目录
一、环境准备
二、编写代码
一、环境准备
pip install beautifulsoup4
pip intall lxml
pip install requests
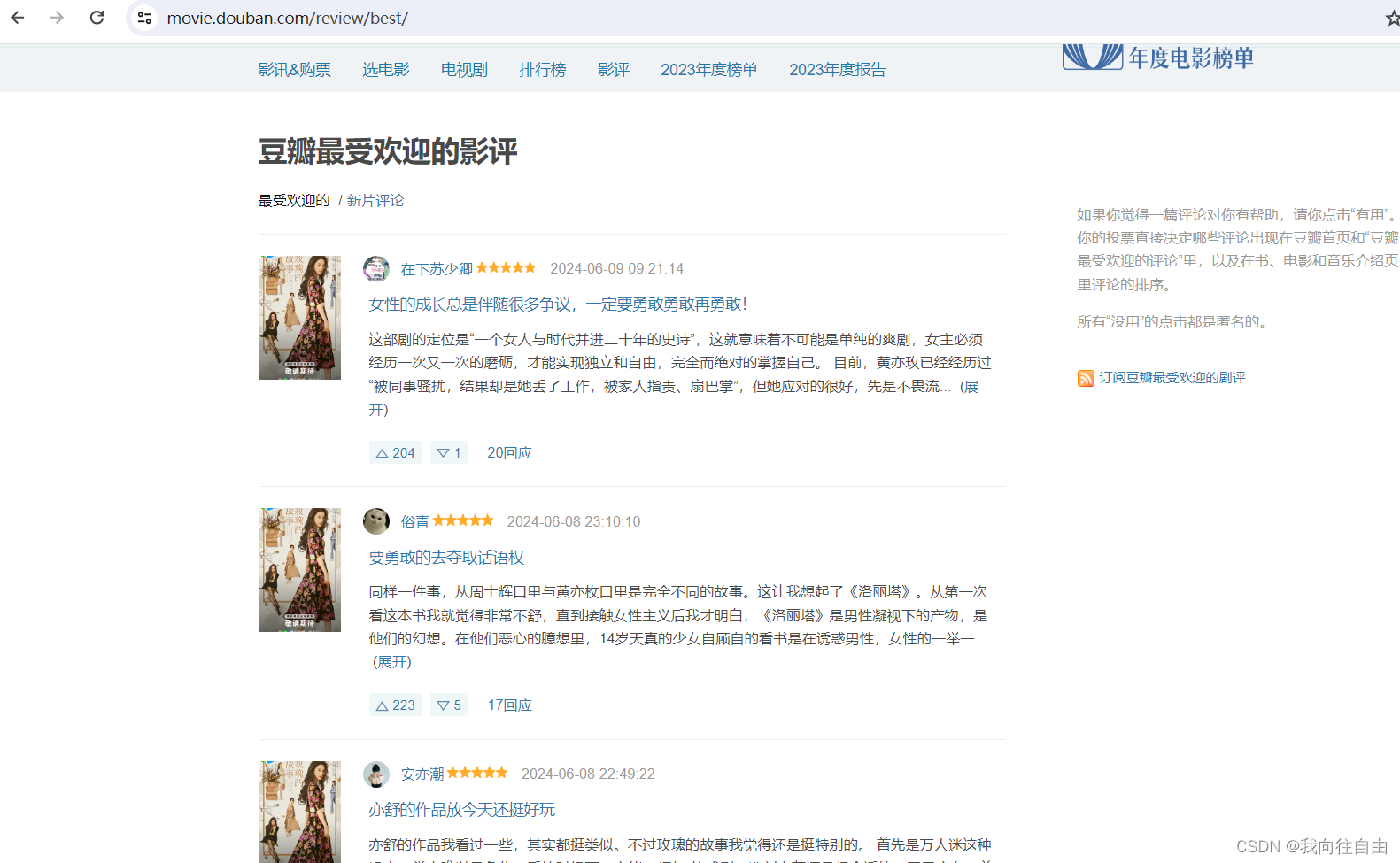
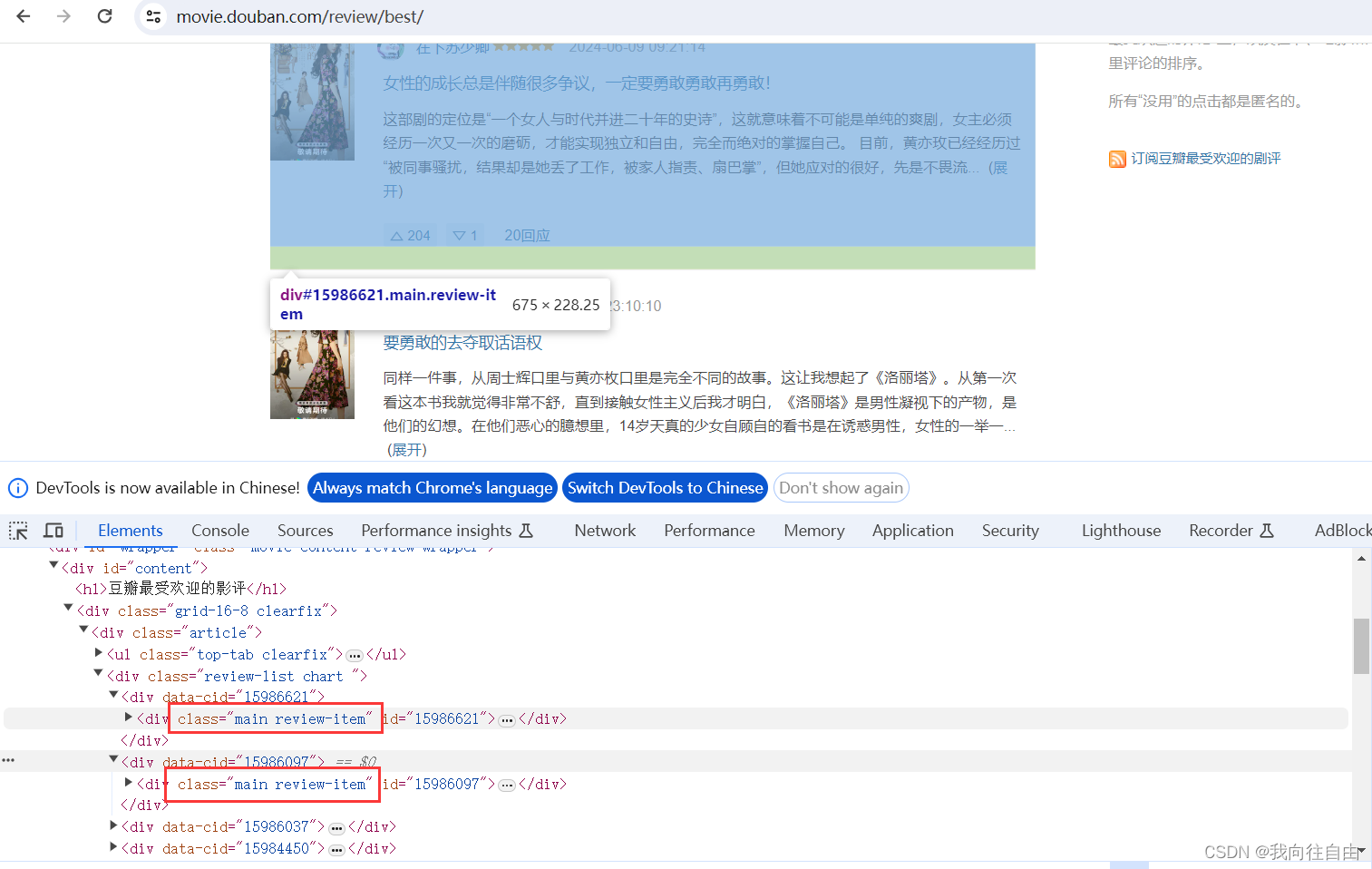
我们需要爬取这些影评
二、编写代码
我们发现每个影评所在的div的class都相同,我们可以从这入手
from bs4 import BeautifulSoup
import requests
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
url = 'https://movie.douban.com/review/best/'
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
div = soup.find_all('div', class_='main review-item') # 找到每个影评的div,返回所有影评div列表
for d in div:
# 获取所有img标签
img = d.img
# 获取硬盘标题
title = d.h2.string
# 获取影评
con = list(d.find('div', class_="short-content").stripped_strings)[0]
print(con)