
大数据产业创新服务媒体
——聚焦数据 · 改变商业
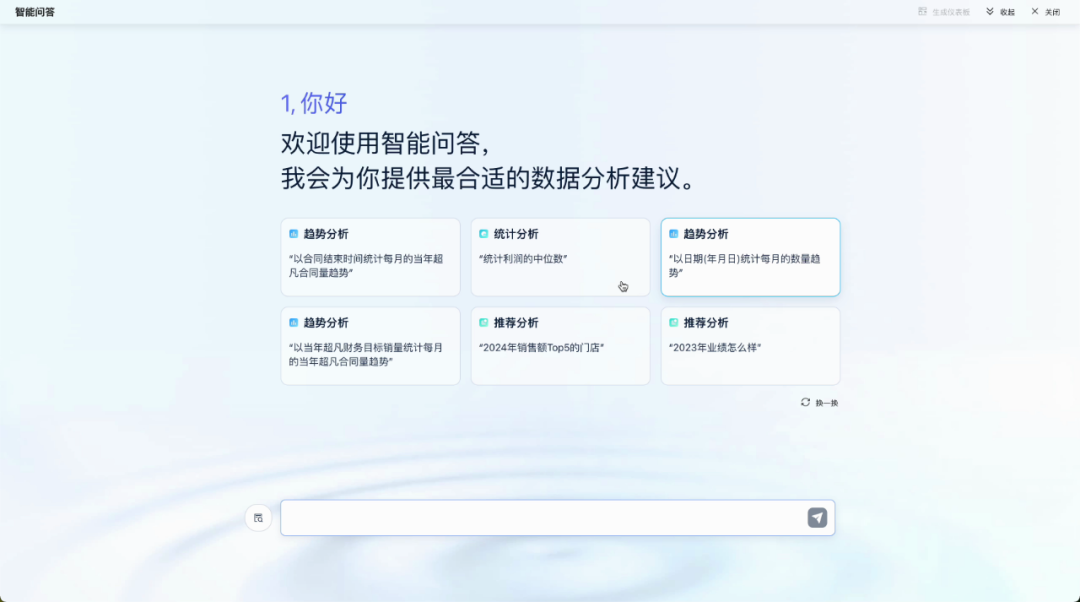
试想一下,假如用户完全不用懂技术,也不需要懂什么数据分析技巧,就可以随心所欲的进行数据分析,该多好。现在,有一个工具可以实现这个设想,那就是基于大模型的对话式BI。
大模型通过其强大的自然语言处理和数据分析能力,能够极大的提升对话式BI的能力,从而进一步降低用户的使用门槛,让更多的业务人员能够直接参与数据分析,帆软最新推出的FineChatBI正是这样一款产品。FineChatBI 将结合报表模式的FineReport和自助模式的FineBI,更加全面的满足不同分析能力的用户,从简单到复杂的数据分析需求,真正实现“让人人都是数据分析师”。
那么,作为一个不爱“赶时髦”的头部BI公司,帆软为什么对此次的大模型+BI如此上心呢?他们是怎么想的,又是怎么做的,踩了哪些坑?而且,跟市面上的对话式数据分析工具不同,帆软将FineChatBI定位于对话式业务分析工具,这里面有什么本质的不同?为了弄清楚这些问题,数据猿专访了帆软的FineChatBI 研发总经理翁林君。
BI持续演进,无线逼近“让人人都是数据分析师”这个愿景
BI产品终极目标是“让人人都是数据分析师”,奔着这个目标 BI 产品持续演进,并发展出不同的产品形态,以满足不同场景的数据需求,具体包括:1)报表式 BI,以复杂报表为核心能力,满足企业管理层固定看数的需求;2)自助式 BI,以数据编辑和拖拉拽搭建为核心能力,满足业务分析师自助分析的需求;3)对话式 BI,以语义理解与对话式交互为核心能力,满足普通业务人员的即时查数与分析需求。
降低用户门槛,是BI发展的不变追求。为了这个目标,BI产品不断吸收新技术,在降低使用门槛的同时,持续提升用户渗透率,让数据分析从少部分人的专利逐步变成普惠的工具。可以说,BI的发展历史,就是一部数据分析底层技术的演进史。为了弄清楚BI的发展方向,我们有必要回顾一下其发展历程。
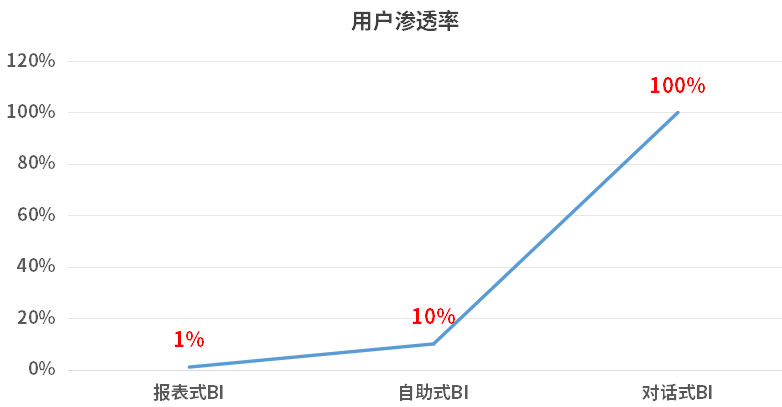
报表式BI,用户要具备 SQL 编写、OLAP 建模等技术能力,渗透率不到1%。
BI起源于20世纪80年代,主要技术包括SQL(结构化查询语言)、OLAP(联机分析处理)和数据可视化。这些技术虽然提供了强大的数据分析能力,但对用户的技术要求极高。用户需要具备SQL编写、数据建模和深厚的业务理解能力,因此,这类 BI 产品的用户主要是IT/DT人员,渗透比例不到1%。
在这一阶段,BI的使用门槛非常高。用户不仅需要掌握复杂的技术,还必须具备数据思维和业务理解能力。这意味着,只有那些既懂技术又懂业务的用户才能真正发挥BI的价值。比如,一名优秀的BI用户需要像DBA(数据库管理员)一样精通SQL,同时也需要像MBA一样具备深入的业务理解能力。这使得BI的普及非常困难,主要集中在少数专业技术人员手中。
自助式BI,不要求 SQL 编写等技术能力,但对数据分析能力要求高,渗透率10%。
进入2000年代,VizQL(Visual Query Language)技术的引入带来了自助式BI的兴起。VizQL技术使用户可以通过可视化界面进行数据操作,而无需编写复杂的SQL代码。这大大降低了BI的技术门槛,让更多的用户能够参与数据分析。然而,尽管技术门槛有所降低,但用户仍需具备数据分析能力。
自助式BI的出现,使得BI的用户群体扩大至除 IT 人员外的一些数据分析师,渗透比例提升至约10%。这一时期的BI工具强调自助服务,用户可以通过拖拽和点击的方式进行数据分析。这种交互方式极大地简化了数据操作,使得更多非技术人员能够使用BI工具。然而,这阶段的BI仍然无法完全摆脱对用户数据思维和业务理解的要求。
进入2010年代,AI技术(如自然语言查询NLQ、自然语言生成NLG、自动洞察AutoInsight)的应用推动了增强BI的发展。增强BI进一步降低了技术门槛,但仍要求用户具备一定的数据思维。增强BI的用户群体进一步扩大,开始包括部分业务人员,渗透比例约为15%。
对话式BI,破除数据思维这个用户门槛,渗透率逼近100%。
整体来看,虽然自助式BI降低了对用户的技术要求,但门槛依然不低,用户仍需掌握一定的技术操作,如数据连接、数据清洗和数据建模等。这对于许多非技术背景的用户来说,依然是一个巨大的障碍。
更重要的是,自助式BI对用户的数据思维有很高的要求。数据思维是指用户能够理解和应用数据来解决业务问题的能力,这不仅需要用户能够从数据中发现问题,还需要他们能够将业务需求转化为数据查询和分析任务。即使有了更智能的BI工具,用户如果不具备数据思维,仍然无法有效使用这些工具。
为了进一步扩大用户适用范围,需要把数据思维这个“门槛”也拆除掉。有什么样的能力,是每个人都具备的呢?不是每个人都具备数据分析技巧,但每个人都能用自然语言来描述自己的业务诉求。如果将数据分析过程,变得像跟朋友交流一样自然,那事情就变得简单了。
对话式BI,为实现这个目标打开了新的方向。基于对话式BI,用户可以通过自然语言问答的方式,来进行数据查询、数据分析等操作,满足自己的业务分析需求。这类工具,不仅不要求用户懂技术,甚至不要求用户懂数据分析,用户只需要知道自己想要分析什么样的业务问题就行。这一下子就打破了数据分析的应用局限,将用户渗透率提升到了近乎100%。

需要指出的是,报表式BI、自助式BI、对话式BI不是简单的替代关系,他们有不同的适用场景和用户群体。当然,将数据分析门槛降低到趋近于零,是一件让人兴奋的事情。
不赶时髦的帆软,为什么这么看重大模型
从上面BI的发展演进历程来看,AI与BI的融合似乎是一个重要的趋势。然而,在很长一段时间,当业界热衷AI概念的时候,帆软似乎对此“不太感冒”。
需要指出的是,尽管帆软在外界很少提及AI,但公司内部一直密切关注AI技术的发展。帆软只是说得很少,但却默默做了很多的探索。
早在2019年,随着国内外厂商纷纷推出“问答式BI”功能,帆软也开始了相关的探索。他们成立了专项攻坚团队,推出了FineAI,并尝试找了一些客户进行内测验证。然而,经过多次尝试之后,帆软发现一个残酷的现实——早期的问答式BI技术面临许多挑战,如模型精度不足、跨场景泛化能力差等问题。这些问题导致问答式BI产品的实际应用效果不佳,用户反馈并不理想。
当时,帆软的技术团队对“问答式 BI”的产品和技术进行了广泛调研,发现当时的问答式BI技术大多采用规则解析或神经网络语言(小)模型加规则解析的方法。这种方法在处理自然语言到SQL转换时存在技术上的局限,导致查询结果的召回率和精度达不到产品化的要求。此外,一些利用端到端(Seq2Seq)方法训练出的模型泛化能力不足,需要针对特定场景准备语料单独训练模型,从而导致实施成本高昂,难以广泛推广。
面对这些挑战,帆软选择暂时终止了问答式BI产品的市场推广,但继续跟踪和研究相关技术。随着大语言模型的出现,帆软看到了新的希望。大模型的跨任务、跨场景的泛化能力,以及涌现出的上下文学习和思维链等新能力,使得实现一个成熟且可落地的问答式BI产品成为可能。
具体来看,大模型之所以能够在自助式业务分析中取得成功,主要解决了两个核心问题:
1.强大的自然语言的理解能力和跨场景泛化能力,让实现一个通用、能落地的问答式BI产品成为可能。
大模型在很多 NLP 任务上都有很好的表现,而且具备跨场景的泛化能力,解决小模型泛化能力不足的问题,有了大模型我们就不需要单独针对每个特定场景准备语料训练模型。这很大程度上降低了研发成本,并提升了产品在不同行业、不同企业的落地效率
2. 将数据分析和业务知识嵌入数据分析工具,大大降低了对用户的数据思维和业务理解能力的要求。
传统BI工具要求用户具备一定数据分析思维和深入的业务知识,才能将业务问题转化为数据分析任务。
大模型内嵌了数据分析的专业知识和不同行业的业务知识,使其能够在数据分析中自动应用这些知识。这意味着,业务用户无需进行专门的数据分析培训,就能通过大模型进行专业的数据分析。
除了行业通用的业务知识,一些企业内部特有的业务知识和业务规则,也可以借助 RAG/RAG-Graph 这样的技术,将检索、知识图谱和大模型等技术结合起来,提升系统对用户意图的理解能力,并将这些业务规则内嵌到数据分析流程中。例如,用户询问“当前的库存水平怎么样?”大模型不仅会考虑库存数据,还会应用企业的库存管理规则,如安全库存水平和补货周期,给出有针对性的分析思路,并提供符合实际业务需求的优化建议。
更进一步,可以让大模型学习具体的业务流程,并将从数据分析中得到的行动建议直接转化成业务系统中的相关任务,真正让数据从业务中来,到业务中去。
这些技术进步为帆软提供了更大的信心,推动他们在“AI For BI”方向上坚决投入。这次,帆软决心以更大的力度推进AI大模型在BI领域的应用,因为他们看到了实现突破性进展的机会。
帆软的FineChatBI ,有什么不一样?
当考虑清楚之后,帆软的行动也很坚决迅速。帆软在研发FineChatBI的过程中,展现了其在 BI 领域的深厚积累和在对话式BI 方向的创新能力,致力于打造一款真正能落地的对话式 BI 产品。具体来看,FineChatBI在企业级BI能力底座、内容可信生成、完善分析闭环、优化交互体验等几个维度持续发力,做出了自己的特色。
1、基于企业级BI能力底座,让 FineChatBI 从一开始就有一个坚实的基础。
一款成熟的对话式 BI 产品离不开一个坚实的 BI 能力底座,帆软将企业级 BI 的核心能力抽象成一组能够复用的公共组件,包括各种数据源的连接、数据建模与计算引擎、可视化组件的搭建渲染、用户数据权限的配置与管理等。基于这些公共能力,FineChatBI 只需要专注于将对话引擎及上层应用做好,就能打造出一款满足企业级要求的对话式 BI 产品。
2、多种模型结合解析用户意图,可控生成确保结果可信。
大模型在处理复杂的自然语言时,常常会出现“幻觉”,即生成不准确或不符合实际的结果。此外,作为一个黑箱模型,大模型的内部工作原理难以解释,这对于需要高透明度和高可信度的数据分析应用是一个重大挑战。FineChatBI 通过以下几项技术手段,确保的结果的准确、可信、可解释。
很多同类型的产品都是利用 Text2SQL 技术,直接将用户的自然语言查询转化为 SQL 语句。这种方法导致的一个问题是,业务人员由于无法判断生成的 SQL 是否准确,导致无法信任最终的生成结果。为了解决这个问题,帆软采用了 Text2DSL技术,先将自然语言转成用户能够理解的数据标准查询结构,再利用底层的引擎能力将该结构转成具体的 SQL 语句。这样用户就能够确认系统是否正确理解了他的数据查询意图并进行干预,从而实现生成过程可干预,结果可信任 。
更进一步,帆软采用自研的规则模型与大模型相结合的方法,利用规则模型以完全可控的方式处理简单、明确的数据问题,保证精度的同时,能够实现快速响应;大模型则用于处理复杂和模糊的问题。这种组合不仅解决了性能问题,还确保了结果的可信度和可解释性。
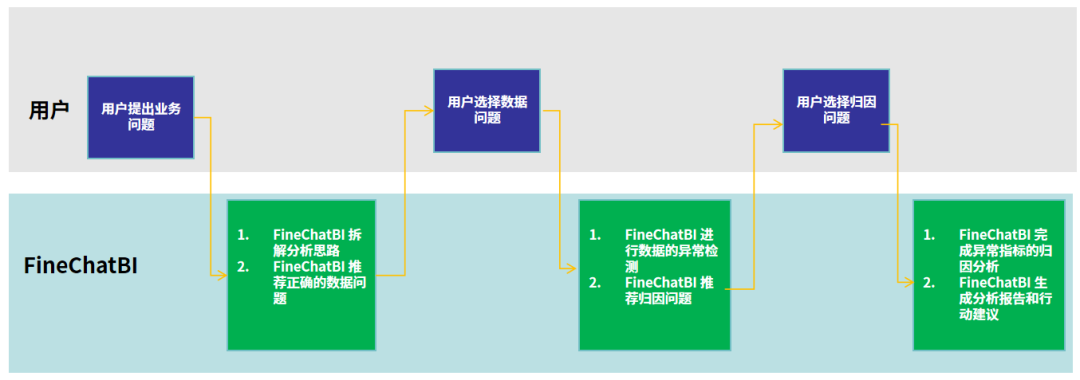
3、不止于查数,FineChatBI 旨在以对话为入口打造分析闭环。
对话式数据分析入口与业务逻辑相结合,FineChatBI不仅仅是一个数据查询工具,还能让用户针对某个业务问题,轻松完成整个数据分析闭环:业务用户只需要提出正确的业务问题,FineChatBI 就能结合数据和业务知识,拆解分析思路并推荐正确的数据问题;用户点击选择对应的数据问题后,系统还能自动基于生成的数据结果进行数据的异常检测,并推荐相应的归因问题;用户可以进一步在产品的引导下完成异常指标的归因分析,并生成分析报告和行动建议。通过这样方式,用户就能在产品的引导下,针对某个业务问题,从描述性分析,到诊断性分析,再到处方性分析,一步步完成整个分析闭环。
4、以对话框为核心持续优化产品交互,让用户体验更加丝滑。
对话式分析对很多用户来说是一种全新的交互形态,体验是否丝滑对用户持续使用产品至关重要。帆软持续改进FineChatBI 的交互体验,通过各种友好的方式引导用户持续问出正确的数据问题并快速得到分析结论。例如,输入联想与模糊匹配能够让用户在输入的过程中快速匹配相似的推荐问题与热点问题;开放图表生成规则让用户能够确认和调整意图解析结果,可以自由切换指标聚合方式、删减维度,并实现图表类型的一键切换;多轮问答能够维持会话上下文,用户可以基于之前的结果连贯提问。为了确保极致的用户体验,帆软在性能优化方面也做了很多投入,从意图理解、数据查询计算到组件渲染各个环境都做了性能优化,确保大部分查询都能实现秒级响应,这对于提高用户粘性度至关重要。
基于这样的思考,与市面上很多对话式BI产品不同,帆软将FineChatBI定位为对话式业务分析工具,而不是对话式数据分析工具,这两者在于关注点、用户体验、技术实现和目标愿景等方面,都有显著的不同。
对话式数据分析工具主要关注数据处理和分析,服务于数据分析师,通过简化数据查询流程来帮助用户获取数据结果。而对话式业务分析工具不仅关注数据,还关注业务逻辑和需求,帮助用户理解数据对业务决策的意义。FineChatBI的愿景是通过整合数据分析与业务逻辑,让用户不仅能获取数据,还能用数据驱动业务发展,真正实现商业智能。这一定位使FineChatBI在市场上具有独特的竞争力,也为BI行业的发展提供了新方向。
让“人人都是数据分析师”不再是一个空洞的口号
可以预见,随着FineChatBI这类对话式BI技术的出现,无论是服务供给端的BI市场,还是数据消费端的企业,都将发生显著的变革。
在BI服务供给侧,对话式BI打开了10倍级的市场空间,有望重塑目前的BI市场竞争格局。
传统的敏捷BI技术虽然提升了数据分析的效率,但其用户群体依然主要集中在技术人员和专业的数据分析师中,仅覆盖了大约10%的人群。而对话式BI则通过自然语言处理技术,让所有业务人员都能够进行数据分析。这意味着,市场规模可以从10%迅速扩大到100%,实现10倍的增长。对话式BI带来的不仅仅是存量市场中的红海竞争,而是一个全新的、充满潜力的蓝海市场。在这个市场,BI厂商不用陷入价格战的内卷中,也可以实现业绩的良性增长,正将推动整个BI行业的健康发展。
在数据消费侧,对话式BI助推了数据普惠和企业数智化升级。
对于个人而言,大部分人在日常工作和生活中,是很少进行数据分析的,更多是依赖自己的经验判断。并不是数据分析不重要,而是以往的数据分析门槛太高了,普通人望而却步了。在数字化时代,数据分析能力是每个人的必备技能。也许,不久的将来,我们做任何决定前,都会下意识的先做一轮数据分析。
对于企业而言,随着经济粗狂式的高速增长时代过去,接下来会是更加激烈的存量市场竞争。这要求企业在经营管理、运营层面,具备精耕细作的能力。以往依赖经验的经营决策方式,将逐步由基于数据的科学决策、精细化决策所代替。
通过FineChatBI等对话式BI工具,企业能够实现数据驱动的精细化管理与运营,大大提高决策质量和业务运营效率。对于企业来说,这种转变不仅仅是工具上的进步,更是生产力和运营模式上的重大变革,真正实现数据驱动的决策和运营。
当每个人、每个企业的数据素养得到提升,那各个行业乃至整个社会的数据素养也将得到提升,这将有力促进数据生产要素的价值释放。无论是数字经济的建设,还是新质生产力的提升,都有重要的战略价值。
文:月满西楼 / 数据猿
责编:凝视深空 / 数据猿