引言
在本文[1]中,我们将从高层次概述大型语言模型 (LLM) 的具体含义。
背景
2023年11月,我偶然间听闻了OpenAI的开发者大会,这个大会展示了人工智能领域的革命性进展,让我深深着迷。怀着对这一领域的浓厚兴趣,我加入了ChatGPT,并很快被激发了学习其背后的大型语言模型(LLMs)技术的热情。然而,像许多人一样,我对LLMs一窍不通,不知道如何入门。
模型定义
大型语言模型(LLMs),例如ChatGPT,正在成为当今技术界的热门话题。根据维基百科,LLM的定义是:LLM是一种因其能够实现通用语言理解和生成而著称的语言模型。它们通过在计算密集型的自我监督和半监督训练过程中学习文本文档的统计关系,从而获得这些能力。LLM是采用变换器架构的人工神经网络。
换句话说:LLMs通过在包括书籍、网站和用户生成内容在内的大量文本数据集上进行训练,能够以一种自然的方式生成延续初始提示的新文本。
LLM模型本质上是一个参数众多的神经网络。简单来说,参数越多,模型的性能通常越好。因此,我们经常听到关于模型大小的讨论,这实际上是指其参数的数量。比如,GPT-3拥有1750亿个参数,而GPT-4的参数数量可能超过1万亿。
-
但模型具体长什么样呢?
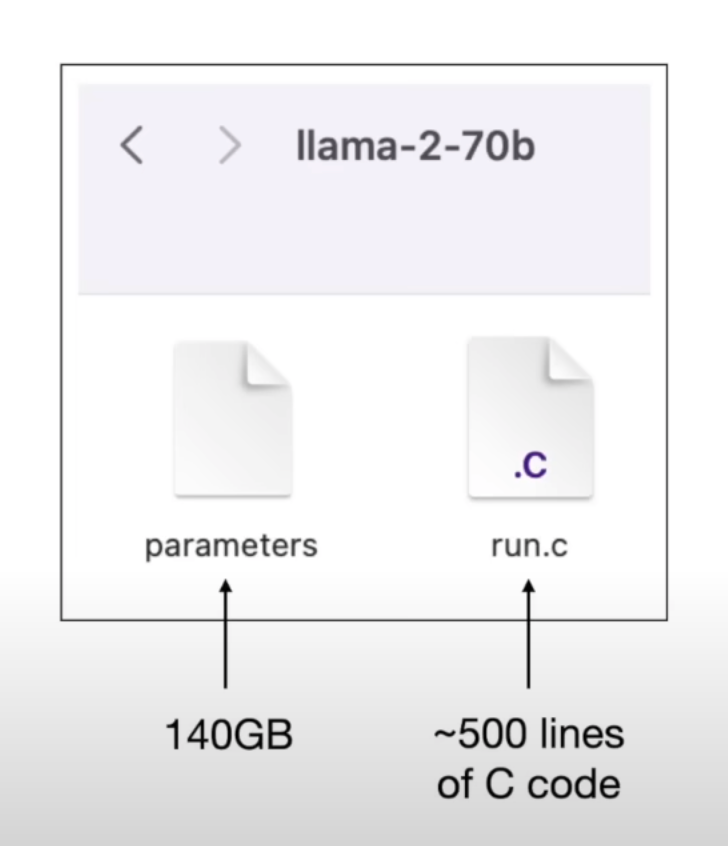
语言模型只是一个二进制文件:
上图中,参数文件是Meta的Llama-2–70b模型,大小为140GB,包含70b个参数(数字格式)。 run.c文件是推理程序,用于查询模型。训练这些超大型模型是非常昂贵的。训练像 GPT-3 这样的模型需要花费数百万美元。

目前,表现最为卓越的模型 GPT-4 已经不再是单一的模型,而是多个模型的集合体。这些模型各自针对特定领域进行了训练或微调,它们在推理时相互协作,以实现最优的性能表现。
不过,无需担心,我们的目标是掌握大型语言模型的基础理论。幸运的是,我们完全可以在自己的个人电脑上,用参数数量少得多的模型进行训练。
模型推理
当模型训练完毕并准备就绪后,用户用问题查询模型,问题文本将传递到该 140GB 文件中并逐个字符进行处理,然后返回最相关的文本作为结果输出。
最相关的意思是模型将返回最有可能是输入文本的下一个字符的文本。例如,
> Input: "I like to eat"
> Output: "apple"
"apple" 被预测为接下来的单词,这是因为在模型训练所用的大量数据中,"I like to eat" 后面最常跟随的就是 "apple"。
我们之前提到的书籍和网站,现在可以这样理解:基于我们提供的数据片段,模型学习到 "I like to eat apple" 是一个频繁出现的句子。而 "I like to eat banana" 也是一个常见的句子,但出现频率没有前者高。
在模型训练时,它:记录了 "apple" 在 "I like to eat" 后面出现的概率为 0.375. 记录了 "banana" 在 "I like to eat" 后面出现的概率为 0.146 和 … 其他单词的概率记录 …
这些概率值实际上被保存在模型文件中,形成了概率集合。(在机器学习中,这些概率通常被称作权重。)简而言之,LLM模型就像是一个概率数据库,它能够为任何特定的字符以及其上下文相关的字符赋予一定的概率分布。
在2017年之前,这样的技术听起来还像是天方夜谭。然而,自从论文《Attention is all you need》发表之后,Transformer 架构的出现,使得通过训练神经网络处理庞大的数据集,实现对上下文的深入理解成为现实。
模型架构
在大型语言模型(LLM)诞生之前,神经网络的机器学习确实只能使用较小的数据集,对于文本的上下文理解能力十分有限。这导致早期的模型无法像人类那样深入理解文本。
该论文最初发表时,是为了训练用于语言翻译的模型。但OpenAI的团队意识到,Transformer 架构是实现字符预测的关键技术。一旦模型经过整个互联网数据的训练,它就可能像人类一样,理解任何文本的上下文,并流畅地完成句子。
下面是一个图解,描述了模型训练过程中的内部机制:
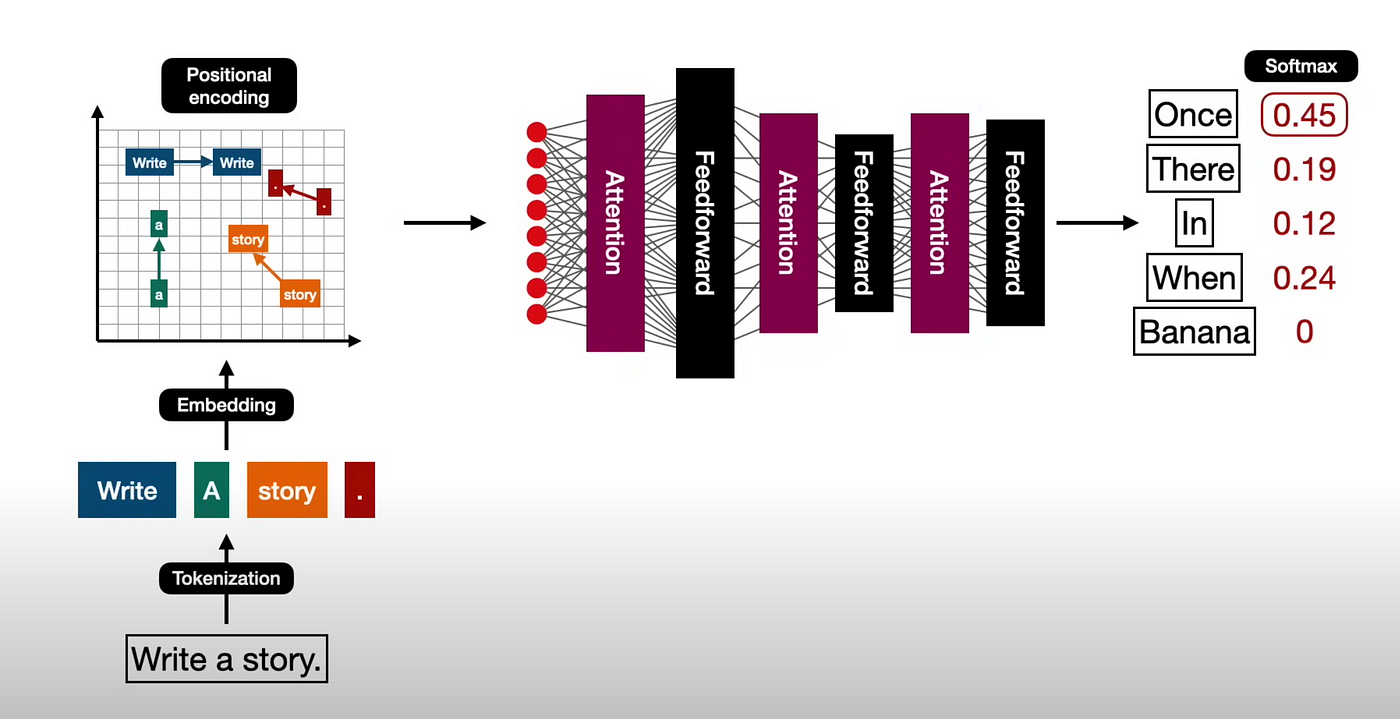
初次接触时我们可能不太明白,但别担心,我们将在随后的文章中逐步解释清楚。
Source: https://medium.com/@waylandzhang/what-is-large-language-model-llms-zero-to-hero-06f329767d03
本文由 mdnice 多平台发布



![[经验] 场效应管是如何发挥作用的 #知识分享#学习方法#职场发展](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fupload%2F2023%2F05%2F20230524161436168491607686604.jpg&pos_id=beh9nDbH)
![[职场] 社保和商业保险有什么区别?可以只买商保不买社保吗? #微信#经验分享#媒体](https://img-blog.csdnimg.cn/img_convert/e2a888fabb02c9f64c25a2fe75cb188d.jpeg)