结果的贡献程度,MASV越大,对模型预测结果的影响越大。研究表明,除了过去的TP浓度序列本身,总氮(TN)和浊度(TU)是影响TP预测的两个主要因素。这表明,TP的变化不仅受历史浓度的直接影响,还与非点源污染排放及水体中氮磷比相关联的藻类生长动态紧密相关。特别是,TN与TP之间的显著相关性,强调了两者在湖泊营养盐循环中的耦合效应,突显了非点源氮输入对磷浓度预测的重要性。

TP浓度预测中TU和TN贡献的动态演变
在不同时间窗口内,TU和TN对TP浓度预测的贡献呈现出动态变化,尤其在雨季更为显著。通过分析2020年全年在姚巷桥、直湖港和观渡桥三个监测站的数据发现,TU和TN的平均绝对SHAP值(MASV)在湿季达到高峰,暗示了非点源污染在此期间的增强。在姚巷桥站,尽管存在特定平季时段TN也有较高MASV值,这可能归因于该地区点源污染的输入。相比之下,观渡桥站的TN贡献度更高,这与该区域周围耕地较多,而非林地或城市土地占主导的其他两站不同,导致非点源污染类型和主要贡献因子存在差异。这些发现表明,CF-LT模型不仅能有效预测TP浓度,还能揭示环境条件变化下TP响应机制的动态,为理解和管理湖泊富营养化提供宝贵洞见。
六、代码实现
CEEMDAN和FE数据预处理
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)构建LSTM-Transformer混合模型
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
# 注意力机制,包括自注意力和编码器-解码器注意力
# 这里简化了多头注意力和残差连接的具体实现
return decoder_output
input_features = Input(shape=(input_shape)) # 假定input_shape为特征维度
lstm_out = LSTM(lstm_units)(input_features) # LSTM层
# 假设我们已经得到了位置编码向量
pos_encodings = get_positional_encoding(max_seq_length, d_model)
# 将LSTM输出与位置编码结合,然后送入Transformer
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
# 解码器部分可以类似实现
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')总结
研究开发了一种可解释的CEEMDAN-FE-LSTM-Transformer混合模型,针对地表水中总磷浓度预测,该模型通过先进的数据预处理技术和深度学习模型的融合,显著提高了预测精度,并通过SHAP提供了清晰的特征解释。实验结果证实了模型的有效性,尤其是对关键环境因素的识别,为水体富营养化管理和污染控制提供了有力的工具。未来的研究方向可以考虑迁移学习和物理-深度学习模型的结合,进一步提高模型的泛化能力和解释力。

![云服务平台仿真-身份认证/授权/申请和释放IT资源[云计算3]](https://img-blog.csdnimg.cn/direct/75724d532e1742779293723501b6476c.png)