大模型(LLMs)以其卓越的性能在多个应用场景中大放异彩。然而,随着应用的深入,这些模型的推理速度问题逐渐凸显。为了解决这一挑战,推测性解码(Speculative Decoding, SPD)技术应运而生。本文深入探讨了SPD在多模态大型语言模型(MLLMs)中的应用,尤其是针对LLaVA 7B模型的优化。MLLMs通过融合视觉和文本数据,极大地丰富了模型与用户的互动,但同时也面临着自回归生成和内存带宽的瓶颈。SPD技术通过小型草稿模型预测未来标记,并由目标LLM进行快速验证,有效提升了推理效率。实验结果更是令人振奋:即便不依赖图像信息,仅利用文本数据的草稿模型也能实现与使用图像特征的模型相媲美的加速效果。这一发现不仅为MLLMs的高效推理提供了新思路,也为未来在更广泛的应用场景中利用SPD技术奠定了基础。
推测性解码(SPD)
推测性解码是一种创新的解码技术,旨在加速大型语言模型(LLMs)的推理过程。在传统的自回归生成中,模型在生成每个新词时都必须等待前一个词的完成,这限制了生成速度。SPD通过使用一个小型的草稿模型来预测一系列未来的词,然后由目标大型语言模型(LLM)并行验证这些预测,从而显著提高了效率。这种方法允许模型在单个调用中评估多个候选词,而不是逐个生成,从而减少了整体的推理时间。
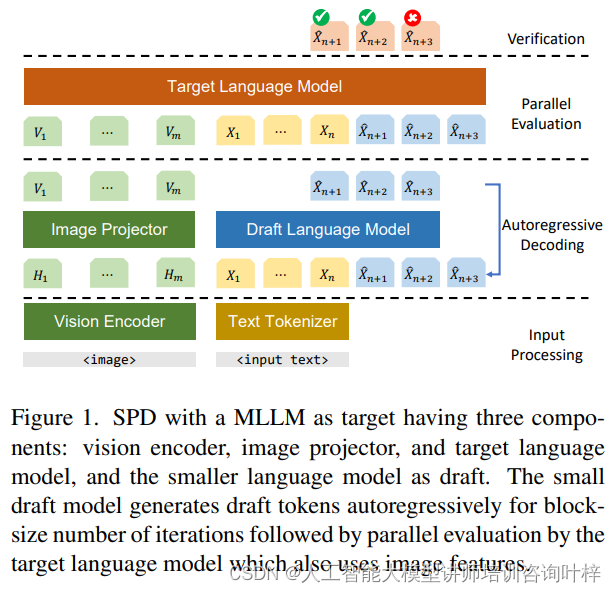
MLLMs通过整合视觉编码器、适配器和语言模型后端,能够处理和理解图像信息,并将这些信息转换为语言模型能够理解的嵌入空间。这种模型能够接收图像和文本的输入,通过内部的融合机制,生成更加丰富和准确的输出。例如,给定一张图片和相关的文本查询,MLLMs能够生成描述图片内容的文本,或者回答与图片相关的复杂问题。
视觉编码器首先将输入图像转换成一系列的图像编码,适配器随后将这些编码转换为与语言模型兼容的嵌入向量。这些图像嵌入与文本标记一起被送入语言模型,模型根据这些信息生成响应。MLLMs的设计允许它们在多种任务中表现出色,包括图像描述、视觉问答和多模态推理等。
然而,MLLMs在处理大量数据时仍然面临内存带宽限制和生成速度的挑战。SPD技术的应用为解决这些问题提供了新的可能性,通过减少对内存的依赖和加速生成过程,SPD有助于提升MLLMs的整体性能和应用范围。接下来的章节将详细介绍SPD在MLLMs中的应用,并通过实验验证其效果。
SPD在MLLMs中的应用
为了充分利用SPD的优势,关键在于设计一个与目标模型(如LLaVA-7B)显著较小但高度一致的草稿模型。在以往的研究中,草稿模型通常是目标模型同系列的小型预训练模型,或者具有相同架构的小型模型。由于LLaVA家族中没有公开可用的小型模型,研究者们不得不从头开始训练一个草稿模型。
草稿模型的设计遵循LLaVA的架构,包括一个适配器和一个语言模型后端,但参数数量远少于LLaVA 7B。研究者们采用了两种草稿模型:
- 小型LLaVA草稿模型:包含一个较小的图像适配器和一个草稿语言模型。
- 文本草稿模型:仅依赖于输入文本标记生成草稿标记,不涉及图像信息。程
草稿模型的生成过程是一个预测性的任务,它在多模态大型语言模型(MLLMs)中起着至关重要的作用。这个过程开始于输入数据的准备,包括一张图像和相关的文本信息。图像首先被一个视觉编码器处理,转换成一系列的嵌入向量,这些向量捕捉了图像的主要内容和特征。与此同时,文本信息也被转换成一系列标记的嵌入向量,这些向量代表了文本的语义信息。
接下来,草稿模型利用这些嵌入向量作为输入,开始生成一系列草稿标记。这个过程是自回归的,意味着每个新生成的标记都依赖于之前生成的所有标记。草稿模型会逐个生成标记,每个新标记都是在已经生成的标记序列的基础上进行预测的。这个过程不需要考虑图像的视觉信息,因为它完全依赖于文本标记来生成草稿标记。
草稿模型会考虑输入的文本标记序列,并基于这些信息,通过其内部的语言模型机制,预测下一个可能出现的标记。然后,这个预测的标记被添加到序列的末尾,成为新的上下文,为下一个标记的生成提供参考。这个过程会一直持续,直到生成了预定数量的标记,形成了一个完整的草稿序列。
这个生成过程的目的是快速产出一个候选的标记序列,这个序列将作为草稿提交给目标模型进行进一步的验证和筛选。草稿模型的生成过程是高效且自主的,它通过预测文本序列的延续,为后续的精确生成打下基础。尽管草稿模型生成的标记可能并不完全准确,但它们为推测性解码提供了必要的原材料,使得目标模型能够在此基础上进行快速且精确的迭代优化。
目标模型的验证过程:一旦草稿模型生成了一系列预测标记,目标LLaVA模型将对这些标记进行评估。目标模型在评估时会考虑图像的嵌入向量和文本标记嵌入,以计算每个草稿标记被接受的概率。如果一个草稿标记与目标模型的预测高度一致,即草稿模型和目标模型对这个标记的预测非常接近,那么这个草稿标记就很可能被接受。如果草稿标记与目标模型的预测不一致,即草稿模型的预测与目标模型相差较远,那么这个标记将被拒绝,并从残差分布中重新采样一个新的标记。残差分布是一种调整后的概率分布,它基于目标模型和草稿模型的概率差异来生成新的标记。
通过这种方式,SPD技术能够有效地利用草稿模型快速生成一系列预测标记,并通过目标模型进行验证,以确保生成的标记符合目标模型的预期输出。这个过程不仅提高了生成速度,还保持了生成质量,使得MLLMs能够更高效地处理复杂的多模态任务。
使用文本草稿模型相较于具有LLaVA架构的草稿模型更为高效,因为它不需要额外的适配器,也不需要适配器的训练。此外,实验结果表明,即使不使用图像信息,仅使用文本的草稿模型也能实现显著的加速效果,这为MLLMs的推理提供了新的思路。
通过上述方法,研究者们能够显著提高MLLMs的推理效率,同时保持了模型性能。接下来的章节将展示具体的实验设置和结果,进一步验证SPD在MLLMs中的有效性。
实验
实验采用了LLaVA-7B模型作为目标模型,它是基于LLaMA-7B语言模型后端构建的。为了探索SPD的性能,研究者训练了一系列规模较小的草稿模型,这些模型的参数量固定为115M。草稿模型经过了不同阶段的训练和微调,包括基础的LLaMA模型、经过指令微调的聊天LLaMA模型,以及进一步在特定数据集上微调的LLaVA模型。

评估任务涵盖了图像问答、图像描述和科学问题回答等多个视觉指令任务,这些任务要求模型生成大量文本,从而充分发挥SPD的优势。研究者使用了LLaVA Instruct 150K数据集、COCO数据集和ScienceQA数据集进行评估,这些数据集不仅提供了丰富的图像和文本信息,也为评估模型的多模态理解能力提供了良好的平台。
在评估指标方面,研究者关注了块效率、内存限制加速和标记率这三个关键指标。块效率反映了每个目标模型运行生成的平均标记数,而内存限制加速则基于块效率和模型参数比值来估计加速效果。标记率则是衡量SPD生成速度的直接指标,即每秒生成的标记数。

实验结果显示,SPD技术显著提升了LLaVA 7B目标模型的输出生成速度。特别是在不使用图像信息的情况下,仅依靠文本的草稿模型也能达到与使用图像特征的草稿模型相当的加速效果。在不同的任务中,经过微调的LLaVA文本模型和LLaVA模型均展现出了优异的性能,这证明了SPD技术在加速MLLMs推理中的潜力。
通过定性分析,研究者观察到草稿模型能够准确预测常见的词汇、短语,甚至是单词的一部分。例如,在COCO图像描述任务中,草稿模型能够基于给定的上下文预测出完整的单词。这种能力在开放的文本生成任务中尤为重要,因为许多标记由常见词汇、短语和单词补全组成,而这些并不依赖于图像信息。

综合实验结果,研究者得出结论,SPD是一种有效的技术,能够显著提高MLLMs的推理速度。文本草稿模型在没有图像信息的情况下也能达到显著的加速效果,这些发现对于推动人工智能领域的发展具有重要意义。它们不仅证明了SPD技术在提高MLLMs效率方面的实际应用价值,而且也为未来在更广泛的任务和应用场景中利用SPD技术提供了坚实的基础。随着技术的不断进步和优化,SPD有望成为加速大型语言模型推理的重要工具,进一步拓展人工智能在各个领域的应用边界。
研究者们的工作也启发了对未来研究方向的思考。例如,如何进一步优化草稿模型的结构,以实现更高的块效率和内存限制加速;如何将SPD技术应用于其他类型的多模态模型,以及如何结合最新的算法进展进一步提升SPD的性能。这些探索将继续推动MLLMs的发展,为构建更加智能和高效的人工智能系统铺平道路。
论文链接:https://arxiv.org/abs/2404.08856