文章目录
- 一、说明
- 二、GAN的介绍
- 三、生成器和鉴别器
- 四、代码实现
一、说明
前言废话免了,会进来看文章内容的只有四种人:1. 只想知道皮毛,GAN在干什么的 2. 想知道细节怎么把GAN训练起来;3. 收藏在收藏夹或是书签当作有看过了;4. 上课上到一定要点点进来。
二、GAN的介绍
GAN属于unsupervised learning。白话一点,GAN是用来生成资料。讲难听一点,GAN被广泛用来造假的。 (但也有正向的)
最近比较知名的影像转换

AI界知名人士的小孩版本。 (source: https://www.reddit.com/r/MachineLearning/comments/o843t5/d_types_of_machine_learning_papers/)
如果不认识我帮你们对应起来

我其实有找到其他人对应的图,但我懒得放了。
下面的网址有用StyleGAN: 可以让人变年轻微笑的范例。
我其实有找到其他人对应的图,但我懒得放了。
下面的网址有用StyleGAN: 可以让人变年轻微笑的范例。 https://www.reddit.com/r/MachineLearning/comments/o6wggh/r_finally_actual_real_images_editing_using/
这不是跟抖音内建功能一样,可以换脸(卡通),可以换表情,可以自动上妆,这用到的技术就是GAN相关的,屏除到政治因素,我个人觉得抖音满好玩的。
听说这个蚂蚁呀嘿下架了,我还没玩到><
利用GAN技术让老照片活起来,

Source: https://imgur.com/i284hKw
以上都是GAN应用最近比较有名的一些影片或是APP等简单介绍。
三、生成器和鉴别器
GAN 生成对抗网络:顾名思义,就是有两个网络架构,分别为「生成」(Generator)和「对抗」(Discriminator)
GAN的概念很简单,我们可以用一部老电影来描述(中文:神鬼交锋,英文: Catch me if you can,英文比较有感):
中文:神鬼交锋,英文: Catch me if you can
一个造假者(李奥纳多)和一个专家(汤姆汉克),造假者需要做假的东西(假支票)出来,让专家去判断真伪,透过专家的判断造假者在不断的增进自己的造假技术,直到专家无法有效的判断真伪。
整个GAN运作的核心概念如下,莱昂纳多就是「生成器(Generator)」,汤姆汉克就是「对抗: 辨别器(Discriminator)」:

花样看完了,实际上我们将GAN化成简图,如下
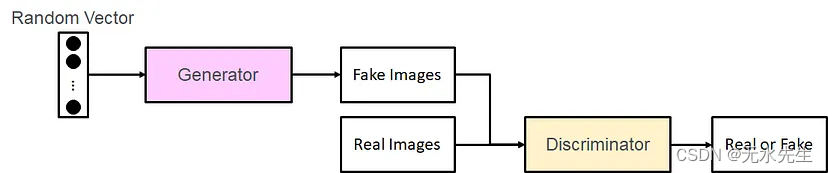
Generator (G) 和 Discriminator (D)
D要判断「真」还是「假」
G生成的数据要呼咙D。
从Random Vector(z,可以为均匀分布或是常态分布)丢入G生成出图片,所以目的就是希望使得G(z)的机率分布接近D的机率分布。
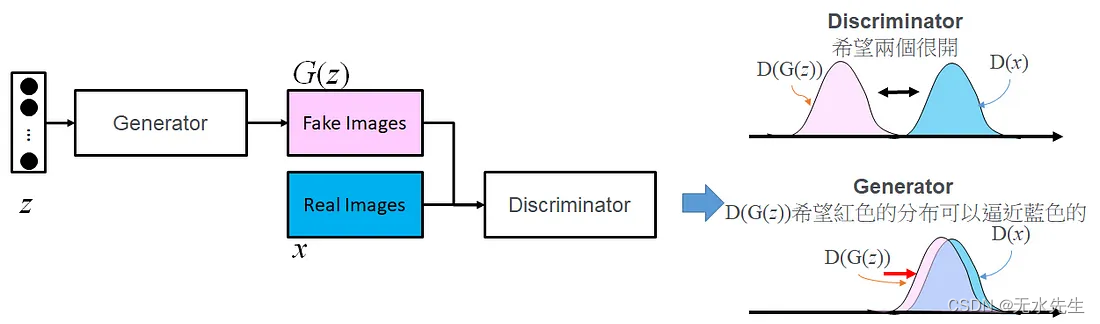
GAN的核心想法
Discriminator: 希望D(x)真实数据被判给真实的机率期望值最大(接近1)
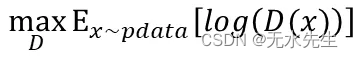
Discriminator: 希望D(G(z))假资料被判给真实的机率期望值最小(接近0)
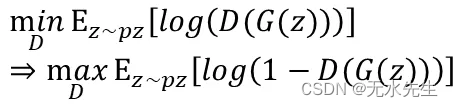
Generator -> Discriminator: 因为要乎巄D,所以在Generator阶段,希望D(G(z))假资料被判给真实的机率期望值最大(接近1)
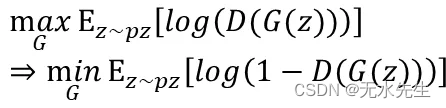
Objective Function of GAN:
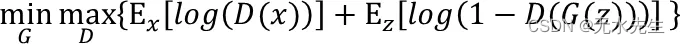
看到这边应该很有感才对,不管是在公式或是算法上
实际上GAN的坑很多,光是Generator和Discriminator怎么设计就是个坑了。
后面范例以DCGAN的模型要设计过Generator才有办法Upsample到MNIST的大小(28*28)。
Generator参数变化不要一次更新太大,通常可以更新几次D后再更新G。 (MNIST范例很简单,所以可以不用)
Learning rate不要设定太大。 如果大家有看过其他人范例大部分都设定为0.0002,其实这样的设定有文献出处Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks

以上是很简单的GAN理论(有错请鞭小力一点,不要太凶)介绍。
Pytorch手把手进行DCGAN实现,以MNIST数据库为例
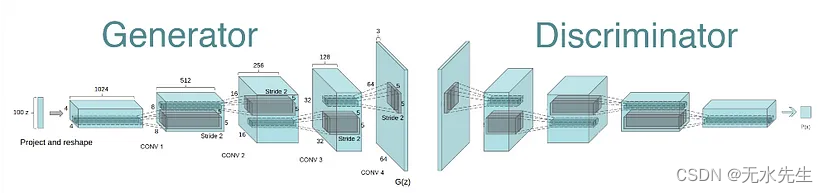
这张图的来源我忘了(应该是DCGAN的论文吧),但这些文章没有营利,应该没有触法吧。
四、代码实现
- 先import 模块吧。
# -*- coding: utf-8 -*-
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import transforms
import numpy as np
import matplotlib.pyplot as plt
import torchvision.utils as vutils
import PIL.Image as Image
Generator
因为我的random vector(z)是采用 latents x 1 x 1 (latents代表z的维度数)
DCGAN是采用ConvTranspose2d进行上采样的进行,也就是让图变大张。
MNIST图片为28 x 28,一般上采样通常是固定放大1倍。
1 x 1 → 上采样 → 2 x 2 → 上采样 → 4 x 4 → 上采样 → 8 x 8 → 上采样 → 16 x 16 → 上采样 → 32 x 32
所以不会变成28 x 28。
所以我利用ConvTranspose2d的stride和pad的设计,让上采样可以非1倍放大,细节请看代码,我每一层输出的大小有写在备注。
1 x 1 → ConvTranspose2d → 2 x 2 → ConvTranspose2d → 3 x 3 → ConvTranspose2d → 6 x 6 → ConvTranspose2d → 7 x 7 → ConvTranspose2d → 14 x 14 → ConvTranspose2d → 28 x 28
Discriminator
这边就没什么特别注意,就是建立一个分类CNN而已,所以我建立一个5层CNN+1层FC可以看下面Discriminator的定义。
我们先订一些卷积模块(CBR, CBLR, TCBR),然后依据上述建立「Generator」和「Discriminator」。
# custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
class CBR(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
norm_layer = nn.BatchNorm2d
super(CBR, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
norm_layer(out_planes),
nn.ReLU(inplace=True),
)
class CBLR(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
norm_layer = nn.BatchNorm2d
super(CBLR, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
norm_layer(out_planes),
nn.ReLU(inplace=True),
)
class TCBR(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=4, stride=2, padding=1):
padding = (kernel_size - 1) // 2
norm_layer = nn.BatchNorm2d
super(TCBR, self).__init__(
nn.ConvTranspose2d(in_planes, out_planes, kernel_size, stride, padding, bias=False),
norm_layer(out_planes),
nn.ReLU(inplace=True),
)
class Generator(nn.Module):
def __init__(self, latents):
super(Generator, self).__init__()
self.layer1= nn.Sequential(
# input is random_Z, state size. latents x 1 x 1
# going into a convolution
TCBR(latents, 256, 4, 2, 1), # state size. 256 x 2 x 2
CBR(256, 128, 3, 1)
)
self.layer2= nn.Sequential(
TCBR(128, 256, 4, 1, 0), # state size. 256 x 3 x 3
TCBR(256, 256, 4, 2, 1), # state size. 256 x 6 x 6
)
self.layer3= nn.Sequential(
TCBR(256, 128, 4, 1, 0), # state size. 256 x 7 x 7
TCBR(128, 128, 4, 2, 1), # state size. 256 x 14 x 14
CBR(128, 128, 3, 1)
# state size. 256 x 6 x 6
)
self.layer4= nn.Sequential(
TCBR(128, 64, 4, 2, 1), # state size. 64 x 28 x 28
CBR(64, 64, 3, 1),
CBR(64, 64, 3, 1),
nn.Conv2d(64, 1, 3, 1, 1), # state size. 1 x 28 x 28
nn.Tanh()
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
class Discriminator(nn.Module):
def __init__(self,):
super(Discriminator, self).__init__()
self.conv = nn.Sequential(
CBLR(1, 32, 3, 2), # b*32*14*14
CBLR(32, 64, 3, 1), # b*64*14*14
CBLR(64, 128, 3, 2), # b*128*7*7
CBLR(128, 128, 3, 2), # b*32*3*3
CBLR(128, 64, 3, 2), # b*32*1*1
)
self.fc = nn.Linear(64,2)
def forward(self, x):
x = self.conv(x)
x = nn.functional.adaptive_avg_pool2d(x, 1).reshape(x.shape[0], -1)
ft = x
output = self.fc(x)
return output
这边开始我们宣告一些pytorch训练需要的一些组件,例如:GPU的使用、Generator 和「Discriminator」的optimizer、学习时候学习率的lr_scheduler和MNIST的dataloader等。
# from torchvision.utils import save_image
flag_gpu = 1
# Number of workers for dataloader
workers = 0
# Batch size during training
batch_size = 100
# Number of training epochs
epochs = 20
# Learning rate for optimizers
lr = 0.0002
# GPU
device = 'cuda:0' if (torch.cuda.is_available() & flag_gpu) else 'cpu'
print('GPU State:', device)
# Model
latent_dim = 10
G = Generator(latents=latent_dim).to(device)
D = Discriminator().to(device)
G.apply(weights_init)
D.apply(weights_init)
# Settings
g_optimizer = optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
d_optimizer = optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))
g_scheduler = torch.optim.lr_scheduler.StepLR(g_optimizer, step_size=5, gamma=0.5)
d_scheduler = torch.optim.lr_scheduler.StepLR(d_optimizer, step_size=5, gamma=0.5)
# Load data
train_set = datasets.MNIST('./dataset', train=True, download=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=workers)
Generator的更新
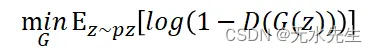
Discriminator的更新
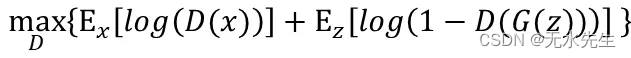
等下程序在执行,模型的Update (loss)需要符合上述的执行,
def show_images(images, epoch):
sqrtn = int(np.ceil(np.sqrt(images.shape[0])))
plt.figure()
for index, image in enumerate(images):
plt.subplot(sqrtn, sqrtn, index+1)
plt.imshow(image.reshape(28, 28))
plt.savefig("Generator_epoch_{}.png".format(epoch))
# Train
adversarial_loss = torch.nn.CrossEntropyLoss().to(device)
# adversarial_loss = torch.nn.BCELoss().to(device)
G.train()
D.train()
loss_g, loss_d = [],[]
start_time= time.time()
for epoch in range(epochs):
epoch += 1
total_loss_g,total_loss_d=0,0
count_d=0
for i_iter, (images, label) in enumerate(train_loader):
i_iter += 1
# -----------------
# Train Generator
# -----------------
g_optimizer.zero_grad()
# Sample noise as generator input
noise = torch.randn(images.shape[0], latent_dim, 1, 1)
noise = noise.to(device)
# 因為Generator希望生成出來的圖片跟真的一樣,所以fake_label標註用 1
fake_label = torch.ones(images.shape[0], dtype=torch.long).to(device) # notice: label = 1
# Generate a batch of images
fake_inputs = G(noise)
fake_outputs = D(fake_inputs)
# Loss measures generator's ability to fool the discriminator
loss_g_value = adversarial_loss(fake_outputs, fake_label)
loss_g_value.backward()
g_optimizer.step()
total_loss_g+=loss_g_value
loss_g.append(loss_g_value)
# ---------------------
# Train Discriminator
# ---------------------
# Zero the parameter gradients
d_optimizer.zero_grad()
# Measure discriminator's ability to classify real from generated samples
# 因為Discriminator希望判斷哪些是真的那些是生成的,所以real_label資料標註用 1,fake_label標註用0。
real_inputs = images.to(device)
real_label = torch.ones(real_inputs.shape[0], dtype=torch.long).to(device)
fake_label = torch.zeros(fake_inputs.shape[0], dtype=torch.long).to(device)
# learning by Discriminator
real_loss = adversarial_loss(D(real_inputs),real_label)
fake_loss = adversarial_loss(D(fake_inputs.detach()),fake_label)
loss_d_value = (real_loss + fake_loss) / 2
loss_d_value.backward()
d_optimizer.step()
total_loss_d+=loss_d_value
loss_d.append(loss_d_value)
total_loss_g/=len(train_loader)
total_loss_d/=len(train_loader)
g_scheduler.step()
d_scheduler.step()
print('[Epoch: {}/{}] D_loss: {:.3f} G_loss: {:.3f}'.format(epoch, epochs, total_loss_d.item(), total_loss_g.item()))
if epoch % 1 == 0:
print('Generated images for epoch: {}'.format(epoch))
imgs_numpy = fake_inputs.data.cpu().numpy()
show_images(imgs_numpy[:16],epoch)
plt.show()
torch.save(G, 'DCGAN_Generator.pth')
torch.save(D, 'DCGAN_Discriminator.pth')
print('Model saved.')
print('Training Finished.')
print('Cost Time: {}s'.format(time.time()-start_time))
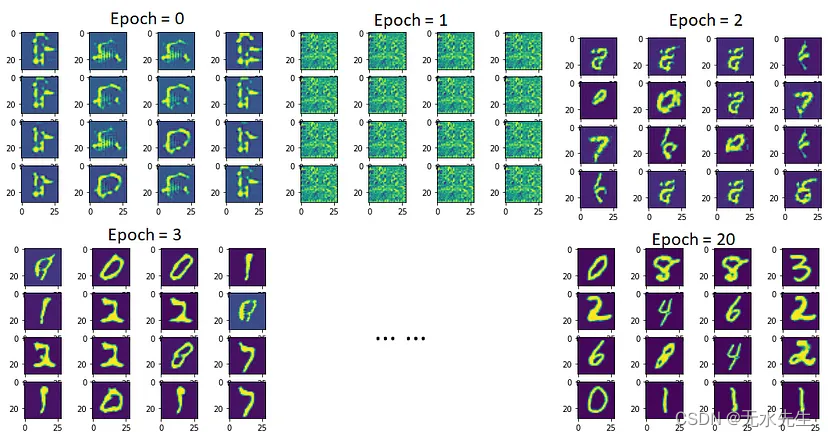
执行后的结果
[Epoch: 1/20] D_loss: 0.373 G_loss: 1.240
Generated images for epoch: 1
[Epoch: 2/20] D_loss: 0.157 G_loss: 2.229
Generated images for epoch: 2
[Epoch: 3/20] D_loss: 0.145 G_loss: 2.603
Generated images for epoch: 3
[Epoch: 4/20] D_loss: 0.354 G_loss: 1.390
Generated images for epoch: 4
[Epoch: 5/20] D_loss: 0.447 G_loss: 1.162
Generated images for epoch: 5
[Epoch: 6/20] D_loss: 0.472 G_loss: 1.064
Generated images for epoch: 6
[Epoch: 7/20] D_loss: 0.473 G_loss: 1.062
Generated images for epoch: 7
[Epoch: 8/20] D_loss: 0.444 G_loss: 1.131
Generated images for epoch: 8
[Epoch: 9/20] D_loss: 0.437 G_loss: 1.152
Generated images for epoch: 9
[Epoch: 10/20] D_loss: 0.460 G_loss: 1.115
Generated images for epoch: 10
[Epoch: 11/20] D_loss: 0.535 G_loss: 0.956
Generated images for epoch: 11
[Epoch: 12/20] D_loss: 0.491 G_loss: 1.026
Generated images for epoch: 12
[Epoch: 13/20] D_loss: 0.509 G_loss: 0.994
Generated images for epoch: 13
[Epoch: 14/20] D_loss: 0.502 G_loss: 1.013
Generated images for epoch: 14
[Epoch: 15/20] D_loss: 0.503 G_loss: 1.011
Generated images for epoch: 15
[Epoch: 16/20] D_loss: 0.570 G_loss: 0.900
Generated images for epoch: 16
[Epoch: 17/20] D_loss: 0.571 G_loss: 0.899
Generated images for epoch: 17
[Epoch: 18/20] D_loss: 0.582 G_loss: 0.888
Generated images for epoch: 18
[Epoch: 19/20] D_loss: 0.574 G_loss: 0.887
Generated images for epoch: 19
[Epoch: 20/20] D_loss: 0.516 G_loss: 0.982
Generated images for epoch: 20
Model saved.
Training Finished.
Cost Time: 715.010427236557s
不同epoch训练出来生成的结果图。
plt.plot(loss_g)
plt.plot(loss_d,‘r’)
plt.legend([‘G’,‘D’])
plt.show()
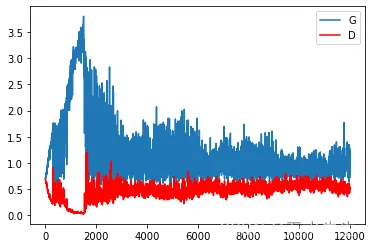
Generator 和Discriminator在每一次更新的loss变化。
收敛了 ,可以进行生成测试。
Generator测试
import torch
def show_images(images):
sqrtn = int(np.ceil(np.sqrt(images.shape[0])))
plt.figure()
for index, image in enumerate(images):
plt.subplot(sqrtn, sqrtn, index+1)
plt.imshow(image.reshape(28, 28))
plt.show()
flag_gpu = 1
device = 'cuda:0' if (torch.cuda.is_available() & flag_gpu) else 'cpu'
print(device)
G = torch.load('DCGAN_Generator.pth', map_location=device)
latent_dim = 10
## Exp:1
noise = torch.randn(20, latent_dim, 1, 1)
noise = noise.to(device)
# Generate a batch of images
fake_inputs = G(noise)
imgs_numpy = fake_inputs.data.cpu().numpy()
show_images(imgs_numpy[:16])
## Exp:2
noise = torch.randn(20, latent_dim, 1, 1) *-10000
noise = noise.to(device)
# Generate a batch of images
fake_inputs = G(noise)
imgs_numpy = fake_inputs.data.cpu().numpy()
show_images(imgs_numpy[:16])
## Exp:3
noise = torch.randn(20, latent_dim, 1, 1) *50000
noise = noise.to(device)
# Generate a batch of images
fake_inputs = G(noise)
imgs_numpy = fake_inputs.data.cpu().numpy()
show_images(imgs_numpy[:16])
- 实验一: random vector(z)是采用 latents产生范围normal(0,1),大概范围是-3~3之间,生成的图片

实验一
- 实验二: random vector(z)是采用 latents产生范围normal(0,1)*-10000,大概范围是-30000~30000之间,生成的图片
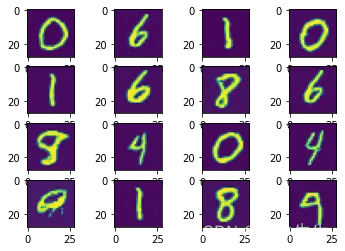
实验二
- 实验三: random vector(z)是采用 latents产生范围normal(0,1)* 50000,大概范围是-50000~50000之间,生成的图片

实验三
大家可以和Pytorch手把手实作-AutoEncoder这篇比较,这个random vector(z)在GAN好像比较不会影响结果,但可能是生成结构的关系,在图片生成的过程中已经将input的random vector(z)正规化了,所以在生成的时候就不影响,但实际上是怎么避掉这样的影响我就没有去深入研究。