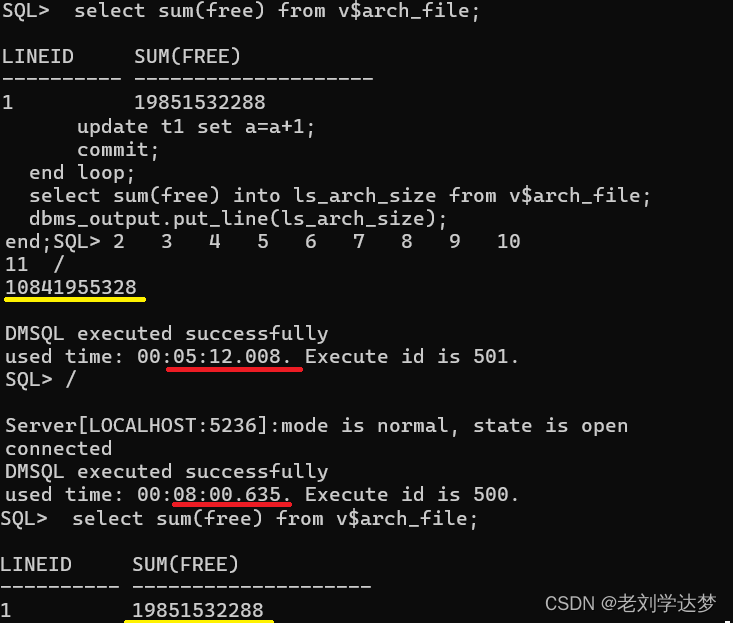
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
汇总合集:
《AIGC 面试宝典》(2024版) 发布!
《大模型面试宝典》(2024版) 发布!
在我们不断追求更准确、更可靠的语言模型(LM)的过程中,创新的方法如检索增强生成(RAG)正在兴起。
然而,对检索到的文档的依赖性带来了相关性和准确性的挑战,迫切需要增强鲁棒性。
在本文中,我们很高兴探讨三个开创性框架的结合:纠正性检索增强生成(CRAG)、自反性检索增强生成(Self-RAG)和自适应QA框架Langchain的LangGraph,这三者共同重新定义了语言模型的能力。
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2040,备注:技术交流+CSDN
定义
我们将结合RAG论文中的思想形成一个RAG代理:
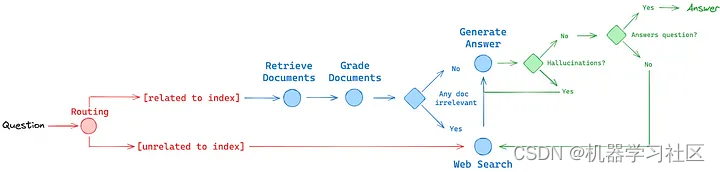
路由:自适应RAG(论文):该框架能够动态路由问题到不同的检索方法,确保检索到最相关的信息以生成响应。
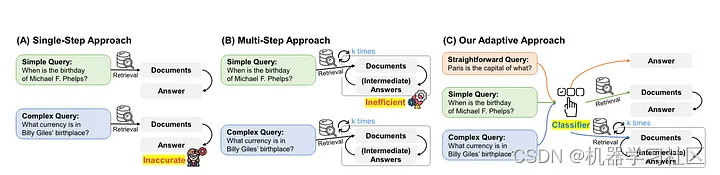
回退:纠正RAG(论文):如果文档被认为与查询不相关,该机制会无缝地回退到网络搜索,确保生成准确且有上下文相关的响应。
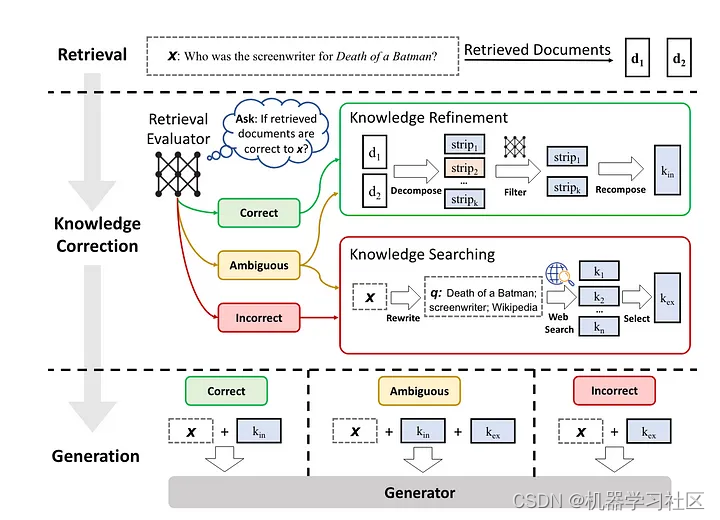
自我纠正:Self-RAG(论文):通过在LM生成中引入自我反思,该框架使模型能够修正受幻觉影响或不回答问题的答案,从而增强各项任务的事实性和多功能性。
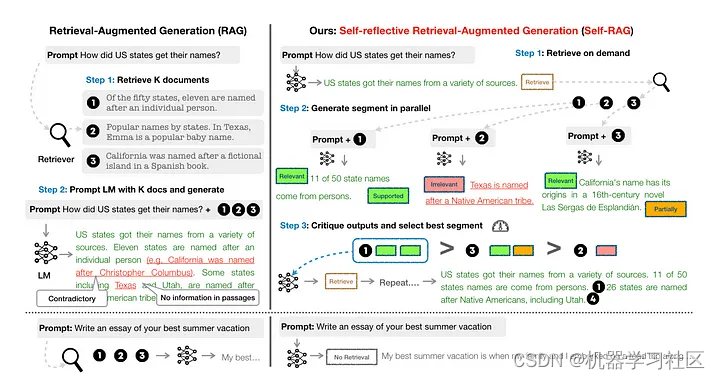
通过将LangGraph纳入RAG框架,LMs能够获得更丰富的知识表示,增强其生成准确且有上下文相关响应的能力。
整合的好处:
将CRAG、Self-RAG、自适应RAG整合到现有语言模型中可以解锁多种好处。
CRAG通过缓解与次优检索相关的不准确性,增强了基于RAG的方法的鲁棒性,确保生成响应的可靠性。
Self-RAG通过引入自我反思,革命性地提升了LM的能力,显著增强了各项任务的事实性和多功能性。
自适应RAG提供了一个动态解决方案,以应对用户查询的复杂性,优化多个数据集的效率和准确性。
代码实现
让我们深入了解如何使用CRAG、Self-RAG、自适应RAG与Langchain的LangGraph。
以下是步骤:
步骤一:安装库
!pip install -U langchain-nomic langchain_community tiktoken langchainhub chromadb langchain langgraph tavily-python langchain-nomic
# LLM
ollama pull llama3
local_llm = 'llama3'
# Tracing
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] =
步骤二:导入库
### Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import GPT4AllEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=GPT4AllEmbeddings(),
)
retriever = vectorstore.as_retriever()
检索评分
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
prompt = PromptTemplate(
template="""system You are a grader assessing relevance
of a retrieved document to a user question. If the document contains keywords related to the user question,
grade it as relevant. It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explaination.
user
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n assistant
""",
input_variables=["question", "document"],
)
retrieval_grader = prompt | llm | JsonOutputParser()
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
# Output
{'score': 'yes'}
生成
from langchain.prompts import PromptTemplate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = PromptTemplate(
template="""system You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise user
Question: {question}
Context: {context}
Answer: assistant""",
input_variables=["question", "document"],
)
llm = ChatOllama(model=local_llm, temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
question = "agent memory"
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
## Output
The context mentions that the memory component of an LLM-powered autonomous
agent system includes a long-term memory module (external database) that record
s a comprehensive list of agents' experience in natural language, referred to
as "memory stream". This suggests that the agent has some form of memory or
recall mechanism.
幻觉评分
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template=""" system You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary score 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation. user
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation} assistant""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
答案评分
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""system You are a grader assessing whether an
answer is useful to resolve a question. Give a binary score 'yes' or 'no' to indicate whether the answer is
useful to resolve a question. Provide the binary score as a JSON with a single key 'score' and no preamble or explanation.
user Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question} assistant""",
input_variables=["generation", "question"],
)
answer_grader = prompt | llm | JsonOutputParser()
answer_grader.invoke({"question": question,"generation": generation})
步骤三:路由器
路由器
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
prompt = PromptTemplate(
template="""system You are an expert at routing a
user question to a vectorstore or web search. Use the vectorstore for questions on LLM agents,
prompt engineering, and adversarial attacks. You do not need to be stringent with the keywords
in the question related to these topics. Otherwise, use web-search. Give a binary choice 'web_search'
or 'vectorstore' based on the question. Return the a JSON with a single key 'datasource' and
no premable or explaination. Question
to route: {question} assistant""",
input_variables=["question"],
)
question_router = prompt | llm | JsonOutputParser()
question = "llm agent memory"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
print(question_router.invoke({"question": question}))
# Output
{'datasource': 'vectorstore'}
步骤四:搜索
搜索
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)
步骤五:LangGraph控制流
from typing_extensions import TypedDict
from typing import List
### State
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question : str
generation : str
web_search : str
documents : List[str]
from langchain.schema import Document
### Nodes
def retrieve(state):
"""
Retrieve documents from vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer using RAG on retrieved documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
If any document is not relevant, we will set a flag to run web search
Args:
state (dict): The current graph state
Returns:
state (dict): Filtered out irrelevant documents and updated web_search state
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke({"question": question, "document": d.page_content})
grade = score['score']
# Document relevant
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
# Document not relevant
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
# We do not include the document in filtered_docs
# We set a flag to indicate that we want to run web search
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def web_search(state):
"""
Web search based based on the question
Args:
state (dict): The current graph state
Returns:
state (dict): Appended web results to documents
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}
### Conditional edge
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
print(question)
source = question_router.invoke({"question": question})
print(source)
print(source['datasource'])
if source['datasource'] == 'web_search':
print("---ROUTE QUESTION TO WEB SEARCH---")
return "websearch"
elif source['datasource'] == 'vectorstore':
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or add web search
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
question = state["question"]
web_search = state["web_search"]
filtered_documents = state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---")
return "websearch"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
### Conditional edge
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score['score']
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question,"generation": generation})
grade = score['score']
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("websearch", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
步骤六:图构建
# Build graph
workflow.set_conditional_entry_point(
route_question,
{
"websearch": "websearch",
"vectorstore": "retrieve",
},
)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"websearch": "websearch",
"generate": "generate",
},
)
workflow.add_edge("websearch", "generate")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "websearch",
},
)
# Compile
app = workflow.compile()
# Test
from pprint import pprint
inputs = {"question": "What are the types of agent memory?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
#Output
---ROUTE QUESTION---
What are the types of agent memory?
{'datasource': 'vectorstore'}
vectorstore
---ROUTE QUESTION TO RAG---
---RETRIEVE---
'Finished running: retrieve:'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
'Finished running: grade_documents:'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('According to the provided context, there are several types of memory '
'mentioned:\n'
'\n'
'1. Sensory Memory: This is the earliest stage of memory, providing the '
'ability to retain impressions of sensory information (visual, auditory, etc) '
'after the original stimuli have ended.\n'
'2. Maximum Inner Product Search (MIPS): This is a long-term memory module '
"that records a comprehensive list of agents' experience in natural "
'language.\n'
'\n'
'These are the types of agent memory mentioned in the context.')
结论
总之,CRAG、Self-RAG和自适应RAG的整合代表了语言模型领域的重大进展。这些框架不仅增强了现有模型的可靠性和多功能性,还为未来的
用通俗易懂的方式讲解系列
-
重磅来袭!《大模型面试宝典》(2024版) 发布!
-
重磅来袭!《大模型实战宝典》(2024版) 发布!
-
用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
-
用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
-
用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
-
用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
-
用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
-
用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
-
用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
-
用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
-
用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
-
用通俗易懂的方式讲解:大模型训练过程概述
-
用通俗易懂的方式讲解:专补大模型短板的RAG
-
用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
-
用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
-
用通俗易懂的方式讲解:大模型微调方法总结
-
用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
-
用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
-
用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了
参考链接:https://ai.gopubby.com/unifying-rag-frameworks-harnessing-the-power-of-adaptive-routing-corrective-fallback-and-1af2545fbfb3