一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
我的写法
时间复杂度分析:
空间复杂度分析:
我要更强
哲学和编程思想
1. 模块化(Modularity)
2. DRY原则(Don't Repeat Yourself)
3. 抽象化(Abstraction)
4. 代码的可读性(Readability)
5. 函数式编程思想(Functional Programming)
举一反三
1. 进一步封装和抽象
2. 优化数据处理
3. 提高代码质量
4. 写作干净且有意义的代码
5. 遵循设计模式
6. 代码简洁性和性能
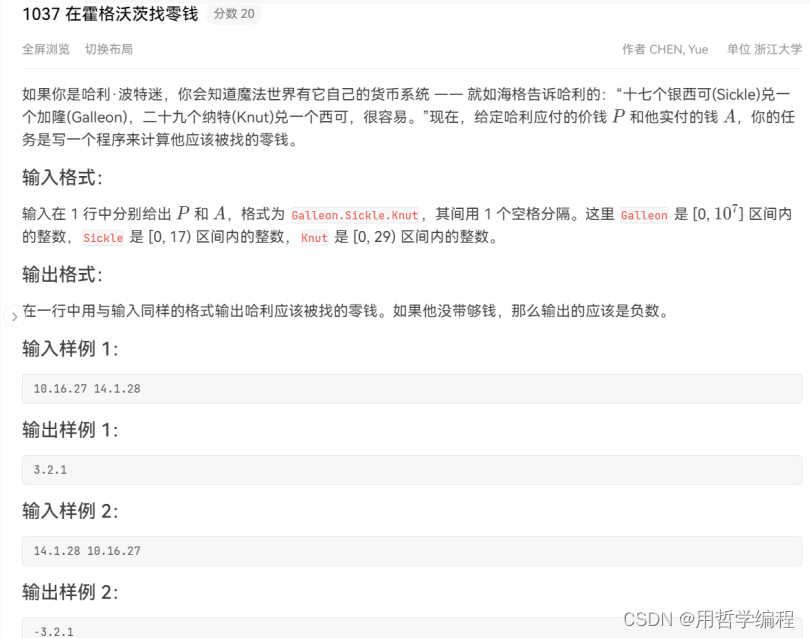
题目链接
我的写法
# 从用户输入获取两个货币值P和A,并以空格分隔
P, A = input().split()
# 将输入的货币值P和A根据点号'.'分解成列表,并将字符串转换成整数
P = list(map(int, P.split('.')))
A = list(map(int, A.split('.')))
# 计算货币P的总纳特数,加隆乘以17再乘以29,西可乘以29,纳特直接相加
P = (17 * P[0]) * 29 + (P[1] * 29) + P[2]
# 计算货币A的总纳特数,同上
A = (17 * A[0]) * 29 + (A[1] * 29) + A[2]
# 判断A是否小于P,若是,则信号为负号'-'
signal = '-' if A < P else ''
# 计算P和A的绝对差值,并将差额转换回原来的货币格式,即加隆.西可.纳特
changes = [abs(A - P) // (29 * 17), # 加隆数,用总差值除以一个加隆的纳特数
abs(A - P) // 29 % 17, # 西可数,用总差值除以一西可的纳特数取余数再对17取余数
abs(A - P) % 29] # 纳特数,用总差值对29取余数
# 格式化输出结果,如果是负差额,前面会有负号
print(f"{signal}{changes[0]}.{changes[1]}.{changes[2]}")
这段代码是一个针对特殊货币系统的差额计算器。它使用简单的数学转换和模运算来计算和格式化两个货币输入之间的差额。这是一个非常专门化的工具,可能适用于某些游戏或特殊的货币转换场景。
时间复杂度分析:
- 分割输入的字符串和转换为整数列表是 O(n) 操作,其中 n 是输入字符串的长度。
- 两次的货币转换操作(计算P和A的总纳特数)是 O(1) 操作,因为这里只涉及到有限的几个乘法和加法运算。
- 计算差额和转换回原货币格式同样是 O(1) 操作,因为无论输入多大,这里的操作数都是固定的。
综上所述,整个操作的时间复杂度是 O(n),主要是由于对输入字符串进行分割和转换。
空间复杂度分析:
- 输入字符串被存储为两个额外的列表 P 和 A,这需要 O(m) 的空间,其中 m 是输入字符串分割成列表后元素的总数。
- 其他操作如货币的转换和差额计算使用了常数空间,因为它们存储了固定数量的变量。
因此,整个操作的空间复杂度是 O(m),主要由输入数据的存储决定。
整体评价: 代码本身比较简洁,并且直接了当地完成了任务。它正确地利用了整数除法和取余,来计算差额并将其分解成不同的货币单位。这样的代码对于处理货币计算的小型任务来说是有效且足够的。
不过,代码在健壮性方面有待改进。例如,它没有检查输入的格式是否正确(是否为三部分数字),也没有检查数字是否在合理范围内。在实际应用中,这些都是应该要考虑的因素。此外,如果这段代码要集成到一个大型的应用中,最好为这个功能封装成函数,这样可以提高代码的可读性和可重用性。
我要更强
这段代码实际上已经是相当高效的。它的时间复杂度在处理单次输入的情况下是 O(n),其中n是输入字符串的长度。因为字符串长度在这里是用户输入的,无法预先确定,所以无法优化输入分割的时间复杂度。
空间复杂度同样是 O(m),其中m是分割后的输入元素总数。由于每个输入字符串都需要被分割和转换为整数进行计算,这是必须占用的空间。
然而,如果考虑到这个脚本可能会被多次调用或者处理多个输入,可以通过创建函数来重复使用相同的代码,这样可以提高代码的可读性和可重用性。在函数中处理每对输入,将有助于保持全局命名空间的清洁,并减少潜在的错误。
以下是改进后的代码及注释:
def calculate_currency_difference(P, A):
# 转换货币值为整数的纳特数
P_knuts = (17 * P[0]) * 29 + (P[1] * 29) + P[2]
A_knuts = (17 * A[0]) * 29 + (A[1] * 29) + A[2]
# 判断需要输出的信号(正数还是负数)
signal = '-' if A_knuts < P_knuts else ''
# 计算差值并转换成货币格式
diff = abs(A_knuts - P_knuts)
galleons = diff // (29 * 17)
sickles = (diff // 29) % 17
knuts = diff % 29
# 返回格式化的货币差值字符串
return f"{signal}{galleons}.{sickles}.{knuts}"
# 主函数,用于读取输入和输出结果
def main():
P_input, A_input = input("Enter two currencies separated by space (e.g., 3.12.1 5.15.21): ").split()
P = list(map(int, P_input.split('.')))
A = list(map(int, A_input.split('.')))
print(calculate_currency_difference(P, A))
# 调用主函数
if __name__ == "__main__":
main()在这段代码中,将计算的部分封装成了 calculate_currency_difference 函数,接受两个分解为列表的货币值 P 和 A。主函数 main 负责读取用户输入,并将输入转化为所需的格式,然后调用 calculate_currency_difference 函数并打印结果。
这段代码保持了原有算法的时间复杂度和空间复杂度,但增加了可读性和可重用性。由于输入操作是用户驱动的,它们的效率依赖于用户输入的长度和数量,这些不是通过算法优化能够改变的。储存输入和计算差值的操作已经是最优的,因为它们分别是由输入大小和固定的变量数决定的。
哲学和编程思想
改进代码的过程中,实际上应用了几个重要的编程哲学和思想,特别是当涉及到代码的可读性、可维护性和效率时。以下是几个关键点:
1. 模块化(Modularity)
通过将货币差额的计算封装到独立的函数中,我们实现了模块化。模块化是软件设计的一个核心原则,它鼓励将一个大问题拆分成小的、更易于管理的部分。这样做可以提高代码的组织性,使得每个模块都可以独立地开发和测试,从而提高了代码的可读性和可维护性。
2. DRY原则(Don't Repeat Yourself)
通过创建函数来避免重复代码。DRY原则强调了减少重复的重要性,它推荐使用抽象化的方式来避免在多个地方编写相同的代码。这不仅可以减少维护时的工作量(因为修复bug或修改功能只需要在一个地方进行),同时也提高了代码的清晰度和可理解性。
3. 抽象化(Abstraction)
通过将具体的计算过程隐藏在函数内部,我们实现了抽象化。抽象化是编程中的一个关键概念,它允许编程者通过提供一个简化的模型来隐藏复杂的细节。在我们的例子中,其他开发者或未来的你不需要理解货币转换的具体实现就可以使用calculate_currency_difference函数。
4. 代码的可读性(Readability)
代码的组织方式使其更加易于阅读和理解。通过清晰命名的函数和变量,以及逻辑的分组,代码的目的和工作方式变得更容易被其他开发者(或未来的自己)理解。可读性是编程中的一个重要方面,因为它直接影响到代码的维护和更新的难易程度。
5. 函数式编程思想(Functional Programming)
虽然这个例子没有完全采用函数式编程的风格,但通过使用函数来封装独立的逻辑单元,它借鉴了函数式编程的一些理念。函数式编程强调通过函数来传递数据和操作,而不是依赖于共享的状态和可变的数据,这有助于减少错误和副作用。
总的来说,通过将计算逻辑封装在函数中,并提高代码的组织性和可读性,遵循了这些编程哲学和思想。这不仅使代码更加清晰和容易维护,也提升了其效率和可重用性。
举一反三
在遵循这些哲学和编程思想的基础上,可以通过以下技巧来提高自己的编程实践,让代码更加健壮、可维护和高效:
1. 进一步封装和抽象
- 创建通用函数:尝试发现代码中的重复模式,并将它们抽象成可复用的函数。例如,如果你经常需要解析不同格式的输入数据,可以创建一个通用的解析函数。
- 数据封装:使用类或结构体来管理数据,这样可以将数据和操作它们的方法组织在一起,增强代码的结构性和清晰度。
2. 优化数据处理
- 使用适当的数据结构:根据需要选择合适的数据结构,例如使用集合(Set)进行快速查找操作,或使用队列(Queue)和栈(Stack)来处理顺序数据。
- 避免过度计算:存储计算结果以避免不必要的重复计算,这种技术被称为缓存或记忆化。
3. 提高代码质量
- 代码复审和对等编程:定期进行代码复审,邀请同事或朋友检查你的代码。这不仅可以帮助发现潜在错误,还可以作为交流最佳实践的机会。
- 单元测试:编写单元测试来验证每个函数的行为,确保在修改代码后仍然能按预期工作。这有助于构建更加稳定和可靠的软件系统。
4. 写作干净且有意义的代码
- 自解释的变量和函数命名:使用描述性强的命名,使得其他读者能够仅通过名称理解变量和函数的用途。
- 保持函数专一:让每个函数只做一件事,保持其简短和专注。这样做不仅有助于代码复用,也使得维护和测试变得更容易。
5. 遵循设计模式
- 学习并应用设计模式:设计模式如工厂模式、单例模式、装饰器模式等,是解决特定问题场景的经典方法。合理应用设计模式可以提高代码的灵活性和可维护性。
6. 代码简洁性和性能
- 代码重构:定期重构代码,去除多余的复杂性,优化算法,使用更高效的方法解决问题。
- 性能考量:在编写代码时,考虑其性能影响,特别是在循环、递归调用和大量数据操作中。使用性能分析工具来找到瓶颈并进行优化。
感谢阅读。