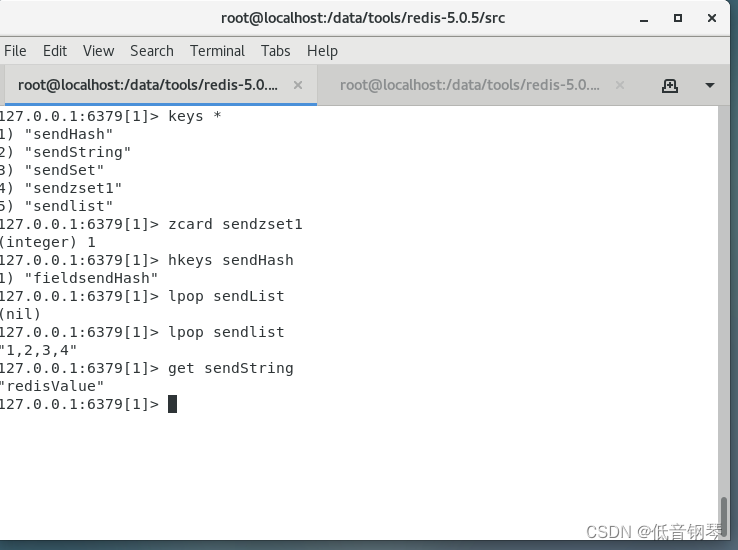
参考官方手册DataStream Connectors
1 DataStream连接器概述
一、预定义的Source和Sink
一些比较基本的Source和Sink已经内置在Flink里。
1、预定义data sources支持从文件、目录、socket,以及collections和iterators中读取数据。
2、预定义data sinks支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
二、附带的连接器
连接器可以和多种多样的第三方系统进行交互。
目前支持以下系统:
Apache Kafka (source/sink)*****
Apache Cassandra (sink)
Amazon DynamoDB (sink)
Amazon Kinesis Data Streams (source/sink)
Amazon Kinesis Data Firehose (sink)
Elasticsearch (sink)
Opensearch (sink)
FileSystem (sink)
RabbitMQ (source/sink)
Google PubSub (source/sink)
Hybrid Source (source)
Apache Pulsar (source)
JDBC (sink)*****
请记住,在使用一种连接器时,通常需要额外的第三方组件,比如:数据存储服务器或者消息队列。
要注意这些列举的连接器是Flink工程的一部分,包含在发布的源码中,但是不包含在二进制发行版中。
apache-flink 1.15.3使用FlinkKafkaConsumer和FlinkKafkaProducer
apache-flink 1.16.0使用KafkaSource和KafkaSink(推荐)
注意:FlinkKafkaConsumer和FlinkKafkaProducer已被弃用
并且将在Flink 1.17中移除
2 Apache Kafka连接器
2.1 依赖
Flink 提供了Apache Kafka连接器使用精确一次(Exactly-once)的语义在Kafka topic中读取和写入数据。
Apache Flink集成了通用的Kafka连接器,它会尽力与Kafka client的最新版本保持同步。该连接器使用的Kafka client版本可能会在Flink版本之间发生变化。当前Kafka client向后兼容 0.10.0 或更高版本的 Kafka broker。
为了在PyFlink作业中使用Kafka connector,需要添加下列依赖:
若使用Kafka source,flink-connector-base也需要包含在依赖中:
在https://mvnrepository.com/里输入flink kafka寻找对应版本的连接器。
flink-connector-base-1.16.0.jar
flink-connector-kafka-1.16.0.jar
kafka-clients-2.8.1.jar
拷贝到/usr/local/lib/python3.6/dist-packages/pyflink/lib。
拷贝到FLINK_HOME/lib。
拷贝到IDEA/External/.../pyflink/lib。
启动kafka
zkServer.sh start
cd /usr/local/kafka/
./bin/kafka-server-start.sh -daemon ./config/server0.properties
2.2 Kafka Source
2.2.1 基本概念
一、以下属性在构建KafkaSource时是必须指定的:
1、Bootstrap server,通过setBootstrapServers(String)方法配置。
2、消费者组ID,通过setGroupId(String)配置。
3、要订阅的Topic / Partition。
4、用于解析Kafka消息的反序列化器(Deserializer)。
二、Kafka Source提供了3种Topic / Partition的订阅方式:
1、Topic列表,订阅Topic列表中所有Partition的消息:
KafkaSource.builder().set_topics("topic-a", "topic-b")
2、正则表达式匹配,订阅与正则表达式所匹配的Topic下的所有Partition:
KafkaSource.builder().set_topic_pattern("topic.*")
3、Partition列表,订阅指定的Partition:
partition_set = {
KafkaTopicPartition("topic-a", 0),
KafkaTopicPartition("topic-b", 5)
}
KafkaSource.builder().set_partitions(partition_set)
三、消息解析
代码中需要提供一个反序列化器(Deserializer)来对Kafka的消息进行解析。 反序列化器通过setDeserializer(KafkaRecordDeserializationSchema)来指定,其中 KafkaRecordDeserializationSchema定义了如何解析Kafka的ConsumerRecord。
如果只需要Kafka消息中的消息体(value)部分的数据,可以使用KafkaSource构建类中的 setValueOnlyDeserializer(DeserializationSchema)方法,其中DeserializationSchema定义了如何解析Kafka消息体中的二进制数据。
也可使用Kafka提供的解析器来解析Kafka消息体。例如使用StringDeserializer来将Kafka消息体解析成字符串:
目前PyFlink只支持set_value_only_deserializer来自定义Kafka消息中值的反序列化.
KafkaSource.builder().set_value_only_deserializer(SimpleStringSchema())
四、起始消费位点
Kafka source能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费 。内置的位点初始化器包括:
KafkaSource.builder()
# 从消费组提交的位点开始消费,不指定位点重置策略
.set_starting_offsets(KafkaOffsetsInitializer.committed_offsets()) \
# 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
.set_starting_offsets(KafkaOffsetsInitializer.committed_offsets(KafkaOffsetResetStrategy.EARLIEST)) \
# 从时间戳大于等于指定时间戳(毫秒)的数据开始消费
.set_starting_offsets(KafkaOffsetsInitializer.timestamp(1657256176000)) \
# 从最早位点开始消费
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
# 从最末尾位点开始消费
.set_starting_offsets(KafkaOffsetsInitializer.latest())
如果未指定位点初始化器,将默认使用OffsetsInitializer.earliest()。
五、有界/无界模式
Kafka Source支持流式和批式两种运行模式。默认情况下,KafkaSource设置为以流模式运行,因此作业永远不会停止,直到Flink作业失败或被取消。
可以使用setBounded(OffsetsInitializer)指定停止偏移量使Kafka Source以批处理模式运行。当所有分区都达到其停止偏移量时,Kafka Source会退出运行。
流模式下运行通过使用setUnbounded(OffsetsInitializer)也可以指定停止消费位点,当所有分区达到其指定的停止偏移量时,Kafka Source会退出运行。
六、其他属性
除了上述属性之外,您还可以使用setProperties(Properties)和setProperty(String, String) 为Kafka Source和Kafka Consumer设置任意属性。
七、动态分区检查
为了在不重启Flink作业的情况下处理Topic扩容或新建Topic等场景,可以将Kafka Source 配置为在提供的Topic / Partition订阅模式下定期检查新分区。要启用动态分区检查,请将 partition.discovery.interval.ms 设置为非负值:
KafkaSource.builder() \
.set_property("partition.discovery.interval.ms", "10000")
# 每10秒检查一次新分区
# 分区检查功能默认不开启。需要显式地设置分区检查间隔才能启用此功能。
八、事件时间和水印
默认情况下,Kafka Source使用Kafka消息中的时间戳作为事件时间。您可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印:
env.fromSource(kafkaSource, new CustomWatermarkStrategy(),
"Kafka Source With Custom Watermark Strategy");
九、空闲
如果并行度高于分区数,Kafka Source 不会自动进入空闲状态。您将需要降低并行度或向水印策略添加空闲超时。如果在这段时间内没有记录在流的分区中流动,则该分区被视为“空闲”并且不会阻止下游操作符中水印的进度。
十、消费位点提交
Kafka source在checkpoint完成时提交当前的消费位点 ,以保证Flink的checkpoint状态和 Kafka broker上的提交位点一致。如果未开启checkpoint,Kafka source依赖于Kafka consumer内部的位点定时自动提交逻辑,自动提交功能由enable.auto.commit和 auto.commit.interval.ms两个Kafka consumer配置项进行配置。
注意:Kafka source不依赖于broker上提交的位点来恢复失败的作业。提交位点只是为了上报Kafka consumer和消费组的消费进度,以在broker端进行监控。
2.2.2 应用示例
Kafka Source提供了构建类来创建KafkaSource的实例。以下代码片段展示了如何构建 KafkaSource来消费“input-topic”最早位点的数据, 使用消费组“my-group”,并且将 Kafka消息体反序列化为字符串:
# -*- coding: UTF-8 -*-
from pyflink.common import SimpleStringSchema, WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
brokers = "192.168.43.48:9092"
source = KafkaSource.builder() \
.set_bootstrap_servers(brokers) \
.set_topics("test") \
.set_group_id("my-group") \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
ds = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
ds.print()
env.execute()
2.3 Kafka Sink
2.3.1 基本概念
一、以下属性在构建 KafkaSink 时是必须指定的:
1、Bootstrap servers, setBootstrapServers(String)。
2、消息序列化器(Serializer),
setRecordSerializer(KafkaRecordSerializationSchema)。
3、如果使用DeliveryGuarantee.EXACTLY_ONCE的语义保证,
则需要使用setTransactionalIdPrefix(String)。
二、序列化器
构建时需要提供KafkaRecordSerializationSchema来将输入数据转换为Kafka的 ProducerRecord。Flink提供了schema构建器以提供一些通用的组件,例如消息键(key)/消息体(value)序列化、topic选择、消息分区,同样也可以通过实现对应的接口来进行更丰富的控制。
KafkaRecordSerializationSchema.builder() \
.set_topic_selector(lambda element: <your-topic-selection-logic>) \
.set_value_serialization_schema(SimpleStringSchema()) \
.set_key_serialization_schema(SimpleStringSchema()) \
# set partitioner is not supported in PyFlink
.build()
其中消息体(value)序列化方法和topic的选择方法是必须指定的,此外也可以通过 setKafkaKeySerializer(Serializer)或setKafkaValueSerializer(Serializer)来使用Kafka提供而非Flink提供的序列化器。
三、容错
KafkaSink总共支持三种不同的语义保证(DeliveryGuarantee)。
对于 DeliveryGuarantee.AT_LEAST_ONCE和DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint必须启用。
默认情况下KafkaSink使用DeliveryGuarantee.NONE。
以下是对不同语义保证的解释:
1、DeliveryGuarantee.NONE不提供任何保证:消息有可能会因Kafka broker的原因发生丢失或因Flink的故障发生重复。
2、DeliveryGuarantee.AT_LEAST_ONCE: sink在checkpoint时会等待Kafka缓冲区中的数据全部被Kafka producer确认。消息不会因Kafka broker端发生的事件而丢失,但可能会在Flink重启时重复,因为Flink会重新处理旧数据。
3、DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink会将所有数据通过在checkpoint时提交的事务写入。因此,如果consumer只读取已提交的数据,在Flink发生重启时不会发生数据重复。然而这会使数据在checkpoint完成时才会可见,因此请按需调整checkpoint的间隔。
请确认事务ID的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将Kafka的事务超时时间调整至远大于checkpoint最大间隔 + 最大重启时间,否则Kafka对未提交事务的过期处理会导致数据丢失。
四、数据丢失
根据你的Kafka配置,即使在Kafka确认写入后,你仍然可能会遇到数据丢失。特别要记住在 Kafka 的配置中设置以下属性:
acks
log.flush.interval.messages
log.flush.interval.ms
log.flush.*
上述选项的默认值是很容易导致数据丢失的。
2.3.2 应用示例
# -*- coding: UTF-8 -*-
from pyflink.common import SimpleStringSchema, WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer, KafkaSink, \
KafkaRecordSerializationSchema
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
brokers = "192.168.43.48:9092"
source = KafkaSource.builder() \
.set_bootstrap_servers(brokers) \
.set_topics("test") \
.set_group_id("my-group") \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
ds = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
record_serializer = KafkaRecordSerializationSchema.builder() \
.set_topic("tt") \
.set_value_serialization_schema(SimpleStringSchema()) \
.build()
sink = KafkaSink.builder() \
.set_bootstrap_servers(brokers) \
.set_record_serializer(record_serializer) \
.build()
ds.sink_to(sink)
env.execute()
3 JDBC连接器
该连接器可以向 JDBC 数据库写入数据。
3.1 依赖
已创建的JDBC Sink能够保证至少一次的语义。 更有效的精确执行一次可以通过upsert语句或幂等更新实现。
(1)在https://mvnrepository.com/里输入flink jdbc寻找对应版本的连接器。
flink-connector-jdbc-1.16.0.jar
mysql-connector-java-8.0.19.jar
(2)查看mysql版本
select version()
8.0.19
3.2 创建表
DROP TABLE IF EXISTS `books`;
CREATE TABLE `books` (
`id` int NOT NULL,
`title` varchar(255) DEFAULT NULL,
`authors` varchar(255) DEFAULT NULL,
`year` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.3 应用示例
# -*- coding: UTF-8 -*-
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.jdbc import JdbcSink, JdbcConnectionOptions
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.STRING(), Types.INT()])
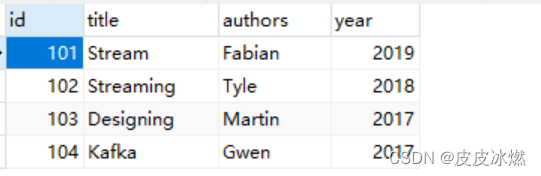
ds = env.from_collection(
[(101, "Stream", "Fabian", 2019),
(102, "Streaming", "Tyle", 2018),
(103, "Designing", "Martin", 2017),
(104, "Kafka", "Gwen", 2017)], type_info=type_info)
ds.add_sink(
JdbcSink.sink(
"insert into books (id, title, authors, year) values (?, ?, ?, ?)",
type_info,
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.with_url('jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=UTC')
.with_driver_name('com.mysql.cj.jdbc.Driver')
.with_user_name('root')
.with_password('bigdata')
.build()
))
env.execute()