【摘要】我们提出了一种简单的提示技术,即后退提示法,它使 LLM 能够进行抽象,从包含特定细节的实例中得出高级概念和第一原理。通过使用概念和原理来指导推理,LLM 显著提高了遵循正确推理路径解决问题的能力。我们使用 PaLM-2L、GPT-4 和 Llama2-70B 模型进行了后退提示法实验,并观察到在各种具有挑战性的推理密集型任务(包括 STEM、知识问答和多跳推理)上的性能显著提升。例如,后退提示法分别将 PaLM-2L 在 MMLU(物理和化学)上的性能提高了 7% 和 11%,将 TimeQA 提高了 27%,将 MuSiQue 提高了 7%。
原文:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
地址:https://arxiv.org/abs/2310.06117
代码:无
出版:ICLR 2024
机构: Google, DeepMind
1 研究问题
本文研究的核心问题是: 如何通过抽象的方式唤起大语言模型中的推理能力
::: block-1
假设一个学生在做物理题时遇到这样一个问题:“如果一个理想气体的温度增加2倍,体积增加8倍,那么压强会发生什么变化?”。如果学生直接利用大语言模型去解决这个问题,模型很可能在推理过程中出错。但如果学生先让模型抽象出解决这个问题需要用到的理想气体定律原理,再基于这个原理进行推理,就更有可能得到正确答案。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 许多复杂任务包含大量细节信息,大语言模型很难直接从中检索出相关事实来解决任务。
- 大语言模型在多步推理任务中容易在中间步骤出错,难以遵循正确的推理路径。
- 现有的提示工程方法如思维链(CoT)提示,虽然一定程度上改善了大语言模型的推理能力,但对于许多复杂任务来说效果仍然有限。
针对这些挑战,本文提出了一种分两步走的"后退提示"(Step-Back Prompting)方法:
::: block-1
第一步是通过上下文学习向大语言模型展示如何"后退一步",对问题进行抽象,提取出解决问题所需的高层次概念和原理。这一过程就像人类在遇到棘手问题时,会先退一步从更高的视角来审视问题。第二步是基于第一步抽象出的概念和原理,发挥大语言模型的推理能力去解决原始问题。这种做法巧妙地将复杂任务分解为相对简单的抽象步骤和推理步骤,减少了模型在推理过程中出错的可能性。同时,通过让模型自己总结概念和原理,而不是像思维链那样直接给出推理步骤,可以更好地发挥大语言模型的知识和理解能力。
:::
2 研究方法
2.1 STEP-BACK PROMPTING概述
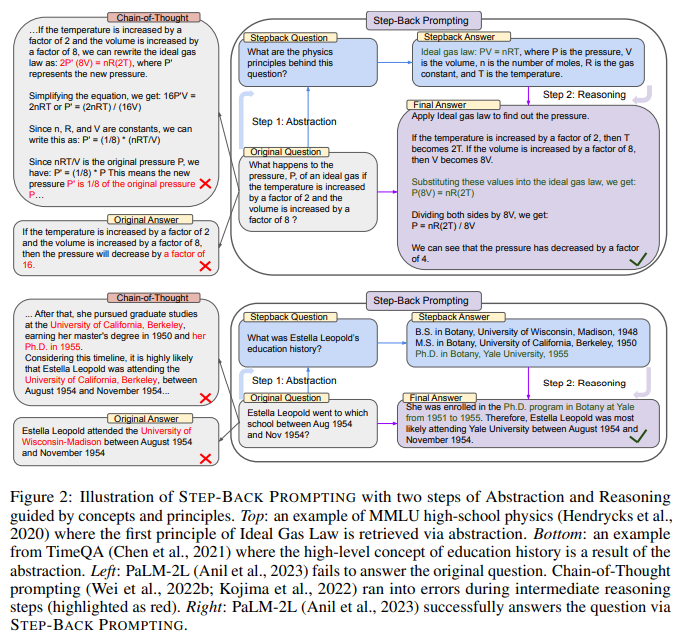
论文提出了一种名为STEP-BACK PROMPTING的新方法,旨在通过抽象和推理两个步骤来提高大型语言模型在复杂推理任务上的表现。这一方法的灵感来源于人类在面对复杂问题时常常会先退一步,从更高的层次上进行抽象,得到指导问题求解的概念或原理。STEP-BACK PROMPTING的第一步是通过少量示例来演示如何进行抽象,即提示模型从给定的具体问题中抽取出高层次的概念或原理。第二步是在这些高层次概念或原理的基础上进行推理,以得出原始问题的答案。
2.2 第一步:抽象
在抽象步骤中,论文通过少量的示例来演示如何从原始问题中抽取高层次的概念或原理。以物理学问题为例,给定一个关于理想气体压强、体积和温度关系的问题,模型需要首先识别出其中涉及的物理学原理,如理想气体状态方程 P V = n R T PV=nRT PV=nRT。这一步骤并不需要人工定义高层次的概念或原理,而是通过向模型展示一些问题-原理对来引导模型自动抽象。
2.3 第二步:推理
在得到高层次的概念或原理之后,推理步骤则在此基础上进行,以得出原始问题的答案。继续以理想气体问题为例,模型需要将给定的条件(如温度增加到原来的2倍,体积增加到原来的8倍)代入理想气体状态方程,通过一系列推导得出压强的变化。这一步骤并不需要对模型进行微调,而是利用了大型语言模型本身已有的推理能力。
2.6 实验细节
在实验中,论文使用了1到5个few-shot示例来演示如何进行抽象。通过消融实验,论文发现即使只使用1个示例,STEP-BACK PROMPTING也能够在大多数任务上取得较好的性能,这表明抽象是一种更容易学习的技能。此外,论文还讨论了扩大few-shot示例数量并不会明显提升性能。这一结果进一步证明了STEP-BACK PROMPTING的抽象步骤是sample-efficient的,即不需要大量的演示就能学会抽象。
3 实验
3.1 实验场景介绍
本文提出了一种简单的提示方法STEP-BACK PROMPTING,通过抽象化和推理两个步骤,在大型语言模型中唤起深度推理能力。实验评估STEP-BACK PROMPTING在三大类任务(STEM、Knowledge QA、Multi-hop Reasoning)上的性能。
3.2 实验设置
- Datasets:
- STEM: MMLU Physics、Chemistry,GSM8K
- Knowledge QA: TimeQA,SituatedQA
- Multi-hop Reasoning: MuSiQue,StrategyQA
- Baseline: PaLM-2L、GPT-4、Llama2-70B模型的标准提示、Chain-of-Thought(CoT)提示等
- Implementation details: 使用greedy decoding推理
- metric: 采用PaLM-2L作为judge模型,对目标答案和模型预测答案是否等价进行评估
3.3 实验结果
实验1、STEP-BACK PROMPTING在STEM任务上的性能
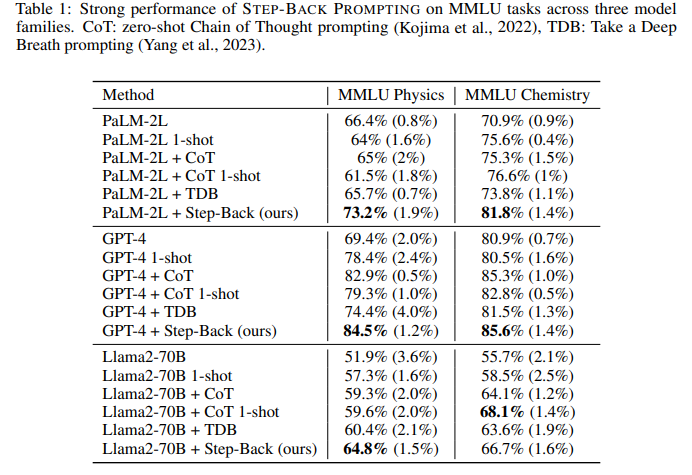
目的: 评估STEP-BACK PROMPTING在MMLU Physics、Chemistry和GSM8K等STEM任务上的有效性
涉及图表: 表1,表4
实验细节概述: 在PaLM-2L、GPT-4、Llama2-70B三个模型上,比较STEP-BACK PROMPTING与标准提示、CoT等方法的性能
结果:
- STEP-BACK PROMPTING在三个模型上的MMLU Physics、Chemistry性能均优于其他方法,提升7%-11%
- 在GSM8K上,STEP-BACK PROMPTING与CoT等效果相当,可能因为GSM8K原理较简单,不需要抽象化
实验2、STEP-BACK PROMPTING在Knowledge QA任务上的性能
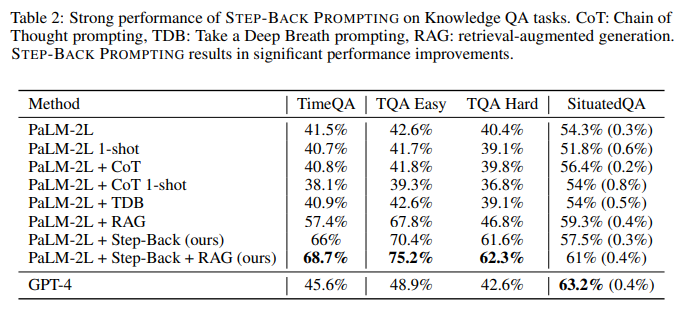
目的: 评估STEP-BACK PROMPTING在TimeQA、SituatedQA等知识密集型问答任务上的有效性
涉及图表: 表2
实验细节概述: 在PaLM-2L上,比较STEP-BACK PROMPTING与标准提示、CoT、检索增强(RAG)等方法的性能
结果:
- TimeQA上,Step-Back+RAG达到最佳的68.7%,比PaLM-2L提升27%
- SituatedQA上,Step-Back+RAG达到61%,略逊于GPT-4的63.2%
- STEP-BACK PROMPTING能更好地检索高级概念的fact,用于grounding最终的推理
实验3、STEP-BACK PROMPTING在Multi-hop Reasoning任务上的性能
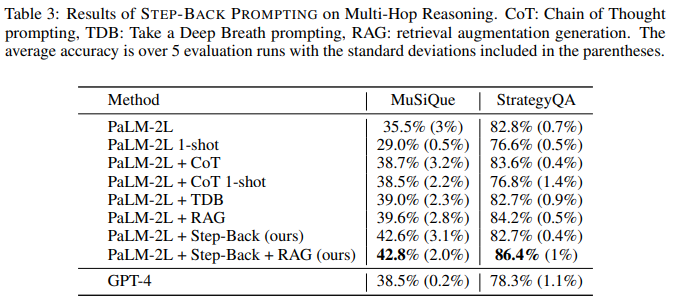
目的: 评估STEP-BACK PROMPTING在MuSiQue、StrategyQA等多跳推理任务上的有效性
涉及图表: 表3
实验细节概述: 在PaLM-2L上,比较STEP-BACK PROMPTING与标准提示、CoT、RAG等方法的性能
结果:
- MuSiQue上,Step-Back+RAG达到最佳的42.8%,显著优于GPT-4的38.5%
- StrategyQA上,Step-Back+RAG达到86.4%,同样大幅领先GPT-4
- 抽象化的强大作用使STEP-BACK PROMPTING能更好解决复杂推理任务
实验4、STEP-BACK PROMPTING在MMLU Physics上的消融实验和错误分析
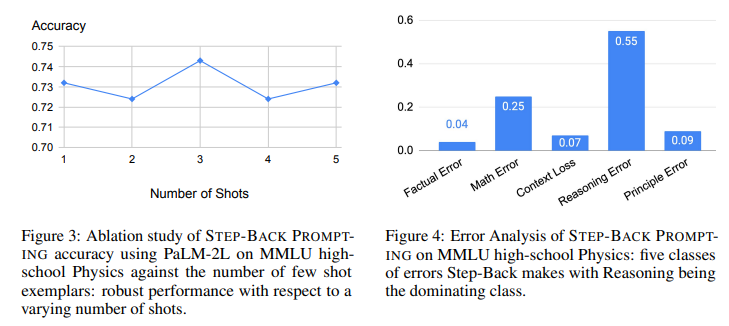
目的: 更细致地分析STEP-BACK PROMPTING的特性
涉及图表: 图3,图4
实验细节概述:
- 对STEP-BACK PROMPTING在不同few-shot示例数下MMLU Physics性能进行消融
- 分析STEP-BACK PROMPTING在MMLU Physics上犯的错误类型
结果:
- STEP-BACK PROMPTING对few-shot示例数不敏感,1个示例就能获得很好性能
- STEP-BACK PROMPTING的错误主要属于推理错误,抽象化技能相对容易few-shot学习
实验5、STEP-BACK PROMPTING在TimeQA上的消融实验和错误分析
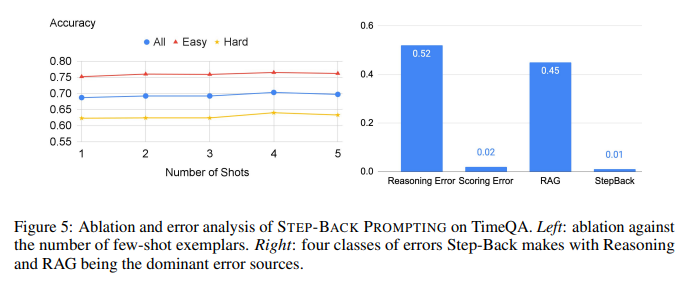
目的: 更细致地分析STEP-BACK PROMPTING的特性
涉及图表: 图5,图6
实验细节概述:
- 对STEP-BACK PROMPTING在不同few-shot示例数下TimeQA性能进行消融
- 分析STEP-BACK PROMPTING在TimeQA上的正误情况
结果:
- STEP-BACK PROMPTING对few-shot示例数不敏感
- Step-Back能修正39.9%baseline的错误,而只引入5.6%新错误
- Step-Back+RAG能修正21.6% RAG的错误,而只引入6.3%新错误
4总结
本论文针对大语言模型(LLM)在多步复杂推理任务上仍然面临挑战的问题,提出了一种名为STEP-BACK PROMPTING的两阶段方法。首先,通过抽象(abstraction)提取高层概念和原则;然后基于这些概念和原则进行推理(reasoning)得到最终答案。在多个涉及STEM、知识型问答、多跳推理的数据集上进行了实验。结果表明,所提方法可以显著提升PaLM-2L、GPT-4、Llama2-70B等多个LLM的表现,相比基线提升高达27%(如在TimeQA数据集上)。
::: block-2
疑惑和想法
- 除了人为设计的问题抽象模板,是否可以让LLM自主学习如何针对不同问题形成恰当的抽象?这可能需要更多的Few-shot示例。
- 在某些推理链很长的场景中,高层抽象可能丢失一些关键细节。如何权衡抽象粒度与推理难度,值得进一步探索。
- 能否将STEP-BACK思想与其他的prompting技术如思维链(Chain-of-Thought)相结合,进一步提升LLM的推理能力?
- 除了问答类任务,STEP-BACK是否可以应用于开放式文本生成,提升生成内容的逻辑性与连贯性?
:::
::: block-2
可借鉴的方法点 - 通过抽象简化问题复杂度,降低LLM推理难度的思路可以推广到其他类型任务如代码生成、对话理解等。
- 将复杂任务分解为两个子问题(抽象+推理)的方法可以借鉴,设计出更多Prompt形式。
- 结合retrieval增强LLM的事实性知识,提升问答正确率的做法值得学习。可以进一步探索如何优化retrieval问题。
- 在不同类型LLM上进行全面评测的实践值得借鉴,这有助于理解方法的普适性和界限。
::: block-2