公众号:尤而小屋
编辑:Peter
作者:Peter
大家好,我是Peter~
继续更新机器学习扩展包MLxtend的文章。本文介绍如何使用MLxtend来绘制与分类模型相关的决策边界decision_regions。
导入库
导入相关用于数据处理和建模的库:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from matplotlib import cm
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import itertools
from sklearn import datasets
from sklearn.linear_model import LogisticRegression # 逻辑回归分类
from sklearn.svm import SVC # SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林分类
from mlxtend.classifier import EnsembleVoteClassifier # 从mlxtend导入集成投票表决分类算法
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions # 绘制决策边界
import warnings
warnings.filterwarnings('ignore')
1维决策边界(Decision regions in 1D)
X,y = iris_data()
X[:3] # names = ['sepal length', 'sepal width','petal length', 'petal width']
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2]])
X = X[:,2] # 只取第二个特征
# X = X[:,None] # 转成2维数组;下同
X = X.reshape(-1,1)
X[:5]
array([[1.4],
[1.4],
[1.3],
[1.5],
[1.4]])
建立模型:
svm = SVC(C=0.5,kernel="linear")
svm.fit(X,y)
绘制决策边界图形:
plot_decision_regions(X,y,clf=svm,legend=2)
plt.xlabel("sepal width")
plt.title("SVM on Iris Datasets based on 1D")
plt.show()

2维决策边界(Decision regions in 2D)
X,y = iris_data()
X = X[:,:2] # 选择两个特征用于建模和可视化
X[:10]
输出结果为:
array([[5.1, 3.5],
[4.9, 3. ],
[4.7, 3.2],
[4.6, 3.1],
[5. , 3.6],
[5.4, 3.9],
[4.6, 3.4],
[5. , 3.4],
[4.4, 2.9],
[4.9, 3.1]])
建立模型:
svm = SVC(C=0.5,kernel="linear")
svm.fit(X,y)
绘制决策边界图形:
plot_decision_regions(X,y,clf=svm,legend=2)
plt.xlabel("sepal length")
plt.ylabel("sepal width")
plt.title("SVM on Iris Datasets based on 2D")
plt.show()

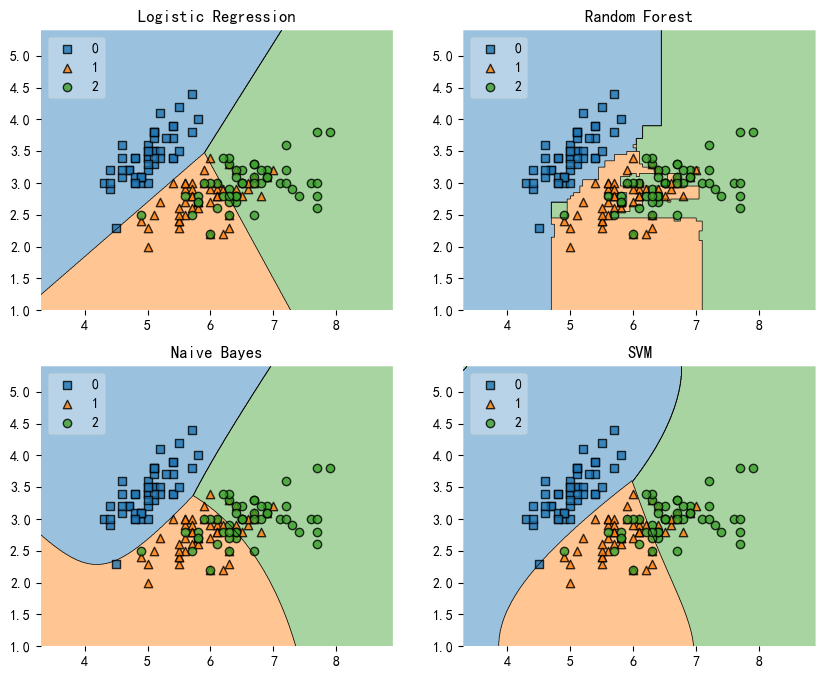
多模型决策边界(Decision Region Grids)
# 导入4个分类模型
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import itertools
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions
4个模型的初始化:
clf1 = LogisticRegression(random_state=1,solver='newton-cg',multi_class='multinomial')
clf2 = RandomForestClassifier(random_state=1, n_estimators=100)
clf3 = GaussianNB()
clf4 = SVC(gamma='auto')
导入数据集:
X,y = iris_data()
X = X[:,:2] # 选择2个特征建模
4个模型的迭代训练与可视化:
gs = gridspec.GridSpec(2,2) # 2*2的网格面
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'SVM']
for clf,lab,grd in zip([clf1, clf2, clf3, clf4],
labels,
itertools.product([0,1], repeat=2)):
clf.fit(X,y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()
高亮测试数据集Highlighting test data
from mlxtend.plotting import plot_decision_regions
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
导入数据集并切分:
X,y = iris_data()
X = X[:,:2] # 选择前2个特征建模
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
模型训练:
svm =SVC(C=0.5, kernel="linear")
svm.fit(X_train, y_train)
plot_decision_regions(X,
y,
clf=svm,
legend=2,
X_highlight=X_test
)
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.title('SVM on Iris with Highlighting Test Data Points')
plt.show()

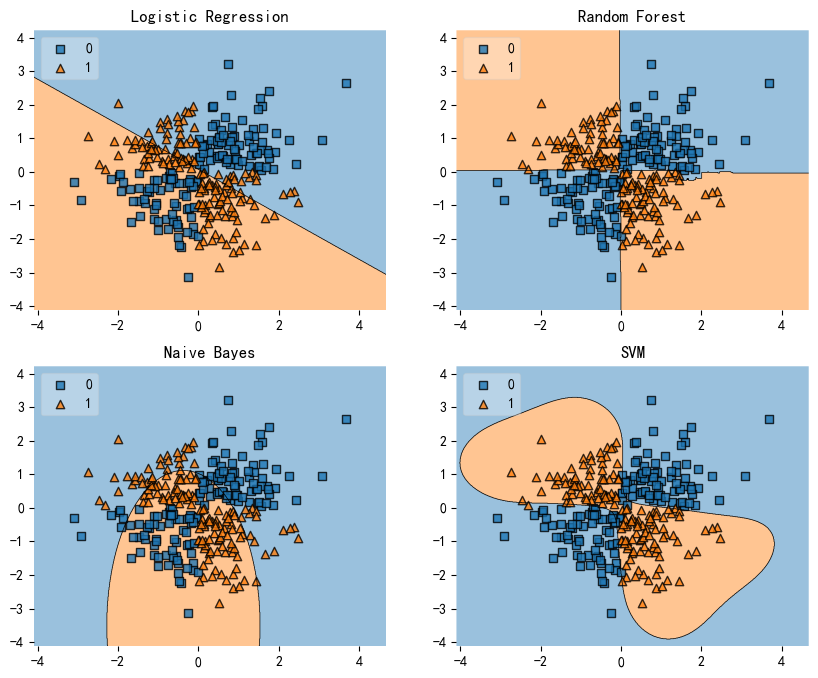
评估分类器在非线性问题的表现Evaluating Classifier Behavior on Non-Linear Problems
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from mlxtend.plotting import plot_decision_regions
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# 定义4个模型
clf1 = LogisticRegression(random_state=1, solver='lbfgs')
clf2 = RandomForestClassifier(n_estimators=100, random_state=1)
clf3 = GaussianNB()
clf4 = SVC(gamma='auto')
XOR问题
X = np.random.randn(300, 2) # 300*2;符合正态分布的数组
X[:5]
array([[-1.96399101, -0.13610581],
[-1.4832503 , -0.01927823],
[-2.32101114, 0.09310347],
[ 1.85377755, 0.08739847],
[-1.26535948, 0.75706403]])
# np.logical_xor用于计算两个布尔数组之间的逐元素逻辑异或。当两个输入数组中的元素相同,为False;当不同时,结果为True。
y = np.array(np.logical_xor(X[:, 0] > 0, X[:, 1] > 0), # 两个特征的是否都大于0;使用异或的结果
dtype=int)
y[:10] # 0-表示False,1-表示True
array([0, 0, 1, 0, 1, 1, 1, 0, 1, 0])
gs = gridspec.GridSpec(2, 2) # 创建2*2的网格布局
fig = plt.figure(figsize=(10,8)) # 图像大小
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'SVM'] # 模型名称
for clf, lab, grd in zip([clf1, clf2, clf3, clf4], # 模型clf + 名称lab + 位置grd(00,01,10,11)
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X, y) # 模型拟合
ax = plt.subplot(gs[grd[0], grd[1]]) # grd[0]-row grd[1]-column
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2) # 绘制决策边界
plt.title(lab) # 模型名称
plt.show()
半月数据集的分类Half-Moons
make_moons是Scikit-learn库中的一个函数,用于生成具有两个弯月形状的数据集。它通常用于测试分类算法在非线性可分数据上的性能。
该函数的基本用法如下:
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
其中,n_samples参数指定生成的数据点数量,noise参数指定数据的噪声水平(0表示无噪声,越大表示噪声越多),random_state参数用于设置随机数生成器的种子以确保结果的可重复性。
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, random_state=123) # 生成弯月数据集
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'SVM']
for clf, lab, grd in zip([clf1, clf2, clf3, clf4],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()

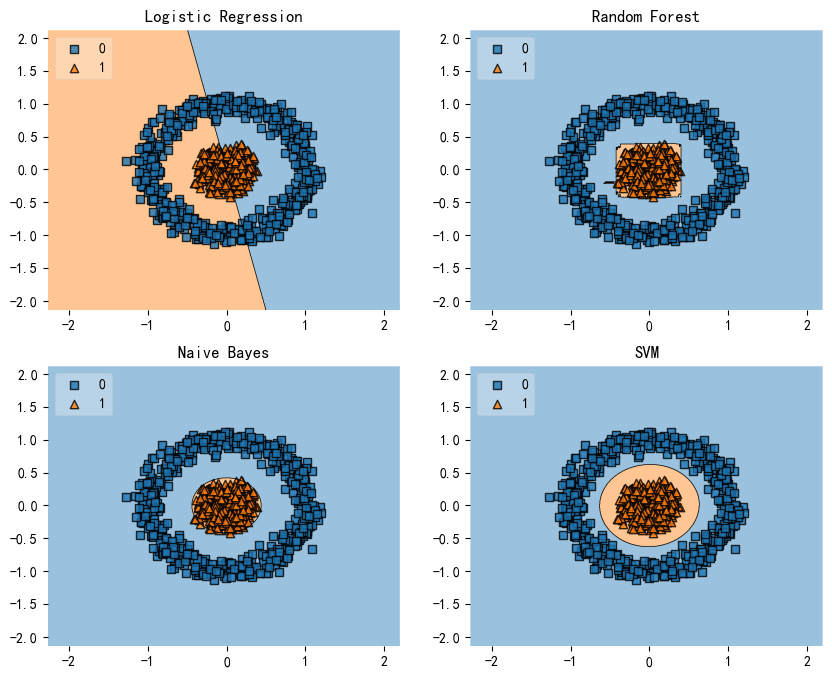
同心圆数据的分类Concentric Circles
from sklearn.datasets import make_circles
# 生成同心圆数据集
X, y = make_circles(n_samples=1000, random_state=123, noise=0.1, factor=0.2)
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'SVM']
for clf, lab, grd in zip([clf1, clf2, clf3, clf4],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()
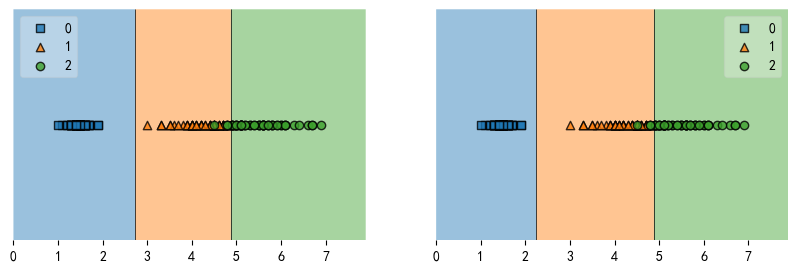
基于子图的分类决策边界
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
from mlxtend.data import iris_data # 内置数据集
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn import datasets
import numpy as np
X,y = iris_data()
X = X[:,2]
X = np.array(X).reshape(-1,1)
建立两个模型并训练:
clf1 = LogisticRegression(
random_state=1,
solver='lbfgs',
multi_class='multinomial')
clf2 = GaussianNB()
clf1.fit(X, y)
clf2.fit(X, y)
创建图形对象fig和ax绘图对象:
fig, axes = plt.subplots(1,2,figsize=(10,3)) # 创建1*2的图形
fig = plot_decision_regions(X=X, y=y, clf=clf1, ax=axes[0], legend=2)
fig = plot_decision_regions(X=X, y=y, clf=clf2, ax=axes[1], legend=1)
plt.show()
基于多特征的决策边界
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
X, y = datasets.make_blobs(
n_samples=600, # 样本数
n_features=3, # 特征数
centers=[[2, 2, -2],[-2, -2, 2]], # 聚类中心
cluster_std=[2, 2], # 聚类方差
random_state=2 # 随机种子
)
建立SVM模型并训练:
svm = SVC(gamma="auto")
svm.fit(X,y)
fig, ax = plt.subplots()
value = 1.5
width = 0.75
plot_decision_regions(
X,
y,
clf=svm,
# Filler values must be provided when X has more than 2 training features.
# 多个特征该参数必须有
filler_feature_values={2: value},
filler_feature_ranges={2: width},
legend=2,
ax=ax
)
ax.set_xlabel("Feature1")
ax.set_ylabel("Feature2")
ax.set_title("Feature3={}".format(value))
fig.suptitle("SVM on make_blobs")
plt.show()
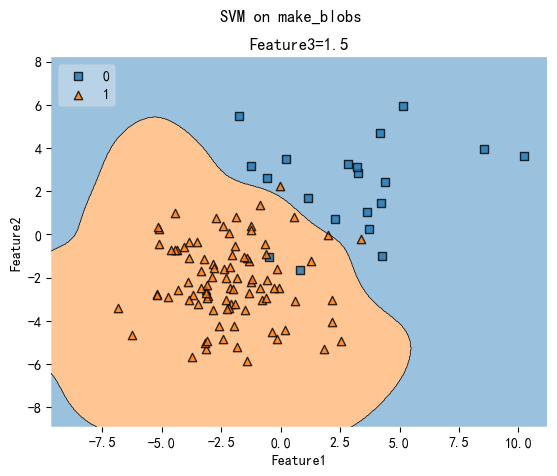
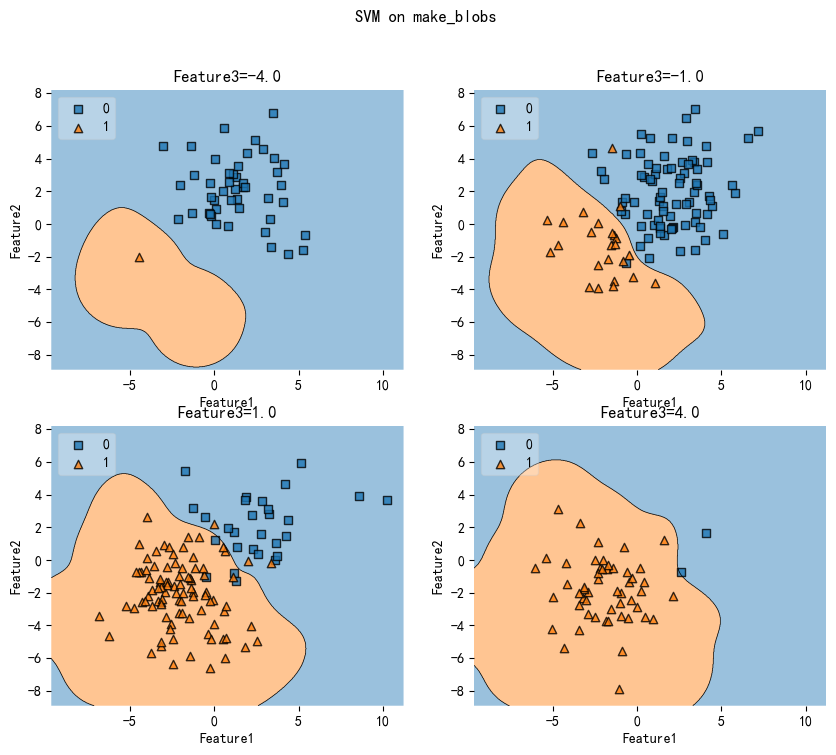
决策边界的网格切片
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
X, y = datasets.make_blobs(
n_samples=600, # 样本数
n_features=3, # 特征数
centers=[[2, 2, -2],[-2, -2, 2]], # 聚类中心
cluster_std=[2, 2], # 聚类方差
random_state=2 # 随机种子
)
# 模型训练
svm = SVC(gamma="auto")
svm.fit(X,y)
fig, axarr = plt.subplots(2, 2, figsize=(10,8), sharex=True, sharey=True)
values = [-4.0, -1.0, 1.0, 4.0]
width = 0.75
for value, ax in zip(values, axarr.flat):
plot_decision_regions(X,
y,
clf=svm,
filler_feature_values={2: value},
filler_feature_ranges={2: width},
legend=2,
ax=ax)
ax.set_xlabel("Feature1")
ax.set_ylabel("Feature2")
ax.set_title("Feature3={}".format(value))
fig.suptitle('SVM on make_blobs')
plt.show()
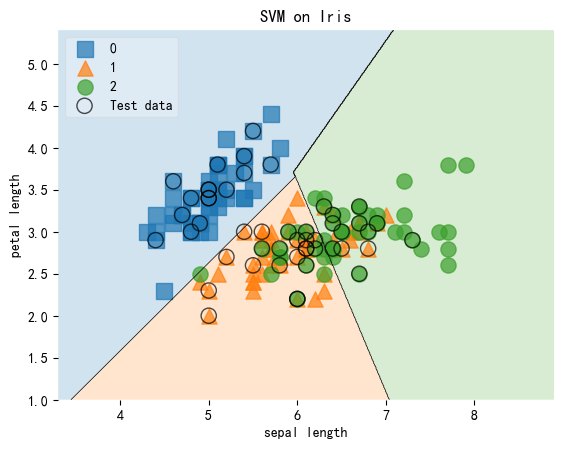
自定义绘图风格
from mlxtend.plotting import plot_decision_regions
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# 导入和切分数据
X,y = iris_data()
X = X[:,:2] # 选择前2个特征建模
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
建立模型和训练:
svm = SVC(C=0.5, kernel='linear')
svm.fit(X_train, y_train)
自定义绘图风格:
scatter_kwargs = {'s': 120, 'edgecolor': None, 'alpha': 0.7}
contourf_kwargs = {'alpha': 0.2}
scatter_highlight_kwargs = {'s': 120, 'label': 'Test data', 'alpha': 0.7}
# 绘制决策边界
plot_decision_regions(X,
y,
clf=svm,
legend=2,
X_highlight=X_test, # 高亮数据
scatter_kwargs=scatter_kwargs,
contourf_kwargs=contourf_kwargs,
scatter_highlight_kwargs=scatter_highlight_kwargs)
# 添加坐标轴标注
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.title('SVM on Iris')
plt.show()
自定义图例legend
from mlxtend.plotting import plot_decision_regions
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# 导入和切分数据
X,y = iris_data()
X = X[:,:2] # 选择前2个特征建模
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
svm = SVC(C=0.5, kernel='linear')
svm.fit(X_train, y_train)
修改图例:
ax = plot_decision_regions(X,y,clf=svm, legend=0)
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.title('SVM on Iris')
# 自定义图例
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles,
['class square','class triangle','class circle'],
framealpha=0.3,
scatterpoints=1)
plt.show()

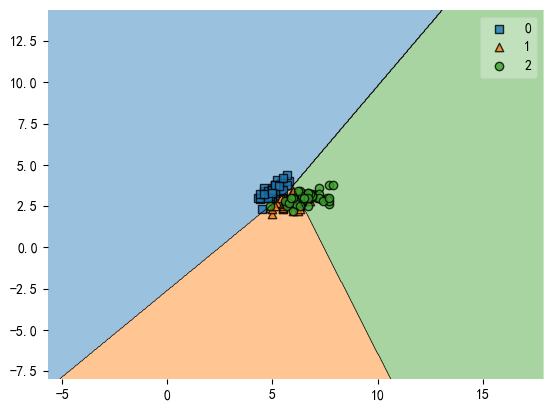
基于缩放因子的决策边界可视化zoom factors
from mlxtend.plotting import plot_decision_regions
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
X,y = iris_data()
X = X[:,:2]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
svm = SVC(C=0.5, kernel='linear')
svm.fit(X_train, y_train)
1、默认的缩放因子zoom_factor=1.0:
plot_decision_regions(X, y, clf=svm, zoom_factor=1.)
plt.show()

2、使用不同的缩放因子:
plot_decision_regions(X, y, clf=svm, zoom_factor=0.1)
plt.show()
plot_decision_regions(X, y, clf=svm, zoom_factor=2)
plt.xlim(5, 6)
plt.ylim(2, 5)
plt.show()

使用Onehot编码输出的分类器onehot-encoded outputs (Keras)
定义了一个名为Onehot2Int的类,该类用于将模型预测的one-hot编码结果转换为整数
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(123)
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from mlxtend.data import iris_data
from mlxtend.preprocessing import standardize
from mlxtend.plotting import plot_decision_regions
class Onehot2Int(object):
# 参数为model;表示需要转换预测结果的模型
def __init__(self, model):
self.model = model
# X表示输入
def predict(self, X):
y_pred = self.model.predict(X) # 预测
return np.argmax(y_pred, axis=1) # 找到每行中最大值的索引,即one-hot编码中1的位置,返回这些索引组成的数组
数据预处理:
X, y = iris_data()
X = X[:, [2, 3]]
X = standardize(X) # 标准化
y_onehot = to_categorical(y) # 独热编码
建立网络模型:
model = Sequential()
model.add(Dense(8,
input_shape=(2,),
activation='relu',
kernel_initializer='he_uniform'))
model.add(Dense(4,
activation='relu',
kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
模型编译和训练:
model.compile(loss="categorical_crossentropy",
optimizer=keras.optimizers.Adam(lr=0.005),
metrics=['accuracy'])
history = model.fit(X,
y_onehot,
epochs=10,
batch_size=5,
verbose=1,
validation_split=0.1)
Epoch 1/10
27/27 [==============================] - 0s 7ms/step - loss: 0.9506 - accuracy: 0.6074 - val_loss: 1.0899 - val_accuracy: 0.0000e+00
Epoch 2/10
27/27 [==============================] - 0s 2ms/step - loss: 0.7453 - accuracy: 0.6963 - val_loss: 1.0886 - val_accuracy: 0.0000e+00
Epoch 3/10
27/27 [==============================] - 0s 1ms/step - loss: 0.6098 - accuracy: 0.7185 - val_loss: 1.0572 - val_accuracy: 0.0000e+00
Epoch 4/10
27/27 [==============================] - 0s 2ms/step - loss: 0.5159 - accuracy: 0.7333 - val_loss: 1.0118 - val_accuracy: 0.0000e+00
Epoch 5/10
27/27 [==============================] - 0s 1ms/step - loss: 0.4379 - accuracy: 0.7630 - val_loss: 0.9585 - val_accuracy: 0.8000
Epoch 6/10
27/27 [==============================] - 0s 2ms/step - loss: 0.3784 - accuracy: 0.8815 - val_loss: 0.8806 - val_accuracy: 0.9333
Epoch 7/10
27/27 [==============================] - 0s 1ms/step - loss: 0.3378 - accuracy: 0.9407 - val_loss: 0.8155 - val_accuracy: 1.0000
Epoch 8/10
27/27 [==============================] - 0s 2ms/step - loss: 0.3130 - accuracy: 0.9481 - val_loss: 0.7535 - val_accuracy: 1.0000
Epoch 9/10
27/27 [==============================] - 0s 2ms/step - loss: 0.2893 - accuracy: 0.9259 - val_loss: 0.6859 - val_accuracy: 1.0000
Epoch 10/10
27/27 [==============================] - 0s 2ms/step - loss: 0.2695 - accuracy: 0.9481 - val_loss: 0.6258 - val_accuracy: 1.0000
model_no_ohe = Onehot2Int(model) # 将现有模型转成one-hot处理后的模型
# 绘制决策边界
plot_decision_regions(X, y, clf=model_no_ohe)
plt.show()
9600/9600 [==============================] - 5s 555us/step










![[word] word文档字体间距怎么调整? #其他#经验分享](https://img-blog.csdnimg.cn/img_convert/477be82f32c3c3d5a3578ddcc8226fc2.jpeg)