为啥要分库分表
IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
垂直拆分
垂直分库:以表为依据,根据业务将不同的表拆分到不同的库里
垂直分表:以字段为依据,根据字段属性,将字段拆分到不同表里。

实现技术
shardingJDBC
基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
MyCat
数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
也不用考虑我们每一次需要连接哪个数据库,需要操作哪个数据库(直接访问MyCat),也不用在应用程序当中去集成任何第三方依赖,也不用做其他的编码和配置
mycat
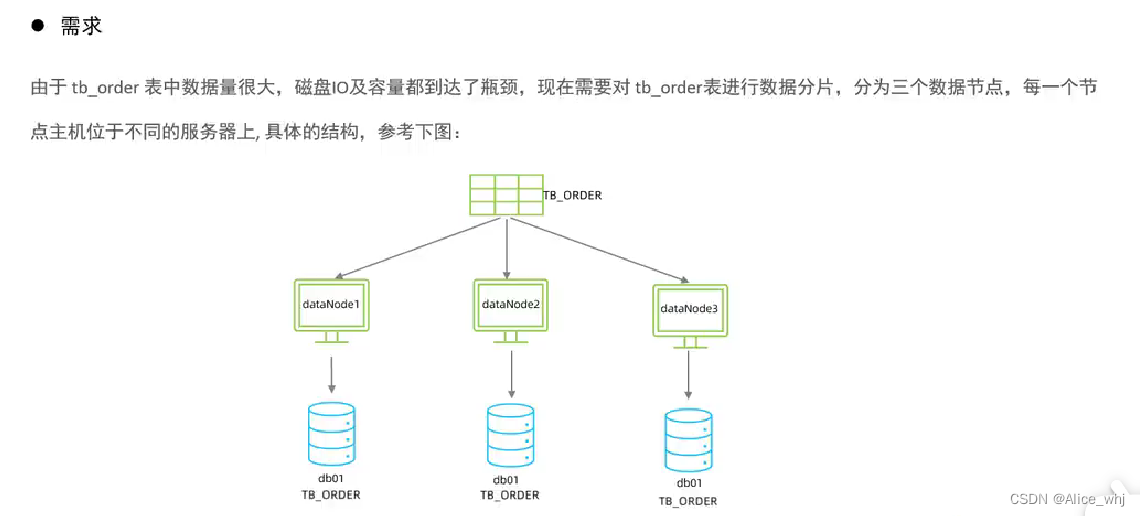


<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="tb_order" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1"
url="jdbc:mysql://192.168.200.210:3306??serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true"
user="root"
password="1234">
</writeHost>
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1"
url="jdbc:mysql://192.168.200.213:3306??serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true"
user="root"
password="1234">
</writeHost>
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1"
url="jdbc:mysql://192.168.200.214:3306??serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true"
user="root"
password="1234">
</writeHost>
</dataHost>
</mycat:schema>







分片规则







应用指定算法
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。


固定Hash算法
该算法类似于十进制求模运算,但是为二进制的操作
例如:取id的二进制低10位与1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十进制,也就是位于0-1023之间。
特点
如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
可以均匀分配,也可以非均匀分配。
分片字段必须为数字类型。

比如我们想插入一个id为515的数据,那515&1023(都转换成二进制),最终会算出一个二进制,将二进制再转换成十进制,并对应的对应的分片,下图是对应在第三个数据分片上]
字符串Hash解析
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片。
![在这里插入图片描述]
按天(日期)分片
按照日期及对应的时间周期来分片


按自然月分片
使用场景为按照月份来分片,每个自然月为一个分片。
如果查过了end时间,就需要从头再计算分片,比如插入的是4月份的数据,就会落在第一个节点当中