问题描述
代码:
from stanfordcorenlp import StanfordCoreNLP
import logging
#中文中的应用,一定记得下载中文jar包,并标志lang=‘zh’
nlp_zh = StanfordCoreNLP(r'D:\stanford-corenlp-full-2016-10-31', port=8094, lang='zh',quiet=False,logging_level=logging.DEBUG)
sentence_zh = '清华大学位于北京。'
print(nlp_zh.word_tokenize(sentence_zh))
print(nlp_zh.pos_tag(sentence_zh))
print(nlp_zh.ner(sentence_zh))
print(nlp_zh.parse(sentence_zh))
print(nlp_zh.dependency_parse(sentence_zh))用到的依赖包:stanford-corenlp-full-2016-10-31、stanford-chinese-corenlp-2016-10-31-models.jar
结果:
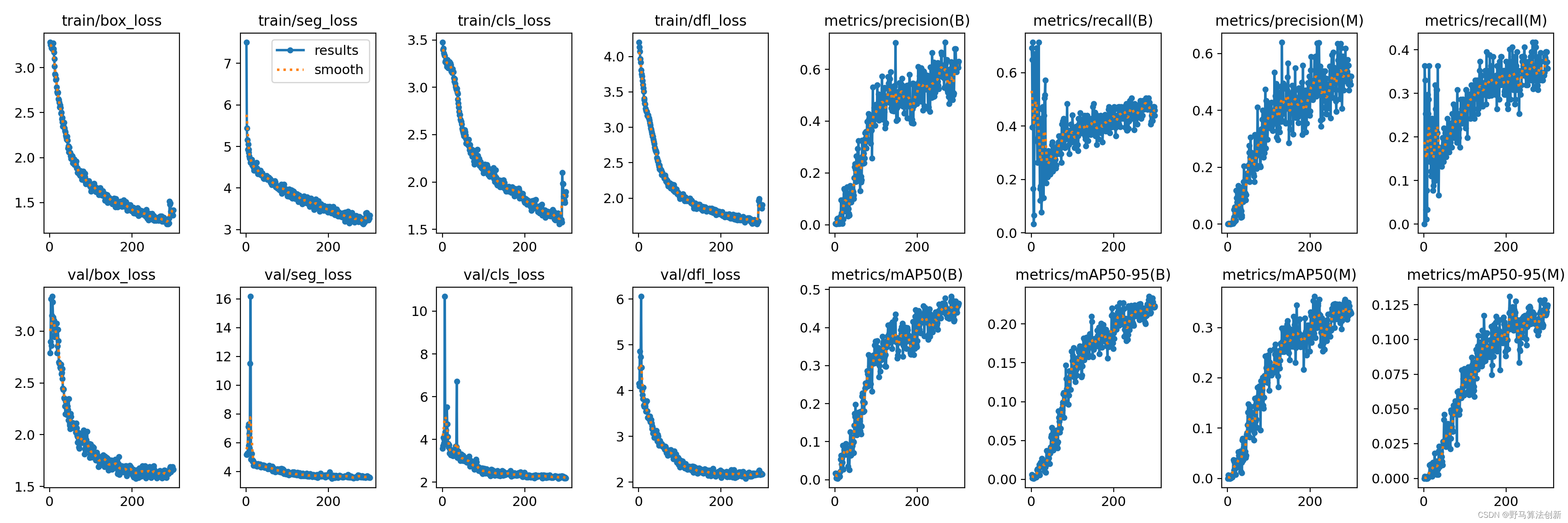
['', '', '', '', '']
[('', 'NR'), ('', 'NN'), ('', 'VV'), ('', 'NR'), ('', 'PU')]
[('', 'ORGANIZATION'), ('', 'ORGANIZATION'), ('', 'O'), ('', 'GPE'), ('', 'O')]
(ROOT
(IP
(NP (NR 清华) (NN 大学))
(VP (VV 位于)
(NP (NR 北京)))
(PU 。)))
[('', 0, 3), ('', 2, 1), ('', 3, 2), ('', 3, 4), ('', 3, 5)]原因解释
可以看到,上面的结果中全是空字符串,而不是中文字符串,说明stanfordcorenlp并没有成功分词,我对比了英文分词的结果,发现英文分词用到的tokenizer是PTBTtokenizer,而中文分词的logging信息中并没有体现出tokenizer这个选项。我一开始以为是tokenizer的问题,结果调整了半天发现没用,后来我想,中文分词要使用专门的jar包,也就是说它的tokenizer是不同于英文的,所以之前发现的问题并不是重点。
后来我突然想到,我在anaconda虚拟环境中下载stanfordcorenlp包是最新的,并没有固定版本,所以是不是我下的这个包的版本和我之前下的jar包的版本不一样导致的问题。
(于是,我去试了下,结果还真是这个问题 晕)
解决办法
卸载虚拟环境中的stanfordcorenlp包,然后下载对用版本的stanfordcorenlp包。
我这里的话,stanford-corenlp-full-2016-10-31、stanford-chinese-corenlp-2016-10-31-models.jar的版本是Stanford Corenlp3.7.0,于是我pip install stanfordcorenlp==3.7.0即可,但是报错说只有3.7.0.2,于是我就下载3.7.0.2,下载之后再运行同样的程序,就有中文字符串了(如下所示),不再是空字符串了。
['清华', '大学', '位于', '北京', '。']
[('清华', 'NR'), ('大学', 'NN'), ('位于', 'VV'), ('北京', 'NR'), ('。', 'PU')]
[('清华', 'ORGANIZATION'), ('大学', 'ORGANIZATION'), ('位于', 'O'), ('北京', 'GPE'), ('。', 'O')]
(ROOT
(IP
(NP (NR 清华) (NN 大学))
(VP (VV 位于)
(NP (NR 北京)))
(PU 。)))
[('ROOT', 0, 3), ('compound:nn', 2, 1), ('nsubj', 3, 2), ('dobj', 3, 4), ('punct', 3, 5)]这里是希望你能越来越好的 小白冲鸭 ~~~
(为什么我总是在犯一些低级错误,简直不忍直视T=T)