文章目录
- 环境
- 加载数据
- 归一化数据
- 训练模型
- 用测试数据集给出评估指标
- 准确率召回率
- 预测某个输入数据
- 随便取一行数据
- 加载训练好的SVM支持向量机模型并预测
- 全部数据和代码下载
环境
之前介绍过用深度学习做入侵检测,这篇用向量机。
环境Python3.10
requirements.txt
训练代码:
x01_train_model_no_pca.py
会得到一些模型文件和图像。
多类别预测中的混淆矩阵讲解:
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.confusion_matrix.html
加载数据
# 加载数据
file_path_train = "./data/NSL_KDD-master/KDDTrain+.csv"
file_path_test = "./data/NSL_KDD-master/KDDTest+.csv"
train_data = pd.read_csv(file_path_train, header=None)
test_data = pd.read_csv(file_path_test, header=None)
data_columns = ["duration", "protocol_type", "service", "flag", "src_bytes",
"dst_bytes", "land_f", "wrong_fragment", "urgent", "hot", "num_failed_logins",
"logged_in", "num_compromised", "root_shell", "su_attempted", "num_root",
"num_file_creations", "num_shells", "num_access_files", "num_outbound_cmds",
"is_host_login", "is_guest_login", "count", "srv_count", "serror_rate",
"srv_serror_rate", "rerror_rate", "srv_rerror_rate", "same_srv_rate",
"diff_srv_rate", "srv_diff_host_rate", "dst_host_count", "dst_host_srv_count",
"dst_host_same_srv_rate", "dst_host_diff_srv_rate", "dst_host_same_src_port_rate",
"dst_host_srv_diff_host_rate", "dst_host_serror_rate", "dst_host_srv_serror_rate",
"dst_host_rerror_rate", "dst_host_srv_rerror_rate", "labels", "difficulty"]
归一化数据
# 归一化数据
scaler = StandardScaler()
normalized_data = scaler.fit_transform(merged_data)
训练模型
ckpt = './model/x01_NO_PCA_IDS_model.m'
if not os.path.exists(ckpt):
svc = SVC(kernel='rbf', class_weight='balanced', C=0.5)
start = time.time()
clf = svc.fit(x_train, y_train)
print('对降维后的数据进行训练用时为{0}'.format(time.time() - start))
# 保存模型
joblib.dump(clf, ckpt)
print('模型保存成功')
else:
clf = joblib.load(ckpt)
score = clf.score(x_val, y_val)
print('x_val y_val精度为%s' % score)
用测试数据集给出评估指标
# 一、对 NSL-KDD-test_set 进行模型评估
test_labels_src = label_encoder_labels.inverse_transform(test_labels)
y_pred_src = label_encoder_labels.inverse_transform(y_pred)
evaluate_and_draw_pic(test_labels_src, y_pred_src, list(type2id.keys()),
'all_class_mutil_class_no_pca_confusion_matrix')
# 二、映射为五个类别进行评估
test_labels_five = np.array([type2id[label] for label in test_labels_src])
y_pred_five = np.array([type2id[label] for label in y_pred_src])
evaluate_and_draw_pic(test_labels_five, y_pred_five, ['normal', 'dos', 'r2l', 'u2r', 'probe'],
'five_class_mutil_class_no_pca_confusion_matrix')
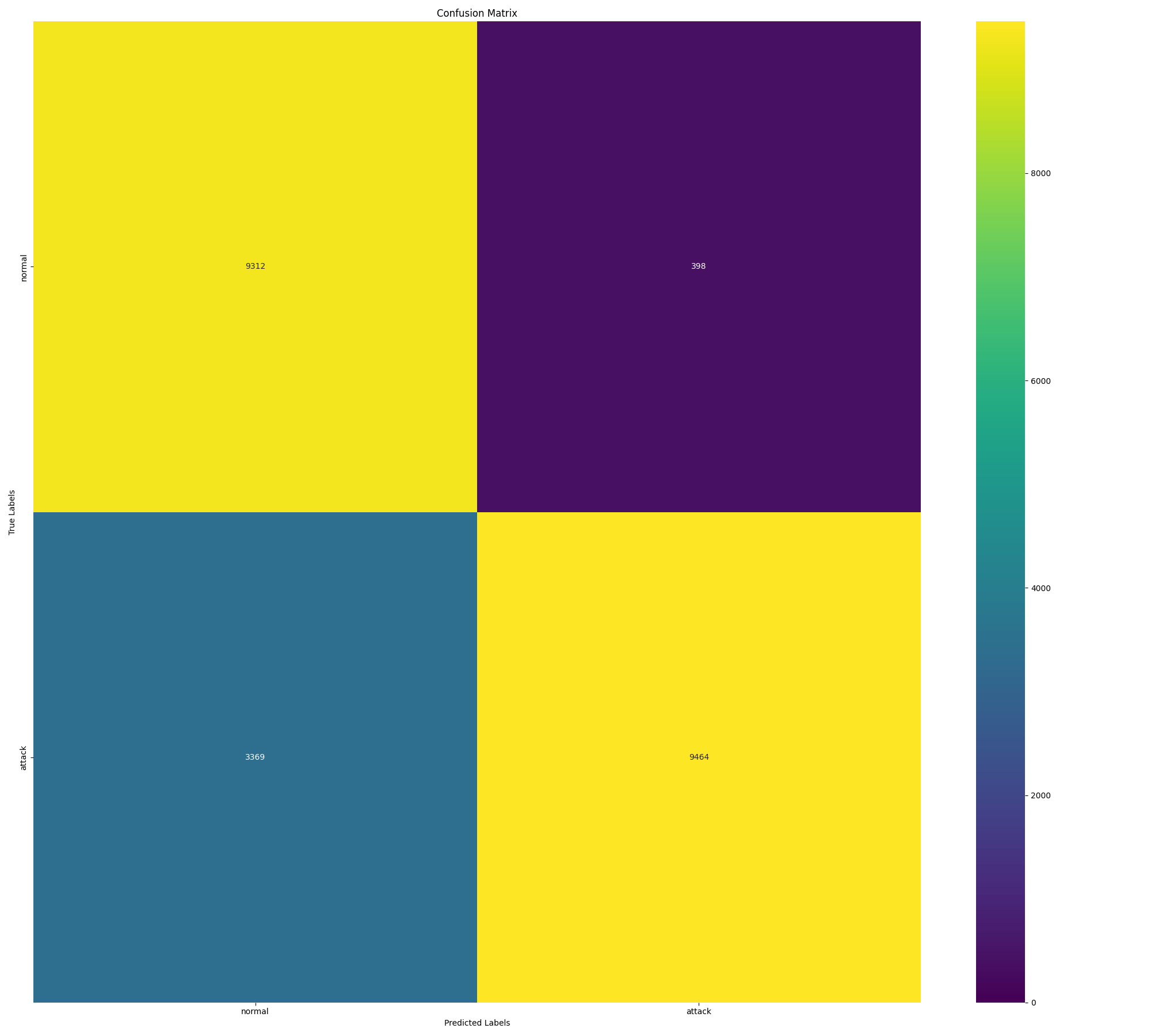
# 三、映射为两个类别进行评估
test_labels_binary = np.array(['normal' if label == 'normal' else 'attack' for label in test_labels_src])
y_pred_binary = np.array(['normal' if label == 'normal' else 'attack' for label in y_pred_src])
evaluate_and_draw_pic(test_labels_binary, y_pred_binary, ['normal', 'attack'],
'binary_class_mutil_class_no_pca_confusion_matrix')
五个类别的混淆矩阵:

两个类别的混淆矩阵:
准确率召回率
==============================
five_class_mutil_class_no_pca_confusion_matrix
Macro-average Precision: 0.6487499999999999
Macro-average Recall: 0.60625
==============================
binary_class_mutil_class_no_pca_confusion_matrix
Macro-average Precision: 0.8460000000000001
Macro-average Recall: 0.842
预测某个输入数据
随便取一行数据
# 加载数据
file_path_train = "./data/NSL_KDD-master/KDDTrain+.csv"
data_columns = ["duration", "protocol_type", "service", "flag", "src_bytes",
"dst_bytes", "land_f", "wrong_fragment", "urgent", "hot", "num_failed_logins",
"logged_in", "num_compromised", "root_shell", "su_attempted", "num_root",
"num_file_creations", "num_shells", "num_access_files", "num_outbound_cmds",
"is_host_login", "is_guest_login", "count", "srv_count", "serror_rate",
"srv_serror_rate", "rerror_rate", "srv_rerror_rate", "same_srv_rate",
"diff_srv_rate", "srv_diff_host_rate", "dst_host_count", "dst_host_srv_count",
"dst_host_same_srv_rate", "dst_host_diff_srv_rate", "dst_host_same_src_port_rate",
"dst_host_srv_diff_host_rate", "dst_host_serror_rate", "dst_host_srv_serror_rate",
"dst_host_rerror_rate", "dst_host_srv_rerror_rate", "labels", "difficulty"]
# 读取第一行的数据,用普通文件读取
with open(file_path_train, 'r') as f:
lines = f.read().splitlines()
first_line = lines[2]
print("原始数据", first_line)
加载训练好的SVM支持向量机模型并预测
# 加载模型
ckpt = './model/x01_NO_PCA_IDS_model.m'
clf = joblib.load(ckpt)
# 预测
y_pred = clf.predict(normalized_data)
print("预测结果是", y_pred)
# 结果标签转换为字符串
y_pred_src = label_encoder_labels.inverse_transform(y_pred)
print("预测结果转换为字符串是", y_pred_src)
日志:
原始数据 0,tcp,private,S0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,123,6,1,1,0,0,0.05,0.07,0,255,26,0.1,0.05,0,0,1,1,0,0,neptune,19
预测结果是 [14]
预测结果转换为字符串是 [‘neptune’]
可见预测准确。
全部数据和代码下载
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2