想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
LLVM 后端实践笔记
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1V_tZkt9uvxo5bnUufhMQ_Q?pwd=ggu5 提取码: ggu5
这一章会介绍与控制流有关的功能实现,比如 if、else、while 和 for 等,还会介绍如何将控制流的 IR 表示转换为机器指令;之后会引入几个后端优化,处理一些跳转需求引入的问题,同时来说明如何编写后端优化的 pass。在条件指令小节中,会介绍 LLVM IR 中的特殊指令 select 和 select_cc,以及如何处理这种指令,从而来支持更细节的控制流支持实现。
目录
一、第一节
1.1 修改的文件
1.1.1 Cpu0ISelLowering.cpp/.h
1.1.2 Cpu0InstrInfo.td
1.1.3 Cpu0MCInstLower.cpp
1.1.4 Cpu0AsmBackend.cpp
1.1.5 Cpu0ELFObjectWriter.cpp
1.1.6 Cpu0FixupKinds.h
1.1.7 Cpu0MCCodeEmitter.cpp
1.2 结果
二、第二节
2.1 新增的文件
2.1.1 Cpu0DelUselessJMP.cpp
2.2 修改的文件
2.2.1 Cpu0.h
2.2.2 Cpu0TargetMachine.cpp
一、第一节
从机器层面上来看,所有的跳转只分为无条件跳转和有条件跳转,从跳转方式上来分,又分为直接跳转(绝对地址)和间接跳转(相对偏移),所以我们只需要将 LLVM IR 的跳转 node 成功下降到机器跳转指令,并维护好跳转的范围、跳转的重定位信息即可。
Cpu032I 型机器支持 J 类型的跳转指令,比如无条件跳转 JMP,有条件跳转 JEQ、JNE、JLT、JGT、JLE、JGE,这部分指令是需要通过检查 condition code (SW 寄存器)来决定跳转条件的;Cpu032II 型机器除了支持 J 类型跳转指令之外,还支持 B 类型的跳转指令,比如 BEQ 和 BNE,这两个是通过直接比较操作数值关系来决定跳转条件的。相比较,后者的跳转依赖的资源少,指令效率更高。
SelectionDAG 中的 node,无条件跳转是 ISD::br,有条件跳转是 ISD::brcond,我们需要在 tablegen 中通过指定指令选择 pattern 来对这些 node 做映射。
另外,J 类型指令依赖的 condition code 是通过比较指令(比如 CMP)的结果来设置的,我们在之前的章节已经完成了比较指令,LLVM IR 的 setcc node 通常会被翻译为 addiu reg1, zero, const + cmp reg1, reg2 指令。
1.1 修改的文件
1.1.1 Cpu0ISelLowering.cpp/.h
Cpu0ISelLowering.cpp文件设置本章需要的几个 node 为 custom 的 lowering 类型,即我们会通过自定义的 lowering 操作来处理它们,这包括 BlockAddress,JumpTable 和 BRCOND。这分别对应 lowerBlockAddress(),lowerJumpTable() 和 lowerBRCOND() 函数(在Cpu0TargetLowering::LowerOperation函数内),具体实现可参见代码,其中 getAddrLocal() 和 getAddrNonPIC() 是我们前边章节已经实现的自定义 node 生成函数。BRCOND 是条件跳转节点(包括 condition 的 op 和 condition 为 true 时 跳转的 block 的地址),BlockAddress 字面可知是 BasicBlock 的起始地址类型的节点,JumpTable 是跳转表类型的节点。后两者是叶子节点类型。
另外,设置 SETCC 在 i1 类型时做 Promote。增加了几行代码来说明额外的一些 ISD 的 node 需要做 Expand,有关于 Expand 我们在之前的章节介绍过,就是采用 LLVM 内部提供的一些展开方式来展开这些我们不支持的操作。这些操作包括:BR_JT,BR_CC,CTPOP,CTTZ,CTTZ_ZERO_UNDEF,CTLZ_ZERO_UNDEF。其中 BR_JT 操作的其中一个 op 是 JumpTable 类型的节点(保存 JumpTable 中的一个 index)。BR_CC 操作和 SELECT_CC 操作类似,区别是它保存有两个 op,通过比较相对大小来选择不同的分支。
; ModuleID = 'test.bc'
source_filename = "test.cpp"
target datalayout = "E-m:m-p:32:32-i8:8:32-i16:16:32-i64:64-n32-S64"
target triple = "mips-unknown-linux-gnu"
define i8 @parity_8(i8 %x) {
%1 = tail call i8 @llvm.ctpop.i8(i8 %x)
%2 = and i8 %1, 1
ret i8 %2
}
declare i8 @llvm.ctpop.i8(i8 %x)对于这样一个ctpop指令我们就能让llvm将其进行扩展(当前还没实现call调用,这个暂时还编不过)。如果我们不加那条的话在指令选择的阶段会报错:

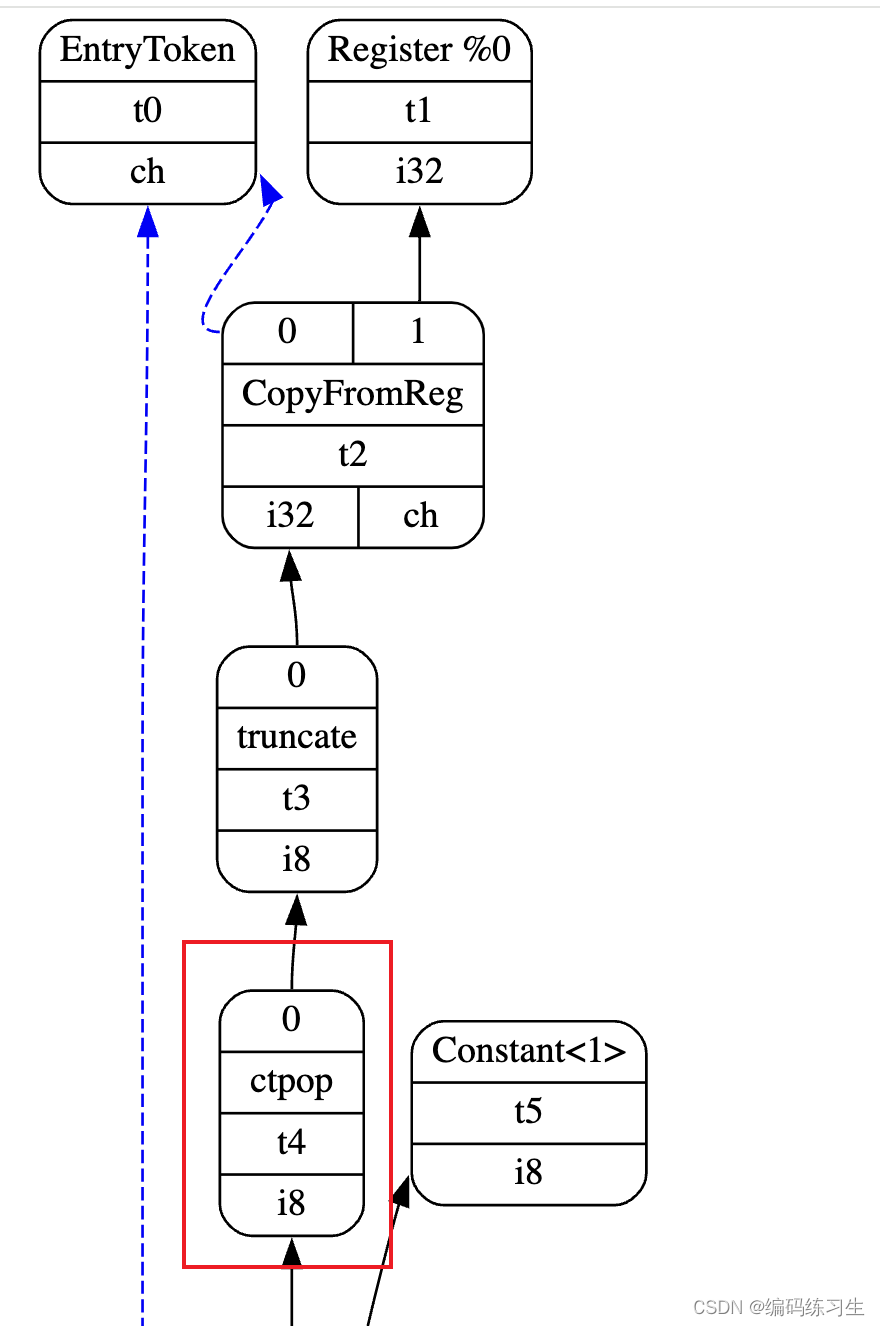
加上之后就会在legalize阶段转化成其他的表示形式,然后也就能顺利输出对应的汇编。

附上DAG调试时候的常用命令(需要debug版本的llc):

上述指令的输出数dot文件,我们还需要使用dot将其转化成可视化的图:
dot -Tsvg test.dot -o test.svg
dot -Tpng test.dot -o test.png1.1.2 Cpu0InstrInfo.td
增加两个和跳转有关的操作数类型:brtarget16 和 brtarget24,前者是 16 位偏移的编码,将用于 BEQ、BNE 一类的指令,这一类指令是属于 Cpu032II 型号中特有;后者是 24 位偏移的编码,将用于 JEQ、JNE 一类的指令。两个操作数均指定了编码函数和解码函数的名称。还定义了 jmptarget 操作数类型,用来作为无条件跳转 JMP 的操作数。之后便是定义这几条跳转指令,包括它们的匹配 pattern 和编码。无条件跳转 JMP 的匹配 pattern 直接指明到了 [(br bb::$addr)],很好理解。类似的语法在之前的章节中我们距离介绍过。
然后我们做一些优化来定义 比较+跳转指令选择 Pattern,也就是将 brcond + seteq/setueq/setne/setune/setlt/setult/setgt/setugt/setle/setule/setge/setuge 系列模式转换为机器指令的比较+跳转指令组合。对于 J 系列的跳转指令,实际上会转换为 Jxx + CMP 模式,而对于 B 系列的跳转指令,则直接转换成指令本身。比如:
def : Pat<(brcond (i32 (setne RC:$lhs, RC:$rhs)), bb:$dst), (JNEOp (CMPOp RC:$lhs, RC:$rhs), bb:$dst)>;
def : Pat<(brcond (i32 (setne RC:$lhs, RC:$rhs)), bb:$dst), (BNEOp RC:$lhs, RC:$rhs, bb:$dst)>;1.1.3 Cpu0MCInstLower.cpp
因为跳转的地址既可以是跳转表偏移,也可以是一个 label,所以需要在 MachineOperand 这里对相关的类型做 lowering。在 LowerSymbolOperand() 函数中增加对 MO_MachineBasicBlock、MO_BlockAddress 和 MO_JumpTableIndex 类型的 lowering。
1.1.4 Cpu0AsmBackend.cpp
Cpu0 的架构和其他 RISC 机器一样,采用五级流水线结构,跳转指令会在 decode 阶段实现跳转动作(也就是将 PC 修改为跳转后的位置),但跳转指令在 fetch 阶段时,PC 会自动先移动到下一条指令位置,fetch 阶段在 decode 阶段之前,所以实际上,在 decode 阶段执行前,PC 已经自动 +4 (一个指令长度),所以实际上跳转指令中的偏移,并不是从跳转指令到目标位置的差,而应该是跳转指令的下一条指令到目标位置的差。比如说:
jne $BB0_2
jmp $BB0_1 # jne 指令 decode 之前,PC 指向这里
$BB0_1:
ld $4, 36($fp)
addiu $4, $4, 1
st $4, 36($fp)
jmp $BB0_2
$BB0_2:
ld $4, 32($fp) # jne 指令 decode 之后,假设 PC 指向这里jne 指令中的偏移,应该是 jmp 指令到 最后一条 ld 指令之间的距离,也就是 20 (而不是 24)。为了实现这样的修正,我们在 adjustFixupValue() 函数中,针对重定位类型 fixup_Cpu0_PC16 和 fixup_Cpu0_PC24,指定其 Value 应该在自身的基础上减 4。
1.1.5 Cpu0ELFObjectWriter.cpp
添加重定位类型的一些设置,在 getRelocType() 函数中增加内容。
1.1.6 Cpu0FixupKinds.h
添加重定位类型 fixup_Cpu0_PC16 和 fixup_Cpu0_PC24。
1.1.7 Cpu0MCCodeEmitter.cpp
实现地址操作数的编码实现函数,包括 getBranch16TargetOpValue(),getBranch24TargetOpValue() 和 getJumpTargetOpValue() 函数,对 JMP 指令同时还是表达式类型的跳转位置的情况,选择正确的 fixups,fixups 类型在 Cpu0FixupKinds.h 文件中定义。
1.2 结果
st $2, 4($sp)
ld $2, 12($sp)
addiu $3, $zero, 9
sltu $2, $3, $2
bne $2, $zero, $BB0_18
nop
# %bb.17: # in Loop: Header=BB0_15 Depth=1
jmp $BB0_15
$BB0_18:
jmp $BB0_20
$BB0_19: # %.loopexit
$BB0_20:
ld $2, 12($sp)
addiu $3, $zero, 10
bne $2, $3, $BB0_22
nop二、第二节
LLVM 的大多数优化操作都是在中端完成,也就是在 LLVM IR 下完成。除了中端优化以外,其实还有一些依赖于后端特性的优化在后端完成。比如说,Mips 机器中的填充延迟槽优化,就是针对 RISC 下的 pipeline 优化。如果你的后端是一个带有延迟槽的 pipeline RISC 机器,那么也可以使用 Mips 的这一套优化。
这一小节,我们实现一个简单的后端优化,叫做消除无用的 JMP 指令。这个算法简单且高效,可以作为一个优化的教程来学习,通过学习,也可以了解如何新增一个优化 pass,以及如何在真实的工程中编写复杂的优化算法。
jmp %BB_0
%BB_0:
... other instructions汇编指令中,若无跳转指令的话指令都是顺序执行的。当jmp 指令的下一条指令就是 jmp 指令需要跳转的 BasicBlock 块时,这里的 jmp 指令是多余的,即使删掉这条 jmp 指令,程序流也一样可以顺序执行正确。所以,我们的目的就是识别这种模式,并删除对应的 jmp 指令。
2.1 新增的文件
2.1.1 Cpu0DelUselessJMP.cpp
这是我们实现该优化 pass 的具体代码。
#define DEBUG_TYPE "del-jmp"
...
LLVM_DEBUG(dbgs() << "debug info");这里是为我们的优化 pass 添加一个调试宏,这样我们可以通过在执行编译命令时,指定该调试宏来打印出我们想要的调试信息。注意需要以 debug 模式来编译编译器,并且在执行编译命令时,指定参数, 或直接打开所有调试信息:
llc -debug-only=del-jmp
llc -debug在写代码的时候调试信息是非常非常重要的!!!如果我们要实现的是个较复杂的功能的话,没事挑事信息的话,在遇到bug的时候我们定位起来很不方便,经常可能需要自己添加一些打印信息,每次都添加的话很影响效率,这样的话,为什么不一开始就在关键的地方加上调试信息打印呢?另一方面有调试信息的话,也方便他人能够更好地理解我们的代码,明白我们各种数据结构中都是什么样的内容。
STATISTIC(NumDelJmp, "Number of useless jmp deleted");这个表示我们定义了一个全局变量 NumDelJmp,可以允许我们在执行编译命令时,当执行完毕时,打印出这个变量的值。这个变量的作用是统计这个优化 pass 一共消除了多少个无用的jmp 指令,变量的累加是在实现该 pass 的逻辑中手动设计进去的。在执行编译命令时,指定参数就可以打印出所有的统计变量的值。:
llc -statsstatic cl::opt<bool> EnableDelJmp(
...
...
);这部分代码是向 LLVM 注册了一个编译参数,参数名称是这里第一个元素,还指定了参数的默认值,描述信息等。我们使用参数名为:enable-cpu0-del-useless-jmp,默认是打开的。这就是说,如果我们指定了这个参数,并且令其值为 false,则会关闭这个优化 pass。
具体的实现代码中,继承了 MachineFunctionPass 类,并在 runOnMachineFunction 中重写了逻辑,这个函数会在每次进入一个新的 Function 时被执行,runOnMachineFunction是后端Machine Function的pass的入口,因此我们要改写这个函数。
我们的基本思路是,在每个函数中遍历每一个基本块,直接取其最后一条指令,判断是否为 jmp 指令,如果是,再判断这条指令指向的基本块是否是下一个基本块。如果都满足,则调用 MBB.erase(I) 删除 I 指向的指令(jmp 指令)并且累加 NumDelJmp 变量。
LLVM这种结构安排很清晰的,处理起来也比较容易。中端就是Instruction->Basic Block->Function->Module,后端就是Machine Instruction->Machine Basic Block->Machine Function。我们要做的功能是修改的什么量级的,就遍历到其中,然后筛选是否是我们要处理的场景,是的话就做相应的增删改查。
2.2 修改的文件
2.2.1 Cpu0.h
声明这个 pass 的工厂函数。
2.2.2 Cpu0TargetMachine.cpp
覆盖 addPreEmitPass() 函数,在其中添加我们的 pass。调用这个函数表示我们的 pass 会在代码发射之前被执行。
后端的PASS流水线的管理主要是在TargetPassConfig.cpp这个文件里边,包括后端对于LLVM IR的pass、对于DAG的pass、对于Machine Function的pass等等。 TargetPassConfig::addMachinePasses接口就是Machine Function的pass流水线,当中包括Pre RA、RA、Post RA等等,如果有需要的话,我们也能够在其中修改。

![线性回归例子, 学习笔记[机械学习]](https://img-blog.csdnimg.cn/direct/98ebda720fcf446e88275018fa508d84.png)