B站UP主视频
感谢UP主“白菜工厂1145号员工”的“熟肉”,我这篇笔记就不展示整一个训练和推理流程,重点写的4060该注意的一些事项。如何解决断句模糊的问题,在本篇笔记的最末尾。
相关连接:
原项目github
UP主的说明文档
1、训练模型:
这里是在windows11的4060下进行训练测试,其他显卡不一定又参考作用,简单再复述一下流程:
1.1、准备数据集
在前期准备数据的时候,使用了没啥背景声音的MP3音频进行处理,用了UVR进行处理,出去分离人声。
难受一点:最开始跑用的不是GPT-soVITS而是soVITS4.0,发现UVR处理的数据总会带来电音(很像auto-tune开大了,生成的每句话相对于原音频都跑调,但auto-tune被强行修正),我去听了每一条处理之后的数据,听感上都挺不错,但还是有这个问题。后来尝试直接把原始数据进行切片,发现比UVR效果好很多。
使用GPT-soVITS的时候我就没有用UVR进行处理,也没进行降噪处理,直接进行切片
1.2、数据集处理和标注
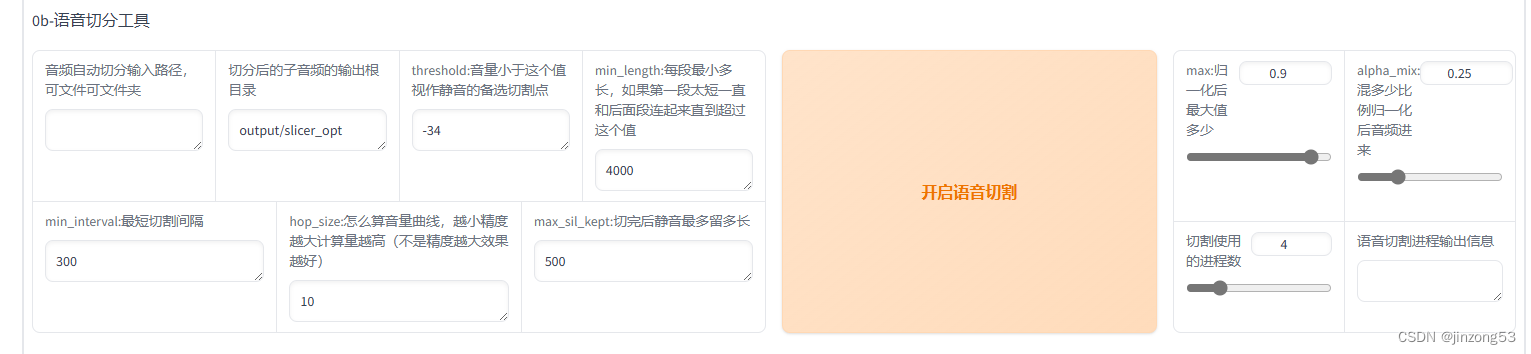
只要数据集没有出现重大瑕疵和背景音,直接进行切片,不要使用UVR和降噪处理!
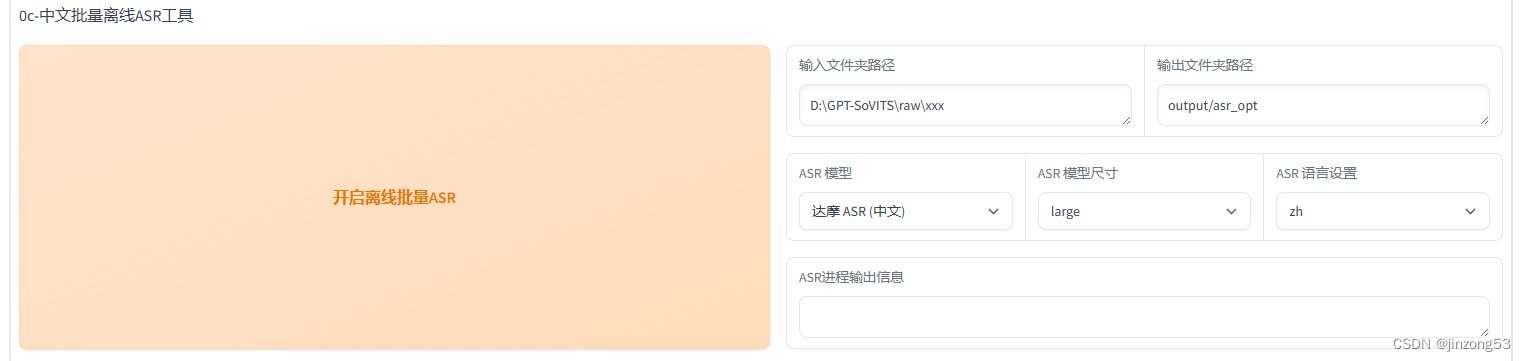
进行标注就可以。
1.3、确认训练数据
这里选择好路径,确认好训练list文件,就可以了
1.4、正式的训练
1.4.1、sovtis语音权重
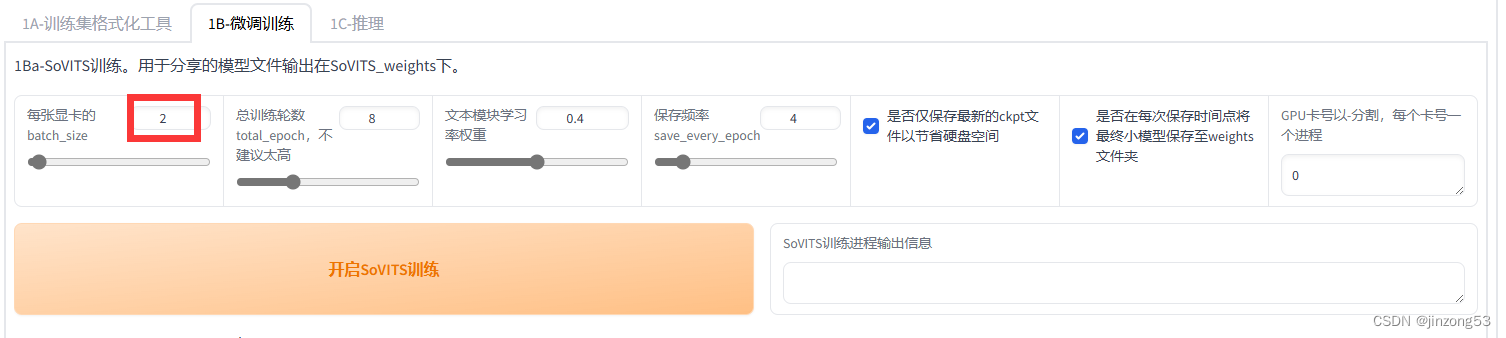
这里batchsize选择2,然后点训练就行,大概是训练了1小时左右
1.4.1、语言模型权重
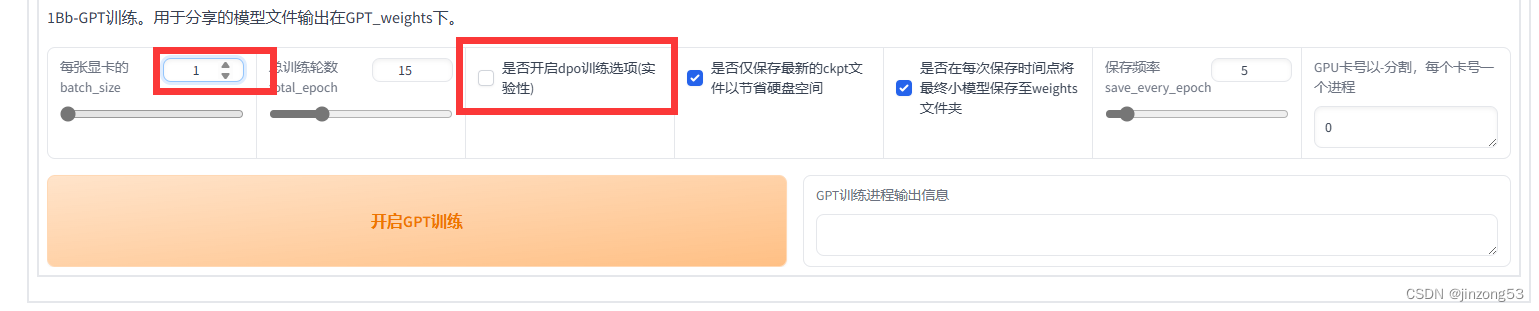
batchsize为1,dpo不开,大概也是训练了1小时左右。
2、推理:
下面的音频都放在的github上了,可能访问较慢,下面就选定模型开启推理就OK。
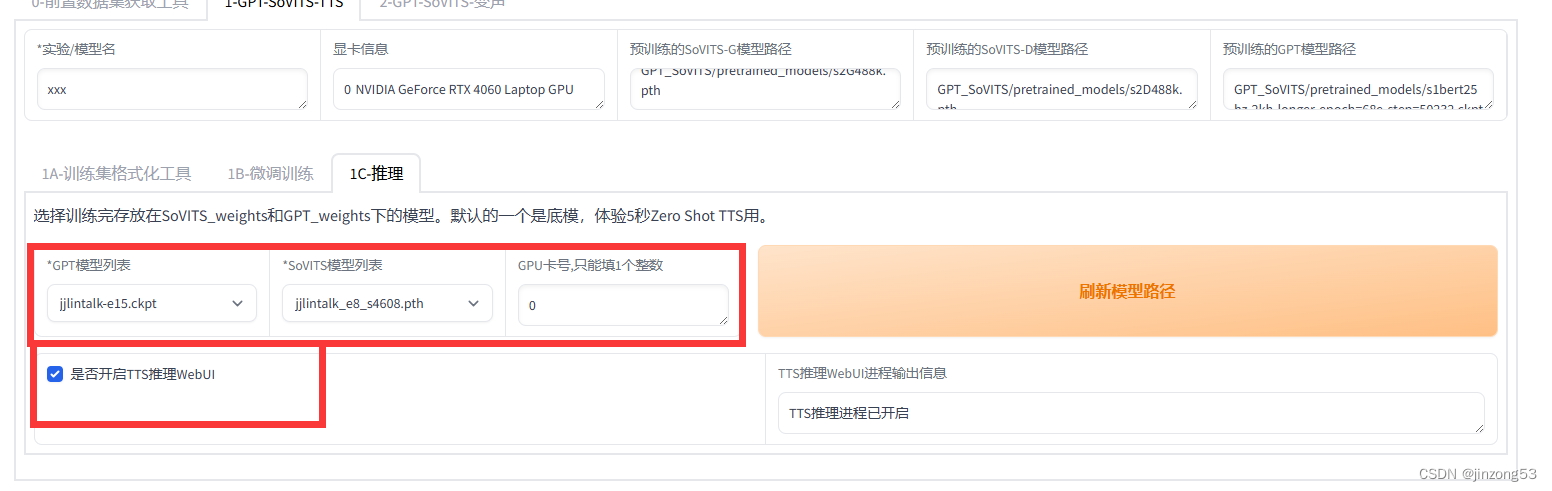
2.1、参考音频
参考音频一定要有,不然难1、2次就得到你想要的,同时5秒的效果最好。然后选定好语音的语言文本类型。

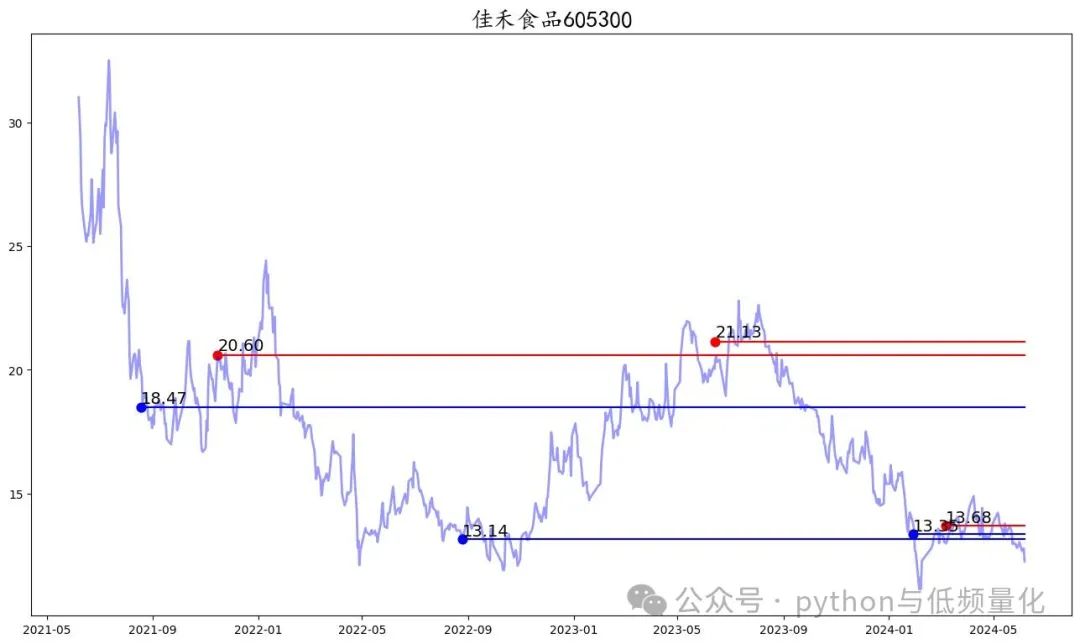
原始参考音频—这个音频的原始文本是:哦吼吼鸡皮疙瘩起来了因为因为这位朋友他是很支持我然后他他也是youtuber。
2.2、确认生成的参数
这里呢,通过大量文本的尝试,我觉得“凑四句切一句”,选这个就对文本长度不太敏感。其次的这个topK的选择,这里表示是将文本分成多少段进行生成,并不是越大越好,也不是越小越好。
topK:太大会导致文本被压缩的很厉害,但是很快。选择1就是一次生成完成,但很容易出现重复读。需要一点点尝试。

2.3、GPT-soVITS推理过程吐字和重复读解决方案
原始文本:
流萤与开拓者聊天时,透露匹诺康尼愿意接纳她,尽管她不属于这里。开拓者怀疑她到底是本地人还是偷渡犯,流萤说她至少现在是本地人,有合法身份。随后,流萤让开拓者凑近,告诉开拓者从二人开始游玩起就有人在跟踪开拓者,为了摆脱跟踪流萤刚才一直在带开拓者绕远路,但对方就没跟丢过。流萤详细描述了跟踪者的具体特征,包括身高、体型、步法,乃至手掌手指的状况以及惯用武器。
输入文本:
流萤与开拓者聊天时,透露匹诺康尼愿意接纳她,尽管她不属于这里。开拓者怀疑她到底是本地人还是偷渡犯,流萤说她至少现在是本地人,有合法身份。随后,流萤让开拓者凑近,告诉开拓者从二人开始游玩起就有人在跟踪开拓者,为了摆脱跟踪流萤刚才一直在带开拓者绕远路,但对方就没跟丢过。流萤详细描述了跟踪者的具体特征,包括身高、体型、步法,乃至手掌手指的状况以及惯用武器。

topK=3,“凑四句切一句”
生成结果—生成结果在 “随后”,“为了摆脱跟踪”,“但对方就没” 的附近出现吞字和重复
2.3.1、进行文本改造

将出现吞字的地方,连续换两行,就可以得到完美解决,同时加入连续的标点符号,可以保证每一句结束出现一点尾音,就不会像机器一样突然结束
流萤与开拓者聊天时,透露匹诺康尼愿意接纳她,尽管她不属于这里。开拓者怀疑她到底是本地人还是偷渡犯,流萤说她至少现在是本地人,有合法身份!!!
随后,流萤让开拓者凑近,告诉开拓者从二人开始游玩起就有人在跟踪开拓者!
为了摆脱跟踪流萤刚才一直在带开拓者绕远路,但对方就没跟丢过。
流萤详细描述了跟踪者的具体特征,包括身高、体型、步法,乃至手掌手指的状况以及惯用武器。
完美生成的链接—没有出现吞字,同时有好听的尾音。





![线性回归例子, 学习笔记[机械学习]](https://img-blog.csdnimg.cn/direct/98ebda720fcf446e88275018fa508d84.png)