目录
一、介绍
(1)解释算法
(2)数据集解释
二、算法实现和代码介绍
1.超平面
2.分类判别模型
3.点到超平面的距离
4.margin 间隔
5.拉格朗日乘数法KKT不等式
(1)介绍
(2)对偶问题
(3)惩罚参数
(4)求解
6.核函数解决非线性问题
7.SMO
(1)更新w
(2)更新b
三、代码解释及其运行结果截图
(1)svm(拉格朗日、梯度、核函数)
(2)测试集预测
(3)画出超平面
四、实验中遇到的问题
五、svm的优缺点
优点:
缺点:
六、实验中还需要改进的地方
七、总代码展现
一、介绍
(1)解释算法
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面 ------------百度百科
本实验采取的数据集依旧是鸢尾花数据集,实现的是二分类,为了使得数据可以在坐标轴上展示出来,实验中取的是鸢尾花数据集的setosa和versicolor类别。
支持向量机SVM的目标是找到一个能够将两类数据点分隔开的超平面,使得两侧距离最近的数据点到超平面的距离最大。这些最靠近超平面的数据点被称为支持向量。
(2)数据集解释
data = pd.read_csv(r"C:\\Users\\李烨\\Desktop\\ljhg.txt", sep=' ')
X_train = data.iloc[:, :2].values
y_train = np.where(data.iloc[:, -1].values == 'setosa', 1, -1)
test_data = pd.read_csv("C:\\Users\\李烨\\Desktop\\ljhgtest.txt", sep='\s+')
X_test = test_data[["Sepal.Length", "Sepal.Width"]].values采用鸢尾花数据集,为了可以在二维图上显示,所以我截取了部分数据,"Sepal.Length", "Sepal.Width"两列来表示横纵坐标,把setosa判断为正类1,把versicolor判断为负类-1
二、算法实现和代码介绍
1.超平面
两侧距离最近的数据点到超平面的距离最大。超平面被用来划分特征空间,以便实现对数据进行分类或回归。
在多分类实验中,是n元空间中,超平面就是一个n-1维的空间。 我们实现的是二分类,就得到的是一条直线。
给定样本数据集,假设样本特征为X,样本标签为y。其中y 的取值只能有+1和-1。表示样本正类和负类。
公式:
其中w代表每个特征前的系数,也就是超平面的法向量
2.分类判别模型
公式:
当f(w)>0时,判定为正类,否则判别为负类。
3.点到超平面的距离
得到样本点到超平面距离的公式:
在二维空间里面,也就是两个特征中,我们可以把超平面也就是直线的公式写成。
将一个点代入,这个点可能在直线的上方,直线上,和直线的下方。那么对于分类为正类1和负类-1,我们可以得到新的公式:
其中
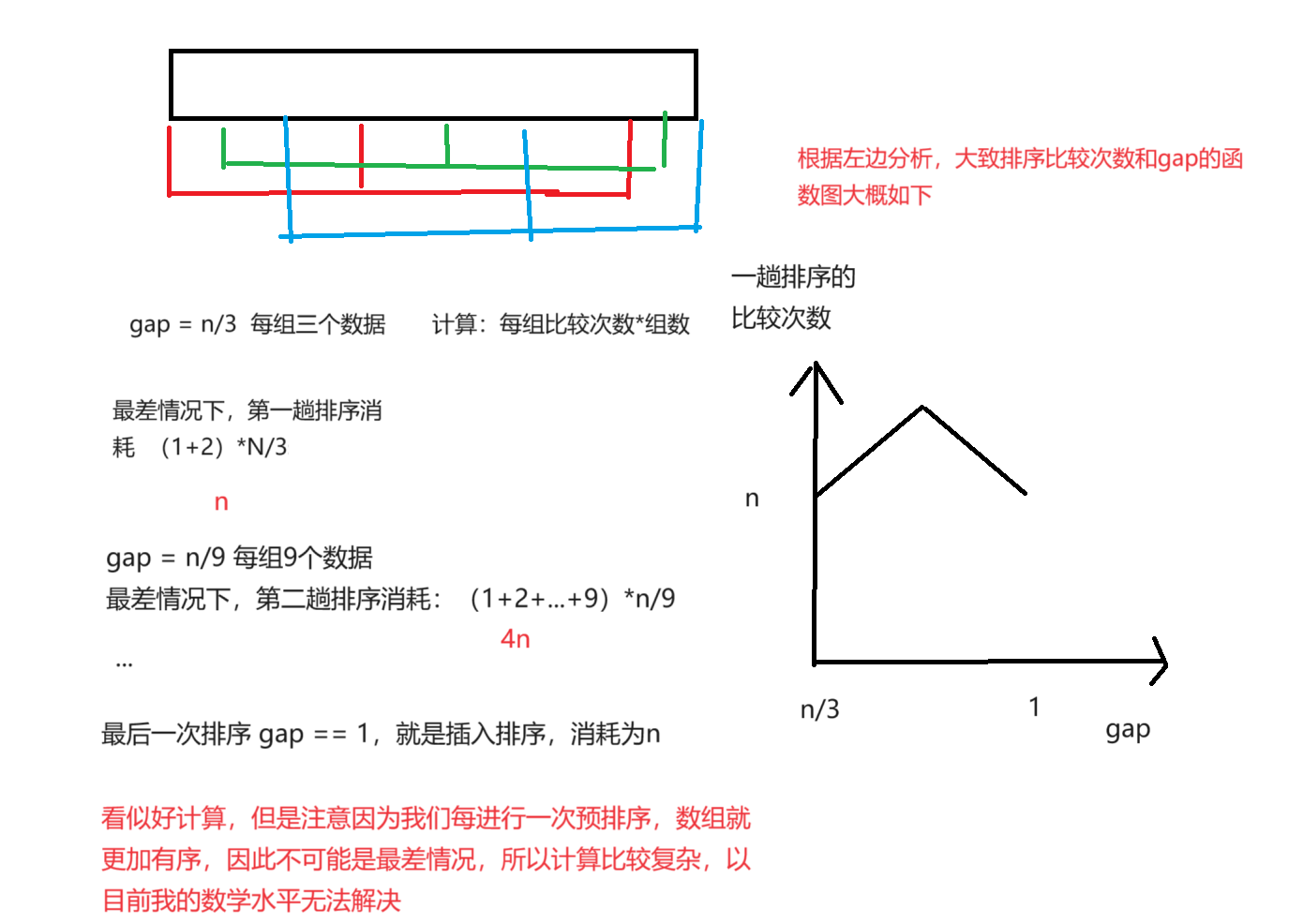
4.margin 间隔
从网上找了张图便于理解

支持向量:在支持向量机中起关键作用的训练数据点。在SVM中,超平面由这些支持向量确定,它们是离分隔超平面最近的那些点。
图中l1和l3直线的确定就是按照支持向量来确定的,查找正类和负类中距离超平面最近的点,找到超平面使得这个间隔最大,以此来确定超平面。
w,b都是未知参数,所以我们就将l1和l3等比例缩放
最后得到
那么这两条直线到超平面的距离就可以表示为
那我们就可以得到预测为正类的公式
负类的公式
合并后得到
我们确定超平面是为了分隔两个类别,所以需要找到超平面到支持向量的最大距离,也就是margin间隔。也就是求两条直线到超平面距离的最大值d,也就是求||w||的最大值,为了方便计算,也就是求的的最大值。
5.拉格朗日乘数法KKT不等式
(1)介绍
拉格朗日乘数法的主要是将有等式约束条件优化问题转换为无约束条件,求解带约束条件下的极值。因为拉格朗日是求解等式约束条件,而要求解带不等式约束条件下的求解,所以引入KKT不等式约束。
对于 求解
我们可以考虑加入alpha使得,这样就可以了利用拉格朗日乘数法得到
拉格朗日得到,求解该式子对应的极值。
对该式子求导得到
为了求解f(x)在s.t条件下的极值,我们先求得不在约束条件下的极值p,然后在约束条件下查找合适的x使得他尽可能的靠近极值点,也就是说alpha就没影响等式。那么就把问题转化为
(2)对偶问题
对于求解等效于 求解
当然这样交换是假设成立。情况分为强对偶和弱对偶
如果是弱对偶,因为是先求解最小值的x,就会使得求最大值是在小中选择较大的,那么。而如果等价的话,那么就是该交换成立。特别的是,在本实验中下凸满足Slater条件,所以对于所有下凸函数都是满足强对偶性。
(3)惩罚参数
我们可以预料到,数据中肯定存在一些点会影响到超平面的选择从而造成超平面的分类效果不理想,这时候就引入惩罚参数,当该点的误差超过一定界限的适合就舍弃该样本点。
(4)求解
最后求解极值就是用到和之前逻辑回归算法一样的梯度上升和梯度下降算法,这里就不多做介绍。
6.核函数解决非线性问题
用升维的方法来解决线性不可分的问题。
假设原始特征为x1,x2,x3,那么将这三个特征两两组合的得到:
在训练模型的适合将这些参与到训练模型中。
对于两个数据m和n,将m和n内积,然后平方得到
公式:
这个公式是多项式核函数,当时他的完整公式是
核函数有线性核函数、多项式核函数、高斯核函数等。
def polynomial_kernel(X, Y, degree=2):
return (np.dot(X, Y.T) ) ** degree7.SMO
在SMO算法中,需要解决的优化问题是一个凸二次规划问题,其目标是最小化关于拉格朗日乘子alpha的二次函数,同时满足一些约束条件,例如 KKT 条件。通过构建拉格朗日函数,然后应用SMO算法来迭代优化,最终得到最优的 alpha 和 b
(1)更新w
选择两个样本i和j来进行更新,更新步长的计算与核函数的值以及拉格朗日乘子都有关系。
公式:
这个步长有正有负。当为正数的时候意味着在更新拉格朗日乘子时,朝着梯度方向移动一个较小的步长。为负数,则可能表示算法中的错误,需要检查和调整。
(2)更新b
当时 b=b1;
当时b=b2;
否则
当然a和b的更新,这边学习的仅仅只是其中的一种。
三、代码解释及其运行结果截图
(1)svm(拉格朗日、梯度、核函数)
def svm_fit(X, y, C, kernel, degree=2, alpha=0.001, num=1000):
n_samples, n_features = X.shape
w = np.zeros(n_samples)
b = 0
kernel_matrix = kernel(X, X, degree)
for _ in range(num):
for idx, x_i in enumerate(X):
E_i = np.sum(w * y * kernel_matrix[idx]) + b - y[idx]
if ((y[idx] * E_i < -alpha and w[idx] < C) or (y[idx] * E_i > alpha and w[idx] > 0)):
j = np.random.choice(np.delete(np.arange(n_samples), idx))
E_j = np.sum(w * y * kernel_matrix[j]) + b - y[j]
w_i_old, w_j_old = w[idx], w[j]
if (y[idx] != y[j]):
L = max(0, w[j] - w[idx])
H = min(C, C + w[j] - w[idx])
else:
L = max(0, w[idx] + w[j] - C)
H = min(C, w[idx] + w[j])
if L == H:
continue
eta = 2 * kernel_matrix[idx, j] - kernel_matrix[idx, idx] - kernel_matrix[j, j]
if eta >= 0:
continue
w[j] = w[j] - (y[j] * (E_i - E_j)) / eta
w[j] = max(L, min(H, w[j]))
if abs(w[j] - w_j_old) < 1e-5:
continue
w[idx] = w[idx] + y[idx] * y[j] * (w_j_old - w[j])
b1 = b - E_i - y[idx] * (w[idx] - w_i_old) * kernel_matrix[idx, idx] - y[j] * (
w[j] - w_j_old) * kernel_matrix[idx, j]
b2 = b - E_j - y[idx] * (w[idx] - w_i_old) * kernel_matrix[idx, j] - y[j] * (
w[j] - w_j_old) * kernel_matrix[j, j]
if 0 < w[idx] < C:
b = b1
elif 0 < w[j] < C:
b = b2
else:
b = (b1 + b2) / 2
return w, b- C是惩罚参数, kernel是代表的核函数, degree是核函数的阶数, alpha是梯度的步长, num是迭代次数。用E_i来表示的是第i个样本的预测误差,也就是样本的核函数对应的数据到超平面的距离减去该样本的分类之和。
- if ((y[idx] * E_i < -alpha and w[idx] < C) or (y[idx] * E_i > alpha and w[idx] > 0))是来判断这个是否要更新参数,如果误差太大,那么就说明w[idx]的值不合适,就需要更新他。
- 先从数据中再次随机选取一个数据,判断y[idx] != y[j],对w[j]进行约束在一定范围内,使得在满足约束条件的同时,能够使得目标函数在更新后有下降较快,可以更节省时间。
- 如果约束到一个点上面,就无法继续优化了,如果没有,二阶导数判断一下更新的方向。if eta >= 0说明图像是下凸的,跳过再次更新,为负数就需要进行整改。
- 对w进行更新,但是w应该在一定范围内。如果w[j]的改变量很小,就认为他对w[idx]的更新没有贡献,跳过。
- 根据smo更新b的方式对b进行更新。
(2)测试集预测
def predict(w, b, X_train, y_train, X_test, kernel, degree=2):
predictions = []
for x in X_test:
prediction = b
for i, x_i in enumerate(X_train):
prediction += w[i] * y_train[i] * kernel(x_i, x, degree)
predictions.append(np.sign(prediction))
return predictions对于测试集中的数据,将他们与训练集中的数据核函数,再根据得到的值为正数和负数分类到正类和负类。
运行结果:
可以看到对于二分类的结果还是较为准确的。

(3)画出超平面
def plot_decision_boundary(X, y, w, b, kernel, degree=2):
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1), np.arange(x2_min, x2_max, 0.1))
Z = predict(w, b, X, y, np.c_[xx1.ravel(), xx2.ravel()], kernel, degree)
Z = np.array(Z).reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, marker='o', edgecolors='k')因为超平面中用到了核函数,所以超平面的公式就和样本数量有关,得到的公式就不再是可以像逻辑回归一样直接表示出来,需要最坐标轴上面的点用核函数表示 代入到公式中得到预测值。
这个代码是参考了网上的代码,以坐标轴的形式,把坐标轴上的点用核函数的公式拿去预测,那么他就得到了整张坐标轴上的分类。超平面就是两个分类交叉的地方。
运行结果:

四、实验中遇到的问题
- 实验中遇到的最主要的问题就是对w和b的更新上,因为和逻辑回归一点像,就没有真正理解算法,对w和b的选取和更新是都花了较大的时间来理解SMO的算法,SMO算法有许多给定的公式来更新w和b,核函数和拉格朗日乘子法KKT不等式等都是利用公式求解,公式较多较为复杂,重点就在对这些公式的掌握和理解上面。
- 实验中的另一个问题就是对于惩罚参数的选取上,由于刚开始看到的并没有添加惩罚参数,所以导致超平面受到的影响较大,受到个别点的影响,导致拟合效果非常不好,而且由于是利用梯度求解,所以就会导致超平面因为拟合效果不好。如图。超平面并不能很好的划分。

3.超平面的画法上面,最开始是想直接将点表示出来,但是发现用核函数得到的超平面公式与样本点的数量有关系,在画超平面的时候仍然需要对他进行核函数求解,所以在预测的时候加上核函数就可以了。
五、svm的优缺点
优点:
逻辑回归主要是处理线性问题,与之相比,支持向量机可以处理许多非线性的问题,SVM 找到最大间隔超平面,这意味着它试图最大化类别之间的间隔,拟合效果会更好。在高维空间中svm支持向量机的适应效果回归更好。
缺点:
支持向量机svm的优化问题通常是凸优化问题,它的计算复杂度随着样本数量和特征维度的增加而增加。在处理大规模数据和高维数据时,训练时间和内存时间复杂度很大。
六、实验中还需要改进的地方
- 与逻辑回归一样,使用的是普通梯度,而随机梯度上升在每次迭代中只需要计算一个样本数据的梯度,因此通常比梯度上升更快。我们可以利用随机梯度来减小时间复杂度。
- 由于对SMO算法的不熟悉,所以我的实验中用到的是最简单的SMO,复杂度高,程序预测效果没那么好,使用更加完整成熟的SMO算法可以有效改进拟合效果。
七、总代码展现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def polynomial_kernel(X, Y, degree=2):
return (np.dot(X, Y.T) ) ** degree
def svm_fit(X, y, C, kernel, degree=2, alpha=0.001, num=1000):
n_samples, n_features = X.shape
w = np.zeros(n_samples)
b = 0
kernel_matrix = kernel(X, X, degree)
for _ in range(num):
for idx, x_i in enumerate(X):
E_i = np.sum(w * y * kernel_matrix[idx]) + b - y[idx]
if ((y[idx] * E_i < -alpha and w[idx] < C) or (y[idx] * E_i > alpha and w[idx] > 0)):
j = np.random.choice(np.delete(np.arange(n_samples), idx))
E_j = np.sum(w * y * kernel_matrix[j]) + b - y[j]
w_i_old, w_j_old = w[idx], w[j]
if (y[idx] != y[j]):
L = max(0, w[j] - w[idx])
H = min(C, C + w[j] - w[idx])
else:
L = max(0, w[idx] + w[j] - C)
H = min(C, w[idx] + w[j])
if L == H:
continue
eta = 2 * kernel_matrix[idx, j] - kernel_matrix[idx, idx] - kernel_matrix[j, j]
if eta >= 0:
continue
w[j] = w[j] - (y[j] * (E_i - E_j)) / eta
w[j] = max(L, min(H, w[j]))
if abs(w[j] - w_j_old) < 1e-5:
continue
w[idx] = w[idx] + y[idx] * y[j] * (w_j_old - w[j])
b1 = b - E_i - y[idx] * (w[idx] - w_i_old) * kernel_matrix[idx, idx] - y[j] * (
w[j] - w_j_old) * kernel_matrix[idx, j]
b2 = b - E_j - y[idx] * (w[idx] - w_i_old) * kernel_matrix[idx, j] - y[j] * (
w[j] - w_j_old) * kernel_matrix[j, j]
if 0 < w[idx] < C:
b = b1
elif 0 < w[j] < C:
b = b2
else:
b = (b1 + b2) / 2
return w, b
def predict(w, b, X_train, y_train, X_test, kernel, degree=2):
predictions = []
for x in X_test:
prediction = b
for i, x_i in enumerate(X_train):
prediction += w[i] * y_train[i] * kernel(x_i, x, degree)
predictions.append(np.sign(prediction))
return predictions
def plot_decision_boundary(X, y, w, b, kernel, degree=2):
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1), np.arange(x2_min, x2_max, 0.1))
Z = predict(w, b, X, y, np.c_[xx1.ravel(), xx2.ravel()], kernel, degree)
Z = np.array(Z).reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, marker='o', edgecolors='k')
data = pd.read_csv(r"C:\\Users\\李烨\\Desktop\\ljhg.txt", sep=' ')
X_train = data.iloc[:, :2].values
y_train = np.where(data.iloc[:, -1].values == 'setosa', 1, -1)
test_data = pd.read_csv("C:\\Users\\李烨\\Desktop\\ljhgtest.txt", sep='\s+')
X_test = test_data[["Sepal.Length", "Sepal.Width"]].values
y_test = test_data[["Species"]].values;
C = 1.0
degree = 2
tol = 0.001
max_iter = 1000
w, b = svm_fit(X_train, y_train, C, polynomial_kernel, degree, tol, max_iter)
predictions = predict(w, b, X_train, y_train, X_test, polynomial_kernel, degree)
cnt=0.0
for i, prediction in enumerate(predictions):
if prediction == 1:
ans='setosa'
else :
ans='versicolor'
print(f"第{i}个数据{X_test[i]}预测结果为{ans},实际结果为{y_test[i]}")
if ans==y_test[i]:
cnt+=1
print(f"准确率为{cnt/len(predictions)}")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10, 6))
plot_decision_boundary(X_train, y_train, w, b, polynomial_kernel, degree)
plt.title('SVM支持向量机')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.show()




![[职场] 为什么不能加薪? #学习方法#知识分享#微信](https://img-blog.csdnimg.cn/img_convert/820a0d9b09b98027e0b1179614121b97.png)