文章目录
- 一、背景
- 二、方法
- 2.1 Square-10M
- 2.2 模型结构
- 2.3 使用 Square-10M 进行有监督微调
- 三、效果
- 3.1 实验设置
- 3.2 Benchmark 测评
论文:TextSquare: Scaling up Text-Centric Visual Instruction Tuning
代码:暂无
出处:字节 | 华中科技大学 | 华东科技大学
时间:2024.04
一、背景
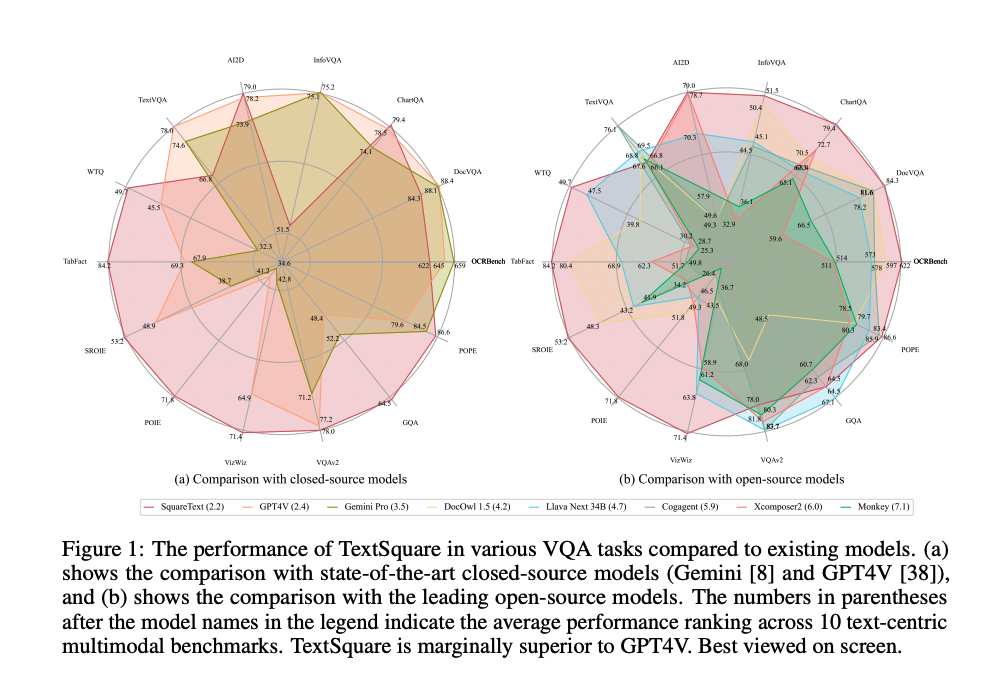
当前多模态大模型在 text-centric VQA 任务中已经取得了很好的效果,比如 GPT-4V 和 Gemini 在某些方面都超过了人类的识别能力,但一些开源的模型还远不如闭源的模型,如图 1 所示,这种差距的来源有很多,如模型结构、模型参数量、图像分辨率、训练数据、训练策略等
因此,有一些模型围绕数据来探究,想要得到更好的微调数据:
- Monkey,使用了专家模型来对图像生成不同的描述,然后使用 GPT-4 来组合出高质量的包含更多细节信息的描述
- LLaVAR [51] 和 TG-Doc [46] 使用 GPT-4 将 OCR 结果整合到指令中来生成与文本丰富的图像相关的对话。
- ShareGPT4V[5] 通过 GPT4V 构建了一个高质量图像描述数据集
但上述方法还是以文本为中心的,图像层面上还存在一些约束,如图像内容呈现方式,图像规模等等
为了解决这一差距,本文提出了一种策略,称为 Square,用于从复杂且多功能的闭源 MLLMs 获取大量高质量、以文本为中心的 VQA 数据,从而构建一个包含数千万实例的数据集(Square-10M),用于指令调优。
该方法包括四个步骤:
- 自我提问:利用 MLLM 在文本-图像分析和理解方面的能力生成与图像文本内容相关的问题
- 回答:利用不同的 prompting 技术(链式思维(Chain-of-Thought)和少样本提示等)来回答这些问题
- 推理:探讨模型回答背后的推理过程
- 评估:评估问题的有效性、图像文本内容的相关性、答案的正确性,从而提高数据质量并减轻幻觉现象
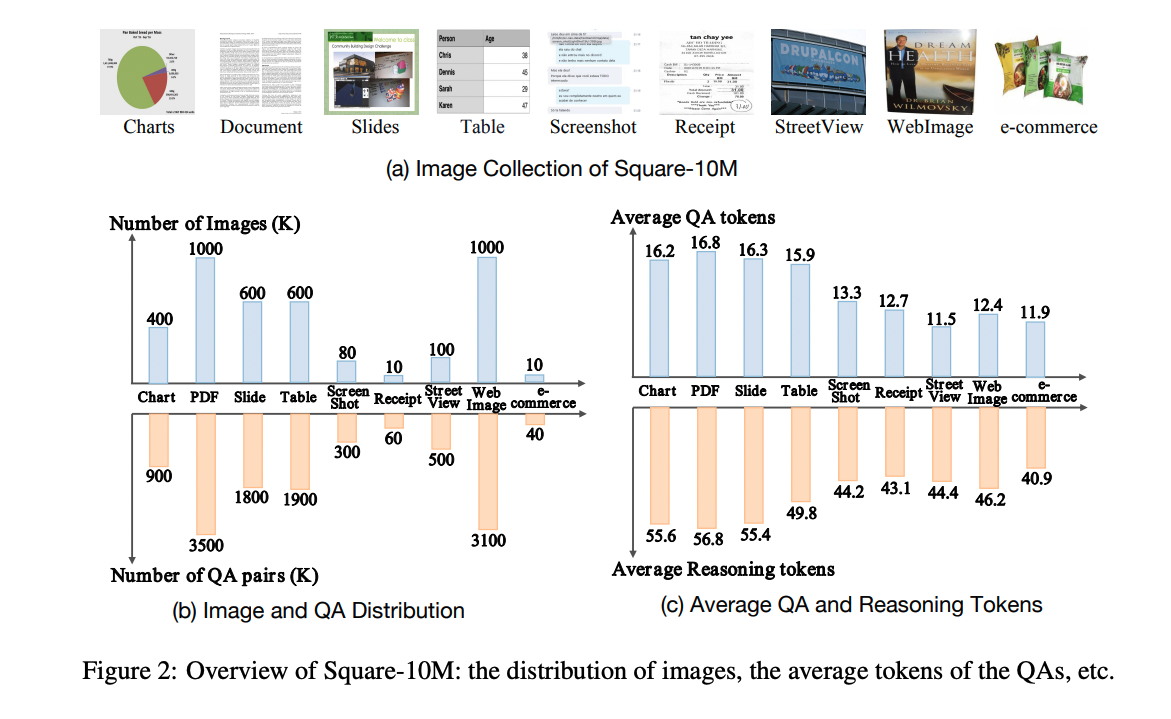
此外,为了丰富图像多样性,作者收集了大量的 text-rich images,包括自然场景、表格、图表、小票、书籍、幻灯片、pdf、文档、产品标签、网络数据等,构建了 Square-10M 数据集
多模态大模型现状:
最近的研究越来越多地关注将视觉知识引入大语言模型(LLMs)中 [52, 2, 7]。一般的尝试是通过中间模块(如 Projector [29]、QFormer [23]、Perceiver Resampler [1] 等)连接视觉编码器和 LLM,并进行预训练对齐和指令微调,以实现视觉-语言理解。
最近,一些研究 [48, 11, 10, 50, 47, 44, 33, 27] 提出了增强多模态大语言模型(MLLMs)理解文本元素(OCR、以文本为中心的 VQA 等)的能力。其中,mPLUG-DocOwl [48] 创建了新的指令跟随数据集,以增强调优过程。
TextMonkey [7] 采用了移位窗口注意机制,并过滤掉了重要的标记。
DocPedia [10] 和 HRVDA [27] 则通过扩大输入分辨率来弥合 MLLMs 与视觉文档理解之间的差距。
尽管现有开源 MLLMs 已取得了显著进展,但它们仍然与最先进的闭源模型(如 GPT4V [38] 和 Gemini Pro [8])存在巨大差距。本文提出通过训练大规模且高质量的指令跟随数据来缩小这一差距。
以文本为中心的 VQA 现状:
以文本为中心的视觉问答(Text-Centric Visual Question Answering)旨在理解图像中文本和视觉元素之间的交互。
Donut [20] 首次提出了一种基于 Transformer 的端到端训练方法,不需要 OCR。
Pix2Struct [22] 引入了一种可变分辨率的输入表示,以适应文档图像。
DoCo [24] 通过对齐多模态输入的文档对象,增强了图像编码器在大视觉语言模型(LVLMs)中的视觉表示。
BLIVA [16] 通过连接学习的查询嵌入和编码的补丁嵌入,扩大了输入标记空间。一些研究 [11, 46, 51] 在这方面进行了以数据为中心的尝试。
UniDoc [11] 从 PowerPoint 演示文稿中构建了60万对面向文档的图像-文本对。
LLaVAR [51] 和 TG-Doc [46] 通过将 OCR 结果整合到指令中,提示仅包含文本的 GPT-4 为文本丰富的图像生成对话。这些研究都局限于小规模注释或基于单一模态输入的生成。
二、方法
2.1 Square-10M
下图为数据处理的整个流程:
- 数据收集:收集包含多种属性的文本元素的大规模图像。
- 数据生成:包括自我提问、回答和推理。在这个阶段,提示多模态大语言模型(MLLM)基于给定图像生成 VQA 对,以及其答案背后的推理过程。
- 数据过滤:对生成的内容进行自我评估,旨在通过利用 MLLMs 的评估能力来丢弃无意义的问题和错误的答案。

- 总计 380 万张包含丰富文本元素的图像
- 通过数据生成阶段获得了 2000 万个问答对
- 最终,通过 Square 策略提炼出了 910 万个问答对及其推理背景。图 2 中展示了对 Square-10M 的更精确分析。
下图为数据示例和数量分布:

如何使用 Gemini 进行数据生成呢:
- 自我提问。在这一阶段,我们提示 Gemini Pro 针对给定图像生成深刻、有意义且非平凡的问题。我们要求 Gemini Pro 首先全面分析图像,然后根据其理解提出问题,如图 3 所示。考虑到高级多模态大语言模型(MLLMs)通常在理解文本元素方面比视觉元素较弱,我们还通过使用专业的 OCR 模型将提取的文本预先添加到提示中。
- 回答。然后,指示 Gemini Pro 对生成的问题给出适当的答案。我们利用各种提示技术来丰富上下文信息并提高生成答案的可靠性,例如链式思维(Chain-of-Thought)和少样本提示(few-shot prompting)。图 3 展示了一个为给定问题生成答案的示例提示。
- 推理。我们要求 Gemini Pro 阐述其答案背后的详细理由。这样的努力促使 Gemini Pro 更深入地思考问题与视觉元素之间的联系,从而减少幻觉并提供准确的答案。此外,生成的理由可以作为针对特定问题的额外上下文信息,有助于研究上下文学习机制。图 3 展示了一个用于自我推理的示例提示。
如何进行数据过滤:
-
MLLMs 的自我评估:我们提示 Gemini Pro 以及其他高级 MLLMs 判断生成的问题是否有意义,答案是否足够好以正确回答问题。图 3 展示了一个用于自我评估的示例提示。
-
多个 prompt 的一致性:除了对生成内容进行直接评估外,我们在数据生成阶段手动扩展了提示和上下文空间。一个正确且有意义的 VQA 对在提供不同提示时应该在语义上保持一致。具体来说,在回答阶段,我们为 Gemini Pro 提供不同但语义相似的提示来回答给定问题。如果生成的答案在语义上不稳定,我们就会丢弃这些 VQA 对。图 3 中给出了一个示例。
-
多个上下文一致性:类似于多提示一致性,我们通过预先添加不同的上下文信息来进一步验证 VQA 对。对于生成的问题,Gemini Pro 在不同上下文下生成三种类型的答案:(1)带推理的回答。Gemini Pro 在详细解释之前回答问题(即在推理阶段生成的内容)。(2)上下文内回答。Gemini Pro 使用链式思维或少样本提示回答问题。(3)简单回答。Gemini Pro 在没有额外上下文的情况下回答问题。如果生成的答案在语义上不一致,我们就会丢弃这些 VQA 对。
2.2 模型结构
- A Vision Encoder modified from OpenAI CLIP ViT-L14-336 [41], where the resolution is increased to 700 for improved performance.
- A LLM based on InternLM-2 [3], utilizing InternLM2-7B-ChatSFT as the practical variant.
- A Projector, which semantically aligns the vision token and the text token.
2.3 使用 Square-10M 进行有监督微调
TextSquare 是通过使用 Square-10M 数据集进行监督微调(SFT)实现的。SFT 过程包括三个阶段:
- 第一阶段:解冻所有三个组件(即视觉编码器、LLM 和投影器),并在分辨率为 490 的情况下训练模型。
- 第二阶段:将输入分辨率提高到 700,并仅训练视觉编码器以适应分辨率变化。
- 第三阶段:在分辨率为 700 的情况下进一步进行全参数微调。
三、效果
3.1 实验设置
训练数据包括 Square-10M 和 Monkey 的 SFT 数据。
训练过程分为三个阶段,使用相同的数据和 AdamW [32] 优化器,并使用 64 个 A100-80G GPU。
- 第一阶段:对 InternLM-Xcomposer2 进行全参数微调,学习率从 1e-5 降到 1e-6,耗时约 9520 GPU 小时。
- 第二阶段:将图像分辨率扩展到 700,并仅训练视觉变换器(VIT),学习率从 1e-4 降到 1e-5,耗时约 7280 GPU 小时。
- 第三阶段:在分辨率为 700 的情况下进行全参数微调,学习率从 1e-5 降到 1e-6,耗时约 12350 GPU 小时。
3.2 Benchmark 测评














![[word] word图片环绕方式怎么设置? #经验分享#笔记#媒体](https://img-blog.csdnimg.cn/img_convert/878c3f9f858731552a4a49f95b979cb0.gif)