目录
🌊1. 研究目的
🌊2. 研究准备
🌊3. 研究内容
🌍3.1 softmax回归的简洁实现
🌍3.2 基础练习
🌊4. 研究体会
🌊1. 研究目的
- 理解softmax回归的原理和基本实现方式;
- 学习如何从零开始实现softmax回归,并了解其关键步骤;
- 通过简洁实现softmax回归,掌握使用现有深度学习框架的能力;
- 探索softmax回归在分类问题中的应用,并评估其性能。
🌊2. 研究准备
- 根据GPU安装pytorch版本实现GPU运行研究代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌊3. 研究内容
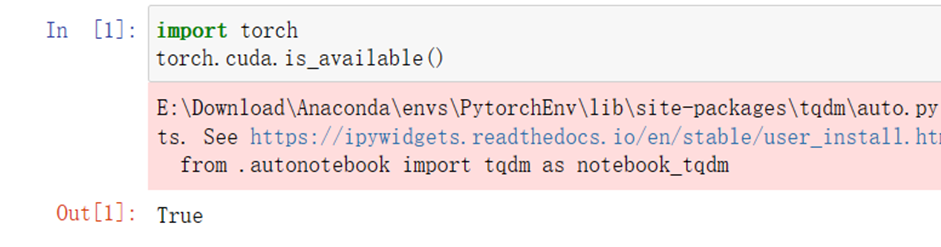
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明研究环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但研究运行是在CPU进行的,结果如下:
🌍3.1 softmax回归的简洁实现
完成softmax回归的简洁实现的研究代码及练习内容如下:
导入必要库及模型:
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)初始化模型参数
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
重新审视Softmax的实现
loss = nn.CrossEntropyLoss(reduction='mean') # 将reduction设置为'mean'或'sum'优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)训练
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
🌍3.2 基础练习
1.尝试调整超参数,例如批量大小、迭代周期数和学习率,并查看结果。
在这个示例中,我将批量大小调整为128,迭代周期数调整为20,学习率调整为0.01。
import torch
from torch import nn
from d2l import torch as d2l
# 超参数调整
batch_size = 128 # 调整批量大小
num_epochs = 20 # 调整迭代周期数
learning_rate = 0.01 # 调整学习率
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
net.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction='mean')
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
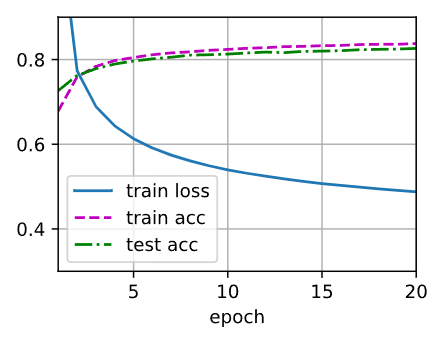
2.增加迭代周期的数量。为什么测试精度会在一段时间后降低?我们怎么解决这个问题?
当增加迭代周期的数量时,训练过程会继续进行更多的迭代,模型会有更多的机会学习训练数据中的模式和特征。通常情况下,增加迭代周期数量可以提高模型的训练精度。然而,如果过度训练,测试精度可能会在一段时间后开始降低。
这种情况被称为"过拟合"(overfitting)。过拟合发生时,模型在训练数据上表现得很好,但在新数据(测试数据)上表现较差。过拟合是由于模型过于复杂,过度记住了训练数据中的噪声和细节,而无法泛化到新数据。
为了解决过拟合问题,可以尝试以下几种方法:
- 提前停止(Early Stopping):在训练过程中,跟踪训练误差和测试误差。一旦测试误差开始上升,就停止训练。这样可以防止模型过度拟合训练数据。
- 正则化(Regularization):通过向损失函数添加正则化项,限制模型参数的大小,防止过度拟合。常见的正则化方法包括L1正则化和L2正则化。
- 数据增强(Data Augmentation):通过对训练数据进行随机变换(如旋转、翻转、缩放等),增加训练样本的多样性,有助于提高模型的泛化能力。
- 减小模型复杂度:减少模型的层数、节点数或参数量,使其更简单。简化模型可以降低过拟合的风险。
- 使用更多的训练数据:增加训练数据量可以减少过拟合的可能性,因为模型将有更多的样本进行学习。
通过组合使用这些方法,可以有效地解决过拟合问题并提高模型的泛化能力。
🌊4. 研究体会
通过这次研究,我深入学习了softmax回归模型,理解了它的原理和基本实现方式。开始了解softmax回归的背景和用途,它在多类别分类问题中的应用广泛;学习了如何从零开始实现softmax回归,并掌握了其中的关键步骤。
通过简洁实现softmax回归,更加熟悉了深度学习框架的使用。可以通过几行代码完成模型的定义、数据的加载和训练过程。还学会了使用框架提供的工具来评估模型的性能,如计算准确率和绘制混淆矩阵。这使能够更方便地对模型进行调试和优化,以获得更好的分类结果。
最后,通过实验探索了softmax回归在分类问题中的应用,并评估了其性能。使用了一些真实的数据集,如MNIST手写数字数据集,来进行实验。在实验中,将数据集划分为训练集和测试集,用训练集来训练模型,然后用测试集来评估模型的性能。
在从零开始实现的实验中,对模型的性能进行了一些调优,比如调整学习率和迭代次数。观察到随着迭代次数的增加,模型的训练损失逐渐下降,同时在测试集上的准确率也在提升。这证明了的模型在一定程度上学习到了数据的规律,并能够泛化到新的样本。而在简洁实现的实验中,由于深度学习框架的优化算法和自动求导功能,模型的训练速度明显快于从零开始实现。同时,框架提供了更多的网络结构和调优方法,使能够更加灵活地构建和调整模型。在简洁实现中,我还尝试了一些不同的模型结构,比如加入隐藏层或使用更复杂的优化算法,以探索更高效的模型设计。