日志分析集群-8版本
作者:行癫(盗版必究)
第一部分:Elasticsearch

一:环境准备
1.简介
部署模式:es集群采用无主模式
es版本:8.13.4
jdk版本:使用es内嵌的jdk21,无需额外安装jdk环境
操作系统:Centos 7
2.环境
| IP地址 | 主机名 | 角色 |
|---|---|---|
| 10.9.12.83 | es-1.xingdian.com | master&data节点 |
| 10.9.12.84 | es-2.xingdian.com | master&data节点 |
| 10.9.12.85 | es-3.xingdian.com | master&data节点 |
二:服务器配置
1.创建用户
es不能使用root用户进行部署,故创建新用户管理es集群
# 添加一个用户 elasticsearch ,密码 elasticsearch
[root@es-1 ~]# useradd elasticsearch && echo elasticsearch|passwd --stdin elasticsearch
2.本地解析
[root@es-1 ~]# vim /etc/hosts
10.9.12.83 es-1.xingdian.com
10.9.12.84 es-2.xingdian.com
10.9.12.85 es-3.xingdian.com
3.系统优化
优化最大进程数,最大文件打开数,优化虚拟内存
[root@es-1 ~]# vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 6553
[root@es-1 ~]# vim /etc/sysctl.conf
vm.max_map_count=262144
[root@es-1 ~]# sysctl -p
三:集群部署
1.获取安装包
官网获取
2.解压安装
[root@es-1 ~]# tar -xf elasticsearch-8.13.4-linux-x86_64.tar.gz -C /usr/local
[root@es-1 ~]# mv /usr/local/elasticsearch-8.13.4 /usr/local/es
[root@es-1 ~]# chown -R elasticsearch.elasticsearch /usr/local/es
3.配置环境变量
[root@es-1 ~]# vim /etc/profile
export JAVA_HOME=/usr/local/es/jdk
export ES_HOME=/usr/local/es
export PATH=$PATH:$ES_HOME/bin:$JAVA_HOME/bin
# 刷新环境变量
[root@es-1 ~]# source /etc/profile
4.创建目录
目录用来存储数据和存放证书并赋予权限
[root@es-1 ~]# mkdir -p /usr/local/es/data
[root@es-1 ~]# mkdir -p /usr/local/es/config/certs
[root@es-1 ~]# chown -R elasticsearch:elasticsearch /usr/local/es
注意:截至到目前为止,所有节点服务器的操作都是一致的
5.签发证书
# 在第一台服务器节点 es-1.xingdian.com 设置集群多节点通信密钥
# 切换用户
[root@es-1 ~]# su - elasticsearch
[elasticsearch@es-1 ~]$ cd /usr/local/es/bin
[elasticsearch@es-1 bin]$./elasticsearch-certutil ca
warning: ignoring JAVA_HOME=/usr/local/es/jdk; using bundled JDK
This tool assists you in the generation of X.509 certificates and certificate
signing requests for use with SSL/TLS in the Elastic stack.
The 'ca' mode generates a new 'certificate authority'
This will create a new X.509 certificate and private key that can be used
to sign certificate when running in 'cert' mode.
Use the 'ca-dn' option if you wish to configure the 'distinguished name'
of the certificate authority
By default the 'ca' mode produces a single PKCS#12 output file which holds:
* The CA certificate
* The CAs private key
If you elect to generate PEM format certificates (the -pem option), then the output will
be a zip file containing individual files for the CA certificate and private key
Please enter the desired output file [elastic-stack-ca.p12]: # 回车即可
Enter password for elastic-stack-ca.p12 : # 回车即可
# 用 ca 证书签发节点证书,过程中需按三次回车键,生成目录:es的home:/usr/local/es/
[elasticsearch@es-1 bin]$ ./elasticsearch-certutil cert --ca elastic-stack-ca.p12
If you specify any of the following options:
* -pem (PEM formatted output)
* -multiple (generate multiple certificates)
* -in (generate certificates from an input file)
then the output will be be a zip file containing individual certificate/key files
Enter password for CA (elastic-stack-ca.p12) : # 回车即可
Please enter the desired output file [elastic-certificates.p12]: # 回车即可
Enter password for elastic-certificates.p12 : # 回车即可
Certificates written to /usr/local/es/elastic-certificates.p12
This file should be properly secured as it contains the private key for
your instance.
This file is a self contained file and can be copied and used 'as is'
For each Elastic product that you wish to configure, you should copy
this '.p12' file to the relevant configuration directory
and then follow the SSL configuration instructions in the product guide.
For client applications, you may only need to copy the CA certificate and
configure the client to trust this certificate.
# 将生成的证书文件移动到 config/certs 目录中
[elasticsearch@es-1 bin]$ cd /usr/local/es/
[elasticsearch@okd elasticsearch-8.11.0]$ ls -l | grep "elastic-"
-rw------- 1 elasticsearch elasticsearch 3596 Feb 10 16:05 elastic-certificates.p12
-rw------- 1 elasticsearch elasticsearch 2672 Feb 10 16:03 elastic-stack-ca.p12
[elasticsearch@es-1 es]$
[elasticsearch@es-1 es]$ mv elastic-certificates.p12 config/certs/
[elasticsearch@es-1 es]$ mv elastic-stack-ca.p12 config/certs/
6.设置集群多节点HTTP证书
# 签发 Https 证书
[elasticsearch@es-1 es]$ cd /usr/local/es/bin/
[elasticsearch@es-1 bin]$ ./elasticsearch-certutil http
warning: ignoring JAVA_HOME=/usr/local/es/jdk; using bundled JDK
## Elasticsearch HTTP Certificate Utility
The 'http' command guides you through the process of generating certificates
for use on the HTTP (Rest) interface for Elasticsearch.
This tool will ask you a number of questions in order to generate the right
set of files for your needs.
## Do you wish to generate a Certificate Signing Request (CSR)?
A CSR is used when you want your certificate to be created by an existing
Certificate Authority (CA) that you do not control (that is, you do not have
access to the keys for that CA).
If you are in a corporate environment with a central security team, then you
may have an existing Corporate CA that can generate your certificate for you.
Infrastructure within your organisation may already be configured to trust this
CA, so it may be easier for clients to connect to Elasticsearch if you use a
CSR and send that request to the team that controls your CA.
If you choose not to generate a CSR, this tool will generate a new certificate
for you. That certificate will be signed by a CA under your control. This is a
quick and easy way to secure your cluster with TLS, but you will need to
configure all your clients to trust that custom CA.
######################################################
# 是否生成CSR,选择 N ,不需要 #
######################################################
Generate a CSR? [y/N]N
## Do you have an existing Certificate Authority (CA) key-pair that you wish to use to sign your certificate?
If you have an existing CA certificate and key, then you can use that CA to
sign your new http certificate. This allows you to use the same CA across
multiple Elasticsearch clusters which can make it easier to configure clients,
and may be easier for you to manage.
If you do not have an existing CA, one will be generated for you.
######################################################
# 是否使用已经存在的CA证书,选择 y ,因为已经创建签发好了CA #
######################################################
Use an existing CA? [y/N]y
## What is the path to your CA?
Please enter the full pathname to the Certificate Authority that you wish to
use for signing your new http certificate. This can be in PKCS#12 (.p12), JKS
(.jks) or PEM (.crt, .key, .pem) format.
######################################################
# 指定CA证书的路径地址,CA Path:后写绝对路径 #
######################################################
CA Path: /usr/local/es/config/certs/elastic-stack-ca.p12
Reading a PKCS12 keystore requires a password.
It is possible for the keystore's password to be blank,
in which case you can simply press <ENTER> at the prompt
######################################################
# 设置密钥库的密码,直接 回车 即可 #
######################################################
Password for elastic-stack-ca.p12:
## How long should your certificates be valid?
Every certificate has an expiry date. When the expiry date is reached clients
will stop trusting your certificate and TLS connections will fail.
Best practice suggests that you should either:
(a) set this to a short duration (90 - 120 days) and have automatic processes
to generate a new certificate before the old one expires, or
(b) set it to a longer duration (3 - 5 years) and then perform a manual update
a few months before it expires.
You may enter the validity period in years (e.g. 3Y), months (e.g. 18M), or days (e.g. 90D)
######################################################
# 设置证书的失效时间,这里的y表示年,5y则代表失效时间5年 #
######################################################
For how long should your certificate be valid? [5y] 5y
## Do you wish to generate one certificate per node?
If you have multiple nodes in your cluster, then you may choose to generate a
separate certificate for each of these nodes. Each certificate will have its
own private key, and will be issued for a specific hostname or IP address.
Alternatively, you may wish to generate a single certificate that is valid
across all the hostnames or addresses in your cluster.
If all of your nodes will be accessed through a single domain
(e.g. node01.es.example.com, node02.es.example.com, etc) then you may find it
simpler to generate one certificate with a wildcard hostname (*.es.example.com)
and use that across all of your nodes.
However, if you do not have a common domain name, and you expect to add
additional nodes to your cluster in the future, then you should generate a
certificate per node so that you can more easily generate new certificates when
you provision new nodes.
######################################################
# 是否需要为每个节点都生成证书,选择 N 无需每个节点都配置证书 #
######################################################
Generate a certificate per node? [y/N]N
## Which hostnames will be used to connect to your nodes?
These hostnames will be added as "DNS" names in the "Subject Alternative Name"
(SAN) field in your certificate.
You should list every hostname and variant that people will use to connect to
your cluster over http.
Do not list IP addresses here, you will be asked to enter them later.
If you wish to use a wildcard certificate (for example *.es.example.com) you
can enter that here.
Enter all the hostnames that you need, one per line.
######################################################
# 输入需连接集群节点主机名信息,一行输入一个IP地址,空行回车结束 #
######################################################
When you are done, press <ENTER> once more to move on to the next step.
es-1.xingdian.com
es-2.xingdian.com
es-3.xingdian.com
You entered the following hostnames.
- es-1.xingdian.com
- es-2.xingdian.com
- es-3.xingdian.com
####################################################
# 确认以上是否为正确的配置,输入 Y 表示信息正确 #
####################################################
Is this correct [Y/n]Y
## Which IP addresses will be used to connect to your nodes?
If your clients will ever connect to your nodes by numeric IP address, then you
can list these as valid IP "Subject Alternative Name" (SAN) fields in your
certificate.
If you do not have fixed IP addresses, or not wish to support direct IP access
to your cluster then you can just press <ENTER> to skip this step.
Enter all the IP addresses that you need, one per line.
####################################################
# 输入需连接集群节点IP信息,一行输入一个IP地址,空行回车结束 #
####################################################
When you are done, press <ENTER> once more to move on to the next step.
10.9.12.83
10.9.12.84
10.9.12.85
You entered the following IP addresses.
- 10.9.12.83
- 10.9.12.84
- 10.9.12.85
####################################################
# 确认以上是否为正确的配置,输入 Y 表示信息正确 #
####################################################
Is this correct [Y/n]Y
## Other certificate options
The generated certificate will have the following additional configuration
values. These values have been selected based on a combination of the
information you have provided above and secure defaults. You should not need to
change these values unless you have specific requirements.
Key Name: es-1.xingdian.com
Subject DN: CN=es-1.xingdian.com
Key Size: 2048
####################################################
# 是否要更改以上这些选项,选择 N ,不更改证书选项配置 #
####################################################
Do you wish to change any of these options? [y/N]N
## What password do you want for your private key(s)?
Your private key(s) will be stored in a PKCS#12 keystore file named "http.p12".
This type of keystore is always password protected, but it is possible to use a
blank password.
####################################################
# 是否要给证书加密,不需要加密,两次 回车 即可 #
####################################################
If you wish to use a blank password, simply press <enter> at the prompt below.
Provide a password for the "http.p12" file: [<ENTER> for none]
## Where should we save the generated files?
A number of files will be generated including your private key(s),
public certificate(s), and sample configuration options for Elastic Stack products.
These files will be included in a single zip archive.
What filename should be used for the output zip file? [/usr/local/es/elasticsearch-ssl-http.zip]
Zip file written to /usr/local/es/elasticsearch-ssl-http.zip
7.分发证书
# 解压
[elasticsearch@es-1 bin]$ cd /usr/local/es/
[elasticsearch@es-1 es]$ unzip elasticsearch-ssl-http.zip
# 移动证书
[elasticsearch@es-1 es]$ mv ./elasticsearch/http.p12 config/certs/
[elasticsearch@es-1 es]$ mv ./kibana/elasticsearch-ca.pem config/certs/
# 将证书分发到其他节点02 03
[elasticsearch@es-1 es]$ cd /usr/local/es/config/certs
[elasticsearch@es-1 certs]$ ll
total 16
-rw------- 1 elasticsearch elasticsearch 3596 Feb 10 16:05 elastic-certificates.p12
-rw-rw-r-- 1 elasticsearch elasticsearch 1200 Feb 10 16:13 elasticsearch-ca.pem
-rw------- 1 elasticsearch elasticsearch 2672 Feb 10 16:03 elastic-stack-ca.p12
-rw-rw-r-- 1 elasticsearch elasticsearch 3652 Feb 10 16:13 http.p12
[elasticsearch@es-1 certs]$ scp * es-2.xingdian.com:/usr/local/es/config/certs/
[elasticsearch@es-1 certs]$ scp * es-3.xingdian.com:/usr/local/es/config/certs/
8.修改配置
[elasticsearch@es-1 certs]$ cd /usr/local/es/config/
[elasticsearch@es-1 config]$ vim elasticsearch.yml
cluster.name: xingdian-es
node.name: es-1.xingdian.com
path.data: /usr/local/es/data
path.logs: /usr/local/es/logs
network.host: 0.0.0.0
http.port: 9200
# 种子主机,在选举时用于发现其他主机的,最好配置多个
discovery.seed_hosts: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
cluster.initial_master_nodes: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: /usr/local/es/config/certs/http.p12
keystore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/http.p12
truststore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: /usr/local/es/config/certs/elastic-certificates.p12
keystore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/elastic-certificates.p12
truststore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
http.host: [_local_, _site_]
ingest.geoip.downloader.enabled: false
xpack.security.http.ssl.client_authentication: none
注意:
1.xpack.security.http.ssl和xpack.security.transport.ssl后的子配置需要空一格,遵循yml的格式要求
2.如果不需要后续的http证书认证或者用户密码认证可以将以下参数的值改为false
xpack.security.http.ssl:
enabled: false
xpack.security.transport.ssl:
enabled: false
3.如果后续在业务场景中遇到了跨域的问题,解决跨域的问题添加以下参数
http.cors.enabled: true
http.cors.allow-origin: "*"
9.参数解释
cluster.name: xingdian-es
含义: 指定Elasticsearch集群的名称。在此例中,集群名为xingdian-es,所有想要加入此集群的节点都应配置相同的集群名称。
node.name: es-1.xingdian.com
含义: 设置单个节点的名称。这里将节点命名为es-1.xingdian.com,有助于标识和管理集群中的不同节点。
path.data: /usr/local/es/data
含义: 指定Elasticsearch存储数据的路径。数据文件将保存在/usr/local/es/data目录下。
path.logs: /usr/local/es/logs
含义: 配置日志文件的存放路径,即日志将会被写入到/usr/local/es/logs目录中。
network.host: 0.0.0.0
含义: 设置监听所有可用网络接口的IP地址,允许Elasticsearch从任何网络接口接收连接请求。
http.port: 9200
含义: 指定HTTP服务监听的端口号,这里是9200,是Elasticsearch默认的HTTP访问端口。
discovery.seed_hosts: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
含义: 列出初始种子节点的地址,用于集群启动时发现其他节点。这有助于新节点加入或现有节点重启后找到集群。
cluster.initial_master_nodes: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
含义: 在初次启动或集群完全重启后,指定哪些节点可以成为初始主节点,用于选举过程。
xpack.security.enabled: true
含义: 启用X-Pack安全特性,提供认证、授权、加密传输等功能,增强Elasticsearch的安全性。
xpack.security.http.ssl.enabled: true
含义: 开启HTTP通信的SSL加密,确保客户端与Elasticsearch之间的数据传输安全。
keystore.path, truststore.path, keystore.password, truststore.password
含义: 分别指定了SSL证书的存放路径和密钥库、信任库的密码。这些设置用于保护SSL连接的密钥和信任信息。
http.host: [local, site]
含义: 指定HTTP服务可以绑定的主机名,_local_表示绑定本地主机,_site_允许绑定所有公开站点地址。
ingest.geoip.downloader.enabled: false
含义: 禁用了GeoIP数据库的自动下载功能。GeoIP用于地理定位,禁用后需要手动管理数据库更新。
xpack.security.http.ssl.client_authentication: none
含义: 设置客户端认证方式为“无”,意味着HTTP客户端连接到Elasticsearch时不需要提供证书进行认证。
10.JVM参数调整
[elasticsearch@es-1 config]$ vim jvm.options
-Xms2g
-Xmx2g
注意:该值为真实内存的1/2
11.启动集群
[elasticsearch@es-1 es]$ nohup /usr/local/es/bin/elasticsearch &
[elasticsearch@es-2 es]$ nohup /usr/local/es/bin/elasticsearch &
[elasticsearch@es-3 es]$ nohup /usr/local/es/bin/elasticsearch &
12.设置登录密码
# 手工指定elastic的新密码 (-i参数)
[elasticsearch@okd ~]$ /usr/local/es/bin/elasticsearch-reset-password -u elastic -i
warning: ignoring JAVA_HOME=/usr/local/es/jdk; using bundled JDK
bThis tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
Did not understand answer 'by'
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]: # 输入用户elastic的密码
Re-enter password for [elastic]: # 输入用户elastic的密码
Password for the [elastic] user successfully reset.
13.浏览器访问
https://es-1.xingdian.com:9200
https://es-2.xingdian.com:9200
https://es-3.xingdian.com:9200
账户密码为:elastic 密码自己设定的
14.HEAD插件访问
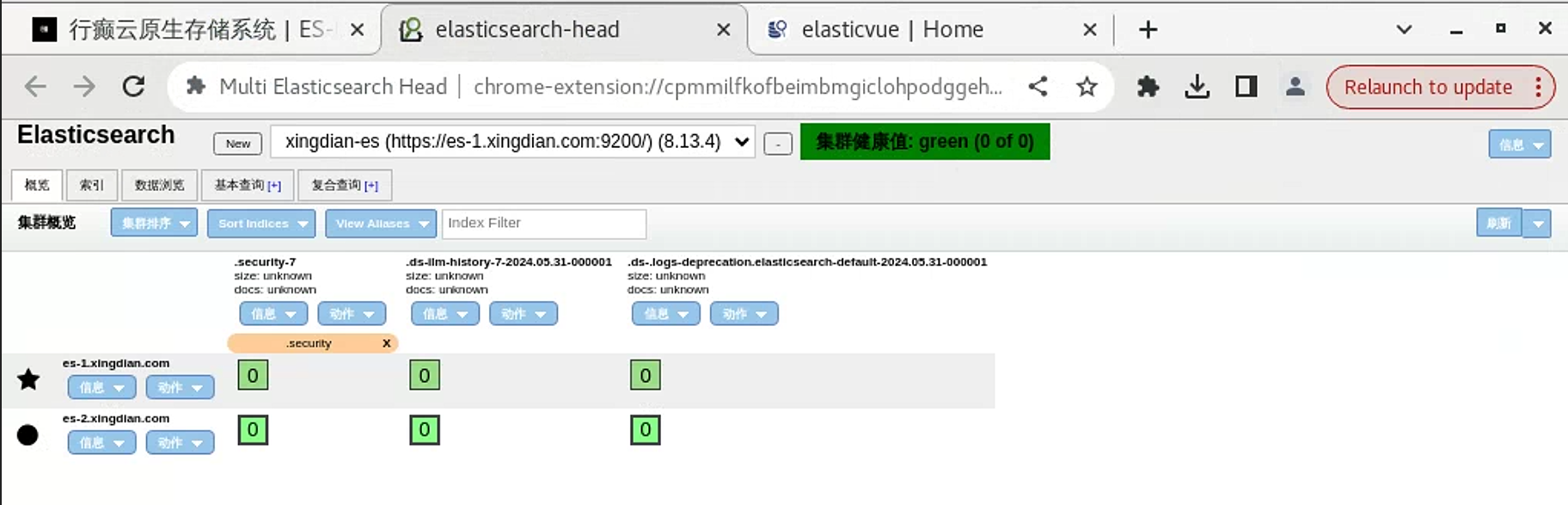

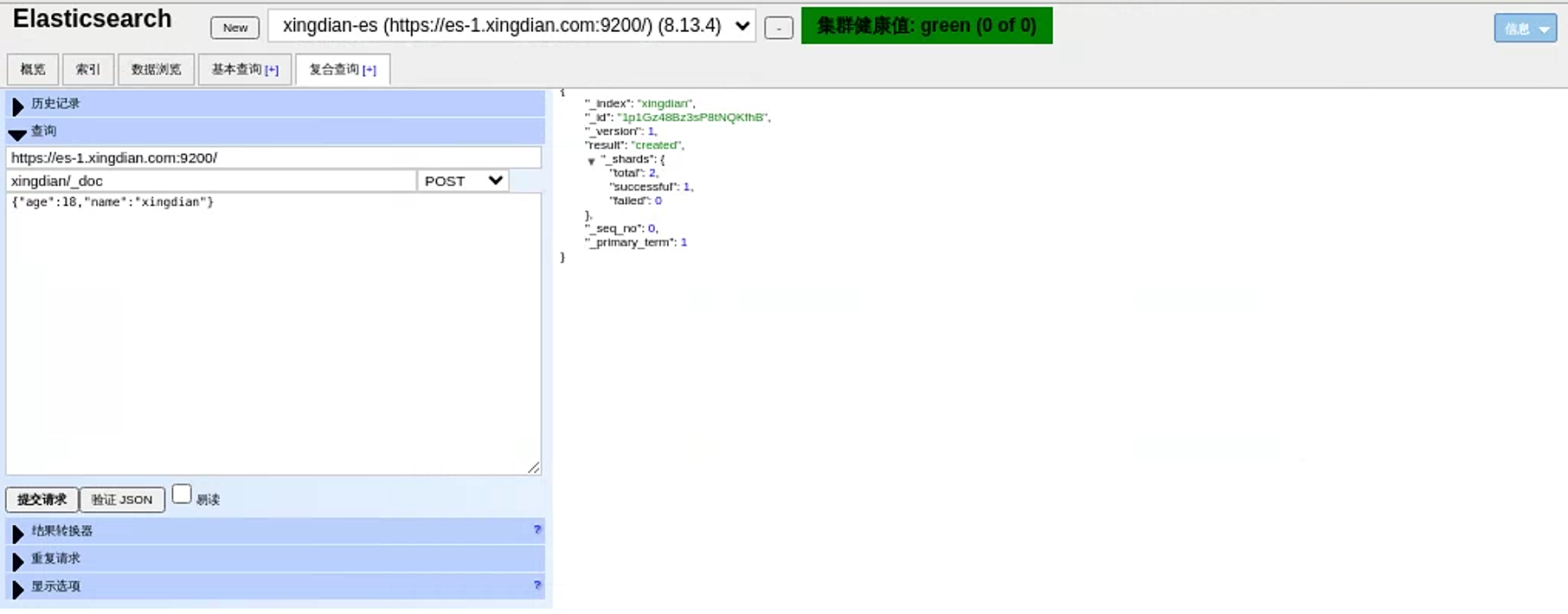
15.模拟数据插入
模拟post请求插入数据
索引名为:xingdian/_doc xingdian为自定义 _doc为固定格式
内容:采用json格式 {“user”:“xingdian”,“mesg”:“hello world”}
四:基本概念
1.ES与传统数据的区别
一个ES集群可以包含多个索引(数据库),每个索引又包含了很多类型(表),类型中包含了很多文档(行),每个文档使用 JSON 格式存储数据,包含了很多字段(列)。
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库>表>行>列 | 索引>类型>文档>字段 |
2.基本概念
索引(index)
ES将数据存储于一个或多个索引中。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,索引由其名称(必须为全小写字符)进行标识。一个ES集群中可以按需创建任意数目的索引。
类型(type)
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。类比传统的关系型数据库领域来说,类型相当于“表”。
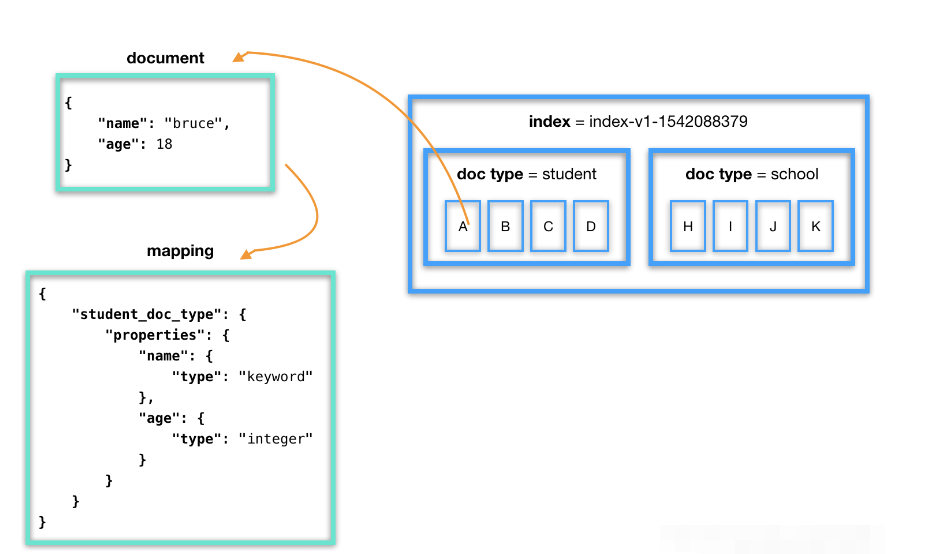
文档(document)
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”,文档基于JSON格式进行表示。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。类比传统的关系型数据库领域来说,类型相当于“行”。
集群(cluster)
一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。
节点(node)
一个运行中的 Elasticsearch 实例称为一个节点。es中的节点分为三种类型:
主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
注意:
使用index和doc_type来组织数据。doc_type中的每条数据称为一个document,是一个JSON Object
ES分布式搜索,传统数据库遍历式搜索
案例解释:
要计算出2.38亿会员中有多少80后的已婚的北京男士:
传统数据库执行时间: 5个小时左右
ES执行时间:1分钟
分片(Shards)
分片是Elasticsearch进行数据分布和扩展的基础。每个索引都可以被分割成多个分片,每个分片其实是一个独立的索引。分片使得Elasticsearch可以把巨大的数据集分散存储在多个节点上,这样可以实现:
水平扩展:随着数据量的增加,可以通过增加更多的节点来分摊数据和负载,从而提高处理能力
提升性能:搜索操作可以并行在多个分片上执行,每个分片处理的速度更快,整体搜索性能得以提升
副本(Replicas)
副本是分片的复制,主要用于提高数据的可用性和搜索查询的并发处理能力。每个分片都可以有一个或多个副本,这些副本分布在不同的节点上,从而提供了:
数据可用性:当某个节点发生故障时,该节点上的分片如果有副本存在于其他节点上,那么这些副本可以保证数据不会丢失,并且服务还可以继续运行
负载均衡:读取操作(如搜索请求)可以在所有副本之间进行负载均衡,这样可以提高查询的吞吐量和响应速度
定义分片和副本
创建索引时指定分片和副本数
当您通过Elasticsearch的REST API创建一个新的索引时,可以在请求体中使用settings部分来指定该索引的分片数(number_of_shards)和副本数(number_of_replicas)。以下是一个具体的示例:
PUT /my_index
{
"settings": {
"index": {
"number_of_shards": 3, # 指定该索引将有3个主分片
"number_of_replicas": 2 # 每个主分片将有2个副本分片
}
}
}
这个例子中,PUT /my_index是创建名为my_index的索引的请求。在请求体中,settings部分指出这个索引将被分成3个主分片,并且每个主分片将会有2个副本分片。这意味着,总共会有9个分片(3个主分片 + 6个副本分片)被分布在集群中
主分片数量:一旦索引被创建,其主分片的数量就无法更改。因此,在创建时应谨慎选择合适的分片数量。
副本数量:与主分片数量不同,副本的数量是可以动态调整的。如果需要更多的数据冗余或查询吞吐量,可以增加副本的数量。
伸缩性与性能:选择分片和副本的数量时需要考虑数据量、查询负载和集群的硬件资源。过多的分片可能会增加集群的管理开销,而过少的分片可能会限制数据和查询的伸缩性。
分片数的确定
数据量预估:估计索引的总数据量大小。一般来说,每个分片处理20GB到50GB数据是比较理想的。这不是固定规则,但可以作为一个起点。
硬件资源:考虑你的硬件资源,尤其是内存和CPU。分片越多,消耗的资源也越多。确保你的Elasticsearch集群有足够的资源来处理这些分片。
写入吞吐量:如果你的应用会有大量的写入操作,更多的分片可能有助于提高写入性能,因为可以并行写入多个分片。
查询性能:更多的分片意味着查询可以并行于更多的分片上执行,这可能会提高查询性能。但是,如果每个查询都要访问大多数分片,那么管理过多的分片会减慢查询速度。
副本数的确定
数据可用性:至少有一个副本可以确保当某个节点失败时,数据不会丢失,并且Elasticsearch服务仍然可用。
读取性能:更多的副本意味着更高的读取吞吐量,因为读取请求可以在多个副本之间分配。如果你的应用主要是读取密集型的,增加副本数可以提高查询性能。
集群负载:考虑集群的整体负载。增加副本会提高数据冗余和读取性能,但也会增加存储需求和网络流量,因此需要确保你的硬件资源可以支持。
五:ES集群架构
1.Discovery发现
发现是集群形成模块寻找其他节点以形成集群的过程。当您启动 Elasticsearch 节点或节点认为主节点发生故障时,此过程将运行,并持续到找到主节点或选出新的主节点为止。
此过程从来自一个或多个种子主机提供商的种子地址列表开始,同时包含最后已知集群中所有符合主节点资格的节点的地址。
此过程分为两个阶段:首先,每个节点通过连接到每个地址并尝试识别其所连接的节点以及验证其是否符合主节点资格来探测种子地址。其次,如果成功,它将与远程节点共享其所有已知符合主节点资格的对等节点的列表,然后远程节点依次与其对等节点进行响应。然后,节点探测它刚刚发现的所有新节点,请求其对等节点,依此类推。
如果节点不符合主节点资格,则它将继续此发现过程,直到发现选举的主节点。如果没有发现选举的主节点,则节点将重试,之后discovery.find_peers_interval默认为1s 。
如果节点符合主节点条件,则它会继续此发现过程,直到发现当选主节点或发现足够多的无主主节点来完成选举。如果上述两种情况都发生得不够快,则节点将重试,之后discovery.find_peers_interval默认为1s。
一旦主节点被选出,它通常会继续担任主节点,直到被故意停止。如果 故障检测确定集群出现故障,它也可能会停止担任主节点。当某个节点不再是主节点时,它会再次开始发现过程。
2.种子主机提供商
默认情况下,集群形成模块提供两个种子主机提供程序来配置种子节点列表
基于设置的种子主机提供程序
基于文件的种子主机提供程序
种子主机提供程序使用设置进行配置discovery.seed_providers ,默认为基于设置的主机提供程序
基于设置的种子主机提供商:
基于设置的种子主机提供程序使用节点设置来配置种子节点地址的静态列表。这些地址可以作为主机名或 IP 地址指定;在每轮发现期间,指定为主机名的主机都会解析为 IP 地址。
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
或者:
discovery.seed_hosts: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
基于文件的种子主机提供商:
基于文件的种子主机提供程序通过外部文件配置主机列表。Elasticsearch会在文件更改时重新加载此文件,这样种子节点列表就可以动态更改,而无需重新启动每个节点。例如,这为在Docker容器中运行的 Elasticsearch 实例提供了一种方便的机制,当节点启动时可能不知道这些IP地址时,可以动态地为其提供要连接的IP地址列表。
discovery.seed_providers: file
然后按照下面描述的格式创建一个文件$ES_PATH_CONF/unicast_hosts.txt。每当对文件进行更改时,Elasticsearch都会获取新的更改并使用新的主机列表。
该unicast_hosts.txt文件每行包含一个节点条目。每个节点条目由主机(主机名或 IP 地址)和一个可选的传输端口号组成。如果指定了端口号,它必须紧跟在主机之后(在同一行上)。
允许使用主机名代替 IP 地址,并由 DNS 解析,如上所述。IPv6 地址必须在括号中给出,如果需要,端口号也应放在括号后面
cat $ES_PATH_CONF/unicast_hosts.txt
10.10.10.5
10.10.10.6:9305
10.10.10.5:10005
# an IPv6 address
[2001:0db8:85a3:0000:0000:8a2e:0370:7334]:9301
3.基于群体的决策
选举主节点和更改集群状态是符合主节点条件的节点必须协同执行的两个基本任务。即使某些节点发生故障,这些活动也必须能够稳健地运行。Elasticsearch 通过在收到来自法定人数(集群中符合主节点条件的节点的子集)的响应后将每个操作视为成功来实现这种稳健性。仅要求一部分节点响应的优点是,这意味着某些节点可以发生故障而不会阻止集群继续运行。法定人数是经过精心选择的,即集群被分成两部分,以至于每个部分可能做出与另一部分不一致的决策。
Elasticsearch 允许您向正在运行的集群添加和删除符合主节点条件的节点。在许多情况下,您只需根据需要启动或停止节点即可完成此操作。
随着节点的添加或删除,Elasticsearch 通过更新集群的投票配置来保持最佳容错水平,投票配置是一组符合主节点条件的节点,在做出诸如选举新主节点或提交新集群状态等决策时,这些节点的响应会被计算在内。只有在投票配置中超过一半的节点做出响应后,才会做出决策。通常,投票配置与集群中当前所有符合主节点条件的节点集相同。但是,在某些情况下,它们可能会有所不同。
为了确保集群保持可用,不能同时停止投票配置中的一半或更多节点。只要超过一半的投票节点可用,集群仍可正常工作。这意味着,如果有三个或四个主节点,集群可以容忍其中一个不可用。如果有两个或更少的主节点,它们必须全部保持可用。
如果您同时停止投票配置中的一半或更多节点,则集群将不可用,直到您使足够多的节点重新联机以再次形成法定人数。当集群不可用时,任何剩余节点都会在其日志中报告它们无法发现或选举主节点。
4.主节点选举
Elasticsearch 使用选举流程来商定选举的主节点,无论是在启动时还是在现有选举主节点发生故障时。任何符合主节点条件的节点都可以启动选举,通常第一次选举将会成功。只有当两个节点恰好同时开始选举时,选举才会失败,因此每个节点都会随机安排选举以降低发生这种情况的概率。节点将重试选举,直到选出主节点,如果失败则放弃,以便最终选举能够成功(概率任意高)。主节点选举的安排由主节点选举设置控制。
5.投票配置
每个 Elasticsearch 集群都有一个投票配置,它是一组 符合主节点条件的节点,在做出诸如选举新主节点或提交新集群状态等决策时,这些节点的响应会被计入。只有在投票配置中的大多数节点(超过一半)响应后,才会做出决策。通常,投票配置与集群中当前所有符合主节点条件的节点集相同。但是,在某些情况下,它们可能会有所不同。
较大的投票配置通常更具弹性,因此 Elasticsearch 通常倾向于在符合主节点资格的节点加入集群后将其添加到投票配置中。同样,如果投票配置中的节点离开集群,并且集群中还有另一个不符合主节点资格的节点不在投票配置中,则最好交换这两个节点。因此,投票配置的大小保持不变,但其弹性会增加。
在节点离开集群后自动从投票配置中删除节点并不是那么简单。不同的策略有不同的优点和缺点,可以使用设置来控制投票配置是否自动cluster.auto_shrink_voting_configuration
如果cluster.auto_shrink_voting_configuration设置为true(这是默认值和推荐值)并且集群中至少有三个主合格节点,则只要除一个主合格节点之外的所有节点都健康,Elasticsearch 仍然能够处理集群状态更新
在某些情况下,Elasticsearch 可能会容忍多个节点丢失,但这并不能保证在所有故障序列下都能做到。如果设置cluster.auto_shrink_voting_configuration为false,则必须手动从投票配置中移除已离开的节点。
配置参数如下:
cluster.auto_shrink_voting_configuration
(动态)控制投票配置是否自动删除已离开的节点(只要它仍包含至少 3 个节点)。默认值为true。如果设置为,投票配置永远不会自动缩小,您必须使用投票配置排除 APIfalse手动删除已离开的节点 。
cluster.election.back_off_time
(静态)设置每次选举失败时选举前等待时间的上限增加量。请注意,这是线性退避。默认值为 100ms。更改此设置(默认设置)可能会导致您的集群无法选举主节点。
cluster.election.duration
(静态)设置每次选举允许花费多长时间,之后节点才会认为选举失败并安排重试。默认值为500ms。更改此设置可能会导致您的集群无法选举出主节点。
cluster.election.initial_timeout
(静态)设置节点在首次尝试选举之前(或当选主节点失败后)等待的时间上限。默认值为 100ms。更改此设置(默认设置)可能会导致您的集群无法选举主节点。
cluster.election.max_timeout
(静态)设置节点在尝试首次选举之前等待时间的最大上限,以便长时间持续的网络分区不会导致选举过于稀疏。默认值为10s。更改此设置(默认设置)可能会导致您的集群无法选举主节点。
cluster.fault_detection.follower_check.interval
(静态)设置当选主节点在集群中每个其他节点的跟随节点检查之间等待的时间。默认为1s。更改此设置(默认设置除外)可能会导致集群变得不稳定。
cluster.fault_detection.follower_check.timeout
(静态)设置当选主节点等待跟随者检查响应的时间,超过该时间则认为主节点失败。默认为10s。更改此设置可能会导致集群变得不稳定。
cluster.fault_detection.follower_check.retry_count
(静态)设置每个节点必须发生多少次连续的跟随者检查失败,当选主节点才会认为该节点有故障并将其从集群中移除。默认为3。更改此设置可能会导致集群变得不稳定。
cluster.fault_detection.leader_check.interval
(静态)设置每个节点在检查当选主节点之间等待的时间。默认为 1s。更改此设置可能会导致集群变得不稳定。
cluster.fault_detection.leader_check.timeout
(静态)设置每个节点等待当选主节点对领导者检查的响应的时间,超过该时间则认为主节点已发生故障。默认为10s。更改此设置可能会导致集群变得不稳定。
cluster.fault_detection.leader_check.retry_count
(静态)设置必须发生多少次连续的领导者检查失败,节点才会认为当选主节点有故障,并尝试查找或选举新主节点。默认为3。更改此设置(默认设置)可能会导致集群变得不稳定。
cluster.follower_lag.timeout
(静态)设置主节点等待从滞后节点接收集群状态更新确认的时间。默认值为90s。如果节点在此时间段内未成功应用集群状态更新,则该节点被视为发生故障并从集群中删除。请参阅 发布集群状态。
cluster.max_voting_config_exclusions
(动态)设置一次投票配置排除的数量限制。默认值为10。请参阅在集群中添加和删除节点。
cluster.publish.info_timeout
(静态)设置主节点等待每个集群状态更新完全发布到所有节点的时间,然后记录一条消息,表明某些节点响应缓慢。默认值为10s。
cluster.publish.timeout
(静态)设置主节点等待每个集群状态更新完全发布到所有节点的时间,除非discovery.type设置为 single-node。默认值为30s。请参阅发布集群状态。
cluster.discovery_configuration_check.interval
(静态)设置某些检查的间隔,这些检查将记录有关不正确的发现配置的警告。默认值为30s。
cluster.join_validation.cache_timeout
(静态)当一个节点请求加入集群时,当选的主节点会向其发送一份最新集群状态的副本,以检测可能阻止新节点加入集群的某些问题。主节点会缓存其发送的状态,如果另一个节点不久后加入集群,则使用缓存的状态。此设置控制主节点等待清除此缓存的时间。默认为60s。
通常,集群中的主节点数应为奇数。如果为偶数,Elasticsearch 会将其中一个节点排除在投票配置之外,以确保其大小为奇数
6.引导集群
首次启动 Elasticsearch 集群时,需要在集群中的一个或多个主节点上明确定义初始主节点集。这称为集群引导。这仅在集群首次启动时才需要。加入正在运行的集群的新启动节点从集群的选定主节点获取此信息。
cluster.initial_master_nodes初始的符合主节点资格的节点集在设置中定义 。这应该设置为一个列表,其中包含每个符合主节点资格的以下项目之一:
节点名称
node.name如果未设置,则默认为节点的主机名
集群形成后,cluster.initial_master_nodes从每个节点的配置中删除该设置。不应为非主节点、加入现有集群的主节点或正在重新启动的节点设置该设置
配置使用如下:
创建新集群的最简单方法是选择一个主节点,该节点将自行引导到单节点集群中,然后所有其他节点将加入该集群
cluster.initial_master_nodes: master-a
对于容错集群引导,请使用所有符合主节点条件的节点。例如,如果您的集群有 3 个符合主节点条件的节点,节点名称master-a为,master-b则按master-c如下方式配置它们:
cluster.initial_master_nodes:
- master-a
- master-b
- master-c
选择集群名称:
此cluster.name设置允许您创建多个彼此独立的集群。节点在首次连接时会验证它们是否同意其集群名称,并且 Elasticsearch 只会从具有相同集群名称的节点组成集群。集群名称的默认值为elasticsearch,但建议将其更改为反映集群的逻辑名称。
开发模式下的自动引导:
默认情况下,每个节点在首次启动时都会自动引导到单节点集群。如果配置了以下任何设置,则不会进行自动引导:
discovery.seed_providers
discovery.seed_hosts
cluster.initial_master_nodes
注意:
一旦 Elasticsearch 节点加入现有集群或引导新集群,它就不会再加入其他集群。Elasticsearch 不会在集群形成后将单独的集群合并在一起,即使您随后尝试将所有节点配置为单个集群。这是因为没有办法将这些单独的集群合并在一起而不丢失数据。
六:IK分词器
1.简介
ES IK分词器是一种基于中文文本的分词器,它是Elasticsearch中文分词的一种实现。它采用了自然语言处理技术,可以将中文文本进行切分,抽取出其中的词汇,从而提高搜索引擎对中文文本的搜索和检索效率。
ES IK分词器的原理是采用了一种叫做“正向最大匹配”(Forward Maximum Matching,简称FMM)和“逆向最大匹配”(Backward Maximum Matching,简称BMM)的分词算法,通过对文本进行多次切分,最终确定最优的分词结果。
ES IK分词器可以用于各种中文文本处理应用,包括搜索引擎、文本挖掘、信息检索等。它支持多种分词模式,包括最细粒度切分、智能切分和最大切分等模式,可以根据具体应用场景进行灵活配置。
2.分类
细粒度分词模式(ik_max_word):
在这种模式下,IK分词器会尽可能地按照词典中的词语进行最大长度匹配,将文本切分成连续的词语序列
这种模式适用于对文本进行细致的切分,尽可能将句子切分为最小的词语单元,获得更加精确的分词结果
智能分词模式(ik_smart):
在智能切分模式下,IK分词器会结合词典匹配和机器学习算法,根据上下文信息分词,保留词语的完整性
这种模式能够更好地处理一些特殊情况,如未登录词和新词等,提高了分词的准确性和适用性
3.下载地址
https://github.com/infinilabs/analysis-ik/releases/tag/Latest
4.安装插件
注意:
安装的插件版本需要跟elasticsearch的版本一致,否则无法安装或报错
安装完成后重启elasticsearch
[elasticsearch@es-1 es]$ bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.13.4
warning: ignoring JAVA_HOME=/usr/local/es/jdk; using bundled JDK
-> Installing https://get.infini.cloud/elasticsearch/analysis-ik/8.13.4
-> Downloading https://get.infini.cloud/elasticsearch/analysis-ik/8.13.4
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See https://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
-> Please restart Elasticsearch to activate any plugins installed
5.项目需求
如果对应的项目使用到了ES IK插件,我们需要在ES集群中构建IK环境
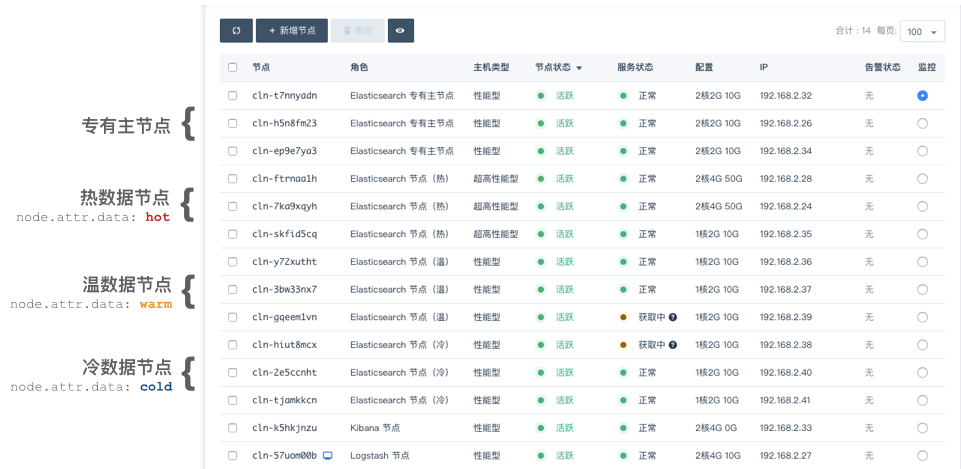
七:冷热温节点部署
1.简介
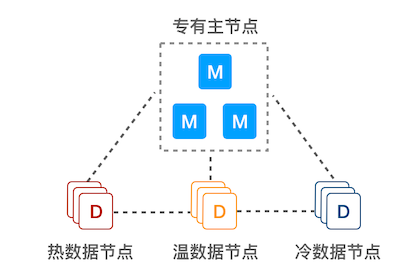
在某些大规模数据分析场景(比如时间数据分析),可以采用此架构:基于时间创建 index,然后持续地把温/冷数据迁移到相应的数据节点。
专有主节点:由于不保存数据,也就不参与索引和查询操作,不会被长 GC 干扰,负载可以保持在较低水平,能极大提高集群的稳定性
热数据节点:保存近期的 index,承担最频繁的写入和查询操作,可以配置较高的资源,如超高性能主机及硬盘。可以在集群配置参数里 Elasticsearch 节点的参数node.attr.data(热)做修改,默认为 hot
温/冷数据节点:保存只读 index,会接收少量的查询请求,可以配置较低的资源。可以在集群配置参数里 Elasticsearch 节点的参数 node.attr.data(温)和 node.attr.data(冷)做修改,默认为 warm和 cold
架构
2.准备工作
前期部署参考:三:集群部署
3.修改配置
es-1-data_hot
[elasticsearch@es-1 es]$ cat config/elasticsearch.yml
cluster.name: xingdian-es
node.name: es-1.xingdian.com
path.data: /usr/local/es/data
path.logs: /usr/local/es/logs
network.host: 0.0.0.0
http.port: 9200
node.roles: [data_hot, data_content, master, ingest]
discovery.seed_hosts: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
cluster.initial_master_nodes: ["es-1.xingdian.com"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: /usr/local/es/config/certs/http.p12
#keystore.password: 123456 如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/http.p12
#truststore.password: 123456 如果生成证书时设置了密码则要添加密码配置
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: /usr/local/es/config/certs/elastic-certificates.p12
#keystore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/elastic-certificates.p12
#truststore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
http.host: [_local_, _site_]
ingest.geoip.downloader.enabled: false
xpack.security.http.ssl.client_authentication: none
es-2-data_warm
[elasticsearch@es-2 es]$ cat config/elasticsearch.yml
cluster.name: xingdian-es
node.name: es-2.xingdian.com
path.data: /usr/local/es/data
path.logs: /usr/local/es/logs
network.host: 0.0.0.0
http.port: 9200
node.roles: [data_warm, data_content, master, ingest]
discovery.seed_hosts: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
cluster.initial_master_nodes: ["es-1.xingdian.com"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: /usr/local/es/config/certs/http.p12
#keystore.password: 123456 如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/http.p12
#truststore.password: 123456 如果生成证书时设置了密码则要添加密码配置
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: /usr/local/es/config/certs/elastic-certificates.p12
#keystore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/elastic-certificates.p12
#truststore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
http.host: [_local_, _site_]
ingest.geoip.downloader.enabled: false
xpack.security.http.ssl.client_authentication: none
es-3-data_cold
[elasticsearch@es-3 es]$ cat config/elasticsearch.yml
cluster.name: xingdian-es
node.name: es-3.xingdian.com
path.data: /usr/local/es/data
path.logs: /usr/local/es/logs
network.host: 0.0.0.0
http.port: 9200
node.roles: [data_cold, data_content, master, ingest]
discovery.seed_hosts: ["es-1.xingdian.com","es-2.xingdian.com","es-3.xingdian.com"]
cluster.initial_master_nodes: ["es-1.xingdian.com"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: /usr/local/es/config/certs/http.p12
#keystore.password: 123456 如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/http.p12
#truststore.password: 123456 如果生成证书时设置了密码则要添加密码配置
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: /usr/local/es/config/certs/elastic-certificates.p12
#keystore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
truststore.path: /usr/local/es/config/certs/elastic-certificates.p12
#truststore.password: 123456 #如果生成证书时设置了密码则要添加密码配置
http.host: [_local_, _site_]
ingest.geoip.downloader.enabled: false
xpack.security.http.ssl.client_authentication: none
4.启动服务
依次启动所有节点
[elasticsearch@es-1 es]$ nohup ./bin/elasticsearch &
[elasticsearch@es-2 es]$ nohup ./bin/elasticsearch &
[elasticsearch@es-3 es]$ nohup ./bin/elasticsearch &
5.修改密码
依次修改所有节点
[elasticsearch@es-1 es]$ /usr/local/es/bin/elasticsearch-reset-password -u elastic -i
warning: ignoring JAVA_HOME=/usr/local/es/jdk; using bundled JDK
This tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Re-enter password for [elastic]:
Password for the [elastic] user successfully reset.
6.访问验证
GET /_cat/nodes

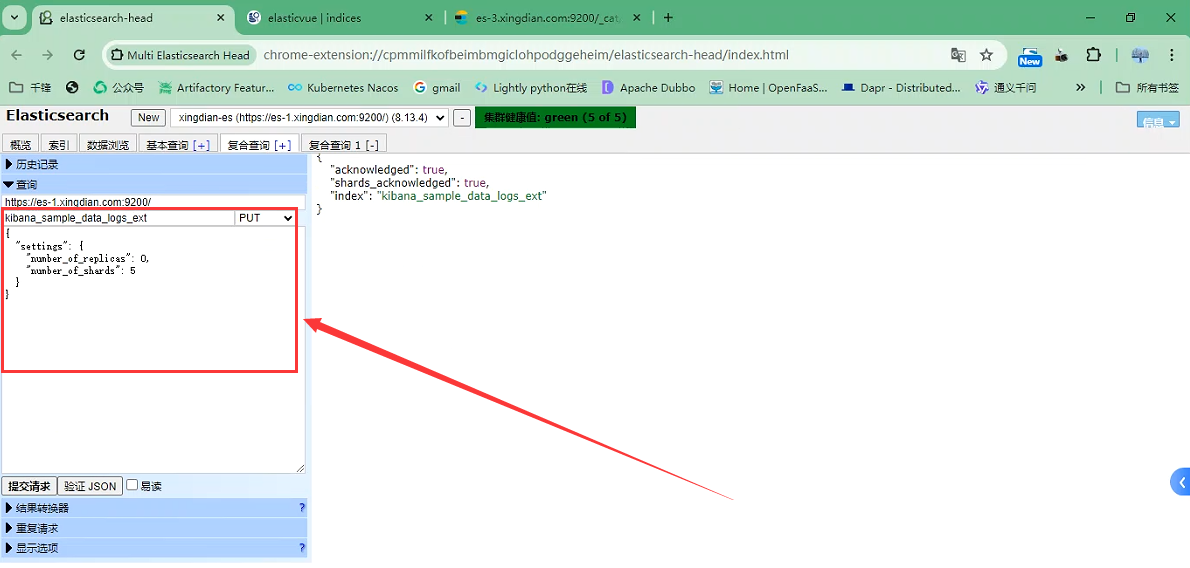
7.应用案例
设置特定的索引,分片设置为5
PUT kibana_sample_data_logs_ext
{
"settings": {
"number_of_replicas": 0,
"number_of_shards": 5
}
}
准备索引数据,首先你得先确保您索引有:diandian
POST _reindex
{
"source": {
"index": "diandian"
},
"dest": {
"index": "kibana_sample_data_logs_ext"
}
}
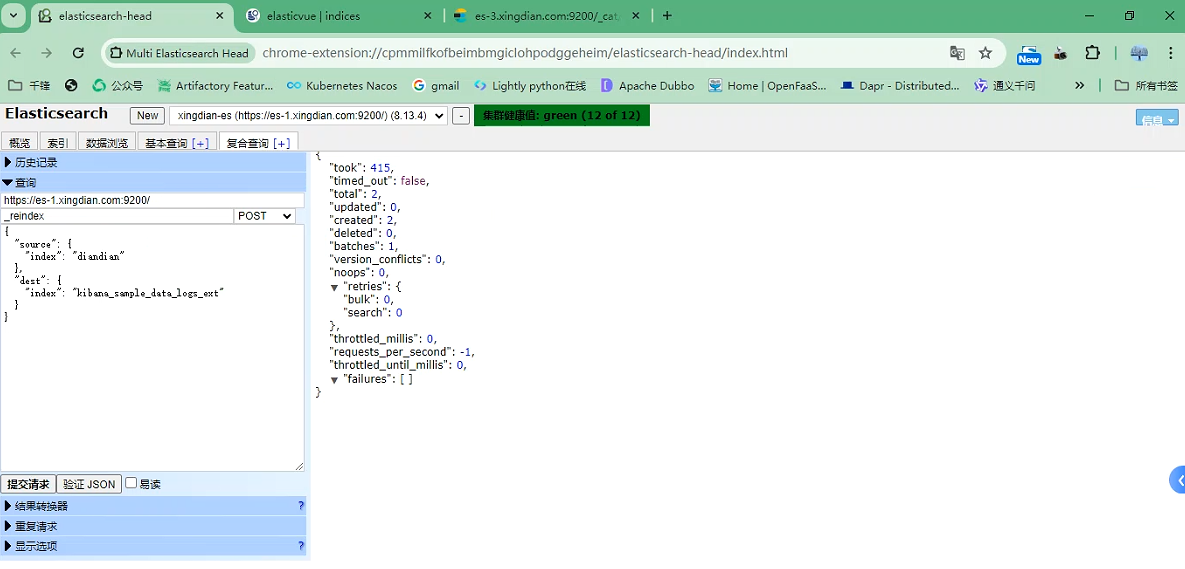
这是现在的分片情况

设置索引分片信息,主要参数:index.routing.allocation.include._tier_preference
索引-路由-分配,分配到data_hot节点上,之前我们在配置文件内定义的节点
PUT kibana_sample_data_logs_ext/_settings
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.include._tier_preference": "data_hot",
"index.blocks.write": true
}
}
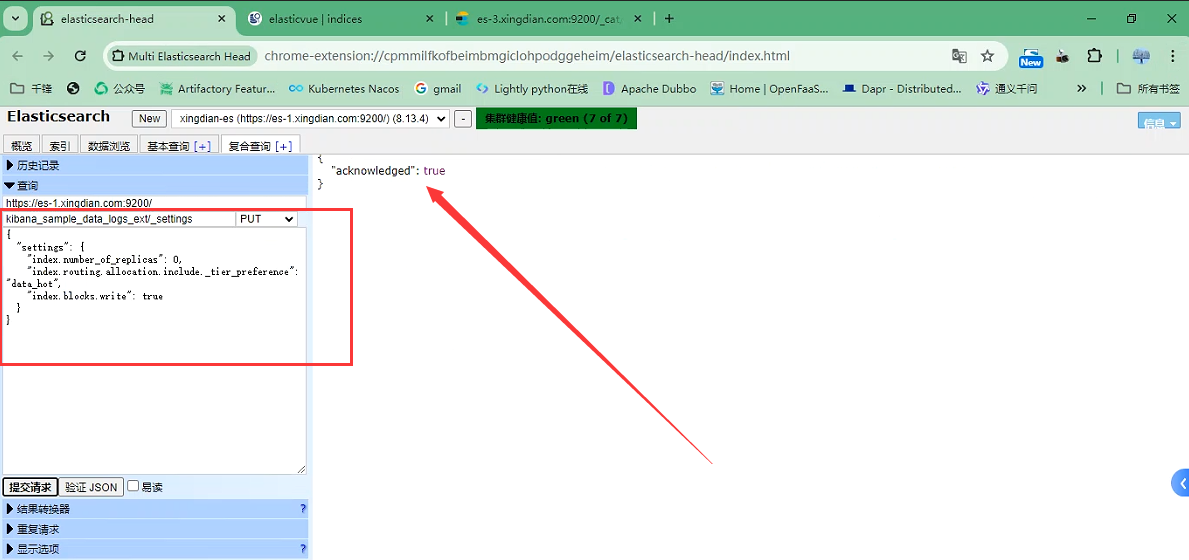
在查询就能看到分片都在hot节点上了
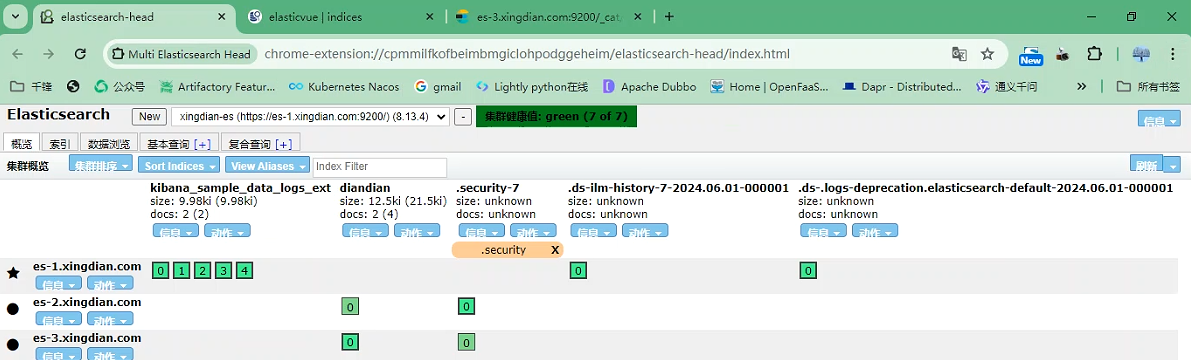
第二部分:Kibana

一:基本概念
1.Kibana简介
Kibana 是一个开源的数据分析和可视化平台,它是 Elastic Stack(包括 Elasticsearch、Logstash、Kibana 和 Beats)的一部分,主要用于对 Elasticsearch 中的数据进行搜索、查看、交互操作。
2.Kibana功能
数据可视化:Kibana 提供了丰富的数据可视化选项,如柱状图、线图等,帮助用户以图形化的方式理解数据
数据探索:Kibana 提供了强大的数据探索功能,用户可以通过 Kibana 的界面进行数据筛选和排序
仪表盘:用户可以将多个可视化组件组合在一起,创建交互式的仪表盘,用于实时监控数据
机器学习:Kibana 还集成了 Elasticsearch 的机器学习功能,可以用于异常检测、预测等任务
定制和扩展:Kibana 提供了丰富的 API 和插件系统,用户可以根据自己的需求定制和扩展 Kibana
二:安装部署
1.获取安装包
对应Elasticsearch版本获取Kibana的安装包
官网获取:https://www.elastic.co/
2.安装部署
[root@kibana ~]# tar xf kibana-8.13.4-linux-x86_64.tar.gz -C /usr/local/
[root@kibana ~]# mv /usr/local/kibana-8.13.4/ /usr/local/kibana
[root@kibana ~]# mkdir /usr/local/kibana/config/certs
3.修改配置
server.port:Kibana 服务监听的端口,默认为 5601
server.host:Kibana Kibana 服务可以被远程主机访问,你可以将此设置为远程主机的 IP 地址
server.name:Kibana 服务的名称。默认情况下,它设置为 your-hostname
elasticsearch.hosts:Kibana 连接 Elasticsearch 服务的地址
elasticsearch.username:连接到 Elasticsearch 服务时使用的用户名 kibana
elasticsearch.password:连接到 Elasticsearch 服务时使用的密码
i18n.locale: "zh-CN" 设置页面中文
4.获取Elasticsearch的CA证书
[root@es-1 kibana]# scp elasticsearch-ca.pem 10.9.12.80:/usr/local/kibana/config/certs/
5.创建运行用户
[root@kibana kibana]# useradd kibana
[root@kibana kibana]# echo kibana |passwd --stdin kibana
[root@kibana kibana]# chown kibana.kibana /usr/local/kibana/ -R
6.启动Kibana
[kibana@kibana kibana]$ nohup ./bin/kibana &
7.常见故障
故障原因:
Error: [config validation of [elasticsearch].username]: value of "elastic" is forbidden. This is a superuser account that cannot write to system indices that Kibana needs to function. Use a service account token instead. Learn more: https://www.elastic.co/guide/en/elasticsearch/reference/8.0/service-accounts.html
at ensureValidConfiguration (/usr/local/kibana/node_modules/@kbn/core-config-server-internal/src/ensure_valid_configuration.js:23:11)
解决方案:
该版本的kibana在连接es集群中,不支持使用elasticsearch中elastic(超级管理员)账户连接
在es集群中自带的kibana账户设定密码
[elasticsearch@es-1 es]$ /usr/local/es/bin/elasticsearch-reset-password -u kibana -i
warning: ignoring JAVA_HOME=/usr/local/es/jdk; using bundled JDK
This tool will reset the password of the [kibana] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
Enter password for [kibana]:
Re-enter password for [kibana]:
Password for the [kibana] user successfully reset.
扩展:
Elasticsearch中创建用户
[elasticsearch@es-1 es]$ bin/elasticsearch-users useradd test_account
为用户分配角色
[elasticsearch@es-1 es]$ bin/elasticsearch-users roles -a superuser test_account
8.浏览器访问
注意:
用户名和密码是es集群登录的用户和密码

三:配置使用
注意:此部分的使用在做完《第三部分:Logstash》中第一节和第二节后在使用
1.Logstash采集到数据进行展示
进入管理界面
进入索引管理
进入要管理的索引
展示索引数据
创建数据视图

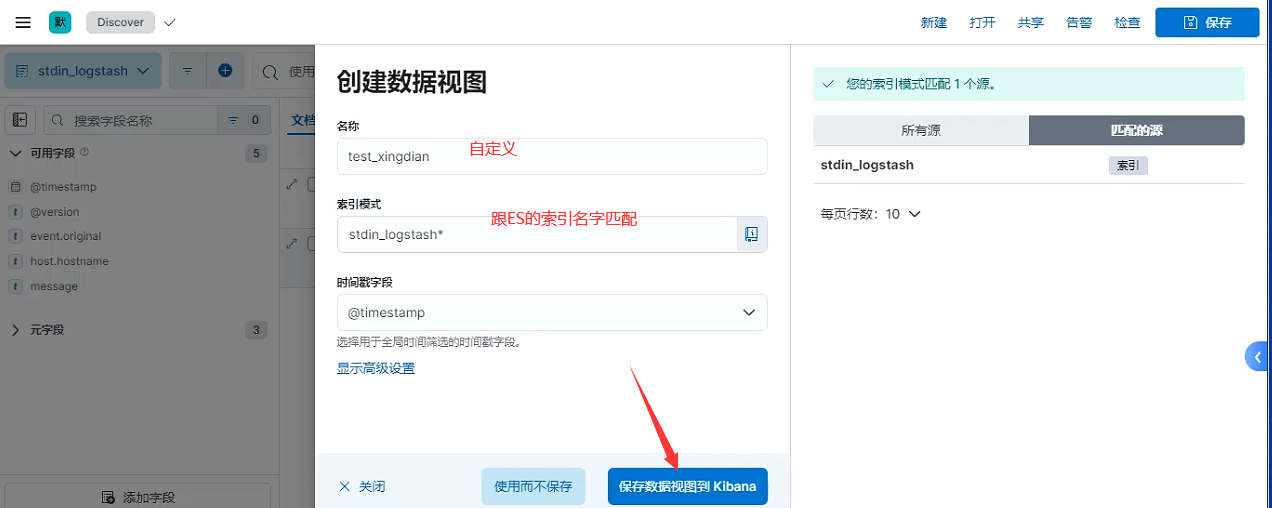 图形展示
图形展示

注意:
这里我们就可以看到Logstash采集的数据,并以图形的方式展示
在图形界面我们可以设置时间范围
在图形界面我们可以设置时间自动刷新时间
第三部分:Logstash

一:基本概念
1.Logstash简介
Logstash 是 Elastic Stack 的中央数据流引擎,用于收集、丰富和统一所有数据,而不管格式或模式
当与Elasticsearch,Kibana,及 Beats 共同使用的时候便会拥有特别强大的实时处理能力
2.Logstash原理
Logstash 管道中的每个输入阶段都在其自己的线程中运行。输入将事件写入位于内存(默认)或磁盘上的中央队列。每个管道工作线程从此队列中取出一批事件,通过配置的过滤器运行这批事件,然后通过任何输出运行过滤后的事件。批次的大小和管道工作线程的数量是可配置的。
默认情况下,Logstash 使用管道阶段(输入 → 过滤器和过滤器 → 输出)之间的内存有界队列来缓冲事件。如果 Logstash 不安全地终止,则存储在内存中的所有事件都将丢失。为了防止数据丢失,您可以启用 Logstash 将传输中的事件保存到磁盘。
二:安装部署
1.下载安装包
官网下载
对应跟ES使用同一版本
2.解压安装
[root@logstash ~]# tar xf logstash-8.13.4-linux-x86_64.tar.gz -C /usr/local/
[root@logstash ~]# cd /usr/local/
[root@logstash local]# mv logstash-8.13.4/ logstash
3.配置jdk环境
Java 11
Java 17(默认)
[root@logstash ~]# vi /etc/profile
JAVA_HOME=/usr/local/logstash/jdk
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
[root@logstash logstash]# java --version
openjdk 17.0.11 2024-04-16
OpenJDK Runtime Environment Temurin-17.0.11+9 (build 17.0.11+9)
OpenJDK 64-Bit Server VM Temurin-17.0.11+9 (build 17.0.11+9, mixed mode, sharing)
4.数据流向
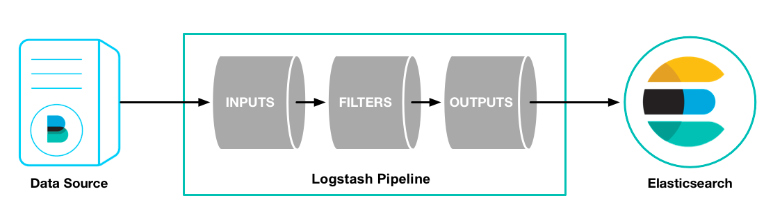
5.模拟运行
输入和输出都来自于终端
[root@logstash logstash]# bin/logstash -e 'input { stdin { } } output { stdout {} }'
....
此处省略了运行过程
....
nihao (INPUT)
{
"@version" => "1",
"@timestamp" => 2024-06-03T02:28:49.450917895Z,
"event" => {
"original" => "nihao"
},
"host" => {
"hostname" => "logstash"
},
"message" => "nihao"
}
输入来自终端,输出到ES集群
Elasticsearch 从8.0开始, 默认开启了SSL安全验证
因此我们需要为 Logstash 配置身份验证凭据才能建立与 Elasticsearch 集群的通信
Logstash创建目录存储Elasticsearch的CA证书
[root@logstash logstash]# mkdir /usr/local/logstash/config/certs
Elasticsearch中将证书拷贝到Logstash
[root@es-1 es]# scp config/certs/elasticsearch-ca.pem 10.9.12.82:/usr/local/logstash/config/certs
创建Logstash采集数据配置文件
[root@logstash logstash]# cat /opt/stdin.conf
input {
stdin{}
}
output {
elasticsearch {
index => "stdin_logstash"
hosts => [ "https://es-1.xingdian.com:9200" ]
cacert => "/usr/local/logstash/config/certs/elasticsearch-ca.pem"
user => "elastic"
password => "xingdian"
}
}
执行Logstash
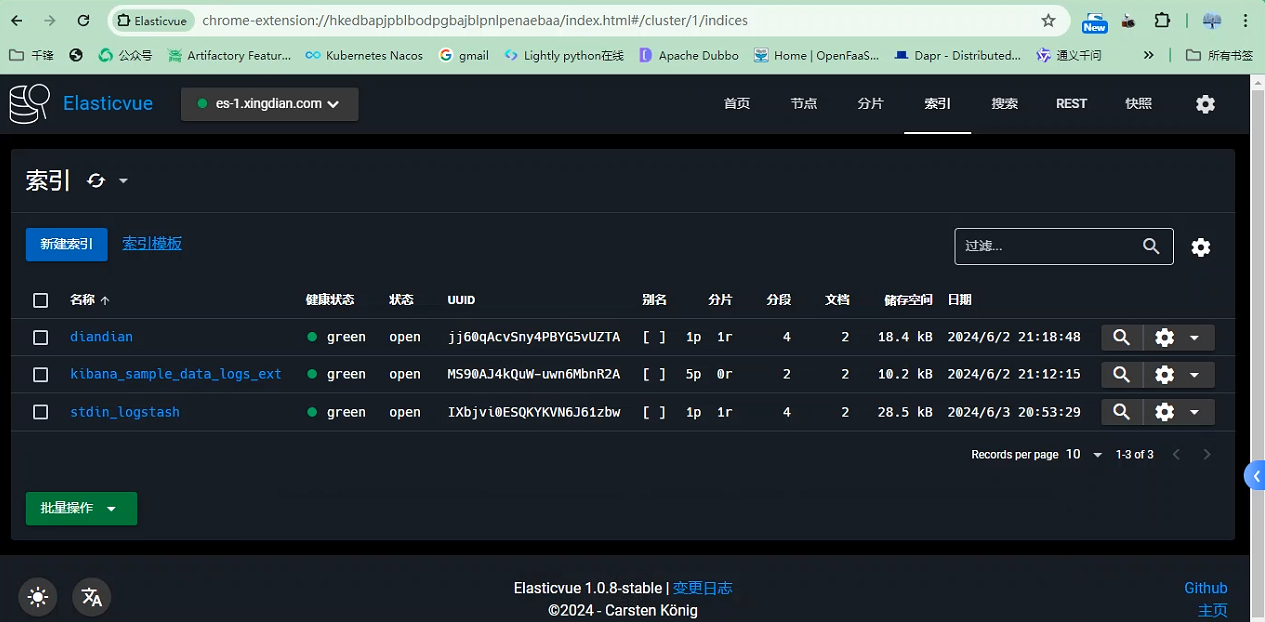
[root@logstash logstash]# ./bin/logstash -f /opt/stdin.conf
Using bundled JDK: /usr/local/logstash/jdk
.....
省略启动过程,以下是终端的标准输入
.....
hello world
hello xingdian
ES插件查看索引信息
输入来自日志文件,输出到ES集群
此处只展示Logstash配置文件
[root@logstash logstash]# cat /opt/nginx_access_logstash.conf
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
output {
elasticsearch {
index => "nginx_access_logstash"
hosts => [ "https://es-1.xingdian.com:9200" ]
cacert => "/usr/local/logstash/config/certs/elasticsearch-ca.pem"
user => "elastic"
password => "xingdian"
}
}
ES插件展示索引
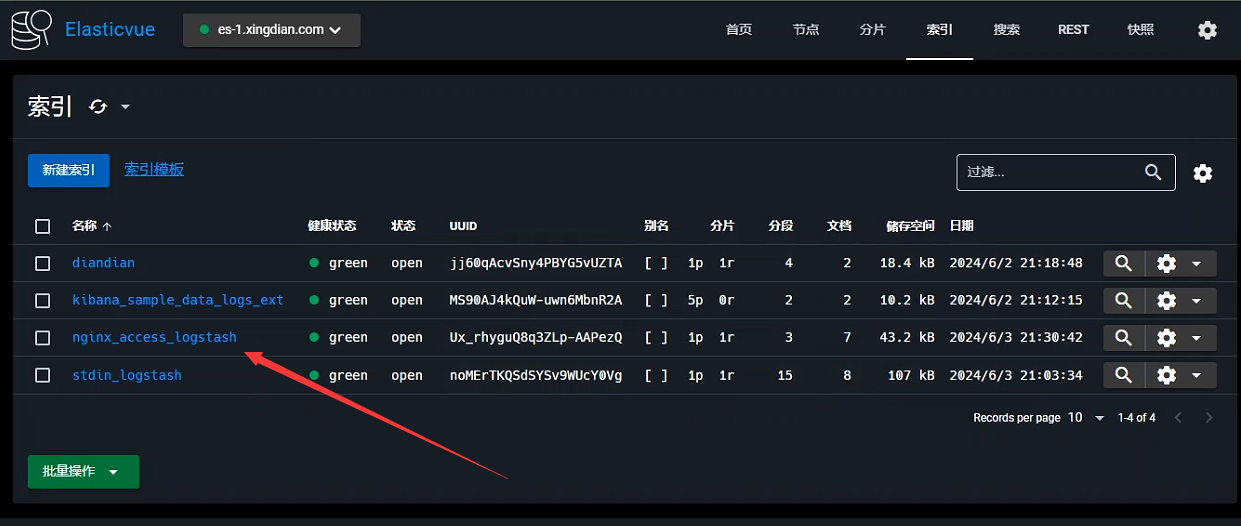
Kibana展示数据

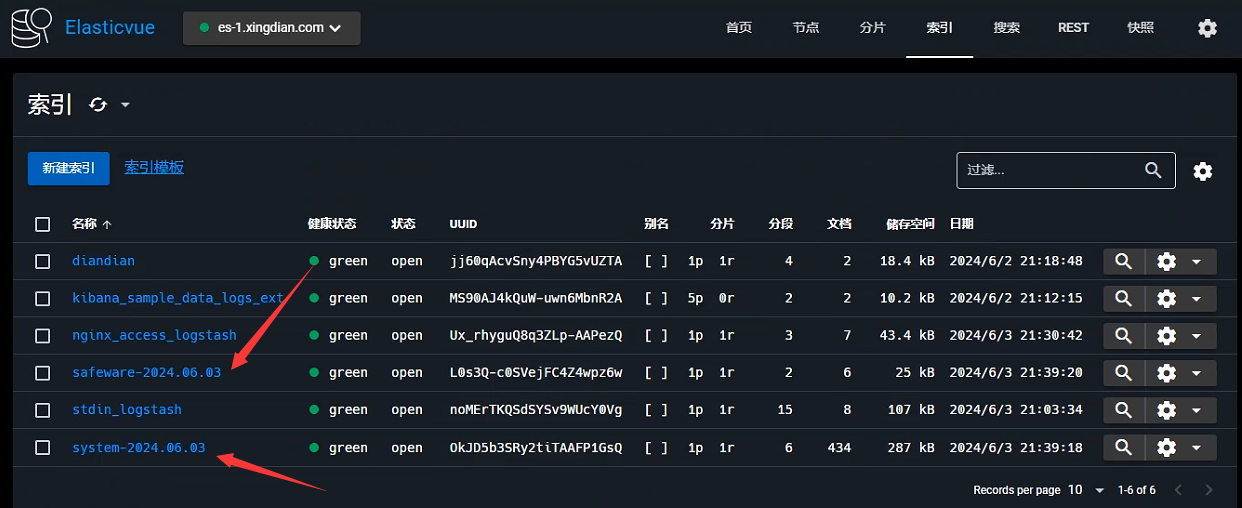
输入来自日志多文件,输出到ES集群
Logstash采集配置文件
[root@logstash ~]# cat /opt/files.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
input {
file {
path => "/var/log/yum.log"
type => "safeware"
start_position => "beginning"
}
}
output {
if [type] == 'system' {
elasticsearch {
index => "system-%{+YYYY.MM.dd}"
hosts => [ "https://es-1.xingdian.com:9200" ]
cacert => "/usr/local/logstash/config/certs/elasticsearch-ca.pem"
user => "elastic"
password => "xingdian"
}
}
if [type] == 'safeware' {
elasticsearch {
index => "safeware-%{+YYYY.MM.dd}"
hosts => [ "https://es-1.xingdian.com:9200" ]
cacert => "/usr/local/logstash/config/certs/elasticsearch-ca.pem"
user => "elastic"
password => "xingdian"
}
}
}
ES插件展示索引
三:数据过滤
1.插件grok简介
grok插件有非常强大的功能,他能匹配一切数据,但是他的性能和对资源的损耗同样让人诟病
filter的grok是目前logstash中解析非结构化日志数据最好的方式
grok位于正则表达式之上,所以任何正则表达式在grok中都是有效的
官网地址:
正则:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns
2.语法格式
Grok 模式的语法是:%{SYNTAX:SEMANTIC}
是SYNTAX将与您的文本匹配的模式的名称
是SEMANTIC您为匹配的文本片段指定的标识符
3.应用案例
针对nginx的访问日志,获取对应的IP地址
Logstash采集数据配置文件:
[root@logstash ~]# cat /opt/grok_nginx_access_logstash.conf
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IP:remote_addr}"}
}
}
output {
elasticsearch {
index => "grok_nginx_access_logstash"
hosts => [ "https://es-1.xingdian.com:9200" ]
cacert => "/usr/local/logstash/config/certs/elasticsearch-ca.pem"
user => "elastic"
password => "xingdian"
}
}
执行:
[root@logstash logstash]# ./bin/logstash -f /opt/grok_nginx_access_logstash.conf
ES插件确认索引:

Kibana查看新字段:
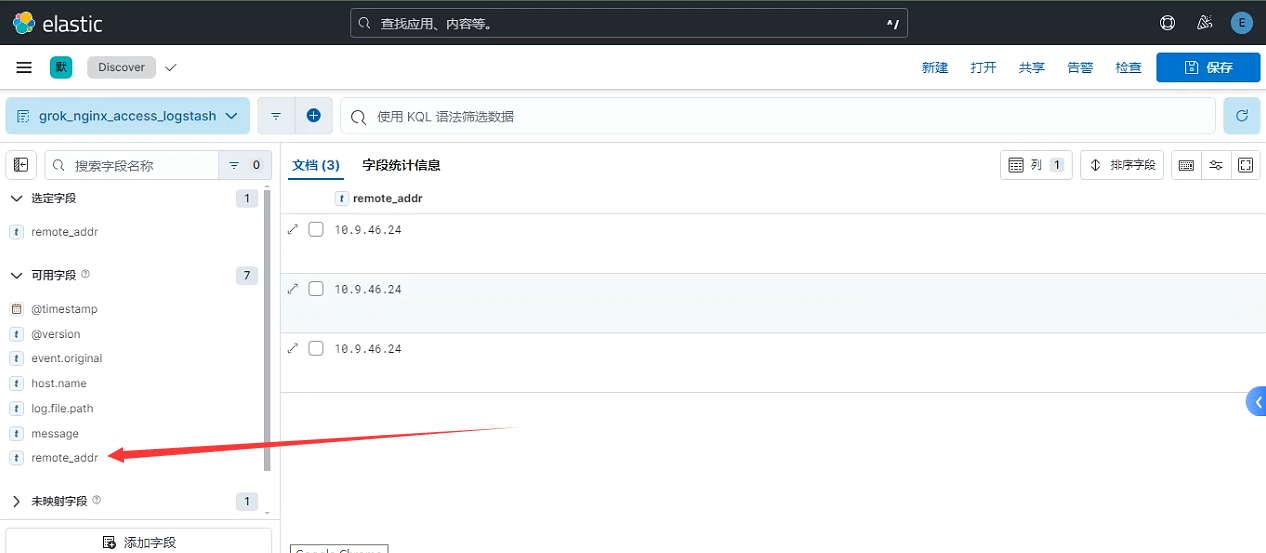
针对nginx的访问日志,对应生成新的字段
Logstash采集数据配置文件:
[root@logstash ~]# cat /opt/grok_nginx_access_logstash.conf
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:client_ip} - %{DATA:user} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response_code} %{NUMBER:bytes_sent} \"%{DATA:referrer}\" \"%{DATA:user_agent}\"" }
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
index => "grok_nginx_access_logstash"
hosts => [ "https://es-1.xingdian.com:9200" ]
cacert => "/usr/local/logstash/config/certs/elasticsearch-ca.pem"
user => "elastic"
password => "xingdian"
}
}
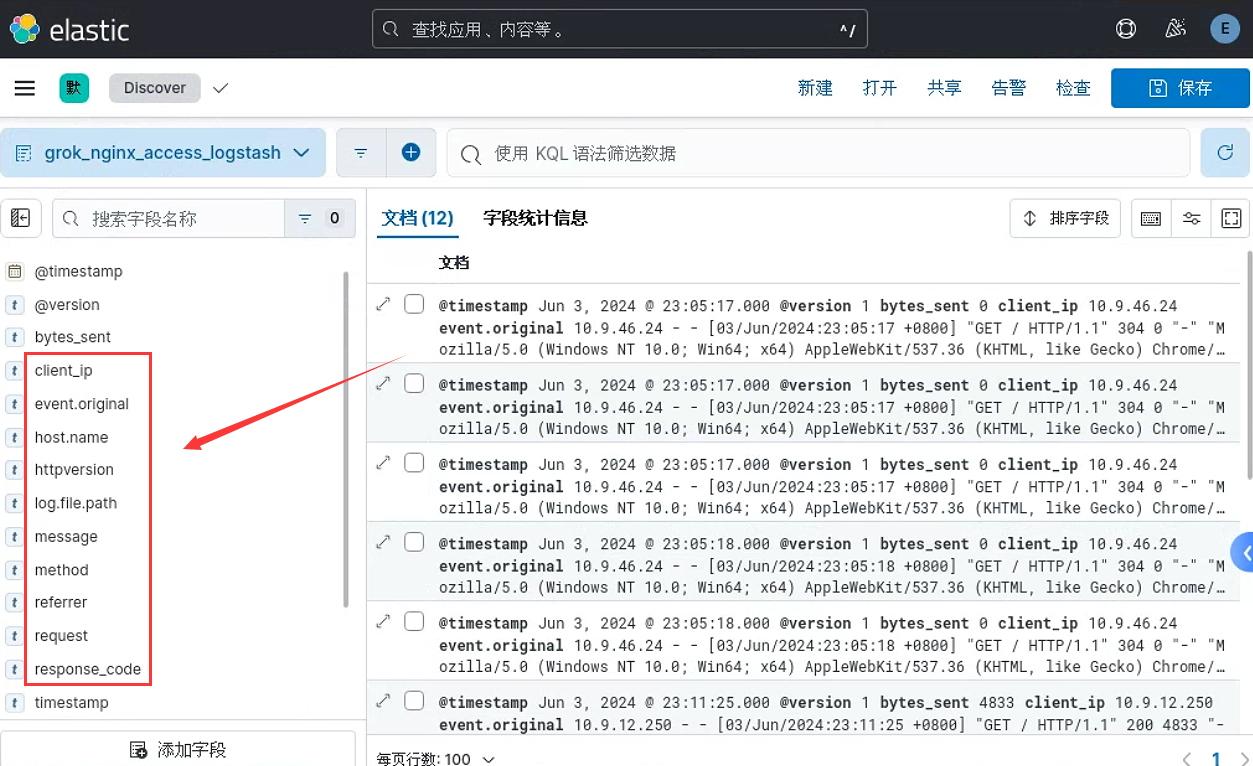
Kibana查看新字段:
第四部分:Filebeat

一:基本概念
1.Filebeat简介
Filebeat是本地文件的日志数据采集器。 作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,并将它们转发给Elasticsearch、Logstash、kafka 等
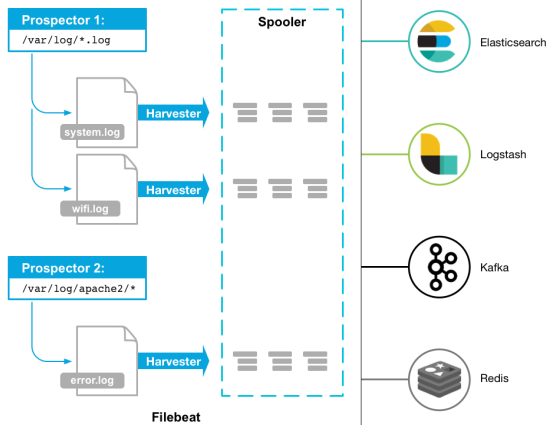
2.核心组件
prospector:负责读取单个文件的内容。读取每个文件,并将内容发送到 the output每个文件启动一harvester, harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态,如果文件在读取时被删除,Filebeat将继续读取文件
harvester:负责管理harvester并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。每个prospector都在自己的Go协程中运行
3.工作原理
启动Filebeat时,它会启动一个或多个查找器,查看您为日志文件指定的本地路径。 对于prospector 所在的每个日志文件,prospector 启动harvester,每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到您为Filebeat配置的输出
注意:
Filebeat目前支持两种prospector类型:log和stdin
4.为什么使用filebeat
Filebeat是一种轻量级的日志搜集器,其不占用系统资源,自出现之后,迅速更新了原有的elk架构。它将收集到的数据发送给Logstash解析过滤,在Filebeats与Logstash传输数据的过程中,为了安全性,可以通过ssl认证来加强安全性。之后将其发送到Elasticsearch存储,并由kibana可视化分析
二:安装部署
1.安装方式
rpm包的方式安装:filebeat-8.13.4-x86_64.rpm
压缩包解压安装:filebeat-8.13.4-linux-x86_64.tar.gz
2.获取安装包
官网地址:
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.13.4-x86_64.rpm
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.13.4-linux-x86_64.tar.gz
3.二进制安装
[root@filebeat ~]# yum -y install ./filebeat-8.13.4-x86_64.rpm
4.修改配置
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml
注意:在配置文件中找到以下参数修改,主要指定的是输出和kibana
output.elasticsearch:
hosts: ["<es_url>"]
protocol: "https"
username: "elastic"
password: "<password>"
# If using Elasticsearch's default certificate
ssl.ca_trusted_fingerprint: "<es cert fingerprint>"
setup.kibana:
host: "<kibana_url>"
注意:
在生产环境中,请勿使用内置 elastic 用户来保护客户端
而要设置授权用户或 API 密钥,并且不要在配置文件中暴露密码
如何获取ssl.ca_trusted_fingerprint参数的值
在ES节点上利用ES的CA文件获取
[root@es-1 certs]# openssl x509 -fingerprint -sha256 -noout -in ./elasticsearch-ca.pem | awk --field-separator="=" '{print $2}' | sed 's/://g'
79FFAE0C4E8B2D14AC4E41338C0463757D7612372F952D3304F611F5885F69E5
扩展:
该实验不用
输出到kafka配置
output.kafka:
enabled: true
hosts: ["172.17.0.4:9092","172.17.0.5:9092"]
topic: 'kafka_run_log'
5.启用Nginx模块
[root@filebeat ~]# filebeat modules enable nginx
修改:参考官方文档
https://www.elastic.co/guide/en/beats/filebeat/8.13/filebeat-module-nginx.html
- module: nginx
# Access logs
access:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/nginx/access.log*"]
# Error logs
error:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/nginx/error.log*"]
启动服务:
[root@filebeat ~]# filebeat setup
[root@filebeat ~]# systemctl start filebeat
6.模拟产生数据
访问Nginx产生数据
7.查看图表
获取状态码访问情况
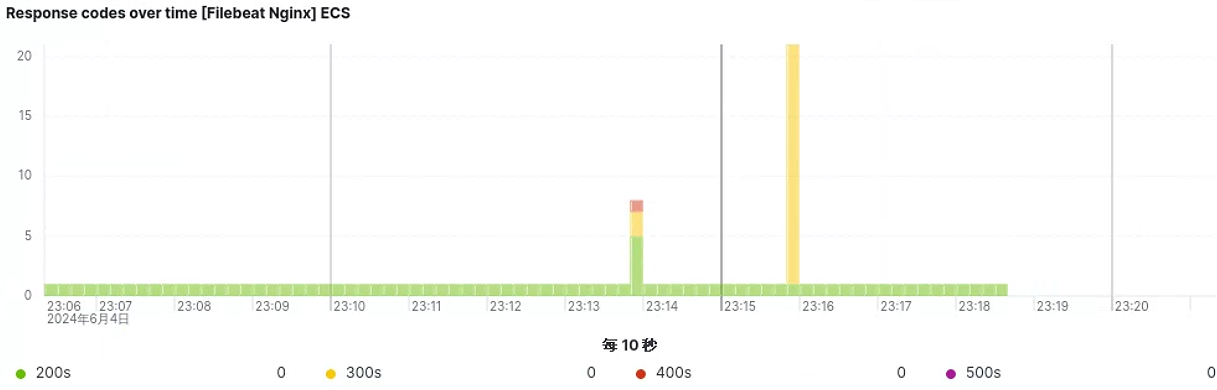
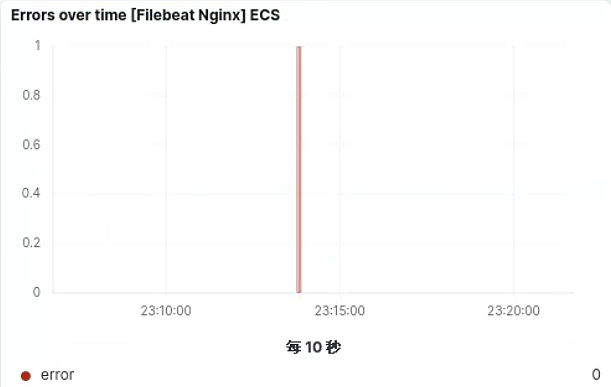
获取错误日志情况
获取访问路径请求

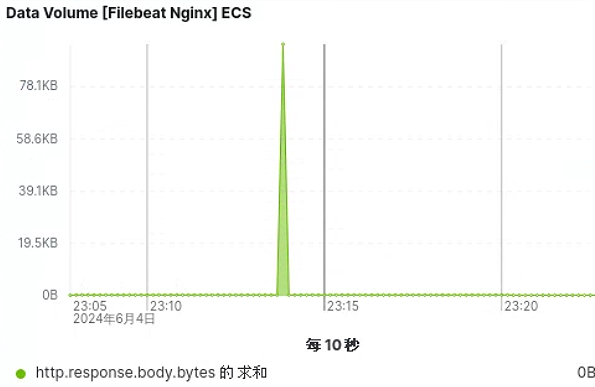
获取访问数据量情况
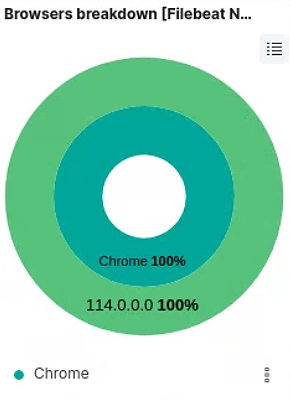
获取客户端使用情况
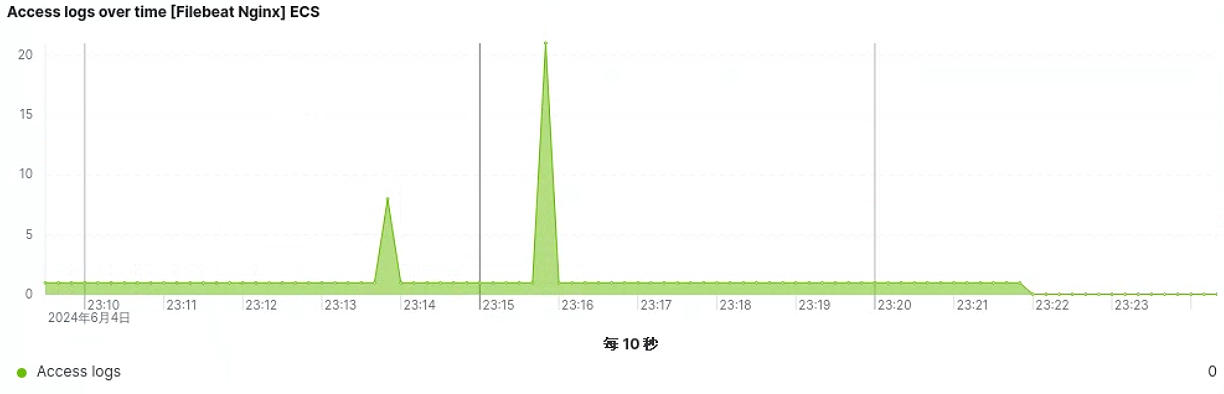
获取服务器访问量
三:配置文件详解
1.配置文件
############### Filebeat 配置文件说明#############
filebeat:
# List of prospectors to fetch data.
prospectors:
-
# paths指定要监控的日志
paths:
- /var/log/*.log
#指定被监控的文件的编码类型使用plain和utf-8都是可以处理中文日志的。
# Some sample encodings:
# plain, utf-8, utf-16be-bom, utf-16be, utf-16le, big5, gb18030, gbk,
# hz-gb-2312, euc-kr, euc-jp, iso-2022-jp, shift-jis, ...
#encoding: plain
#指定文件的输入类型log(默认)或者stdin。
input_type: log
# 在输入中排除符合正则表达式列表的那些行
# exclude_lines: ["^DBG"]
# 包含输入中符合正则表达式列表的那些行默认包含所有行include_lines执行完毕之后会执行exclude_lines。
# include_lines: ["^ERR", "^WARN"]
# 忽略掉符合正则表达式列表的文件默认为每一个符合paths定义的文件都创建一个harvester。
# exclude_files: [".gz$"]
# 向输出的每一条日志添加额外的信息比如“level:debug”方便后续对日志进行分组统计。默认情况下会在输出信息的fields子目录下以指定的新增fields建立子目录例如fields.level。
#fields:
# level: debug
# review: 1
# 如果该选项设置为true则新增fields成为顶级目录而不是将其放在fields目录下。自定义的field会覆盖filebeat默认的field。
#fields_under_root: false
# 可以指定Filebeat忽略指定时间段以外修改的日志内容比如2h两个小时或者5m(5分钟)。
#ignore_older: 0
# 如果一个文件在某个时间段内没有发生过更新则关闭监控的文件handle。默认1h,change只会在下一次scan才会被发现
#close_older: 1h
# 设定Elasticsearch输出时的document的type字段也可以用来给日志进行分类。Default: log
#document_type: log
# Filebeat以多快的频率去prospector指定的目录下面检测文件更新比如是否有新增文件如果设置为0s则Filebeat会尽可能快地感知更新占用的CPU会变高。默认是10s。
#scan_frequency: 10s
# 每个harvester监控文件时使用的buffer的大小。
#harvester_buffer_size: 16384
# 日志文件中增加一行算一个日志事件max_bytes限制在一次日志事件中最多上传的字节数多出的字节会被丢弃。The default is 10MB.
#max_bytes: 10485760
# 适用于日志中每一条日志占据多行的情况比如各种语言的报错信息调用栈。这个配置的下面包含如下配置
#multiline:
# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [
#pattern: ^\[
# Defines if the pattern set under pattern should be negated or not. Default is false.
#negate: false
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
# Note: After is the equivalent to previous and before is the equivalent to to next in Logstash
#match: after
# The maximum number of lines that are combined to one event.
# In case there are more the max_lines the additional lines are discarded.
# Default is 500
#max_lines: 500
# After the defined timeout, an multiline event is sent even if no new pattern was found to start a new event
# Default is 5s.
#timeout: 5s
# 如果设置为trueFilebeat从文件尾开始监控文件新增内容把新增的每一行文件作为一个事件依次发送而不是从文件开始处重新发送所有内容。
#tail_files: false
# Filebeat检测到某个文件到了EOF之后每次等待多久再去检测文件是否有更新默认为1s。
#backoff: 1s
# Filebeat检测到某个文件到了EOF之后等待检测文件更新的最大时间默认是10秒。
#max_backoff: 10s
# 定义到达max_backoff的速度默认因子是2到达max_backoff后变成每次等待max_backoff那么长的时间才backoff一次直到文件有更新才会重置为backoff。
#backoff_factor: 2
# 这个选项关闭一个文件,当文件名称的变化。#该配置选项建议只在windows。
#force_close_files: false
# Additional prospector
#-
# Configuration to use stdin input
#input_type: stdin
# spooler的大小spooler中的事件数量超过这个阈值的时候会清空发送出去不论是否到达超时时间。
#spool_size: 2048
# 是否采用异步发送模式(实验!)
#publish_async: false
# spooler的超时时间如果到了超时时间spooler也会清空发送出去不论是否到达容量的阈值。
#idle_timeout: 5s
# 记录filebeat处理日志文件的位置的文件
registry_file: /var/lib/filebeat/registry
# 如果要在本配置文件中引入其他位置的配置文件可以写在这里需要写完整路径但是只处理prospector的部分。
#config_dir:
############################# Output ############
# 输出到数据配置.单个实例数据可以输出到elasticsearch或者logstash选择其中一种注释掉另外一组输出配置。
output:
### 输出数据到Elasticsearch
elasticsearch:
# IPv6 addresses should always be defined as: https://[2001:db8::1]:9200
hosts: ["localhost:9200"]
# 输出认证.
#protocol: "https"
#username: "admin"
#password: "s3cr3t"
# 启动进程数.
#worker: 1
# 输出数据到指定index default is "filebeat" 可以使用变量[filebeat-]YYYY.MM.DD keys.
#index: "filebeat"
# 一个模板用于设置在Elasticsearch映射默认模板加载是禁用的,没有加载模板这些设置可以调整或者覆盖现有的加载自己的模板
#template:
# Template name. default is filebeat.
#name: "filebeat"
# Path to template file
#path: "filebeat.template.json"
# Overwrite existing template
#overwrite: false
# Optional HTTP Path
#path: "/elasticsearch"
# Proxy server url
#proxy_url: http://proxy:3128
# 发送重试的次数取决于max_retries的设置默认为3
#max_retries: 3
# 单个elasticsearch批量API索引请求的最大事件数。默认是50。
#bulk_max_size: 50
# elasticsearch请求超时事件。默认90秒.
#timeout: 90
# 新事件两个批量API索引请求之间需要等待的秒数。如果bulk_max_size在该值之前到达额外的批量索引请求生效。
#flush_interval: 1
# elasticsearch是否保持拓扑。默认false。该值只支持Packetbeat。
#save_topology: false
# elasticsearch保存拓扑信息的有效时间。默认15秒。
#topology_expire: 15
# 配置TLS参数选项如证书颁发机构等用于基于https的连接。如果tls丢失主机的CAs用于https连接elasticsearch。
#tls:
# List of root certificates for HTTPS server verifications
#certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for TLS client authentication
#certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#certificate_key: "/etc/pki/client/cert.key"
# Controls whether the client verifies server certificates and host name.
# If insecure is set to true, all server host names and certificates will be
# accepted. In this mode TLS based connections are susceptible to
# man-in-the-middle attacks. Use only for testing.
#insecure: true
# Configure cipher suites to be used for TLS connections
#cipher_suites: []
# Configure curve types for ECDHE based cipher suites
#curve_types: []
# Configure minimum TLS version allowed for connection to logstash
#min_version: 1.0
# Configure maximum TLS version allowed for connection to logstash
#max_version: 1.2
### 发送数据到logstash 单个实例数据可以输出到elasticsearch或者logstash选择其中一种注释掉另外一组输出配置。
#logstash:
# Logstash 主机地址
#hosts: ["localhost:5044"]
# 配置每个主机发布事件的worker数量。在负载均衡模式下最好启用。
#worker: 1
# #发送数据压缩级别
#compression_level: 3
# 如果设置为TRUE和配置了多台logstash主机输出插件将负载均衡的发布事件到所有logstash主机。
#如果设置为false输出插件发送所有事件到随机的一台主机上如果选择的不可达将切换到另一台主机。默认是false。
#loadbalance: true
# 输出数据到指定index default is "filebeat" 可以使用变量[filebeat-]YYYY.MM.DD keys.
#index: filebeat
# Optional TLS. By default is off.
#配置TLS参数选项如证书颁发机构等用于基于https的连接。如果tls丢失主机的CAs用于https连接elasticsearch。
#tls:
# List of root certificates for HTTPS server verifications
#certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for TLS client authentication
#certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#certificate_key: "/etc/pki/client/cert.key"
# Controls whether the client verifies server certificates and host name.
# If insecure is set to true, all server host names and certificates will be
# accepted. In this mode TLS based connections are susceptible to
# man-in-the-middle attacks. Use only for testing.
#insecure: true
# Configure cipher suites to be used for TLS connections
#cipher_suites: []
# Configure curve types for ECDHE based cipher suites
#curve_types: []
### 文件输出将事务转存到一个文件每个事务是一个JSON格式。主要用于测试。也可以用作logstash输入。
#file:
# 指定文件保存的路径。
#path: "/tmp/filebeat"
# 文件名。默认是 Beat 名称。上面配置将生成 packetbeat, packetbeat.1, packetbeat.2 等文件。
#filename: filebeat
# 定义每个文件最大大小。当大小到达该值文件将轮滚。默认值是1000 KB
#rotate_every_kb: 10000
# 保留文件最大数量。文件数量到达该值将删除最旧的文件。默认是7一星期。
#number_of_files: 7
### Console output 标准输出JSON 格式。
# console:
#如果设置为TRUE事件将很友好的格式化标准输出。默认false。
#pretty: false
############################# Shipper #############
shipper:
# #日志发送者信息标示
# 如果没设置以hostname名自居。该名字包含在每个发布事务的shipper字段。可以以该名字对单个beat发送的所有事务分组。
#name:
# beat标签列表包含在每个发布事务的tags字段。标签可用很容易的按照不同的逻辑分组服务器。
#例如一个web集群服务器可以对beat添加上webservers标签然后在kibana的visualisation界面以该标签过滤和查询整组服务器。
#tags: ["service-X", "web-tier"]
# 如果启用了ignore_outgoing选项beat将忽略从运行beat服务器上所有事务。
#ignore_outgoing: true
# 拓扑图刷新的间隔。也就是设置每个beat向拓扑图发布其IP地址的频率。默认是10秒。
#refresh_topology_freq: 10
# 拓扑的过期时间。在beat停止发布其IP地址时非常有用。当过期后IP地址将自动的从拓扑图中删除。默认是15秒。
#topology_expire: 15
# Internal queue size for single events in processing pipeline
#queue_size: 1000
# GeoIP数据库的搜索路径。beat找到GeoIP数据库后加载然后对每个事务输出client的GeoIP位置目前只有Packetbeat使用该选项。
#geoip:
#paths:
# - "/usr/share/GeoIP/GeoLiteCity.dat"
# - "/usr/local/var/GeoIP/GeoLiteCity.dat"
############################# Logging #############
# 配置beats日志。日志可以写入到syslog也可以是轮滚日志文件。默认是syslog。
logging:
# 如果启用发送所有日志到系统日志。
#to_syslog: true
# 日志发送到轮滚文件。
#to_files: false
#
files:
# 日志文件目录。
#path: /var/log/mybeat
# 日志文件名称
#name: mybeat
# 日志文件的最大大小。默认 10485760 (10 MB)。
rotateeverybytes: 10485760 # = 10MB
# 保留日志周期。 默认 7。值范围为2 到 1024。
#keepfiles: 7
# Enable debug output for selected components. To enable all selectors use ["*"]
# Other available selectors are beat, publish, service
# Multiple selectors can be chained.
#selectors: [ ]
# 日志级别。debug, info, warning, error 或 critical。如果使用debug但没有配置selectors* selectors将被使用。默认error。
#level: error
2.参数详解
解压方式安装使用
-c, --c FILE
指定用于Filebeat的配置文件。 你在这里指定的文件是相对于path.config。 如果未指定-c标志,则使用默认配置文件filebeat.yml。
-d, --d SELECTORS
启用对指定选择器的调试。 对于选择器,可以指定逗号分隔的组件列表,也可以使用-d“*”为所有组件启用调试。 例如,-d “publish”显示所有“publish”相关的消息。
-e, --e
记录到stderr并禁用syslog /文件输出。
-v, --v
记录INFO级别的消息。
1.测试filebeat启动后,查看相关输出信息:
./filebeat -e -c filebeat.yml -d "publish"
2.后台方式启动filebeat:
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出
nohup ./filebeat -e -c filebeat.yml > filebeat.log &
第五部分:Metricbeat

一:基本概念
1.Metricbeat简介
Metricbeat是轻量型指标采集器
Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据
用于从系统和服务收集指标
可以获取系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据
还可针对系统上的每个进程获得与 top 命令类似的统计数据
Metricbeat 提供多种内部模块,这些模块可从多项服务诸如 Apache、NGINX…中收集指标
2.工作原理
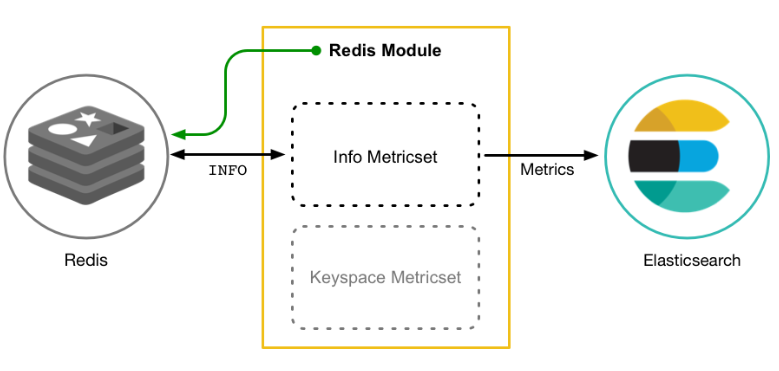
Metricbeat 由模块和指标集组成。Metricbeat模块定义了从特定服务(如 Redis、MySQL 等)收集数据的基本逻辑;模块指定有关服务的详细信息,包括如何连接、收集指标的频率以及要收集哪些指标
每个模块都有一个或多个指标集;指标集是模块的一部分,用于获取和构建数据;指标集不是将每个指标作为单独的事件收集,而是在对远程系统的单个请求中检索多个相关指标的列表
Metricbeat 根据period您在配置模块时指定的值定期询问主机系统来检索指标。由于多个指标集可以向同一服务发送请求,因此 Metricbeat 会尽可能重复使用连接;如果 Metricbeat 无法在配置设置指定的时间内连接到主机系统timeout,则会返回错误;Metricbeat 异步发送事件,这意味着不会确认事件检索;如果配置的输出不可用,事件可能会丢失
例如:(每个模块都有对应的文档)
Redis 模块提供了一个指标集,info指令 它通过运行命令并解析返回的结果来从 Redis 收集信息和统计信息
MySQL 模块提供了一个status指标集,可通过运行 SQL 查询从 MySQL 收集数据SHOW GLOBAL STATUS
Nginx结合ngx_http_stub_status_module模块实现对Nginx指标的获取
二:安装部署
1.安装方式
rpm包的方式安装:metricbeat-8.13.4-x86_64.rpm
压缩包解压安装:metricbeat-8.13.4-linux-x86_64.tar.gz
2.获取安装包
官网地址:
https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.13.4-x86_64.rpm
https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.13.4-linux-x86_64.tar.gz
3.二进制安装
[root@metricbeat ~]# yum -y install ./metricbeat-8.13.4-x86_64.rpm
4.修改配置
[root@metricbeat ~]# vim /etc/metricbeat/metricbeat.yml
output.elasticsearch:
hosts: ["<es_url>"]
username: "elastic"
password: "<password>"
# If using Elasticsearch's default certificate
ssl.ca_trusted_fingerprint: "<es cert fingerprint>"
setup.kibana:
host: "<kibana_url>"
注意:
在生产环境中,请勿使用内置 elastic 用户来保护客户端
而要设置授权用户或 API 密钥,并且不要在配置文件中暴露密码
如何获取ssl.ca_trusted_fingerprint参数的值
在ES节点上利用ES的CA文件获取
[root@es-1 certs]# openssl x509 -fingerprint -sha256 -noout -in ./elasticsearch-ca.pem | awk --field-separator="=" '{print $2}' | sed 's/://g'
79FFAE0C4E8B2D14AC4E41338C0463757D7612372F952D3304F611F5885F69E5
5.启用Nginx模块
[root@metricbeat ~]# ./metricbeat modules enable nginx
先修改:参考官方文档
https://www.elastic.co/guide/en/beats/metricbeat/8.13/metricbeat-module-nginx.html
- module: nginx
metricsets:
- stubstatus
period: 10s
enabled: true
# Nginx hosts
hosts: ["http://10.9.12.74"]
# Path to server status. Default nginx_status
server_status_path: "status"
#username: "user"
#password: "secret"
6.开启Nginx的对应模块
[root@metricbeat ~]# vim /etc/nginx/nginx.conf
location = /status {
stub_status;
}
[root@metricbeat ~]# nginx -s reload
7.模拟产生数据
浏览器访问网站
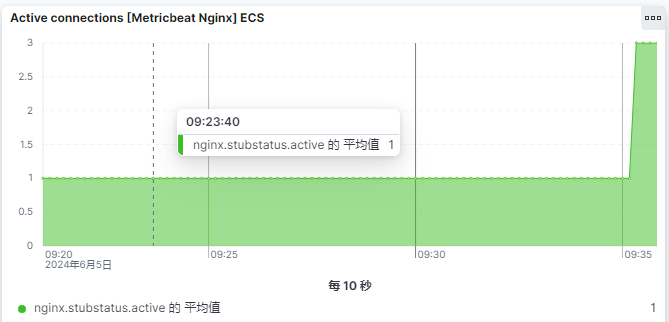
8.查看图表
活跃连接数
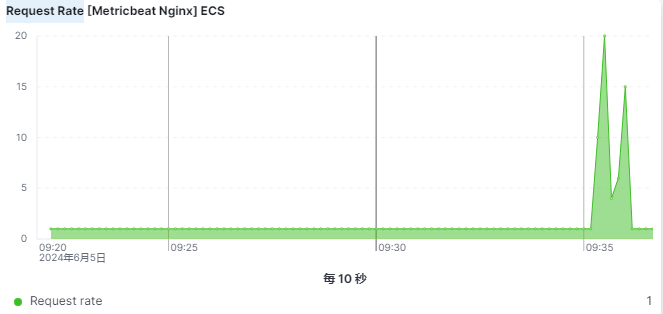
请求速率
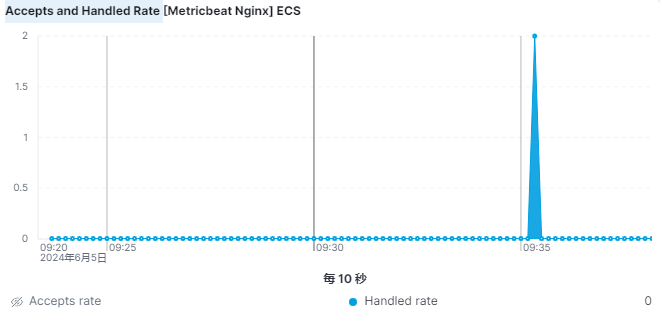
接受率和处理率
读/写/等待率
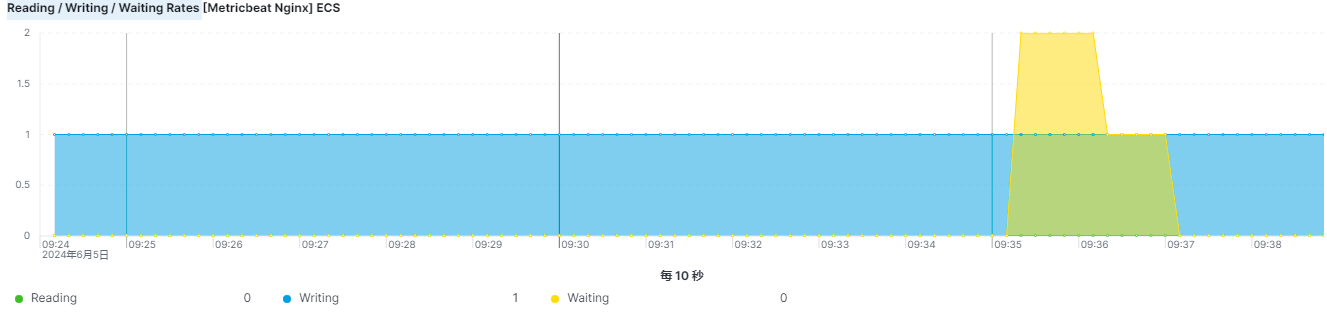
三:配置文件详解
1.配置文件
# 可选,定义 Metricbeat 的全局设置
metricbeat.config:
modules:
# 需要加载的模块配置文件路径。可以是文件或目录。
path: ${path.config}/modules.d/*.yml
# 设置为true时, Metricbeat将会定期检查模块配置文件的变更并重新加载它们。
reload.enabled: false
# 定义模块配置文件重新加载的周期, 默认是 10s
reload.period: 10s
# 设置日志的详细程度。支持 "error", "warning", "info", "debug"。
logging.level: info
# 可选,日志的输出路径。如果没有设置,日志将输出到 stdout。
logging.to_files: true
logging.files:
path: /var/log/metricbeat
name: metricbeat
keepfiles: 7
permissions: 0644
# 定义 Metricbeat 启用的模块及其设置
metricbeat.modules:
- module: system
metricsets:
- cpu
- memory
- network
- process
- process_summary
- uptime
- socket_summary
- entropy
enabled: true
period: 10s
processes: ['.*']
cpu_ticks: false
# 定义 Metricbeat 数据的输出位置
# 输出到 Elasticsearch
output.elasticsearch:
hosts: ["http://localhost:9200"]
username: "elastic"
password: "changeme"
# 配置索引名称模式
index: "metricbeat-%{[agent.version]}-%{+yyyy.MM.dd}"
# 输出到 Logstash
output.logstash:
hosts: ["localhost:5044"]
# 可选,启用SSL/TLS
ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
ssl.certificate: "/etc/pki/client/cert.pem"
ssl.key: "/etc/pki/client/cert.key"
# 监控 Metricbeat 自身的指标并发送到指定的 Elasticsearch
monitoring.enabled: true
monitoring.elasticsearch:
hosts: ["http://localhost:9200"]
username: "elastic"
password: "changeme"
更多查看官方文档:
https://www.elastic.co/guide/en/beats/metricbeat/current/metricbeat-reference-yml.html
第六部分:Elastic-agent(了解)
一:基本概念
二:安装部署
1.代理背景
由于业务需求,我们需要在7个不同的业务平台安装ES-Agent以收取其数据
我们的策略是在每个平台上安装一个Fleet Server,用于管理各平台的ES-Agent
2.生成证书
ES节点操作
生成CA
[root@es-1 es]# ./bin/elasticsearch-certutil ca --pem
生成了elastic-stack-ca.zip文件,将其解压,内置ca.crt和ca.key
[root@es-1 es]# unzip elastic-stack-ca.zip
使用CA为不同的Fleet Server主机生成证书,每个Fleet Server节点都需要单独的证书
./bin/elasticsearch-certutil cert \
--name fleet-server \
--ca-cert /path/to/ca/ca.crt \ (填写(1)中生成的ca.crt路径)
--ca-key /path/to/ca/ca.key \ (填写(1)中生成的ca.key路径)
--dns your.host.name.here \(填写Fleet Server主机的hostname)
--ip 192.0.2.1 \ (填写Fleet Server主机的IP地址)
--pem
例如:
./bin/elasticsearch-certutil cert \
--name fleet-server \
--ca-cert /usr/local/es/ca/ca.crt \
--ca-key /usr/local/es/ca/ca.key \
--dns fleet-server.xingdian.com \
--ip 10.9.12.72 \
--pem
生成一个叫做 certificate-bundle.zip的文件,将它拷贝到要安装Fleet Server的主机上
注意:将ES的ca证书也拷贝到fleet-server主机(elasticsearch-ca.pem)
3.Agent部署
下载安装
官网获取
解压并安装
[root@fleet-server ~]# tar xf elastic-agent-8.13.4-linux-x86_64.tar.gz -C /usr/local/
[root@fleet-server ~]# mv /usr/local/elastic-agent-8.13.4-linux-x86_64/ /usr/local/elastic-agent
4.创建Fleet
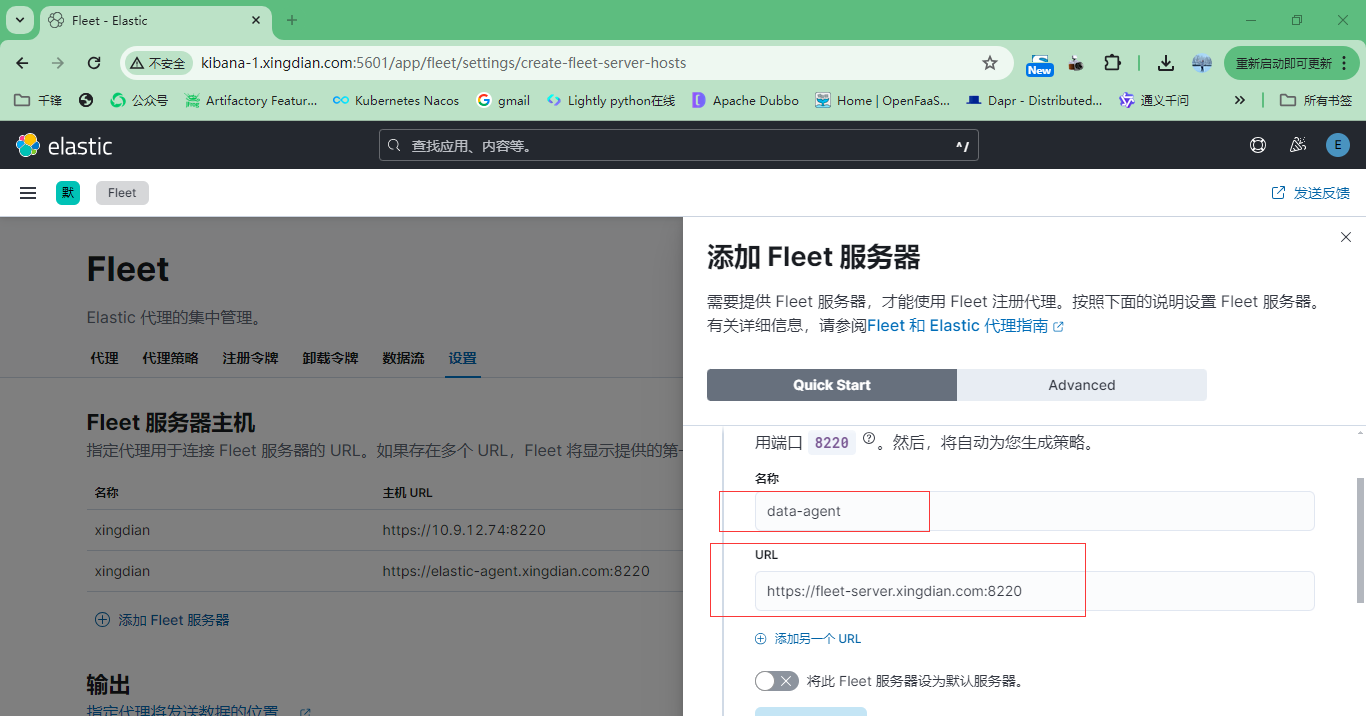
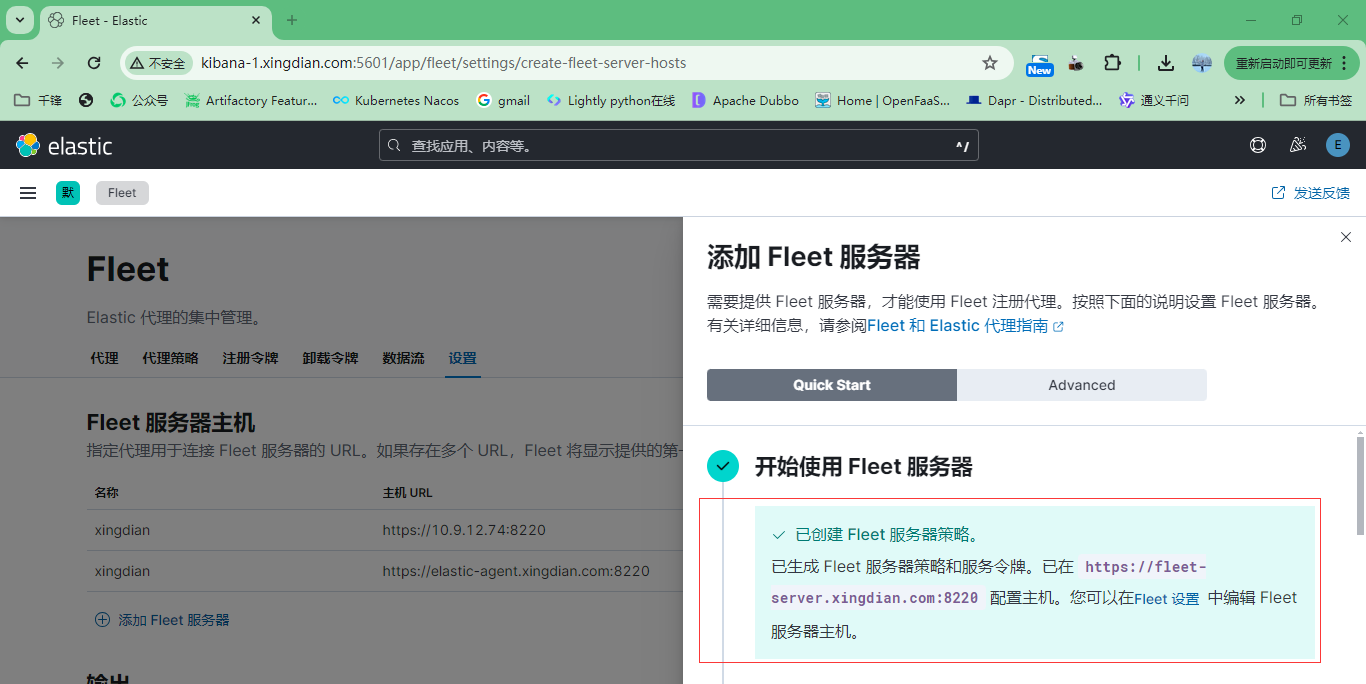
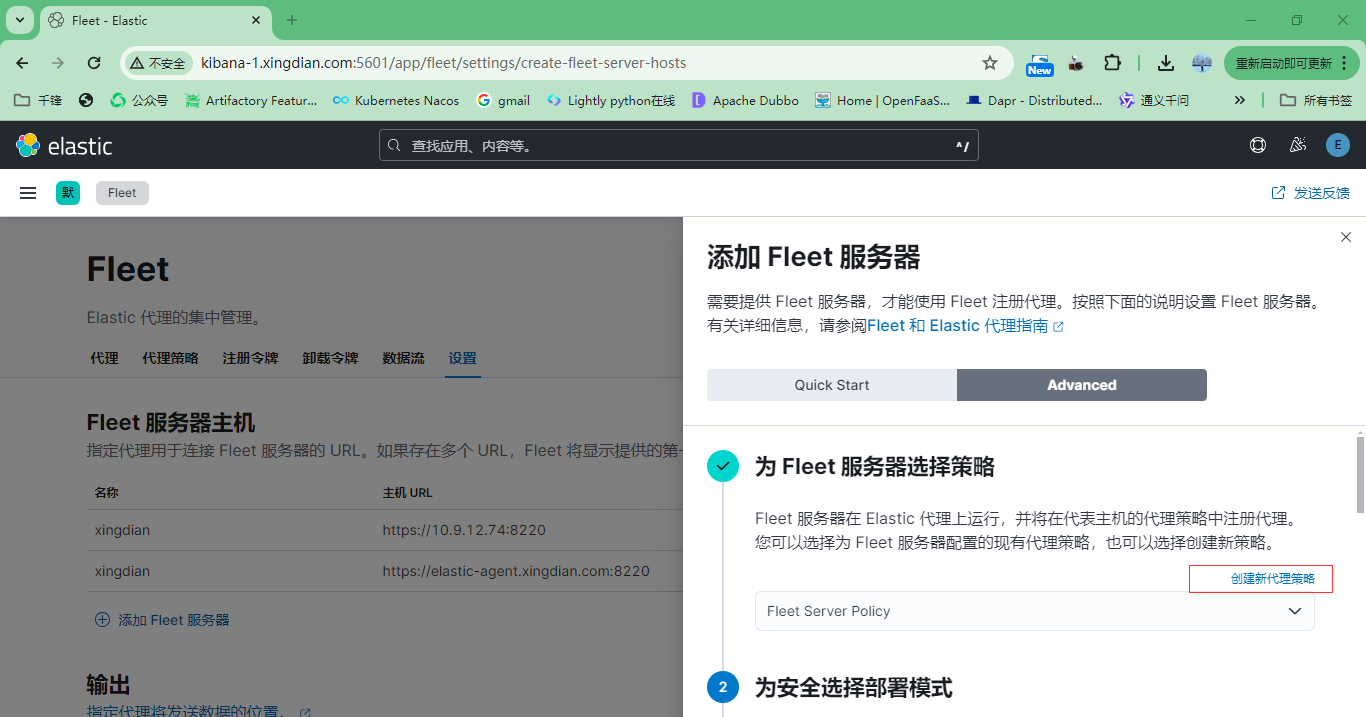
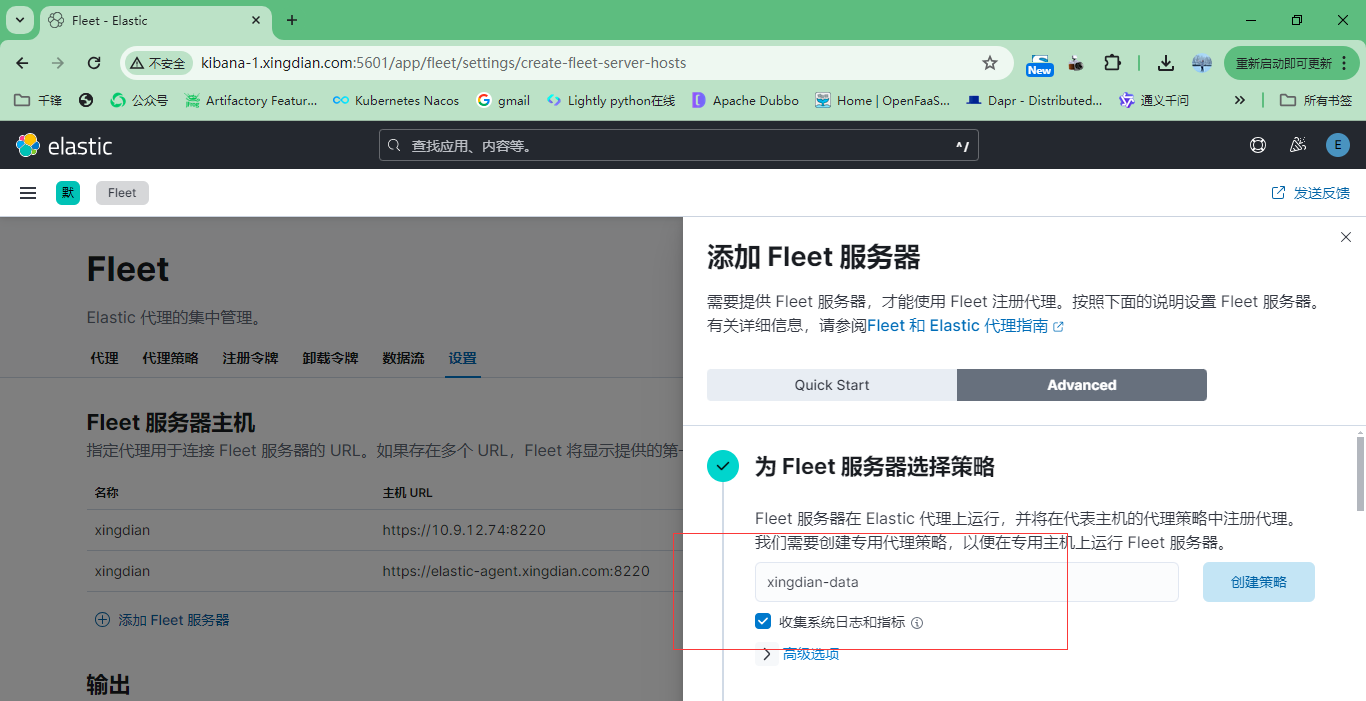
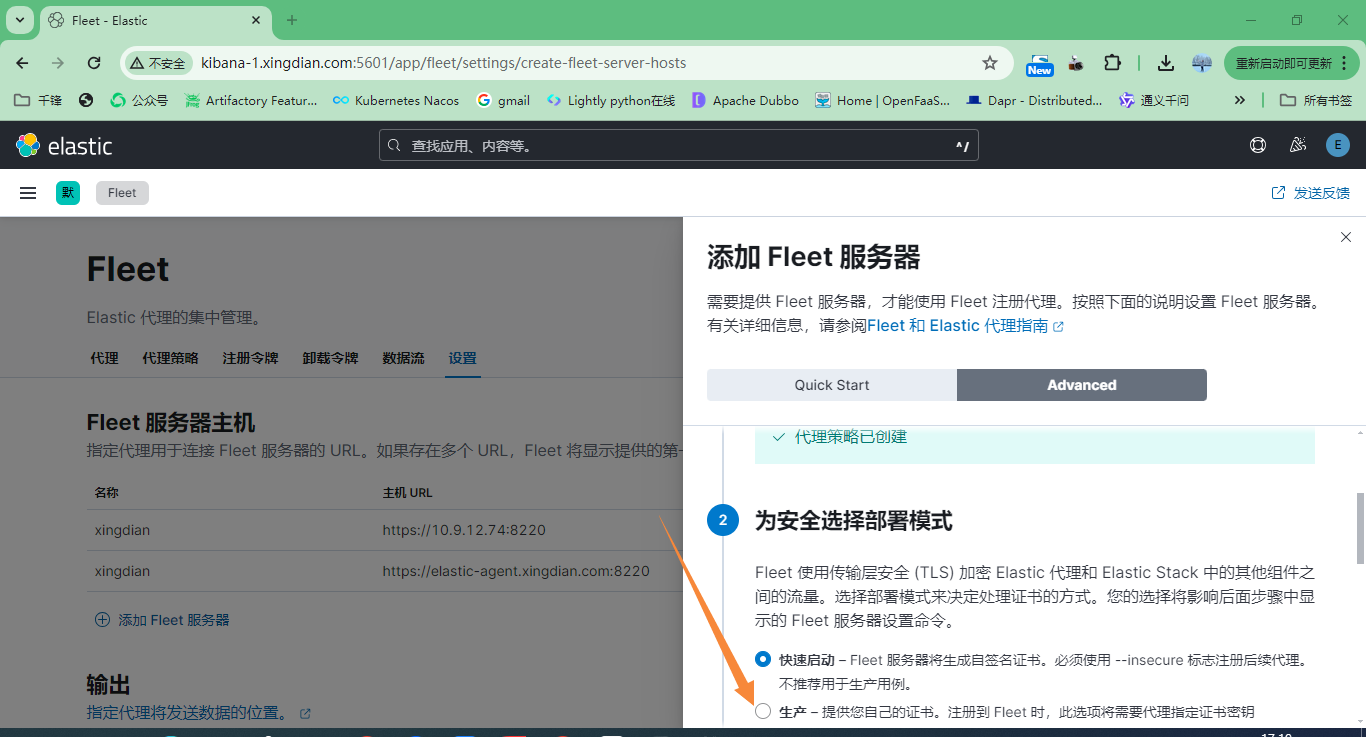
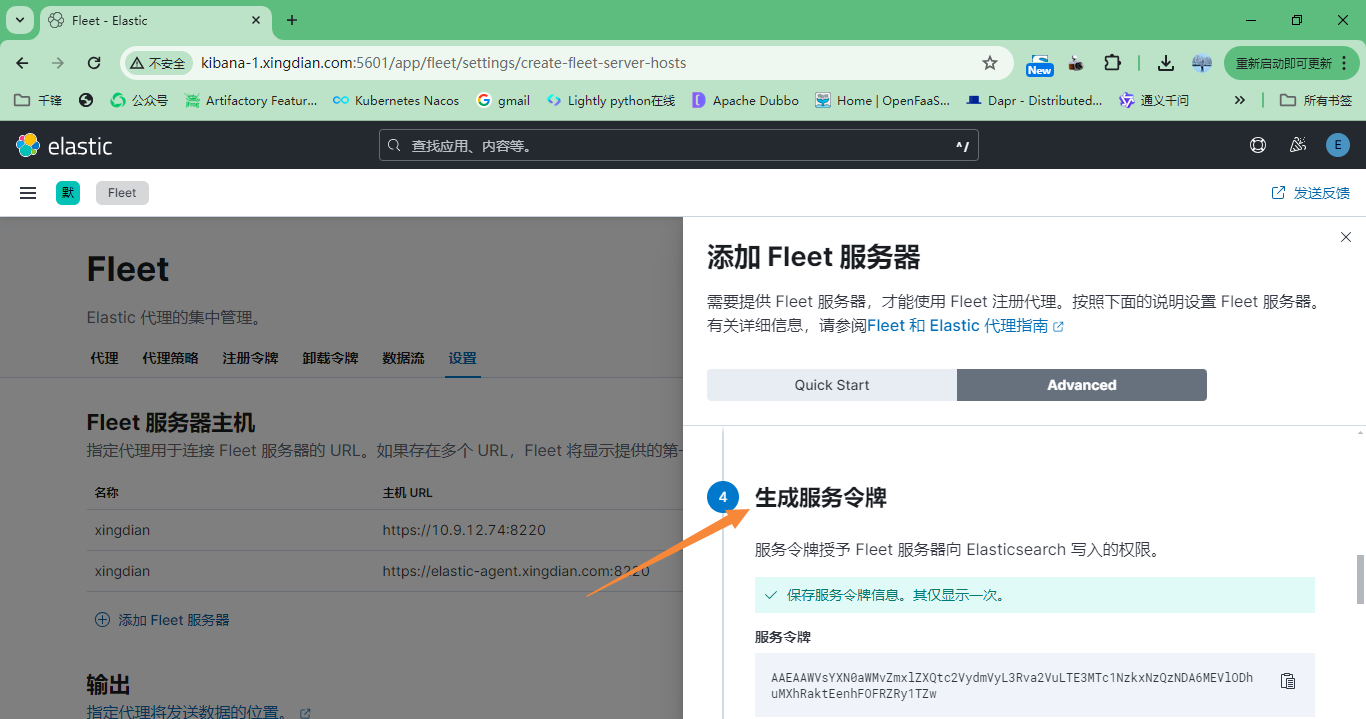
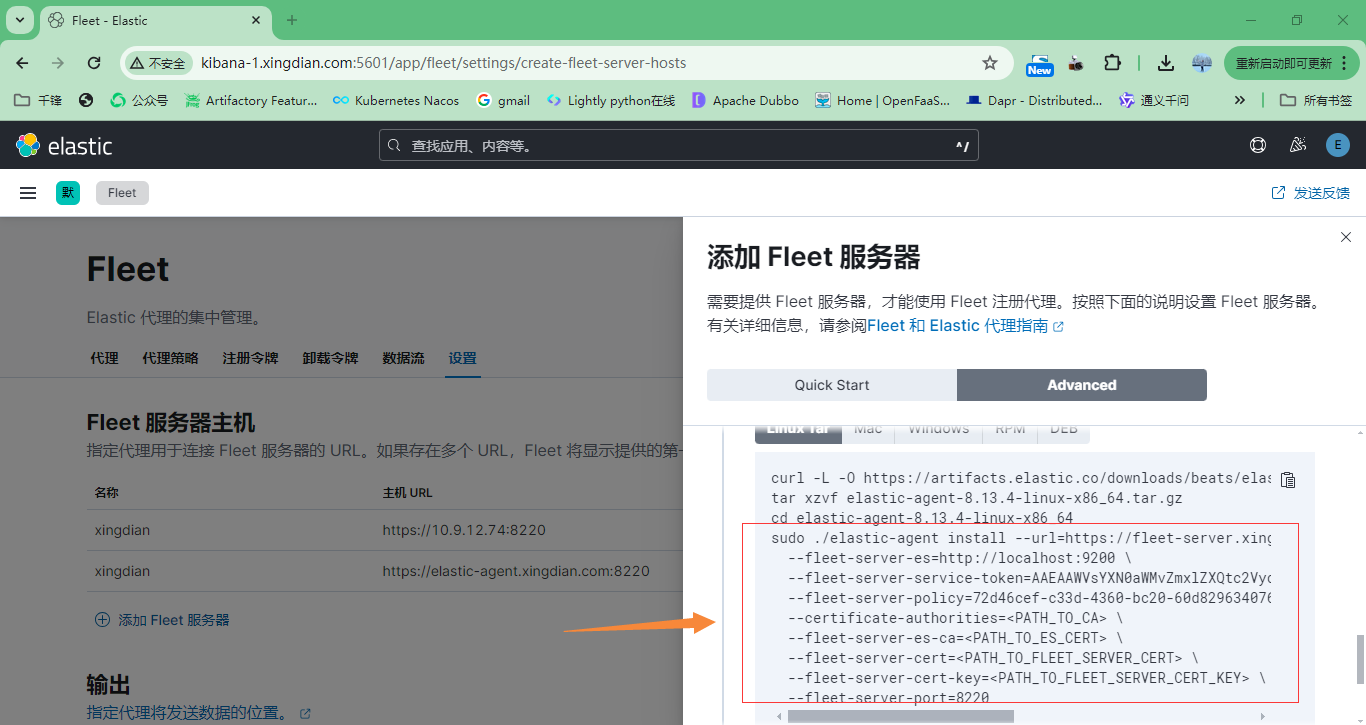
5.在agent上安装
以下内容来自上面图片中的复制,注意修改参数的值
[root@fleet-server elastic-agent]# cat a.sh
./elastic-agent install --url=https://fleet-server.xingdian.com:8220 \
--fleet-server-es=https://es-1.xingdian.com:9200 \
--fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE3MTc1NzkxNzQzNDA6MEVlODhuMXhRaktEenhFOFRZRy1TZw \
--fleet-server-policy=72d46cef-c33d-4360-bc20-60d829634076 \
--certificate-authorities=/opt/ca/ca.crt \
--fleet-server-es-ca=/opt/elasticsearch-ca.pem \
--fleet-server-cert=/opt/fleet-server/fleet-server.crt \
--fleet-server-cert-key=/opt/fleet-server/fleet-server.key \
--fleet-server-port=8220
6.fleet注册
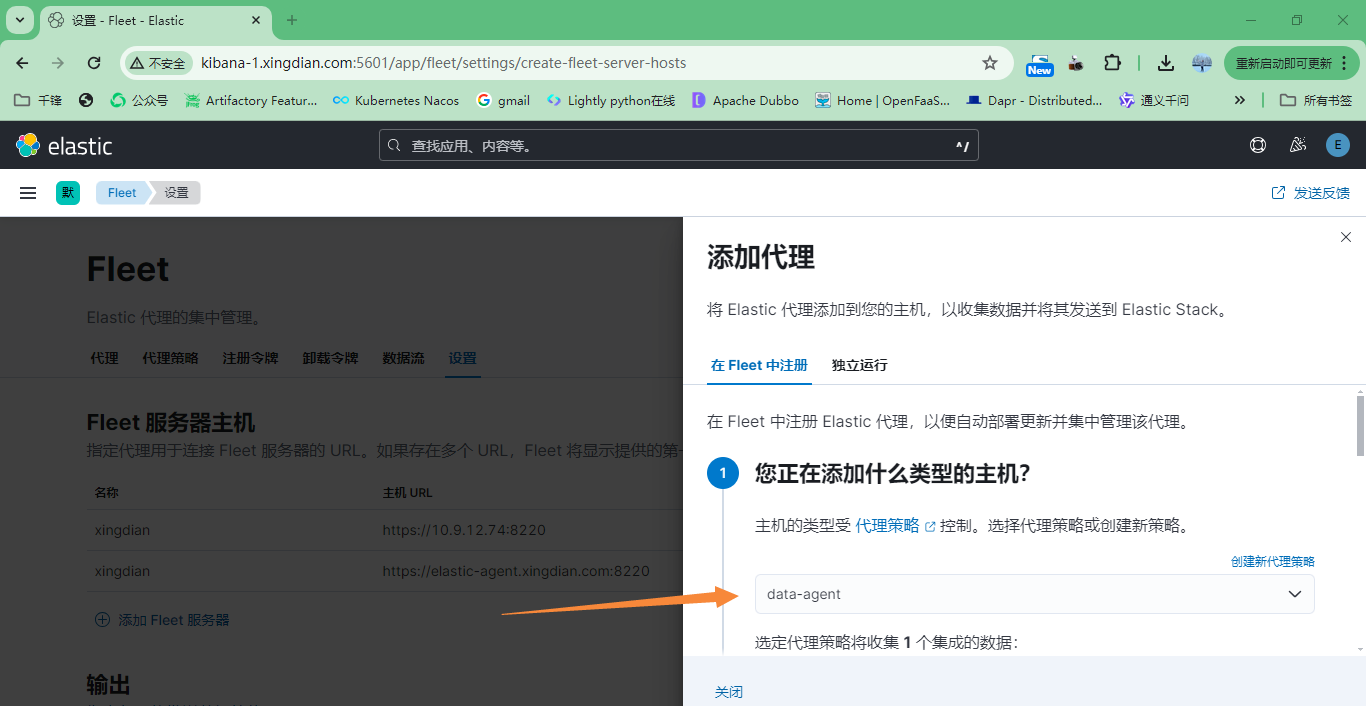
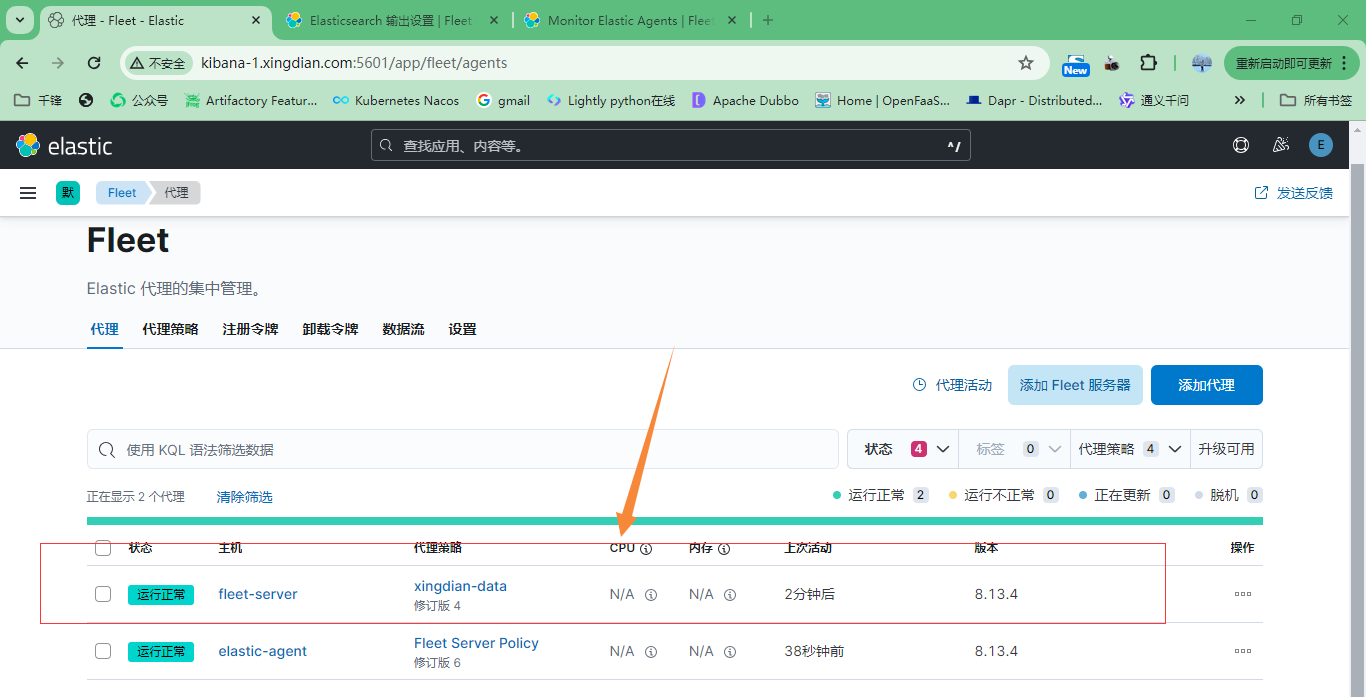
至此:代理安装成功
第七部分:Kafka

一:基本概念
1.kafka简介
kafka是一个分布式的消息发布—订阅系统,是Apache基金会并成为顶级开源项目
是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统
最大的特性就是可以实时的处理大量数据以满足各种需求场景
比如基于hadoop的批处理系统、低延迟的实时系统等等
2.kafka特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
3.核心组件
话题(Topic):是特定类型的消息流。消息是字节的有效负载,话题是消息的分类名或种子(Feed)名
生产者(Producer):是能够发布消息到话题的任何对象(发布消息到 kafka 集群的终端或服务)
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群
消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息
partition(区):每个 topic 包含一个或多个 partition,每一个topic将被分为多个partition(区)
replication:partition 的副本,保障 partition 的高可用
leader:replication 中的一个角色, producer 和 consumer 只跟 leader 交互
follower:replication 中的一个角色,从 leader 中复制数据
controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover
zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息
Consumer group:每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费
4.架构图
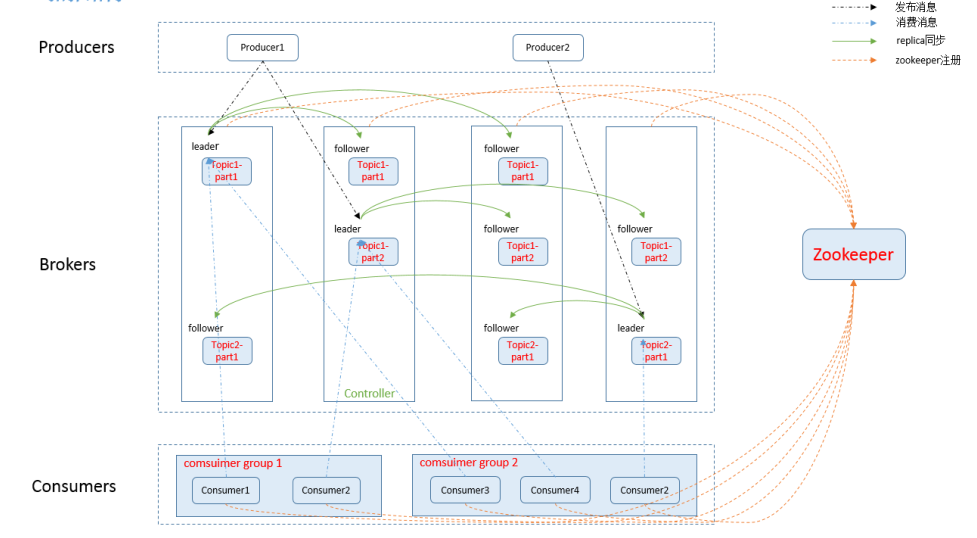
二:集群部署
无
q8-1717741628915)]
[外链图片转存中…(img-fvyCqep4-1717741628916)]
[外链图片转存中…(img-ZQqysPC8-1717741628917)]
[外链图片转存中…(img-aQYfCpmo-1717741628918)]
[外链图片转存中…(img-LoRS9nvf-1717741628918)]
[外链图片转存中…(img-yA0yP4UN-1717741628919)]
[外链图片转存中…(img-z3Prep00-1717741628920)]
[外链图片转存中…(img-0uhHnWAw-1717741628921)]
[外链图片转存中…(img-vHQwMjLp-1717741628922)]
[外链图片转存中…(img-8Dj650Ev-1717741628923)]
[外链图片转存中…(img-iebWGpRr-1717741628924)]
[外链图片转存中…(img-jGjS4SsP-1717741628925)]
5.在agent上安装
以下内容来自上面图片中的复制,注意修改参数的值
[root@fleet-server elastic-agent]# cat a.sh
./elastic-agent install --url=https://fleet-server.xingdian.com:8220 \
--fleet-server-es=https://es-1.xingdian.com:9200 \
--fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE3MTc1NzkxNzQzNDA6MEVlODhuMXhRaktEenhFOFRZRy1TZw \
--fleet-server-policy=72d46cef-c33d-4360-bc20-60d829634076 \
--certificate-authorities=/opt/ca/ca.crt \
--fleet-server-es-ca=/opt/elasticsearch-ca.pem \
--fleet-server-cert=/opt/fleet-server/fleet-server.crt \
--fleet-server-cert-key=/opt/fleet-server/fleet-server.key \
--fleet-server-port=8220
6.fleet注册
[外链图片转存中…(img-OUa9fA6T-1717741628926)]
[外链图片转存中…(img-6xAjWAAs-1717741628927)]
至此:代理安装成功
第七部分:Kafka
[外链图片转存中…(img-SsIeXHQD-1717741628928)]
一:基本概念
1.kafka简介
kafka是一个分布式的消息发布—订阅系统,是Apache基金会并成为顶级开源项目
是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统
最大的特性就是可以实时的处理大量数据以满足各种需求场景
比如基于hadoop的批处理系统、低延迟的实时系统等等
2.kafka特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
3.核心组件
话题(Topic):是特定类型的消息流。消息是字节的有效负载,话题是消息的分类名或种子(Feed)名
生产者(Producer):是能够发布消息到话题的任何对象(发布消息到 kafka 集群的终端或服务)
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群
消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息
partition(区):每个 topic 包含一个或多个 partition,每一个topic将被分为多个partition(区)
replication:partition 的副本,保障 partition 的高可用
leader:replication 中的一个角色, producer 和 consumer 只跟 leader 交互
follower:replication 中的一个角色,从 leader 中复制数据
controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover
zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息
Consumer group:每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费
4.架构图
[外链图片转存中…(img-bOW0tdbn-1717741628929)]
二:集群部署
无