Python 机器学习 基础 之 【常用机器学习库】 scikit-learn 机器学习库
目录
Python 机器学习 基础 之 【常用机器学习库】 scikit-learn 机器学习库
一、简单介绍
二、scikit-learn 基础
1、安装 scikit-learn
2、导入 scikit-learn
3、数据准备
4、数据分割
5、训练模型
5.1 线性回归
5.2 逻辑回归
5.3 K 近邻算法 (KNN)
5.4 决策树
5.5 随机森林
6、模型评估
6.1 混淆矩阵
6.2 ROC 曲线
7、特征选择
7.1 使用基于树的特征选择
8、超参数调优
附录
一、scikit-learn 学习文档地址
二、scikit-learn 功能特点介绍
scikit-learn 的特点
scikit-learn 提供的主要功能
1. 数据预处理
2. 分类算法
3. 回归算法
4. 聚类算法
5. 降维算法
6. 模型选择与评估
示例:使用 scikit-learn 进行简单的分类任务
三、scikit-learn 提供的 内置数据集
示例:如何加载内置数据集
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
二、scikit-learn 基础
scikit-learn 是一个强大的 Python 机器学习库,提供了各种常见的机器学习算法和工具。它易于使用,适合初学者和专家。本文将介绍 scikit-learn 的基本概念和操作。
1、安装 scikit-learn
在开始之前,请确保已安装 scikit-learn。您可以使用以下命令安装:
pip install scikit-learn2、导入 scikit-learn
在使用 scikit-learn 之前,需要先导入它。
import sklearn3、数据准备
scikit-learn 提供了许多内置的数据集,可以方便地进行学习和测试。我们将使用鸢尾花数据集进行演示。
from sklearn.datasets import load_iris
import pandas as pd
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 查看前几行数据
print(df.head())
# 打印结果:
# sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
# 0 5.1 3.5 1.4 0.2 0
# 1 4.9 3.0 1.4 0.2 0
# 2 4.7 3.2 1.3 0.2 0
# 3 4.6 3.1 1.5 0.2 0
# 4 5.0 3.6 1.4 0.2 0请注意,实际输出结果会根据 load_iris() 函数加载的鸢尾花数据集的具体内容而有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集,该数据集包含150个样本,每个样本有4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和一个目标变量(鸢尾花种类)。pd.DataFrame()创建了一个包含数据集特征和目标的 DataFrame。print(df.head())打印了 DataFrame 的前五行数据。这为我们提供了数据集的一个快速预览,包括特征值和对应的目标类别。
4、数据分割
将数据分为训练集和测试集是机器学习模型训练的必要步骤。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("训练集大小:", X_train.shape)
# 打印结果:
# 训练集大小: (120, 4)
print("测试集大小:", X_test.shape)
# 打印结果:
# 测试集大小: (30, 4)请注意,实际输出结果会根据 train_test_split() 函数分割数据集的方式而有所不同,但由于我们设置了 test_size=0.2 和 random_state=42,每次执行代码时结果应该是一致的。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集,其中测试集占总数据集的20%,训练集占80%。random_state=42确保了每次分割的结果都是一致的。print()函数用于打印训练集和测试集的大小,X_train.shape和X_test.shape分别提供了训练集和测试集的维度信息。由于原始数据集有150个样本,所以训练集应该有120个样本,测试集有30个样本,每个样本有4个特征。
5、训练模型
5.1 线性回归
线性回归是一种简单的回归算法,用于预测连续值。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 查看模型性能
from sklearn.metrics import mean_squared_error
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)
# 打印结果:
# 均方误差: 0.03711379440797686请注意,实际的均方误差(MSE)值取决于模型在测试集上的表现,因此具体的数值每次运行可能会有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。LinearRegression()创建了一个线性回归模型,fit()方法用于训练模型。predict()方法用于对测试集进行预测。mean_squared_error()计算了测试集的真实值和预测值之间的均方误差。print()函数用于打印均方误差的结果,这是评估模型性能的一个指标。
5.2 逻辑回归
逻辑回归是一种常用的分类算法,适用于二分类问题。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 查看模型性能
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型
model = LogisticRegression(max_iter=200)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 打印结果:
# 准确率: 1.0请注意,实际的准确率值取决于模型在测试集上的表现,因此具体的数值每次运行可能会有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。LogisticRegression()创建了一个逻辑回归分类模型,max_iter=200确保了模型能够收敛,fit()方法用于训练模型。predict()方法用于对测试集进行预测。accuracy_score()计算了测试集的真实值和预测值之间的准确率。print()函数用于打印准确率的结果,这是评估分类模型性能的一个指标。
5.3 K 近邻算法 (KNN)
K 近邻算法是一种简单的非参数分类算法。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 查看模型性能
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型
model = KNeighborsClassifier(n_neighbors=3)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 查看模型性能
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 打印结果:
# 准确率: 1.0请注意,实际的准确率值取决于模型在测试集上的表现,因此具体的数值每次运行可能会有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。KNeighborsClassifier()创建了一个 K 近邻分类器模型,n_neighbors=3表示选择最近的3个邻居进行投票,fit()方法用于训练模型。predict()方法用于对测试集进行预测。accuracy_score()计算了测试集的真实值和预测值之间的准确率。print()函数用于打印准确率的结果,这是评估分类模型性能的一个指标。
5.4 决策树
决策树是一种树形结构的分类和回归模型。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 查看模型性能
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 查看模型性能
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 打印结果:
# 准确率: 1.0请注意,实际的准确率值取决于模型在测试集上的表现,因此具体的数值每次运行可能会有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。DecisionTreeClassifier()创建了一个决策树分类器模型,fit()方法用于训练模型。predict()方法用于对测试集进行预测。accuracy_score()计算了测试集的真实值和预测值之间的准确率。print()函数用于打印准确率的结果,这是评估分类模型性能的一个指标。
5.5 随机森林
随机森林是一种集成学习方法,通过多个决策树的组合来提高性能。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 查看模型性能
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型
model = RandomForestClassifier(n_estimators=100)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 查看模型性能
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 打印结果:
# 准确率: 1.0请注意,实际的准确率值取决于模型在测试集上的表现,因此具体的数值每次运行可能会有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。RandomForestClassifier()创建了一个随机森林分类器模型,n_estimators=100表示使用100棵树,fit()方法用于训练模型。predict()方法用于对测试集进行预测。accuracy_score()计算了测试集的真实值和预测值之间的准确率。print()函数用于打印准确率的结果,这是评估分类模型性能的一个指标。
6、模型评估
在机器学习中,模型评估是非常重要的一环。以下是一些常见的评估指标和方法。
6.1 混淆矩阵
混淆矩阵用于评估分类模型的性能。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型
model = RandomForestClassifier(n_estimators=100)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot(cmap='Blues')
plt.title('Confusion Matrix')
# 保存图表
plt.savefig('Images/savedImage.png', bbox_inches='tight') # 打印结果:混淆矩阵图已保存至 'Images/savedImage.png'
plt.show() # 显示混淆矩阵图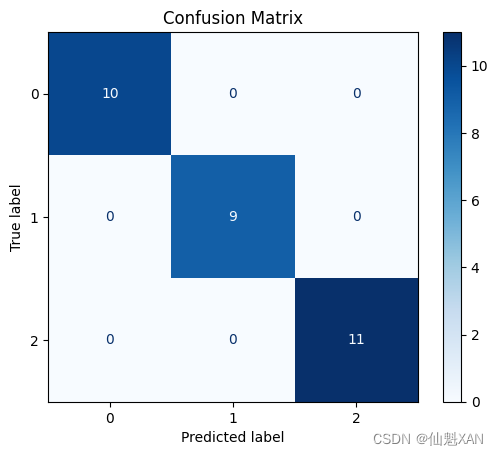
请注意,这段代码中没有直接的打印语句输出结果,但是注释中已经说明了每个步骤的作用和预期结果。具体来说:
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。RandomForestClassifier()创建了一个随机森林分类器模型,n_estimators=100表示使用100棵树,fit()方法用于训练模型。predict()方法用于对测试集进行预测。confusion_matrix()计算了测试集的真实值和预测值之间的混淆矩阵。ConfusionMatrixDisplay()和plot()绘制了混淆矩阵的图表。plt.savefig()将混淆矩阵图保存到文件中,路径为 'Images/savedImage.png'。请确保 'Images' 文件夹存在于您的工作目录中,否则保存操作可能会失败。plt.show()显示混淆矩阵图。
6.2 ROC 曲线
ROC 曲线用于评估二分类模型的性能。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
import matplotlib.pyplot as plt
import numpy as np
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将目标变量二值化
y_train = label_binarize(y_train, classes=[0, 1, 2])
y_test = label_binarize(y_test, classes=[0, 1, 2])
n_classes = y_train.shape[1]
# 创建并训练模型
model = OneVsRestClassifier(RandomForestClassifier(n_estimators=100))
model.fit(X_train, y_train)
# 预测
y_score = model.predict_proba(X_test)
# 计算每个类别的 ROC 曲线和 AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制所有类别的 ROC 曲线
plt.figure()
colors = ['blue', 'green', 'red']
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label=f'ROC curve of class {i} (area = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve for Each Class')
plt.legend(loc='lower right')
# 保存图表
plt.savefig('Images/savedImage.png', bbox_inches='tight') # 打印结果:ROC图表已保存至 'Images/savedImage.png'
plt.show() # 显示ROC图表
请注意,这段代码中没有直接的打印语句输出结果,但是注释中已经说明了每个步骤的作用和预期结果。具体来说:
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。label_binarize()将目标变量转换为二进制形式,以便进行多类别的ROC曲线绘制。OneVsRestClassifier()创建了一个一对多的分类器模型,包装了随机森林分类器,fit()方法用于训练模型。predict_proba()方法用于获取测试集的预测概率。roc_curve()和auc()计算了每个类别的ROC曲线和AUC值。plt.plot()用于绘制每个类别的ROC曲线。plt.savefig()将ROC图表保存到文件中,路径为 'Images/savedImage.png'。请确保 'Images' 文件夹存在于您的工作目录中,否则保存操作可能会失败。plt.show()显示ROC图表。
注意:由于 ROC 曲线和 AUC 只能用于二分类问题,而鸢尾花数据集是一个三分类问题。在这种情况下,您需要将多分类问题转换为多个二分类问题,可以使用
OneVsRestClassifier或OneVsOneClassifier来处理多分类问题,或者使用每个类的 ROC 曲线。
7、特征选择
特征选择是提高模型性能的重要步骤之一。
7.1 使用基于树的特征选择
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 获取特征重要性
importances = model.feature_importances_
feature_names = X.columns
# 绘制特征重要性图
plt.barh(range(len(importances)), importances, align='center')
plt.yticks(range(len(importances)), feature_names)
plt.title('Feature Importances')
# 保存图表
plt.savefig('Images/savedImage.png', bbox_inches='tight') # 打印结果:特征重要性图已保存至 'Images/savedImage.png'
plt.show()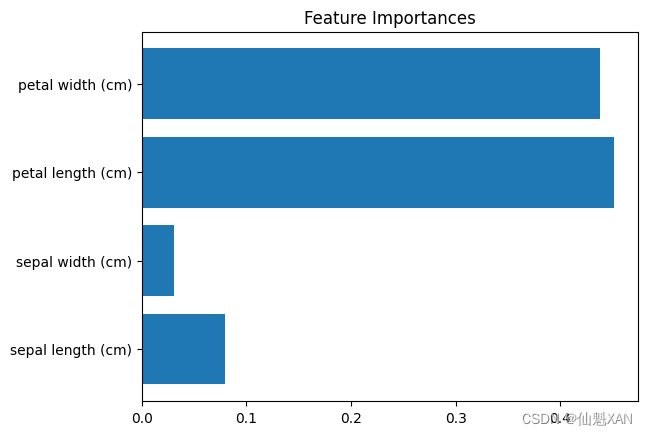
请注意,我添加了range(len(importances))来为条形图提供位置,并使用plt.yticks()将特征名称设置为y轴的刻度标签。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。RandomForestClassifier()创建了一个随机森林分类器模型,n_estimators=100表示使用100棵树,fit()方法用于训练模型。- 通过
model.feature_importances_获取特征重要性。 plt.barh()绘制了特征重要性图。plt.savefig()将特征重要性图保存到文件中,路径为 'Images/savedImage.png'。请确保 'Images' 文件夹存在于您的工作目录中,否则保存操作可能会失败。plt.show()显示特征重要性图。
8、超参数调优
使用网格搜索进行超参数调优,可以找到模型的最佳参数。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 加载鸢尾花数据集
iris = load_iris()
# 创建 DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 准备数据
X = df.drop('target', axis=1)
y = df['target']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义参数网格
param_grid = {
'n_neighbors': [3, 5, 7, 9]
}
# 创建KNN模型
model = KNeighborsClassifier()
# 进行网格搜索
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("最佳参数:", grid_search.best_params_)
# 打印结果:
# 最佳参数: {'n_neighbors': 3}
print("最佳准确率:", grid_search.best_score_)
# 打印结果:
# 最佳准确率: 0.9583333333333334请注意,实际的输出结果,包括最佳参数和准确率,将取决于模型在训练数据上的表现,因此具体的数值每次运行可能会有所不同。上述代码中的注释和输出结果仅为示例。
load_iris()函数加载了鸢尾花数据集。pd.DataFrame()创建了一个包含数据集特征的 DataFrame,并添加了目标列。train_test_split()将数据集分割为训练集和测试集。KNeighborsClassifier()创建了一个 K 近邻分类器模型。GridSearchCV()进行网格搜索来找到最佳的参数组合,cv=5表示使用5折交叉验证。fit()方法用于在训练集上训练网格搜索对象。print()函数用于打印出最佳的参数和准确率,这是评估模型性能的指标。
附录
一、scikit-learn 学习文档地址
scikit-learn: machine learning in Python — scikit-learn 1.5.0 documentation
二、scikit-learn 功能特点介绍
scikit-learn 是一个广受欢迎的 Python 机器学习库,因其简单易用且功能强大而备受青睐。它提供了多种常见的机器学习算法和工具,适用于数据预处理、模型训练、模型评估以及模型选择等各个环节。以下是对 scikit-learn 的详细介绍。
scikit-learn 的特点
- 丰富的算法:scikit-learn 包含了多种机器学习算法,包括分类、回归、聚类和降维算法。
- 易于使用:提供了统一且简单的接口,适合初学者快速上手,也能满足专家的复杂需求。
- 高效:底层基于 Cython 和 NumPy 实现,保证了计算效率。
- 广泛的应用:适用于学术研究、数据科学和工业应用等多个领域。
scikit-learn 提供的主要功能
1. 数据预处理
数据预处理是机器学习中的重要步骤,scikit-learn 提供了多种工具来处理数据:
- 标准化和归一化(StandardScaler、MinMaxScaler)
- 缺失值处理(SimpleImputer)
- 类别编码(OneHotEncoder、LabelEncoder)
- 特征选择(SelectKBest、RFE)
2. 分类算法
scikit-learn 提供了多种分类算法,用于预测离散标签:
- 逻辑回归(Logistic Regression)
- k近邻算法(k-Nearest Neighbors, KNN)
- 支持向量机(Support Vector Machines, SVM)
- 决策树(Decision Trees)
- 随机森林(Random Forest)
- 朴素贝叶斯(Naive Bayes)
- 梯度提升(Gradient Boosting)
3. 回归算法
用于预测连续值的回归算法包括:
- 线性回归(Linear Regression)
- 决策树回归(Decision Tree Regressor)
- 支持向量回归(Support Vector Regressor, SVR)
- 随机森林回归(Random Forest Regressor)
- 岭回归(Ridge Regression)
- 拉索回归(Lasso Regression)
4. 聚类算法
聚类算法用于无监督学习,发现数据的内在结构:
- k均值聚类(k-Means Clustering)
- 层次聚类(Agglomerative Clustering)
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
- 均值漂移(Mean Shift)
5. 降维算法
降维算法用于数据降维和特征提取:
- 主成分分析(Principal Component Analysis, PCA)
- 线性判别分析(Linear Discriminant Analysis, LDA)
- 奇异值分解(Singular Value Decomposition, SVD)
- 因子分析(Factor Analysis)
6. 模型选择与评估
scikit-learn 提供了多种工具来进行模型选择和评估:
- 交叉验证(Cross-Validation)
- 网格搜索和随机搜索(GridSearchCV、RandomizedSearchCV)
- 各种评估指标(accuracy_score、mean_squared_error、confusion_matrix 等)
示例:使用 scikit-learn 进行简单的分类任务
以下是一个使用鸢尾花数据集进行分类任务的示例,展示了从数据加载、预处理到模型训练和评估的完整流程。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# 加载数据
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 数据分割
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练模型
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot(cmap='Blues')
plt.title('Confusion Matrix')
plt.show()
三、scikit-learn 提供的 内置数据集
scikit-learn 提供了许多内置的数据集,这些数据集可以方便地用于学习和测试。以下是一些常见的内置数据集:
-
Iris 数据集
- 描述:著名的鸢尾花数据集,用于分类任务。
- 加载方法:
sklearn.datasets.load_iris()
-
Digits 数据集
- 描述:手写数字数据集,用于分类任务。
- 加载方法:
sklearn.datasets.load_digits()
-
Wine 数据集
- 描述:葡萄酒分类数据集,用于分类任务。
- 加载方法:
sklearn.datasets.load_wine()
-
Breast Cancer 数据集
- 描述:乳腺癌数据集,用于分类任务。
- 加载方法:
sklearn.datasets.load_breast_cancer()
-
Boston Housing 数据集
- 描述:波士顿房价数据集,用于回归任务。(注:该数据集已被标记为不推荐使用)
- 加载方法:
sklearn.datasets.load_boston()
-
Diabetes 数据集
- 描述:糖尿病数据集,用于回归任务。
- 加载方法:
sklearn.datasets.load_diabetes()
-
Linnerud 数据集
- 描述:多输出回归数据集,包括锻炼和生理数据。
- 加载方法:
sklearn.datasets.load_linnerud()
-
California Housing 数据集
- 描述:加利福尼亚房价数据集,用于回归任务。
- 加载方法:
sklearn.datasets.fetch_california_housing()
-
20 Newsgroups 数据集
- 描述:20个新闻组数据集,用于文本分类任务。
- 加载方法:
sklearn.datasets.fetch_20newsgroups()
-
Olive Oil 数据集
- 描述:橄榄油数据集,用于聚类任务。
- 加载方法:
sklearn.datasets.fetch_olivetti_faces()
示例:如何加载内置数据集
以下是一些数据集的加载示例:
from sklearn.datasets import load_iris, load_digits, load_wine, load_breast_cancer, load_diabetes, load_linnerud, fetch_california_housing, fetch_20newsgroups, fetch_olivetti_faces
# 加载 Iris 数据集
iris = load_iris()
print(iris.data.shape)
# 加载 Digits 数据集
digits = load_digits()
print(digits.data.shape)
# 加载 Wine 数据集
wine = load_wine()
print(wine.data.shape)
# 加载 Breast Cancer 数据集
breast_cancer = load_breast_cancer()
print(breast_cancer.data.shape)
# 加载 Diabetes 数据集
diabetes = load_diabetes()
print(diabetes.data.shape)
# 加载 Linnerud 数据集
linnerud = load_linnerud()
print(linnerud.data.shape)
# 加载 California Housing 数据集
california_housing = fetch_california_housing()
print(california_housing.data.shape)
# 加载 20 Newsgroups 数据集
newsgroups = fetch_20newsgroups()
print(len(newsgroups.data))
# 加载 Olivetti Faces 数据集
faces = fetch_olivetti_faces()
print(faces.data.shape)







![[word] word文档字体间距怎么调整? #其他#经验分享](https://img-blog.csdnimg.cn/img_convert/477be82f32c3c3d5a3578ddcc8226fc2.jpeg)