参考官方文档Table API连接器
1 Table API连接器概述
Flink的Table API和SQL程序可以连接到其他外部系统,用于读取和写入批处理表和流式表。source表提供对存储在外部系统(如数据库、键值存储、消息队列或文件系统)中的数据的访问。sink表将table发送到外部存储系统。根据source和sink的类型,它们支持不同的格式,如CSV、Avro、Parquet或ORC。
本页介绍如何使用本机支持的连接器在Flink中注册source表和sink表。注册source或sink后,可以通过Table API和SQL语句访问它。
Name Source Sink
Filesystem Bounded and Unbounded Scan,Lookup Streaming,Batch
Elasticsearch Not supported Streaming,Batch
Opensearch Not supported Streaming,Batch
Apache Kafka Unbounded Scan Streaming,Batch***
JDBC Bounded Scan,Lookup Streaming,Batch***
Apache HBase Bounded Scan,Lookup Streaming,Batch
Apache Hive Unbounded Scan,Bounded Scan,Lookup Streaming,Batch
Amazon DynamoDB Not supported Streaming,Batch
Amazon Kinesis Data Streams Unbounded Scan Streaming
Amazon Kinesis Data Firehose Not supported Streaming
Flink支持使用SQL CREATE TABLE语句来注册表。可以定义表名、表模式和用于连接到外部系统的表选项。
2 Print SQL连接器
Print连接器允许将每一行写入标准输出流或者标准错误流。
设计目的:简单的流作业测试,对生产调试带来极大便利。
创建一张基于Print的表
# -*- coding: UTF-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1. 创建 TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2.创建source表
my_source_ddl = """
CREATE TABLE datagen (
id INT,
data STRING
) WITH (
'connector' = 'datagen',
'fields.id.kind' = 'sequence',
'fields.id.start' = '1',
'fields.id.end' = '5'
)
"""
# 注册source表
table_env.execute_sql(my_source_ddl)
# 3.创建sink表
my_sink_ddl = """
CREATE TABLE print_table (
id INT,
data STRING
) WITH ('connector' = 'print')
"""
# 注册sink表
table_env.execute_sql(my_sink_ddl)
# 4.通过SQL查询语句来写入
table_env.execute_sql("INSERT INTO print_table SELECT * FROM datagen").wait()

3 JDBC SQL连接器
JDBC连接器允许使用JDBC驱动向任意类型的关系型数据库读取或者写入数据。本文档描述了针对关系型数据库如何通过建立JDBC连接器来执行SQL查询。
3.1 依赖
flink-connector-jdbc-1.16.0.jar
mysql-connector-java-8.0.19.jar
3.2 创建表
DROP TABLE IF EXISTS `books`;
CREATE TABLE `books` (
`id` int NOT NULL,
`title` varchar(255) DEFAULT NULL,
`authors` varchar(255) DEFAULT NULL,
`years` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
一、连接器参数:
connector 必填 (none) String 指定使用什么类型的连接器,这里应该是'jdbc'。
url 必填 (none) String JDBC 数据库 url。
table-name 必填 (none) String 连接到 JDBC 表的名称。
driver 可选 (none) String 用于连接到此URL的JDBC驱动类名,如果不设置,将自动从URL中推导。
username 可选 (none) String JDBC用户名。如果指定了'username'和'password'中的任一参数,则两者必须都被指定。
password 可选 (none) String JDBC 密码。
二、创建JDBC表
-- 在 Flink SQL 中注册一张 MySQL 表 'users'
CREATE TABLE MyUserTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users'
);
-- 从另一张表 "T" 将数据写入到 JDBC 表中
INSERT INTO MyUserTable
SELECT id, name, age, status FROM T;
-- 查看 JDBC 表中的数据
SELECT id, name, age, status FROM MyUserTable;
3.3 代码示例
# -*- coding: UTF-8 -*-
from pyflink.table import EnvironmentSettings, TableEnvironment
# 1. 创建 TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 2.创建source表
my_source_ddl = """
CREATE TABLE books (
id INT,
title STRING,
authors STRING,
years INT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=UTC',
'driver' = 'com.mysql.cj.jdbc.Driver',
'table-name' = 'books',
'username' = 'root',
'password' = 'bigdata'
)
"""
# 注册source表
table_env.execute_sql(my_source_ddl)
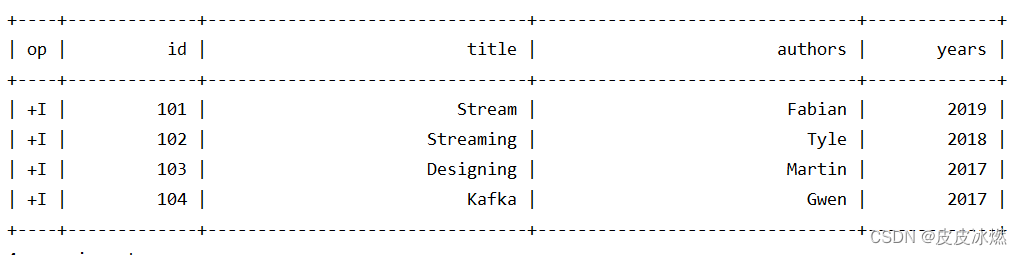
# 3.查看JDBC表中的数据
table = table_env.sql_query("select * from books")
table.execute().print()
4 Kafka SQL连接器
4.1 依赖
flink-connector-kafka-1.16.0.jar
4.2 示例代码
4.2.1 csv格式
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
# 1. 创建 StreamTableEnvironment
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env)
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
# 2.创建source表
my_source_ddl = """
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = '192.168.43.48:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
)
"""
# 注册source表
st_env.execute_sql(my_source_ddl)
# 3.(SQL表)KafkaTable转换成(Table API表)table
table = st_env.from_path("KafkaTable")
table.execute().print()
kafka中输入如下信息:
1,2,3
1,2,"good"
ts是自动生成的,系统时间。

4.2.2 json格式
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
# 1. 创建 StreamTableEnvironment
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env)
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
# 2.创建source表
my_source_ddl = """
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = '192.168.43.48:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
)
"""
# 注册source表
st_env.execute_sql(my_source_ddl)
# 3.(SQL表)KafkaTable转换成(Table API表)table
table = st_env.from_path("KafkaTable")
table.execute().print()
kafka中输入如下信息:
{"user_id":1,"item_id":2,"behavior":"good"}
ts是自动生成的,系统时间。

4.2.3 时间戳的处理
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
# 1. 创建 StreamTableEnvironment
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env)
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
# 2.创建source表
my_source_ddl = """
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = '192.168.43.48:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
)
"""
# 注册source表
st_env.execute_sql(my_source_ddl)
# 3.(SQL表)KafkaTable转换成(Table API表)table
table = st_env.from_path("KafkaTable")
table.execute().print()
kafka中输入如下信息:
{"user_id":1,"item_id":2,"behavior":"good","ts":"2023-01-26 12:30:30.000"}
ts是输入的时间戳。






![[NPUCTF2020]ezinclude](https://img-blog.csdnimg.cn/58bee4ab7031486198f49ba7aafff1a0.png)
