前言
在科技日新月异的今天,人工智能(AI)已不再是遥不可及的未来科技,而是逐渐融入我们日常生活的实用工具。从智能语音助手到自动驾驶汽车,从智能家居系统到精准医疗诊断,AI技术正以其强大的计算能力和数据分析能力,改变着我们的工作方式、生活方式乃至思维方式。
相信大家对高考都有极深的感情,不管是考的好或不好,都是我们人生中难以忘记的一个拐点,那么在现如今AI时代,我不禁想到,如果用人工智能参加高考,会得多少分呢?
不知道朋友们有没有关注今年的高考作文题目呢?有部分考生反馈,很庆幸,自己的语文老师押中了作文的方向,尤其是“新课标 I 卷”的作文。毕竟去年 ChatGPT 正火热的时候,还有不少人好奇为什么“高考作文没有与 AI 相关的”,原来惊喜留在了今年。
紧密结合当下科技发展潮流的“新课标 I 卷”的作文聚焦在 AI 上,题目为:
阅读下面的材料,根据要求写作。(60分) 随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?
以上材料引发了你怎样的联想和思考?请写一篇文章。
要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。
人工智能相关技术
人工智能,简称AI,是计算机科学的一个分支,旨在开发和应用能够模拟、延伸和扩展人类智能的理论、方法和技术,包括机器人、自然语言处理、语音和图像识别、专家系统等。它结合了数学、计算机科学、心理学等多学科的理论,通过让计算机模拟人类的思考和行为过程,实现人机交互,提高计算机的智能水平,以更好地服务于人类社会。
近年来,随着深度学习技术的突破,AI在诸多领域取得了显著的成果。深度学习是机器学习的一个分支,它利用神经网络模型来模拟人脑的学习过程,通过大量的数据训练,使计算机能够自动提取特征并进行预测或分类。在写作领域,深度学习技术可以帮助计算机理解和生成自然语言文本,从而实现自动化写作或辅助写作。
随着人工智能技术的迅猛发展,其在各个领域的应用越来越广泛,包括教育领域。高考作文,作为评估学生语言运用能力和思维水平的重要标准,一直是教育领域的关注焦点。近年来,利用AI技术进行高考作文辅助写作的研究和实践逐渐增多,这不仅为作文教学带来了新的可能性,也为我们提供了一个独特的视角来审视AI技术在自然语言处理(NLP)领域的应用。
一、人工智能与自然语言处理
计算机中的数据分为两大类:
- 结构化数据:指可以按某种数据结构组织的数据,比如字母、数字、货币、日期
- 非结构化数据:指没有按照预定义的方式组织或缺少特定数据模型的数据,比如文章、演示文稿、电子邮件、日志等
结构化数据易于处理,传统计算机可以代替人工高速处理这类结构化数据。然而实际上大多数数据都是非结构化的,而且非结构化数据比结构化数据具有更大的信息量。在人工智能出现后,对非结构化数据的处理进行了探索,并取得了一定成效。
自然语言处理(Natural Language Processing, NLP) 就是一种通过分析非结构化人类语言,理解文本信息并加以利用的人工智能技术,是研究在人与人交互中以及在人与计算机交互中的语言问题的一门学科。它研究如何使计算机能够理解和生成人类自然语言。NLP技术涵盖了文本分析、文本生成、信息抽取、情感分析等多个方面,这些技术为AI在高考作文写作中的应用提供了基础。
NLP目前的主要研究方向包括:
- 信息抽取:从给定文本中抽取重要的信息,比如时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等
- 文本生成:机器像人一样使用自然语言进行表达和写作
- 问答系统:对一个自然语言表达的问题,通过查询与语义分析,给出一个精准的答案
- 对话系统:通过一系列的对话,理解用户意图,与用户进行沟通
- 文本挖掘:包括文本聚类、分类、情感分析等
- 语音识别和生成
- 信息过滤:通过计算机系统自动识别和过滤符合特定条件的文档信息,主要用于信息安全和防护,网络内容管理等
- 舆情分析:是指收集和处理海量信息,自动化地对网络舆情进行分析,以实现及时应对网络舆情的目的
- 信息检索:对大规模文档进行索引
- 机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本
在写作中,NLP技术可以发挥以下作用:
- 文本分析:通过分析学生的作文文本,提取出关键信息、主题思想、情感倾向等,帮助教师更好地评估学生的写作水平。
- 文本生成:基于大量的语料库和训练数据,AI可以生成符合高考作文要求的文章框架、段落结构和句子表达,为学生提供写作参考。
- 信息抽取:从给定文本中抽取与作文主题相关的知识、观点、论据等,帮助学生丰富作文内容,提高作文质量。
AI在高考作文写作中的技术实现
要实现AI在高考作文写作中的应用,需要借助一系列先进的技术手段和方法。以下是几个关键的技术点:
- 深度学习:深度学习是NLP领域的核心技术之一,它通过构建神经网络模型,让计算机自动学习文本数据的内在规律和特征。在高考作文写作中,深度学习模型可以用于作文文本的自动分类、情感分析、主题识别等任务。
- 自然语言生成:自然语言生成(NLG)技术是指让计算机能够生成人类可理解的自然语言文本。在高考作文写作中,NLG技术可以用于生成符合语法和语义规范的句子、段落和篇章结构。
- 知识图谱:知识图谱是一种用于表示实体、概念和它们之间关系的数据结构。在高考作文写作中,知识图谱可以帮助AI从海量数据中抽取与作文主题相关的知识点,并构建它们之间的关联关系,从而为学生提供更丰富的写作素材和思路。
- 文本摘要与压缩:由于高考作文篇幅有限,学生需要在有限的字数内充分表达自己的观点和想法。文本摘要与压缩技术可以帮助AI从长文本中提取出关键信息和主要观点,并将其压缩成符合要求的短文本形式,从而辅助学生完成作文任务。
在技术层面,由于高考作文写作涉及到复杂的自然语言处理(NLP)技术和深度学习模型,且这些技术的实现通常需要大量的代码和专业的训练数据,因此在这里直接给大家完整的代码示例并不现实。不过,可以为大家展示一个简化的、概念性的代码框架,用来说明AI在高考作文辅助写作中可能涉及的一些关键步骤和概念。
注意,这个框架是一个高度简化的版本,并不直接适用于真实的高考作文写作场景。真实的系统需要更复杂的模型和大量的数据来训练和优化。
概念性代码框架
# 假设我们有一些预处理好的作文数据集(需要自行准备或下载)
# 这些数据集用于训练AI模型
# 1. 数据预处理
# 在这里,你可能需要执行一些文本清洗、分词、词性标注等步骤
def preprocess_data(text):
# 文本清洗(去除标点符号、特殊字符等)
# 分词
# 词性标注(可选)
# ... 其他预处理步骤
cleaned_text = ...
return cleaned_text
# 2. 构建词向量(可选步骤,用于表示文本)
# 在这里,我们可以使用Word2Vec、GloVe等预训练模型,或者自己训练词向量
from gensim.models import Word2Vec
# 假设我们已经有了一个预处理好的文本语料库
corpus = [...] # 包含多篇预处理后的作文文本
# 训练词向量模型
model = Word2Vec(corpus, vector_size=100, window=5, min_count=1, workers=4)
# 3. 构建深度学习模型(例如,用于作文评分或生成作文开头)
# 在这里,我们可以使用循环神经网络(RNN)、长短时记忆网络(LSTM)或Transformer等模型
import torch
import torch.nn as nn
class EssayModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(EssayModel, self).__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# LSTM层
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
# 全连接层
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# 嵌入层
embedded = self.embedding(x)
# LSTM层
lstm_out, _ = self.lstm(embedded)
# 取最后一个时间步的输出
output = lstm_out[:, -1, :]
# 全连接层
output = self.fc(output)
return output
# 初始化模型(需要定义vocab_size, embedding_dim, hidden_dim, output_dim等参数)
model = EssayModel(...)
# 4. 训练模型(需要定义损失函数、优化器等)
# 这里省略了训练循环和模型保存的代码
# 5. 使用模型进行作文评分或生成作文开头(示例)
def generate_essay_start(model, start_text, tokenizer, max_length):
# 将开始文本转换为词向量
input_tensor = tokenizer.encode(start_text, add_special_tokens=False).unsqueeze(0)
input_lengths = torch.tensor([len(input_tensor[0])])
# 初始化隐藏状态和单元状态(对于LSTM)
h0 = torch.zeros(1, 1, model.lstm.hidden_size).to(input_tensor.device)
c0 = torch.zeros(1, 1, model.lstm.hidden_size).to(input_tensor.device)
# 前向传播
output, _ = model.lstm(input_tensor, (h0, c0))
# 生成接下来的文本(这里只是示例,实际可能需要更复杂的解码策略)
# ...
# 返回生成的作文开头
return generated_text
# 注意:上述代码仅为示例,实际实现会涉及更多的细节和复杂性
注意:
1. 数据:需要有一个大规模的、标注好的作文数据集来训练你的模型。这通常涉及到从公开资源获取数据、进行人工标注或使用已有的标注数据集。
2. 预处理:作文文本通常需要进行清洗、分词、词性标注等预处理步骤,以便模型能够更好地理解文本内容。
3. 模型选择:根据具体需求(如作文评分、作文生成等),可能需要选择不同的深度学习模型。上述示例中仅使用了LSTM模型作为示例。
那这道作文题究竟该怎么答?我们让参与百模大战的各家大厂大模型产品们试了试,没想到让 AI 写一篇 800-1000 字的 AI 作文,只需要约 20 秒的时间。
接下来,我们将细细品读 10 款主流的大模型带来的最新作品!

OpenAI 的 GPT-4o
外国人学好中文并不是一件易事,那国外大模型的语文水平如何?OpenAI 的 GPT-4o 给出了它的答案:
作文标题:《信息时代的提问与思考》


自评得分:50 分(满分为 60 分)

Google Gemini
作文标题:《互联网时代,问题与思考》

自评得分:45 分(满分为 60 分)
“总而言之,我的作文是一篇合格的作文,但仍有很大的改进空间。如果满分为60分,我会给自己打45分。”Google Gemini 自评道。

百度——文心一言
作文标题:《在智能时代,我们的问题为何仍如繁星》

自评得分:50-52 分(满分为 60 分)

阿里——Qwen2-72B-instruct Chat
就在今天,阿里通义千问 Qwen2 大模型发布,并在 Hugging Face(https://huggingface.co/Qwen)、GitHub(https://github.com/QwenLM/Qwen2)和 ModelScope(https://modelscope.cn/organization/qwen)上同步开源。
我们也在第一时间体验了一下。
作文标题:《信息洪流下的求知之路》
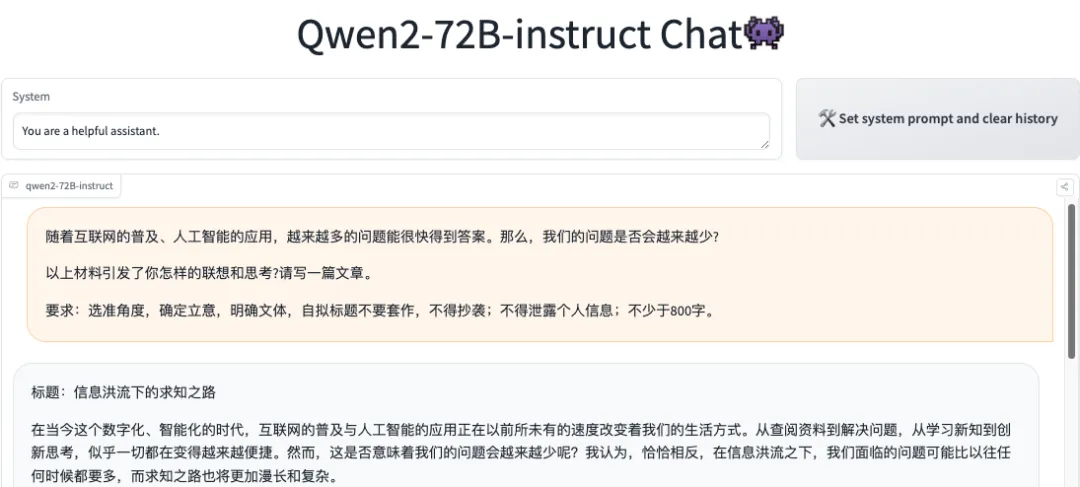
自评得分:55 分(满分为 60 分)
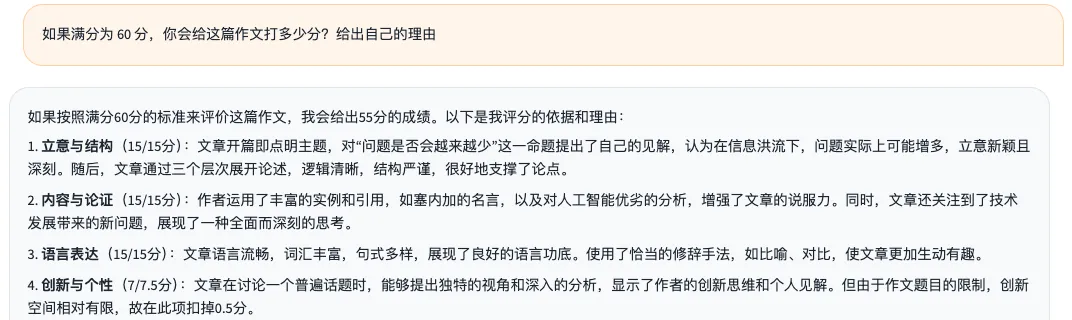
腾讯元宝
作文标题:《智涌未来,问题无穷——论互联网与人工智能时代的问与答》

自评得分:54 分(满分为 60 分)

科大讯飞——讯飞星火大模型
作文标题:《互联网和人工智能:问题的答案还是新问题的源泉?》

自评得分:50 分(满分为 60 分)
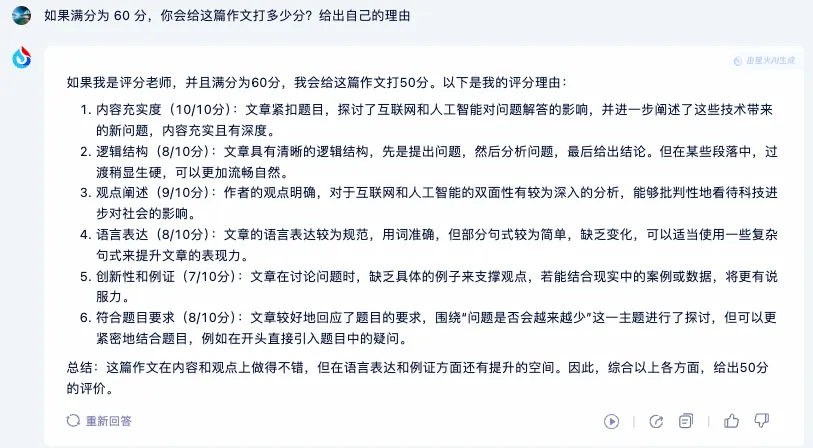
昆仑万维——天工 AI
作文标题:《数字时代的智慧之光与思考之影》

自评得分:55 分(满分为 60 分)

字节跳动——豆包
作文标题:《问题之泉,永不干涸》

自评得分:50 分(满分为 60 分)

月之暗面——Kimi
作文标题:《智能时代:问题的答案与新问题的诞生》
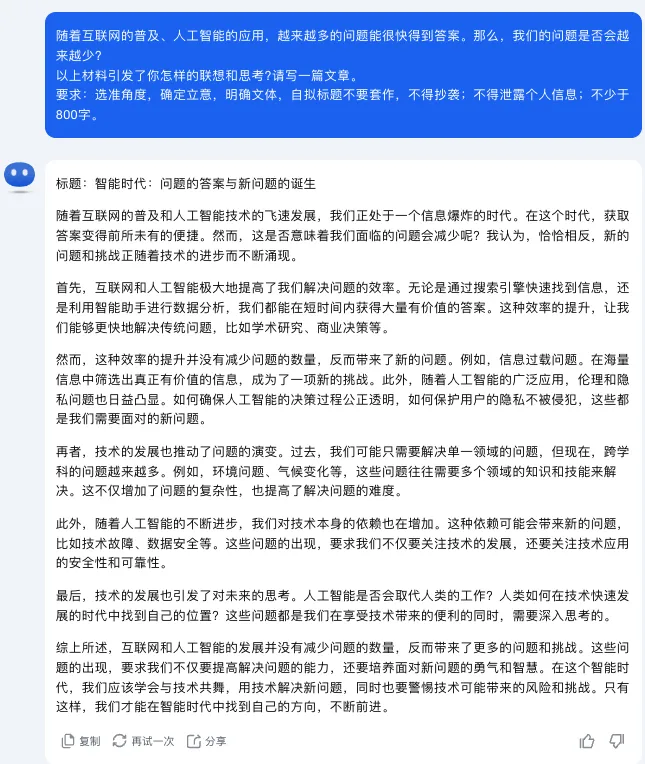
当让 Kimi 自评这篇作文时,其起初称,“作为人工智能助手,我并不具备主观评价文章的能力,但我可以提供一些评价标准供您参考”。不过,再次问它一遍时,它自评得分为:45-50 分(满分为 60 分)。
零一万物——万知
作文标题:《信息时代的提问艺术:从依赖到创新》

自评得分:55 分(满分为 60 分)。

以上便是一些主流 AI 工具生成的高考作文。我个人觉得这篇作文题目难度并不大,考生们考前应该也都写过类似的文章,所以平均分应该都有45分吧,AI这么多素材50分也挺正常。
AI懂问题,但不懂作文,所以AI回答的差别不大,但是如果要求加上小说叙述等其他文体,AI写的就会更有深意,感觉他们在彼此抄袭,立意、事例都很像。整体比较俗气,中流水平。其中,阿里最新的发布的 Qwen2、昆仑万维的天工 AI、零一万物的万知给自己的作文打分最高,均达到了 55 分。你觉得它们的水平如何?哪家写得最好?