先来说实现逻辑,首先我要获取到这个网站上所有的信息,那么我们就可以开始对元素进行检查
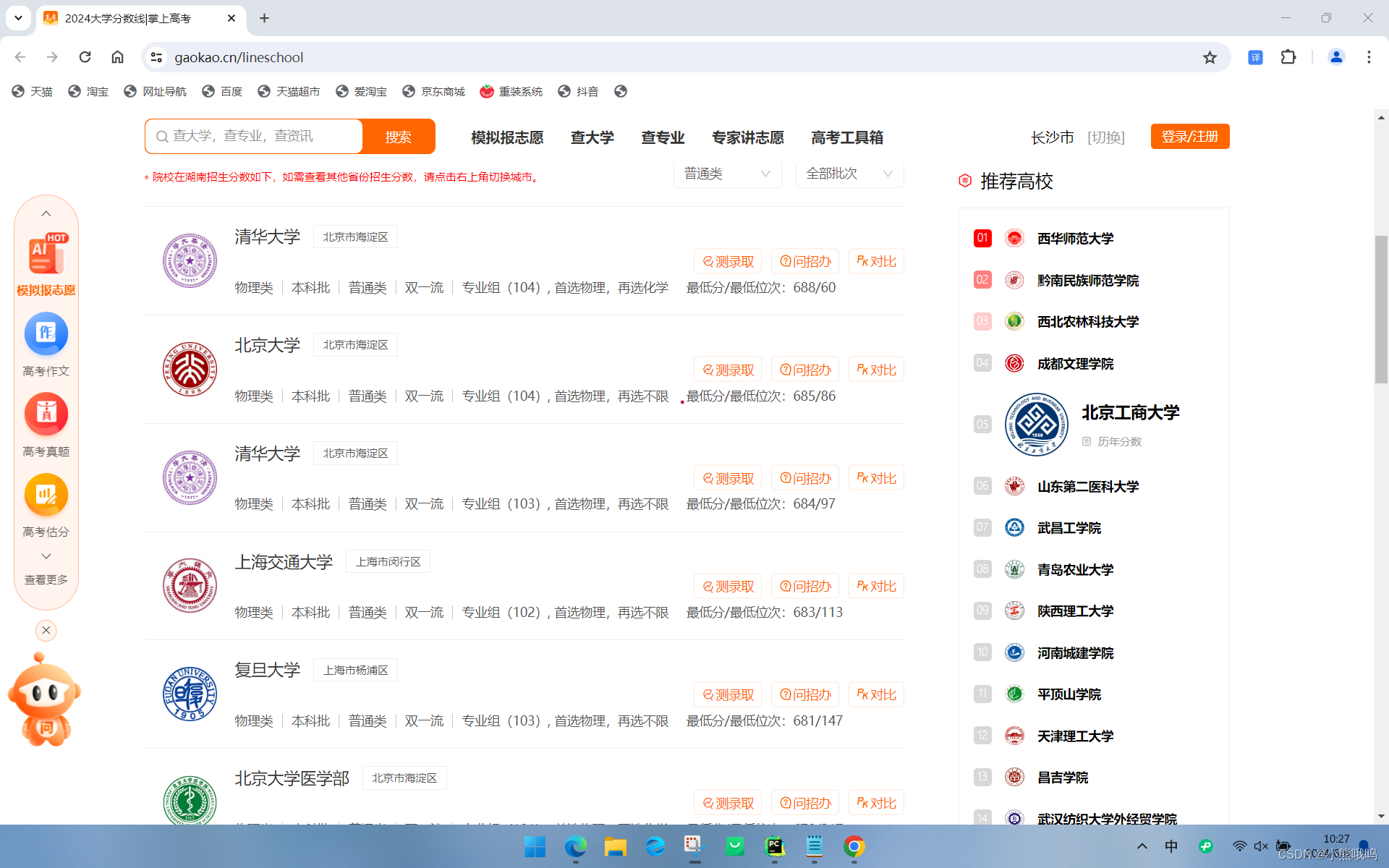
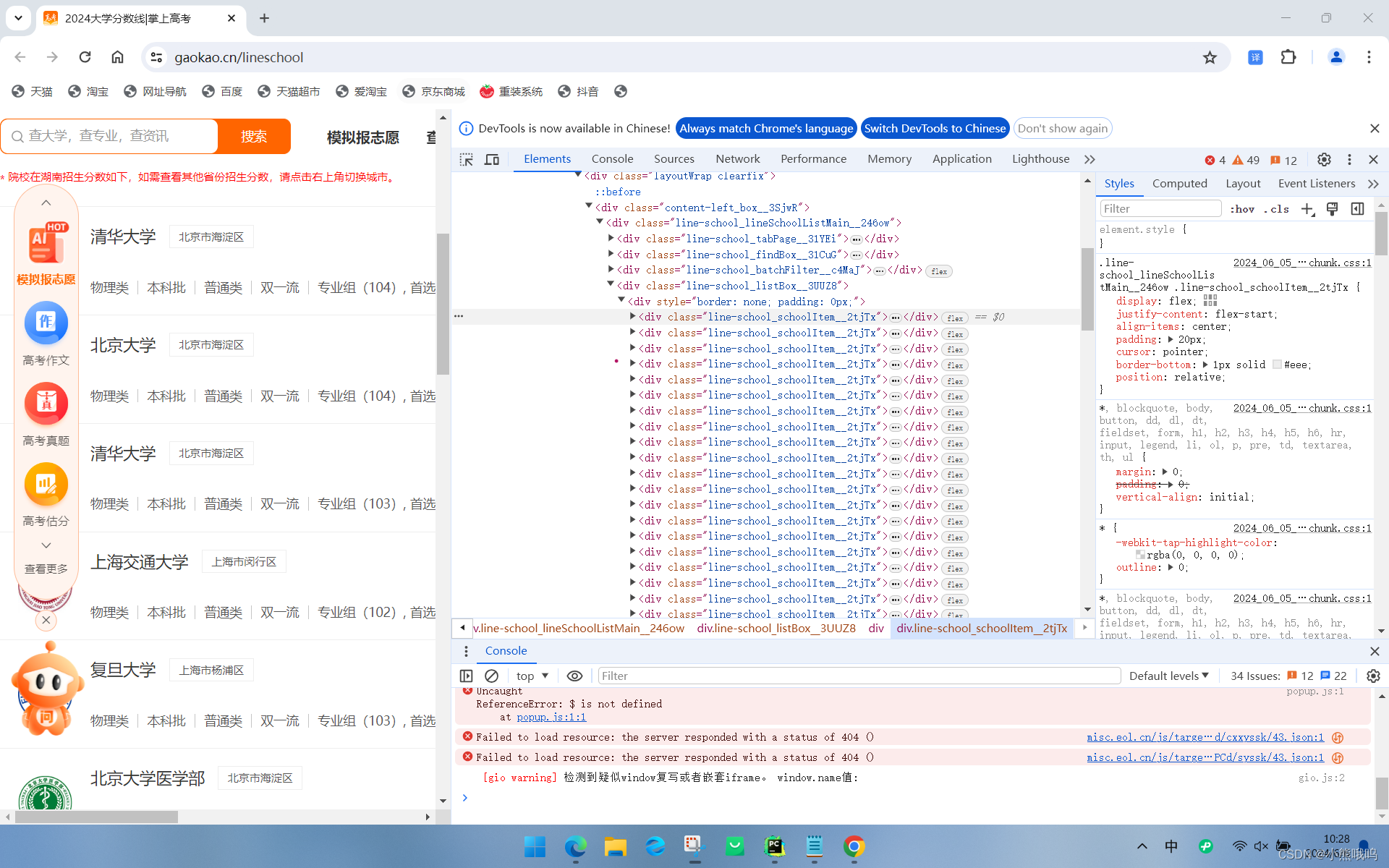 我们发现他的每一个学校信息都有一个对应的属性,并且是相同的,那么我们就可以遍历这个网页中的所有属性一样的开始爬取
我们发现他的每一个学校信息都有一个对应的属性,并且是相同的,那么我们就可以遍历这个网页中的所有属性一样的开始爬取
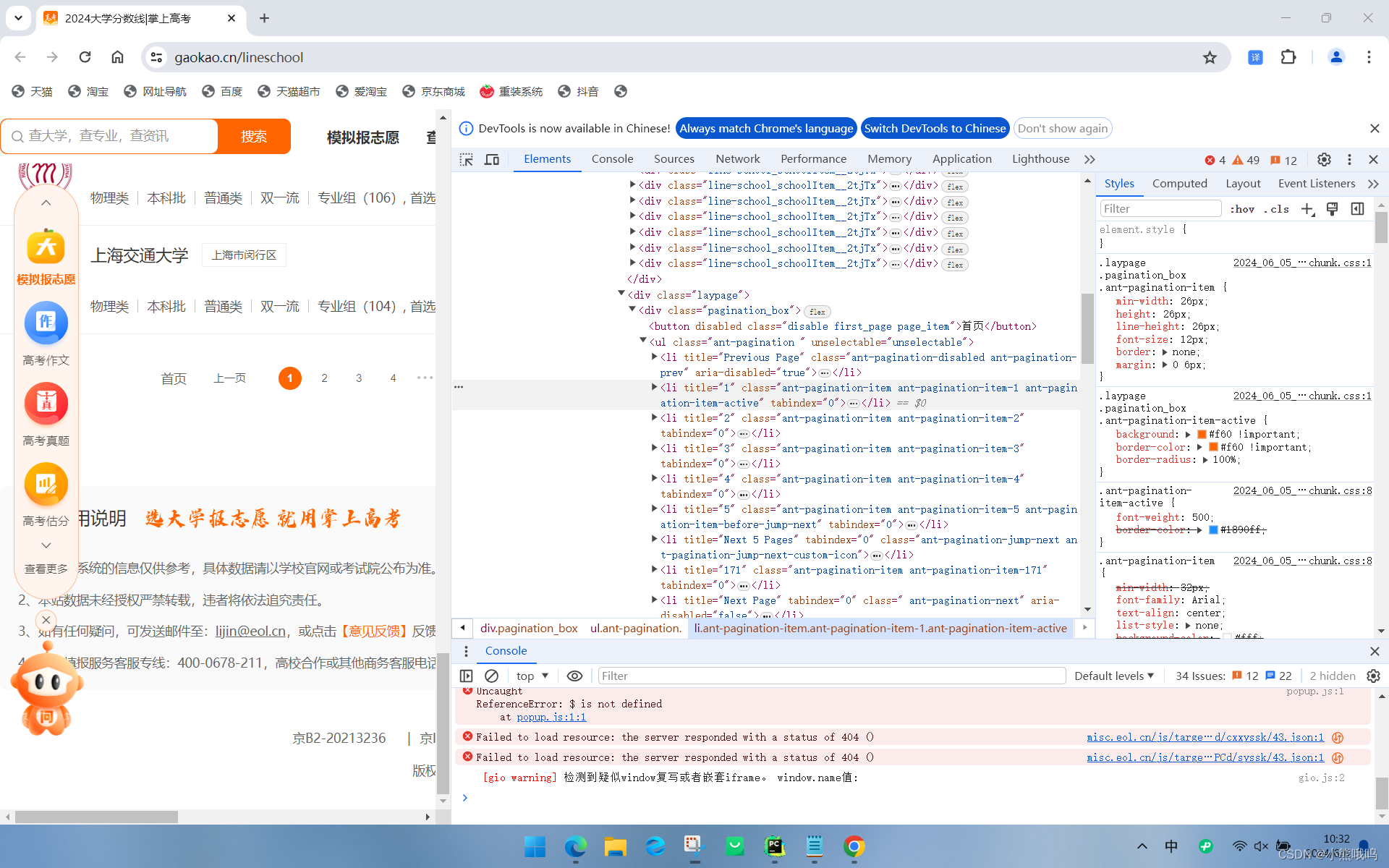
在来分析,我们会发现,是不是我们不只是要获取到一页的数据,我们要获取这个网站上所有的大学数据对吧,那么我们就要获取到这个按钮然后通过模拟用户操作webdriver,来模拟用户点击执行,然后在对这个数据来进行保存,当然这个数据是保存到数据库中的
import time
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
url = "https://www.gaokao.cn/lineschool"
driver.get(url)
try:
# 等待直到元素加载完成
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "ant-btn-primary"))
)
# 点击按钮
element.click()
except TimeoutException:
pass
# 提取学校信息
school_infos = driver.find_elements(By.CLASS_NAME, "line-school_schoolInfo__1sdvn")
# 初始化列表用于存储提取的信息
school_data = []
# 循环执行点击操作
for i in range(3):
print("第" + str(i))
# # 将页面滚动到最底部
# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 点击下一页
next_page_element = driver.find_element(By.CLASS_NAME, "ant-pagination-next")
next_page_element.click()
try:
driver.find_element(By.CLASS_NAME, "login-popup_wordIcon__ljiP9").click()
password_login_element = driver.find_element(By.XPATH, "//div[@class='login-popup_passwordItem__OouFG']")
password_login_element.click()
time.sleep(2)
name = driver.find_element(By.CSS_SELECTOR, ".login-popup_inputItem__29c36 .undefined ")
name.send_keys("15573491551")
password_input_element = driver.find_element(By.XPATH, "//input[@type='password']")
password = "Tjt987666"
password_input_element.send_keys(password)
# 找到复选框并点击选中
checkbox_element = driver.find_element(By.XPATH, "//input[@type='checkbox']")
checkbox_element.click()
# 获取到点击按钮
driver.find_element(By.CLASS_NAME, "login-popup_loginBtn__3buCc ").click()
except TimeoutException:
print("没有继续下一步")
school_infos = driver.find_elements(By.CLASS_NAME, "line-school_schoolInfo__1sdvn")
# 遍历每个学校信息
for school_info in school_infos:
print("数据执行")
# 提取学校名称和所在城市信息
name_element = school_info.find_element(By.CSS_SELECTOR, ".line-school_schoolName__1Zk8b em")
city_element = school_info.find_element_by_class_name("line-school_cityName__VnOjC")
school_name = name_element.text
city_name = city_element.text
# 提取标签信息
tags_elements = school_info.find_elements_by_class_name("line-school_tagName__1Hr9k")
tags_text = [tag.text for tag in tags_elements]
# 获取最后一个 span 标签的文本值
last_span_text = school_info.find_element(By.XPATH,
".//div[@class='line-school_tags__3Cdah']//span[last()]").text
# 提取数字部分
score_value = last_span_text.split(":")[-1]
# 存储学校信息为元组
school_tuple = (school_name, city_name, tags_text, score_value)
# 将元组添加到列表中
school_data.append(school_tuple)
for school_tuple in school_data:
print(school_tuple)


![[HNCTF 2022 WEEK4]flower plus](https://img-blog.csdnimg.cn/img_convert/684174ef3acaf22317e426244003b48f.png)