1、常用命令
1.1、ls
| 选项 | 说明 |
| -a | 显示所有文件及目录 (包括隐藏文件) |
| -i | 显示inode |
| -A | 同 -a选项 ,但不列出 "." (目前目录) 及 ".." (父目录) |
| -l | 列出信息详细(如文件型态、权限、拥有者、文件大小等) |
| -R | 递归显示(若目录下有文件,则以下之文件亦皆依序列出) |
| -r | 反序显示(将文件以相反的次序显示)。 |
| -F | 符号显示(普通文件不添加后缀,对可执行文件添加*号,为目录添加/号,为符号链接添加@号) 使用ls -F|grep "*"可以查找可执行文件 使用ls -F|grep "/" 可以查找目录 |
| -t | 按时间排序(从先到后) |
1.2、stat
1.2、cd
| 命令 | 说明 |
| cd /绝对路径 | 指定绝对路径 |
| cd / | 根目录 |
| cd .. | 回到上级目录 |
| cd ~ | 回到用户家目录 |
| cd - | 回到上次的目录 |
1.3、pwd
| 命令 | 说明 |
| pwd | 显示当前路径 |
| pwd -P | 显示出实际路径(如果当前路径是软链接,显示链接目录的实际路径) |
1.4、mkdir
| 选项 | 说明 |
| -m | 设置文件模式 |
| -p | 一次建立多个目录(若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录) |
1.5、rm
| 选项 | 说明 |
| -f | 强制删除 |
| -r | 递归删除 |
| -i | 交互式删除 |
1.6、rmdir
删除空目录
1.7、mv
| 选项 | 说明 |
| -f | 强制执行 |
| -i | 交互式 |
| -b | 若需覆盖文件,则覆盖前先行备份。 |
| -u | 若目标文件已经存在,且源文件比较新,才会更新(update) |
1.8、cp
| 选项 | 说明 |
| -f | 强制复制 |
| -i | 交互复制 |
| -l | 硬链接文件,而不是复制。 |
| -d | 复制时保留链接。 注:一般用于复制库文件,以保留链接关系!!! |
| -p | 除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。 |
| -R | 递归复制(复制目录及目录内的所有项目)。 |
| -a | 此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。 |
1.9、touch
新建一个不存在的文件。
1.10、nl
计算文件中行号
| 选项 | 说明 | |
| -b | a | 表示不论是否为空行,也同样列出行号(类似 cat -n) |
| t | 如果有空行,空的那一行不要列出行号(默认值) | |
| -n | ln | 行号在萤幕的最左方显示; |
| rn | 行号在自己栏位的最右方显示,且不加 0 ; | |
| rz | 行号在自己栏位的最右方显示,且加 0 ; | |
| -w | 行号栏位的占用的位数 | |
1.10、wc
统计文件字数信息
| -c | 以字节(byte)来计数 |
| -m | 以字符(char)来计数 |
| -w | 以词(word)来计数 |
| -l | 以行(line)来计数 |
| -L | 显示最长的一行 |
当不使用任何选项来运行 wc 命令时,wc 命令输出了四个字段
行数 词数 字节数 文件名称1.11、chmod
| 符号模式 | |
| u | user(文件拥有者) |
| g | group(文件所有者所在组) |
| o | others(所有其他用户) |
| a | all(所用用户, 相当于 ugo) |
| Operator | 说明 |
| + | 为指定的用户类型增加权限 |
| - | 去除指定用户类型的权限 |
| = | 设置指定用户权限的设置,即将用户类型的所有权限重新设置 |
| 选项 | 说明 |
| r(读) | 设置为可读权限 |
| w(写) | 设置为可写权限 |
| x(执行权限) | 设置为可执行权限 |
| X(特殊执行权限) | 只有当文件为目录文件,或者其他类型的用户有可执行权限时,才将文件权限设置可执行 |
| s(setuid/gid) | 当文件被执行时,根据who参数指定的用户类型设置文件的setuid或者setgid权限 |
| t(粘贴位) | 设置粘贴位,只有超级用户可以设置该位,只有文件所有者u可以使用该位 |
1.12、date
| 选项 | 参数 |
| %s | 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数 |
| %Y | 完整年份 (0000..9999) |
| %m | 月份 (01..12) |
| %d | 日 (01..31) |
| %H | 小时(00..23) |
| %M | 分钟(00..59) |
| %S | 秒(00..61) |
1.13、cal
cal [参数][月份][年份]| 选项 | 说明 |
| -j | 显示天数 |
| -y | 输出整年的日历(默认只输出当月的日历) |
1.13、echo
| -e | 开启转义字符 |
| -n | 不换行 |
1.14、xargs
将标准输入的参数作为其指定命令。xargs 的标准输入中出现的“换行符、空格、制表符”都将被空格取代。
注:管道无法实现将前面的标准输出作为后面的“命令参数”!!!有些命令只接受命令行参数中指定的处理内容,不从标准输入中获取处理内容。此时就需要用到xargs啦~
| 选项 | 说明 |
| -0 | 将 NULL 作为分隔符。并将单引号、双引号、反斜线等统统默认为是普通字符。 |
| -d | delim 分隔符,默认的xargs分隔符是空格 |
| -t | 打印出最终要执行的命令 |
| -n num | 执行一次使用的参数个数(默认执行所有)。 |
| -p | 当每次执行一个argument的时候询问一次用户。 |
| -E | 设置逻辑EOF字符串;如果END作为输入行出现,则忽略输入的其余部分(如果指定-0或-d则忽略) |
find命令有一个特别的参数-print0,指定输出的文件列表以null分隔。然后,xargs命令的-0参数表示用null当作分隔符。
还有一个原因,使得xargs特别适合find命令。有些命令(比如rm)一旦参数过多会报错"参数列表过长",而无法执行,改用xargs就没有这个问题,因为它对每个参数执行一次命令。
1.15、alias
| 命令 | 说明 |
| alias | 查看所有别名 |
| alias name | 查看指定别名 |
| alias [name[=value]] | 定义别名 |
注:shell中默认不能使用别名!!!
1.16、unalias
| 命令 | 说明 |
| unalias -a | 取消所有别名 |
| unalias name | 取消定义别名 |
1.17、time
测量命令的执行时间,或者给出系统资源的使用情况。
| 命令 | 说明 |
| time 程序 | Bash的内置命令 |
| \time 程序 | time命令(功能比Bash的内置强) |
注:如果要执行命令本身而非别名,则需在命令前使用反斜线(\)。
1.18、sleep
睡眠一段时间(默认的单位为秒)。
sleep number[smhd]| 选项 | 说明 |
| s | 表示秒 |
| m | 表示分钟 |
| h | 表示小时 |
| d | 表示天 |
1.18.1、毫秒级睡眠
使用小数值
sleep 0.003 //睡眠3ms1.18.2、时间参数组合
sleep 1m 40s //睡眠1分40秒(中间需要有空格分隔)1.19、ln
创建文件链接。
| 选项 | 说明 |
| -s | 软链接(符号链接) |
| -f | 强制执行 |
| -n | 将指向目录的符号链接的目标当作普通文件对待。 |
1.20、file
查看文件类型。
| 选项 | 说明 |
| -b | 不显示文件名称。 |
| -i | 输出文件的 MIME 类型字符串。 |
| -F | 设置输出分隔符 |
| -L | 直接显示符号连接所指向的文件的类别。 |
| -f <名称文件> | 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称。 |
| -z | 尝试去解读压缩文件的内容。 |
1.21、dd
用于读取、转换并输出数据。
| 选项 | 说明 |
| if=文件名 | 输入文件名(默认为标准输入),即指定源文件。 |
| of=文件名 | 输出文件名(默认为标准输出),即指定目的文件。 |
| count=blocks | 指定块数量。 |
| bs=bytes | 同时设置读入/输出的块大小为bytes个字节。 |
| ibs=bytes | 一次读入bytes个字节,即指定一个块大小为bytes个字节。 |
| obs=bytes | 一次输出bytes个字节,即指定一个块大小为bytes个字节。 |
| skip=blocks | 从输入文件开头跳过blocks个块后再开始复制。 |
| seek=blocks | 从输出文件开头跳过blocks个块后再开始复制。 |
| conv=notrunc | 不截短输出文件 |
1.22、cut
剪切文件中的数据
注:cut 只擅长处理“以一个字符间隔”的文本内容。
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]| 选项 | 说明 |
| -b | 以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 |
| -c | 以字符为单位进行分割。 |
| -d | 自定义分隔符,默认为制表符。 注:cut 只允许间隔符是一个字符。 |
| -f | 与-d一起使用,指定显示哪个区域。 |
| -n | 取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的 范围之内,该字符将被写出;否则,该字符将被排除 |
1.22.1、定位数字的设置
1)多个定位数字之间还可以用逗号隔开 n1,n2,n3
2)最大定位数 -n
3)最小定位数 n-
1.23、split-切割(拆分)文件
split [-b ][-C ][-][-l ][要切割的文件][输出文件名前缀][-a ]| 常用参数 | 描述 |
| -b<字节> | 指定按多少字节进行拆分,也可以指定 K、M、G、T 等单位。 |
| -<行数>或-l<行数> | 指定每多少行要拆分成一个文件。 |
| 输出文件名前缀 | 设置拆分后的文件的名称前缀,split 会自动在前缀后加上编号,默认从 aa 开始。 |
| -a<后缀长度> | 默认的后缀长度是 2,也就是按 aa、ab、ac 这样的格式依次编号。 |
| -d | 指定数字形式的文件后缀 |
1.24、paste-合并文件的列
将几个文件的相应行用制表符连接起来,并输出到标准输出。
paste [-s][-d <间隔字符>][--help][--version][文件...]| 常用参数 | 描述 |
| -d<间隔字符> | 用指定的间隔字符取代制表符。 |
| -s | 串列进行而非平行处理。 |
1.25、watch
| 选项 | 说明 |
| -n | 指定执行间隔(默认间隔为2秒) |
| -d | 把变动过的地方高亮显示。 |
1.26、diff
用于比较文件的差异。
diff file1 file2| 符号 | 说明 |
| c | 有区别 |
| a | file2与file1比有新增 |
| d | file2比file1 比有删除 |
1.27、vi
| 命令 | 说明 |
| :s/旧内容/新内容/ | 替换。只替换当前行中第一个匹配到的内容 |
| :s/旧内容/新内容/g | 替换。替换当前行中所有匹配到的内容 |
| :1,$s/旧内容/新内容/g | 全局替换(第一行到最后一行)。替换所有匹配到的内容 |
| :%s/旧内容/新内容/g |
1.28、tr
用于转换或删除文件中的字符。
注:可以使用dd和tr命令生成全ff的文件
1.29、md5sum
用于生成和校验文件的md5值。
| 选项 | 说明 |
| -b | 以二进制模式读入文件内容 |
| -t | 以文本模式读入文件内容 |
| -c | 根据已生成的md5值,对现存文件进行校验 |
1.30、sort
| 选项 | 说明 |
| -n | 依照数值的大小排序。 |
| -u | 去重 |
| -r | 降序排序(默认升序)。 |
| -o<输出文件> | 将排序后的结果存入指定的文件。 |
| -t<分隔字符> | 指定排序时所用的栏位分隔字符。 |
| -k[ field1[,field2]] | 按指定的列进行排序。 |
1.31、read
用于读取值。
1)如果输入的数据数量少于变量的个数,那么多余的变量不会获取到数据,即变量值为空。
2)如果输入的数据数量多于变量的个数,那么超出的数据将都赋值给最后一个变量。
3)如果 read 命令后面没有写任何变量,数据会存放到一个叫作 $REPLY 的变量中。
| 选项 | 说明 |
| -p | 输入提示文字 |
| -n | 输入字符长度限制 |
| -t | 输入限时 |
| -s | 隐藏输入内容 |
| -u | 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的。 |
| -r | 屏蔽\,如果没有该选项,则\作为一个转义字符,否则\为普通字符。 |
1.32、expr
1.32.1、书写规则
1) 用空格隔开每个项。
2) 将反斜杠(\)放在 Shell 特殊字符前面。
3) 对包含空格和其他特殊字符的字符串用引号括起来。
1.32.2、四则运算运算
加减乘除
1.32.3、 字符串运算
| 运算 | 表达式 | 意义 |
|---|---|---|
| match | match STRING REGEXP | STRING 中匹配 REGEXP 字符串并返回匹配 字符串的长度 |
| substr | substr STRING POS LENGTH | 从 POS 位置获取长度为 LENGTH 的字符串 |
| index | index STRING SUBSTR | 杳找子字符串的起始位置 |
| length | length STRING | 计算字符串的长度 |
2、查看文件
2.1、cat
| 常用功能 | |
| cat 文件 | 显示文件 |
| cat > 文件 | 创建文件(只能创建新文件,不能编辑已有文件) |
| cat file1 file2 > file | 文件合并 |
| 选项 | 说明 |
| -n | 显示行号 |
| -b | 和 选项-n 相似,只不过对于空白行不编号。 |
| -s | 当遇到有连续两行以上的空白行,就代换为一行的空白行。 |
| -v | 使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外 |
| -E | 在每行结束处显示 $ |
| -T | 将 TAB 字符显示为 ^I |
| -A | 等价于 -vET |
| -e | 等价于"-vE"选项 |
| -t | 等价于"-vT"选项 |
2.2、tail
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
| 选项 | 说明 |
| -f | 当文件增长时,输出追加的数据; |
| -v | 显示文件名 |
| -c<字节> | 显示字节数 |
| -n<行数> | 显示的行数 |
2.3、head
用来显示文件的开头至标准输出中,默认head命令打印其相应文件的开头10行。
| 选项 | 说明 |
| -v | 显示文件名 |
| -c<字节> | 显示字节数 |
| -n<行数> | 显示的行数 |
2.4、more
功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上。 more会以一页一页的显示方便使用者逐页阅读。more会在启动时加载整个文件。
| 命令参数 | |
| +n | 从笫n行开始显示 |
| -n | 定义屏幕大小为n行 |
| +/pattern | 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示 |
| -c | 从顶部清屏,然后显示 |
| -s | 当遇到有连续两行以上的空白行时,就替换为一行的空白行。 |
| 常用操作 | |
| Enter | 向下n行(默认为1行)。 |
| 空格键 | 向下滚动一屏 |
| Ctrl+B | 返回上一屏 |
| = | 输出当前行的行号 |
| :f | 输出文件名和当前行的行号 |
2.5、less
less 与 more 类似, less 在查看之前不会加载整个文件。
2.6、od
od 命令是一个用于显示文件内容的工具,它可以以多种格式(如八进制、十进制、十六进制、ASCII编码等)显示文件内容。
| -c | 以字符方式显示文件,不显示十六进制数据。 |
| -d | 以有符号十进制整数方式显示文件。 |
| -f | 以浮点数方式显示文件。 |
| -h | 以十六进制方式显示文件。 |
| -s | 从指定偏移量开始显示文件,可与-n选项合用。 |
| -N | 仅显示文件的前n个字节,可与-s选项合用。 |
| -A | 选择以何种基数表示地址偏移(d for decimal, o for octal, x for hexadecimal or n for none) |
| -w | 设置每行显示的字节数,BYTES 缺省为 32 字节 |
2.7、hexdump
3、查找相关
3.1、which
会在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
3.2、find
| 选项 | 说明 |
| -name name, | 文件名称符合 name 的文件。 |
| -iname name | 文件名称符合 name 的文件(忽略大小写)。 |
| -type 文件类型 | d: 目录 c: 字型文件 b: 块文件 p: 管道 f: 一般文件 l: 符号链接 s: socket |
| -size n | 文件大小 是 n 单位 |
| -atime n | 在过去n天内被读取过的文件 |
| -ctime n | 在过去n天内被修改过的文件 |
3.3、whereis
该指令只能用于查找二进制文件、源代码文件和man手册页,一般文件的定位需使用locate命令。
| 选项 | 说明 |
| -b | 只查找二进制文件 |
| -m | 只查找说明文件 |
| -s | 只查找原始代码文件。 |
注:和find相比,whereis查找的速度非常快,这是因为linux系统会将 系统内的所有文件都记录在一个数据库文件中,当使用whereis和locate时,会从数据库中查找数据,而不是像find命令那样,通过遍历硬盘来查找。 但是该数据库文件并不是实时更新,因此,在用whereis和locate 查找文件时,有时会找到已经被删除的数据,或者刚刚建立文件,却无法查找到,原因就是因为数据库文件没有被更新!!!
3.4、locate
用于查找符合条件的文档,他会去保存文档和目录名称的数据库内,查找合乎范本样式条件的文档或目录。
注:locate 与 find 不同: find 是去硬盘找,locate 只在 /var/lib/slocate 资料库中找。
4、网络相关
4.1、ping
| 选项 | 说明 |
| -c<次数> | 设置完成要求回应的次数。 |
| -i<间隔秒数> | 指定收发信息的间隔时间。 |
| -s<数据包大小> | 设置数据包的大小。 |
| -t<数值> | 设置TTL的大小。 |
4.2、scp
scp [参数] [原路径] [目标路径]| 选项 | 说明 |
| -r | 递归复制整个目录 |
| -P port | port是指定数据传输用到的端口号 |
| -p | 保留原文件的修改时间,访问时间和访问权限。 |
| -1 | 强制scp命令使用协议ssh1 |
| -2 | 强制scp命令使用协议ssh2 |
| -4 | 强制scp命令只使用IPv4寻址 |
| -6 | 强制scp命令只使用IPv6寻址 |
4.3、netstat
4.4、ss
ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
| -s | 显示套接字使用概况 |
| -a | 显示所有套接字 |
| -t | 仅显示 TCP套接字 |
| -u | 仅显示 UCP套接字 |
| -w | 仅显示 RAW套接字 |
| -x | 仅显示 Unix套接字 |
| -p | 显示使用套接字的进程 |
4.5、traceroute
4.6、route
4.7、ifconfig
ifconfig wlan0 up
5、进程相关
5.1、kill
| 选项 | 说明 |
| -l | 列出所有信号 |
| -信号 进程PID | 向进程发送信号 |
5.2、killall
用来结束同名的的所有进程
| -信号 进程名 | 向进程发送信号 |
5.3、ps
一般使用如下命令即可:
-a显示由其他用户所拥有的进程的状态
-x显示没有控制终端的进程状态
-j显示与作业有关的信息(会话ID、进程组ID、控制终端、终端进程组ID)
-u指定用户的所有进程
在ps的输出中,内核守护进程的名字出现在方括号中
ps aux
ps -ef5.4、nohup
用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
注:一般搭配&一起使用。
6、系统资源
6.1、top
| 选项 | 说明 |
| -i<时间> | 设置间隔时间 |
| -n<次数> | 循环显示的次数 |
| 操作 | |
| 1 | 在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况: |
| 2 | 敲击键盘“b”(打开/关闭加亮效果),运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。 |
| 3 | 敲击键盘“x”(打开/关闭排序列的加亮效果) |
6.2、uptime
显示系统已经运行了多长时间,它依次显示下列信息:当前时间、系统已经运行了多长时间、有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
6.3、du
用于显示目录或文件的大小。
| 选项 | 说明 |
| -h | 以K,M,G为单位,提高信息的可读性。 |
| --block-size=SIZE | 按大小缩放; |
| -s | 计算总和 |
| -c | 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。 |
| --max-depth=<目录层数> | 控制深度。超过指定层数的目录后,予以忽略。 |
| -a | 显示目录中所有文件的大小。 注:默认情况下,du 命令只会关心文件夹,输出的都是文件夹的空间使用量,而不会关注单个文件。 |
| --exclude | 过滤指定的目录或文件。 |
| 单位 | |
| 1 | 如果通过 --block-size 选项设置了块大小,则会成为du 输出信息的单位。 |
| 2 | 假如上一条没满足,且设置了环境变量 DU_BLOCK_SIZE,则会成为du 输出信息的单位。 |
| 3 | 假如上两条都没满足,且设置了环境变量 BLOCK_SIZE,则这会成为du 输出信息的单位。 |
| 4 | 假如前三条都没满足,且设置了环境变量 BLOCKSIZE,则这会成为du 输出信息的单位。 |
| 5 | 假如前四条都没满足,且开启了环境变量 POSIXLY_CORRECT,则 du 输出信息的单位会是 512bytes。 |
| 6 | 假如前面的五条都没满足,那么 du 的输出信息的单位就是 1024 bytes。 |
6.4、df
用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计。
df -h6.5、free
显示内存使用情况。
| 选项 | 说明 |
| -b | 以Byte为单位显示内存使用情况。 |
| -k | 以KB为单位显示内存使用情况。 |
| -m | 以MB为单位显示内存使用情况。 |
| -g | 以GB为单位显示内存使用情况。 |
| -s<间隔秒数> | 持续观察内存使用状况。 |
6.8、who
用于显示系统中有哪些使用者。显示的内容包含了使用者 ID、使用的终端机、从哪边连上来的、上线时间、呆滞时间、CPU 使用量、动作等等。
| 选项 | 说明 |
| -H | 显示各栏位的标题信息列 |
6.9、whoami
用于显示自身用户名称。
7、压缩
7.1、gzip
gzip命令是.gz文件的压缩程序。只能针对普通文件进行压缩和解压,对于文件夹、符号链接等是不支持的!!!
注:gzip命令在压缩过程中,不保留原始文件。
gzip 文件| 选项 | 说明 |
| -d | 解压缩文件 |
| -c | 把压缩的内容输出到标准输出 |
| -<压缩效率> | 压缩效率是一个介于1-9的数值,预设值为"6",指定越大的数值,压缩效率就会越高(压缩需要的时间也更久)。 |
| -v | 显示指令执行过程 |
| -l | 列出压缩文件的相关信息 |
7.1.1、与tar结合使用
| 命令 | 说明 |
| tar -xzvf 压缩文件.tar.gz | 解压拆包 |
| tar -czvf 压缩文件.tar.gz 源文件 | 打包压缩 |
| tar -tzvf 压缩文件.tar.gz | 不解压,看看内容 |
7.2、bzip2
bzip2命令是.bz2文件的压缩程序。只能针对普通文件进行压缩和解压,对于文件夹、符号链接等是不支持的!!!
注:bzip2命令在压缩过程中,不保留原始文件。
bzip2 文件| 选项 | 说明 |
| -d | 解压缩文件 |
| -c | 把压缩的内容输出到标准输出 |
| -v | 显示指令执行过程 |
| -t | 测试.bz2压缩文件的完整性 |
7.2.1、与tar结合使用
| 命令 | 说明 |
| tar -xjvf 压缩文件.tar.gz | 解压拆包 |
| tar -cjvf 压缩文件.tar.gz 源文件 | 打包压缩 |
| tar -jtvf 压缩文件.tar.gz | 不解压,看看内容 |
7.3、zip
zip 命令在压缩过程中,会保留原始文件。
zip 压缩文件.zip 文件| 选项 | 说明 |
| -r | 递归处理,将指定目录下的所有文件和子目录一并处理。 |
| -v | 显示指令执行过程或显示版本信息。 |
| -d | 从压缩文件内删除指定的文件。 |
7.4、unzip
用于解压缩zip文件
| 选项 | 说明 |
| -d | 指定解压目录 |
| -v | 不解压,只想查看内容 |
| -t | 检查压缩文件是否正确。 |
| -l | 显示压缩文件内所包含的文件 |
8、开发常用
8.1、history
查看和执行历史命令.
| 命令 | 说明 |
| history | 查看和执行历史命令 |
| history -c; history -w | 删除所有的历史命令 history -c//删除的只是 Linux 系统内存中的历史命令 |
8.1.1、定位命令
| 方法 | 说明 |
| 叹号定位法 | 使用!值来定位指定命令 |
| 搜索定位 | 按下 Ctrl+r 快捷键后,进入了反向搜索状态,此时输入字符,系统会找到最近一个包含这个字符的命令,再次按下 Ctrl + R,会继续向前搜索。 |
8.1.2、history的配置
| 指令 | 说明 |
| export HISTTIMEFORMAT='%F %T ' | 设置历史记录的时间 |
| export HISTSIZE=数量 | 设置内存中的history命令的个数 |
| export HISTFILESIZE=数量 | 设置文件中的history命令的个数 |
| export HISTFILE=存储文件 | 历史命令的存储位置 |
| export HISTCONTROL=erasedups | 清除整个命令历史中的重复条目 |
| export HISTCONTROL=ignoredups | 忽略记录命令历史中连续重复的命令 |
| export HISTCONTROL=ignorespace | 忽略记录空格开始的命令 |
| export HISTCONTROL=ignoreboth | 等价于ignoredups和ignorespace |
8.1.3、不保留记录
| 方法 | 说明 |
| 方法1 | 当使用这种方式时,以空格开头的命令将不被保留记录。 1)设置 HISTCONTROL 环境变量:export HISTCONTROL=ignorespace。 2)输入命令时,在输入命令前加上空格。 |
| 方法2 | 当使用这种方法时,所有的命令都不保留。 1)设置 HISTIGNORE 环境变量 export HISTIGNORE=* 注:可以使用此方法来保护重要的命令不被别人所看到。输入命令前先export HISTIGNORE=*,输入命令后再export HISTIGNORE= 。 |
8.2、tmux
分屏管理工具。
8.2.1、会话操作
| Session操作 | 说明 |
| 新建会话 | |
| tmux new | 新建默认名称会话 |
| tmux new -s 会话 | 新建指定名称会话 |
| 分离会话 | |
| Ctrl+B d | 分离当前会话 |
| Ctrl+B D | 分离指定会话 |
| 连接会话 | |
| tmux a | 连接上一个会话 |
| tmux a -t | 连接指定会话 |
| tmux ls | 显示会话列表 |
| 重命名 | |
| tmux rename -t 旧会话名 新会话名 | 重命名会话 |
| Ctrl+B $ | 重命名当前会话 |
| 关闭 | |
| tmux kill-server | 关闭所有会话 |
| tmux kill-session | 关闭上次打开的会话 |
| tmux kill-session -t 会话 | 关闭会话 |
| tmux kill-session -a -t s1 | 关闭除s1外的所有会话 |
| 切换 | |
| Ctrl+B s | 列出所有会话 |
2.1.2、窗口操作
| window操作 | 说明 |
| 打开/关闭 | |
| Ctrl+B c | 创建一个新窗口 |
| Ctrl+B & | 关闭当前窗口 |
| tmux kill-window -t 窗口号 | 关闭指定窗口 |
| 切换 | |
| Ctrl+B l | 进入之前操作的窗口 |
| Ctrl+B p | 切换到上一个窗口 |
| Ctrl+B n | 切换到下一个窗口 |
| Ctrl+B 窗口号 | 使用窗口号切换窗口(0~9) |
| Ctrl+B w | 列出所有窗口,进行切换 |
| Ctrl+B ' | 切换至指定编号的窗口(可大于9) |
| 修改 | |
| Ctrl+B , | 重命名当前窗口,便于识别各个窗口 |
| Ctrl+B . | 修改当前窗口索引编号 |
2.1.3、面板操作
| Panel操作 | 说明 |
| Ctrl+B z | 放大当前窗格(再次按下将还原) |
| 打开/关闭 | |
| Ctrl+B % | 横向分Terminal(左右) |
| Ctrl+B " | 纵向分Terminal(上下) |
| Ctrl+B x | 关闭当前窗格 |
| 切换 | |
| Ctrl+B 方向键 | 自由选择各面板 |
| 布局 | |
| Ctrl+B q | 显示面板编号 |
| Ctrl+B 空格键 | 重新排列当前窗口下的所有窗格 |
| Ctrl+B } | 与下一个窗格交换位置 |
| Ctrl+B { | 与上一个窗格交换位置 |
| Ctrl+B Ctrl+o | 逆时针旋转当前窗口的窗格 |
9、grep查找
9.1、grep
| 选项 | 参数 |
| --color | 高亮查找的字符串 |
| -c | 计算符合样式的列数。 |
| -v | 显示不包含匹配文本的所有行。 |
| -n | 显示行号。 |
| -A<显示行数> | 显示后几行。 |
| -B<显示行数> | 显示前几行。 |
| -C<显示行数> | 显示前后几行。 |
| -i | 忽略大小写 |
| -f | 从文件中获取PATTERN |
| -l | 列出文件内容符合指定的样式的文件名称。 |
| -L | 列出文件内容不符合指定的样式的文件名称。 |
| -w | 全词匹配 注:在正则表达式中,通常用尖括号表示一个“词”(使用 |
| -E | 将样式视为拓展正则表达式。 注:等价于egrep |
| -F | 将样式视为固定字符串的列表。 注:等价于fgrep |
9.2、egrep
grep 的正则表达式是基本正则表达式,而 egrep 的正则表达式是扩展正则表达式。
9.3、fgrep
grep 和 egrep 都支持正则表达式,但 fgrep 却不支持正则表达式。
注:当搜索字符串中包含了特殊字符,而这些特殊字符恰好又是正则表达式预留的字符,比如说“^”、“$”等时,就可以使用 fgrep 来避免烦琐的转义了。
9.4、grep、egrep、fgrep的关系
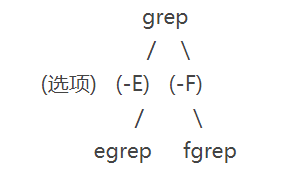
| 命令 | 正则类型 |
| grep | 基本正则表达式 |
| egrep | 拓展正则表达式 |
| fgrep | / |
9.5、pgrep
用来查找进程的信息,通常会和kill命令来连用,在指定条件下kill问题进程。
| 选项 | 说明 |
| -l | 同时显示进程名和PID |
| -o | 当匹配多个进程时,显示进程号最小的那个 |
| -n | 当匹配多个进程时,显示进程号最大的那个 |
10、sed
sed 基础教程 - sed 基础教程 - 简单教程,简单编程
sed [option] [sed-command] [input-file]10.1、范围设定
| 指定行数 | 比如‘3,5’表示第 3行到第5行;而‘5,$’表示第 5 行至文件最后一行。 |
| 模式匹配 | 比如/^[^dD]/表示匹配行首不是以 d 或 D 开头的行。 |
10.2、选项
| 选项 | 说明 |
| -e | 多点编辑。-e选项的后面要立即接 command内容,不允许再夹杂其他选项(按照在命令中的先后顺序执行)。 |
| -f | 指定这个文件作为sed 命令的 command 部分 |
| -n | 仅显示模式缓冲区的内容 |
| -i | 直接修改文件内容 |
| l | 显示不可见字符 |
| r | 读取指定文件的内容。 |
| a | 新增。 |
| d | 删除。 |
| c | 替换。 |
| i | 插入。 |
| p | 打印。 注:通常 p 会与选项n搭配使用 |
| y | 逐字替换。 注:s 支持 & 符号和预存储等特性,可以实现更多灵活的替换效果。 |
| s | 替换,可以搭配正规表示法。 |
| w | 保存。将匹配到的内容写入到另一个文件中。 注:如果 file 参数指定的文件不存在,sed 会新建文件。如果 file 参数指定的文件已经存在,sed 会删除原内容。 |
| q | 使 sed 命令在第一次匹配任务结束后,退出 sed 程序,不再进行对后续数据的处理。 |
& 字符,在 sed 命令中,它表示的是“之前被匹配的部分”
sed 的预存储技术,命令中被“(”和“)”括起来的内容会被依次暂存起来,存储到 \1、\2…里面。这样你就可以使用‘\N’形式来调用这些预存储的内容了。
10.3、定位行范围
/首/,/尾/10.4、 数据的搜寻并执行命令
'/搜索的内容/{执行的命令}'11、awk
12、查看ascii表
man ascii
13、查看Linux内核和发行版本信息
查看内核版本:uname -a
查看发行版:cat /etc/issue
13.1、uname
| 选项 | 说明 |
| -a | 显示全部的信息。 |
| -m | 显示机器类型 |
| -n | 显示主机名称 |
| -r | 显示操作系统的发行编号 |
| -s | 显示操作系统名称 |
| -v | 显示操作系统的版本 |
6.7、arch
显示显示机器类型,相当于uname -m
ulimit
pipe的大小和测试的不一样?


IPC
ipcs输出有关System V IPC特性的各种信息,ipcrm则删除一个SYstem V消息队列、信号量或共享内存区。
ipcs -q 消息队列
ipcs -m 共享内存
XXX、/etc目录
/etc/issue 发行版