外挂知识库
1.什么是rag?
RAG,即LLM在回答问题或生成文本时,会先从大量文档中检索出相关的信息,然后基于这些信息生成回答或文本,从而提高预测质量。
2.外挂知识库的实现思路
只用几十万量级的数据对大模型进行微调并不能很好的将额外知识注入大模型。如果想让大模型根据文档来回答问题,必须要精简在输入中文档内容的长度。
如果模型对无限长的输入都有很好的理解能力,那么我可以设计这样一个输入“以下是世界上所有乐队的介绍:[插入100w字的乐队简介文档],请根据上文给我介绍一下万青这支乐队”,让模型来回答我的问题。
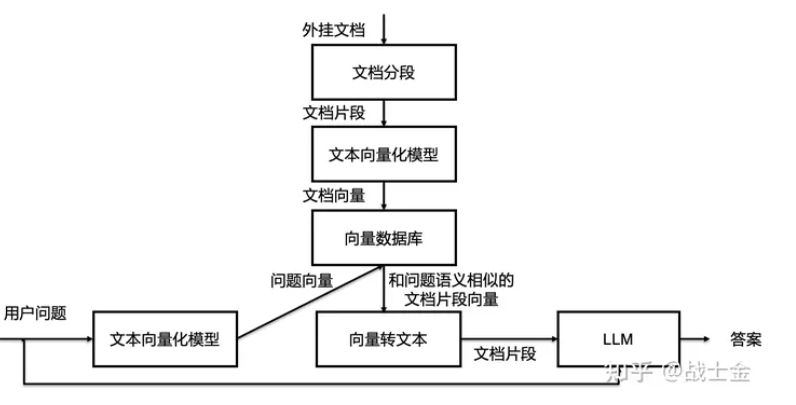
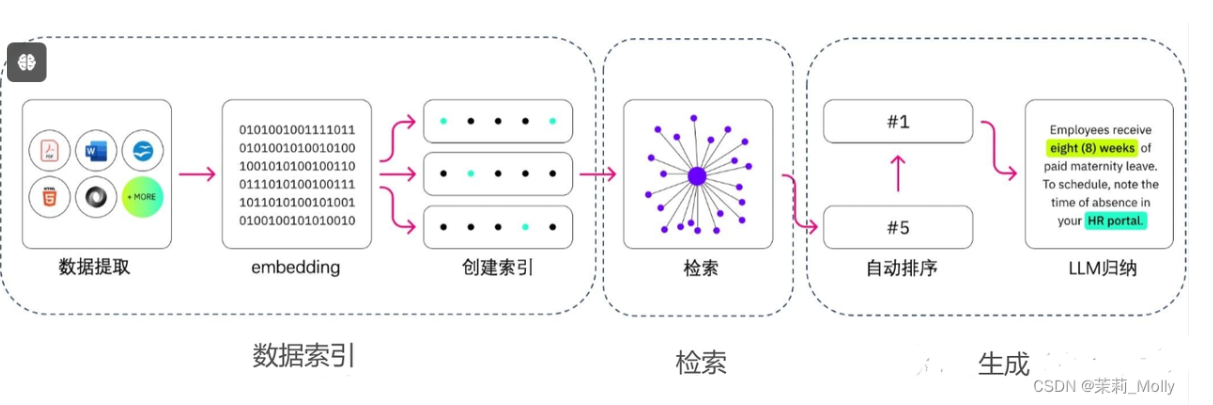
一种做法是,我们可以把文档切成若干段,只将少量的和问题有关的文档片段拿出来,放到大模型的输入里。至此,”大模型外挂数据库“的问题转换成了“文本检索的问题”了,目标是根据问题找出文档中和问题最相关的片段,这已经和大模型本身完全无关了。
文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化(通过语言模型,如bert等),然后存到向量数据库(如Annoy、 FAISS、hnswlib等)里边,来了一个问题之后,也对问题语句进行向量话,以余弦相似度或点积等指标,计算在向量数据库中和问题向量最相似的top k个文档片段,作为上文输入到大模型中。向量数据库都支持近似搜索功能,在牺牲向量检索准确度的情况下,提高检索速度。
3.对称语义检索与非对称语义检索
问题1:How to learn Python online?
答案1:How to learn Python on the web?
适用于非对称语义检索的例子:
问题2:What is Python?
答案2:*Python is an interpreted, high-level and general-purpose programming language. Python’s design philosophy …”
对称语义检索的“问题”和“答案”要求有差不多的意思,或者根本就不属于我们常规意义里的问答,而仅仅是同义句匹配。而非对称语义检索所做的任务才是我们常规意义下问答任务。很显然,通过向量检索的方式进行非对称语义检索的难度要大的多。对称语义检索的目标是找相似的句子,与向量检索基于计算向量相似度的原理天然匹配,只需要模型有比较强的内容抽象能力就可以。但是非对称语义检索则要求模型能够将问题和答案映射到同一空间
通过上述例子,可以看出向量检索只能检索出意思差不多的内容,下游用一个可以真正能很好理解语义的大模型进行进一步的提取检索出来的句子中的信息是十分有必要的。
模型是否支持非对称语义检索的根本原因是什么呢?是训练的数据不同
正是因为训练数据有真正的问答属性,模型才有真正的问答检索能力(将问题与答案映射到同一向量空间)。我的理解是,如果训练数据里没有某一领域的数据,比如金融领域,那么通用的非对称语义模型就不能很好的完成该领域的检索任务。但是对称语义检索有“泛化”到其他领域的能力,毕竟只需要理解“字面意思”。
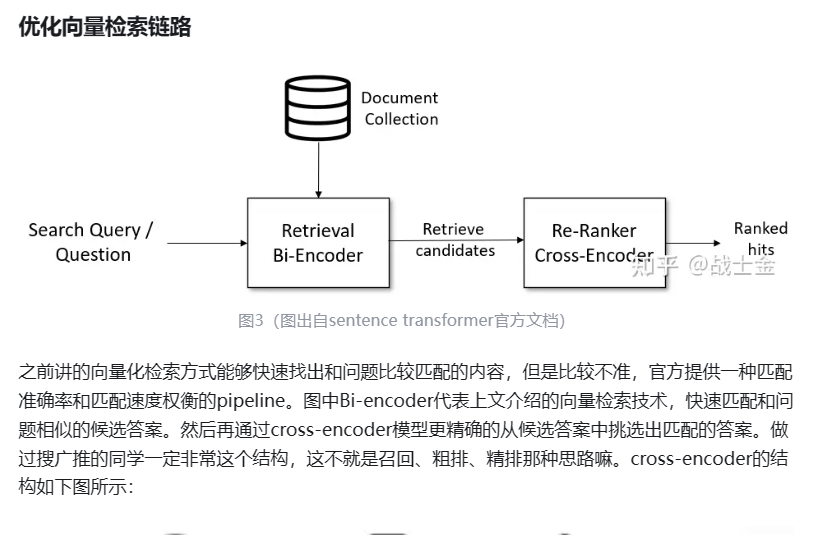
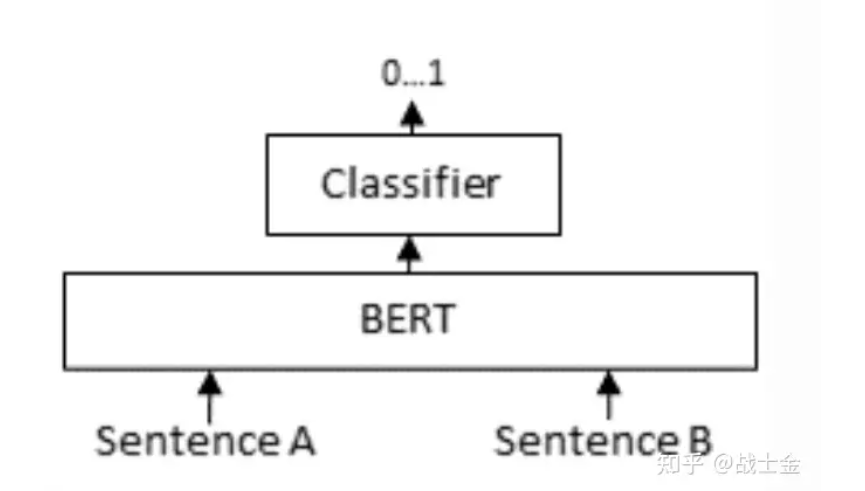
就直接把问题+答案拼在一起,做个二分类嘛。模型同时有了问题+答案这样一对的上下文信息,当然比直接分别将问题+答案映射到相同的向量空间、再计算相似度准的多了。但是这种计算向量相似度的模式会慢。假设有m个问题和n个答案,向量检索(图中的bi-encoder环节)只需要跑m+n次bert模型就够了,但是cross-encoder需要将所有问题和答案分别组合起来,跑m*n次bert模型。
4.如何协调查询和文档的语义空间?(上述问题的一个解决思路)
1.查询重写。
由于用户的查询可能表达不清晰或缺少必要的语义信息。因而可以使用大模型的能力生成一个指导性的伪文档,然后将原始查询与这个伪文档结合,形成一个新的查询。
也可以通过文本标识符来建立查询向量,利用这些标识符生成一个相关但可能并不存在的“假想”文档,它的目的是捕捉到相关的模式。
此外,多查询检索方法让大语言模型能够同时产生多个搜索查询。这些查询可以同时运行,它们的结果一起被处理,特别适用于那些需要多个小问题共同解决的复杂问题。
2.嵌入变换
在2023年提出的LLamaIndex中,研究者们通过在查询编码器后加入一个特殊的适配器,并对其进行微调,从而优化查询的嵌入表示,从而使之更适合特定的任务。
Li 团队在 2023 年提出的 SANTA 方法,就是为了让检索系统能够理解并处理结构化的信息。他们提出了两种预训练方法:一是利用结构化与非结构化数据之间的自然对应关系进行对比学习;二是采用了一种围绕实体设计的掩码策略,让语言模型来预测和填补这些被掩盖的实体信息。
5.基本步骤概括
1.将文档内容加载进来
2.由于文档很长,可能会超出模型所允许的token,因而对文档进行切割。
3.对文档进行向量化,变成计算机可以理解的形式。
4.对数据进行检索
在对数据进行检索时,可以首先进行一下元数据过滤,当索引分成许多的chunks时,检索效率会成为问题,通过元数据进行过滤,可以大大提升效率和相关度。
图关系检索:引入知识图谱,将实体变成node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。
检索技术
向量化(embedding)相似度检索:相似度计算方式包括欧氏距离、曼哈顿距离、余弦等;
关键词检索:这是很传统的检索方式,元数据过滤也是一种,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率;
全文检索:
SQL检索:更加传统的检索算法。
重排序(Rerank):相关度、匹配度等因素做一些重新调整,得到更符合业务场景的排序。
查询轮换:这是查询检索的一种方式,一般会有几种方式:
子查询:可以在不同的场景中使用各种查询策略,比如可以使用LlamaIndex等框架提供的查询器,采用树查询(从叶子结点,一步步查询,合并),采用向量查询,或者最原始的顺序查询chunks等;
HyDE:这是一种抄作业的方式,生成相似的或者更标准的 prompt 模板。
6.将原始query和检索得到的文本组合起来输入模型得到结果的过程,本质上就是个prompt enginering的过程。
6.现如今全流程的框架
Langchain和LLamaIndex
7.案例
1.chatPDF
2.Baichuan
3.Multi-modal retrieval-based LMs
8.存在的问题
1.检索效果依赖embedding和检索算法。目前可能检索到无关信息,反而对输出有负面影响。
2.大模型如何检索到的信息仍是黑盒。可能仍存在不准确(甚至生成的文本与检索信息相冲突)
3.对所有任务都无差别检索 k 个文本片段,效率不高,同时会大大增加模型输入的长度;
4.无法引用来源,也因此无法精准地查证事实,检索的真实性取决于数据源及检索算法。
9.RAG的评估方法
1.独立评估
独立评估涉及对检索模块和生成模块的评估
指标:
1.答案相关性
此指标的目标是评估生成的答案与提供的问题提示之间的相关性。答案如果缺乏完整性或者包含冗余信息,那么其得分将相对较低。这一指标通过问题和答案的结合来进行计算,评分的范围通常在0到1之间,其中高分代表更好的相关性。
2.忠实度
这个评价标准旨在检查生成的答案在给定上下文中的事实准确性。评估的过程涉及到答案内容与其检索到的上下文之间的比对。这一指标也使用一个介于0到1之间的数值来表示,其中更高的数值意味着答案与上下文的一致性更高。
3.上下文精确度
在这个指标中,我们评估所有在给定上下文中与基准信息相关的条目是否被正确地排序。理想情况下,所有相关的内容应该出现在排序的前部。这一评价标准同样使用0到1之间的得分值来表示,其中较高的得分反映了更高的精确度。
4.答案正确性
该指标主要用于测量生成的答案与实际基准答案之间的匹配程度。这一评估考虑了基准答案和生成答案的对比,其得分也通常在0到1之间,较高的得分表明生成答案与实际答案的一致性更高。
现如今的评估框架:
RGAGS、ARES
https://zhuanlan.zhihu.com/p/661867062)
案与实际基准答案之间的匹配程度**。这一评估考虑了基准答案和生成答案的对比,其得分也通常在0到1之间,较高的得分表明生成答案与实际答案的一致性更高。
现如今的评估框架:
RGAGS、ARES
https://zhuanlan.zhihu.com/p/661867062)



![[C#]使用OpenCvSharp图像滤波中值滤波均值滤波高通滤波双边滤波锐化滤波自定义滤波](https://img-blog.csdnimg.cn/direct/0182889615b0479cb66697ecbd8ea9be.png)