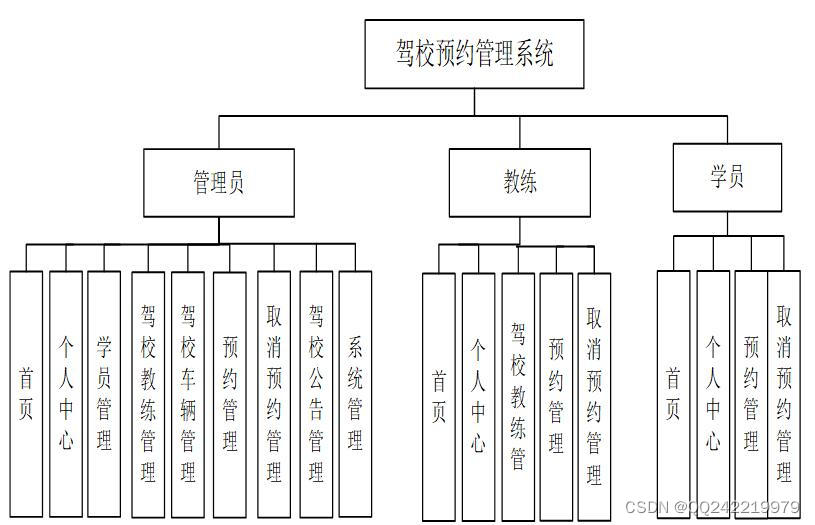
一些我自己不懂的过程,我自己在后面写了demo解释。
import torch
import torch.nn as nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
def pair(t):
return t if isinstance(t, tuple) else (t, t)class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)## 对tensor张量分块 x :1 197 1024 qkv 最后是一个元祖,tuple,长度是3,每个元素形状:1 197 1024
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return xclass ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size) #224x224
patch_height, patch_width = pair(patch_size) # 16x16
assert image_height % patch_height == 0 and image_width % patch_width == 0 , 'Image dimensions'
#块数
num_patches = (image_height // patch_height) * (image_width // patch_width)
#每块展开的长度
patch_dim = channels * patch_height * patch_width
assert pool in {'cls','mean'}, 'pool type cls or mean'
#完成的操作是将(B,C,H,W)的shape调整为(B,(H/P *W/P),P*P*C)
#H/P *W/P:块数 p1 p2 c:每块展开的长度 = patch_dim
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
#块拉伸之后,做一个映射 ,每一块就是一个batch
nn.Linear(patch_dim, dim),
)
#生成了[1, num_patches + 1, dim] 形状的参数,这些随机数字满足标准正态分布(0~1)
#num_patches + 1:块位置的编码+cls
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
#生成cls_token 的参数
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
#在transformer中一般采用LayerNorm,LayerNorm也是归一化的一种方法,与BatchNorm不同的是它是对每单个batch进行的归一化,而batchnorm是对所有batch一起进行归一化的
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img) ## img 1 3 224 224 输出形状x : 1 196 1024
b, n, _ = x.shape ##
print('块嵌入后的维度'+ str(x.shape))
#这个是复制b份cls_token
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
print('cls_tokens维度'+ str(cls_tokens.shape))
x = torch.cat((cls_tokens, x), dim=1)
print('块嵌入拼接cls_tokens的维度'+str(x.shape))
x += self.pos_embedding[:, :(n + 1)]
print("self.pos_embedding[:, :(n + 1)]维度"+str(self.pos_embedding[:, :(n + 1)].shape))
print("x+pos维度"+str(x.shape))
x = self.dropout(x)
x = self.transformer(x)
print('after_transformer'+str(x.shape))
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
print(x.shape)
x = self.to_latent(x)
return self.mlp_head(x)
v = ViT(
image_size = 224, #输入图像的大小
patch_size = 16, #块的大小
num_classes = 1000, #做多少分类
dim = 1024, # 维度
depth = 6, #encoder要堆叠多少个
heads = 8, #多头注意力机制有多少个头
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)img = torch.randn(2, 3, 224, 224)
preds = v(img) # (1, 1000)以上是代码的简单实现,但是我还是有一些代码没有看懂。自己写了几个demo就看懂了。毕竟我还很菜。
1.Rearrange
用来改变张量的shape
完成的操作是将(B,C,H,W)的shape调整为(B,(H/P *W/P),P*P*C)
f = Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = 16, p2 = 16)
a = f(img)
print(a.shape)输出:

这是另外一个小例子:

2.nn.Linear
不管数据的shape是怎样的,该函数处理的是最后一维,将n1维度映射为n2维度。
f = Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = 16, p2 = 16)
a = f(img)
print(a.shape)
#demo部分
f1 = nn.Linear(768, 1026)
b = f1(a)
print(b.shape)
test = torch.randn(2, 768)
t = f1(test)
print(t.shape)
test1 = torch.randn(3,2, 768)
t1 = f1(test1)
print(t1.test)
test2 = torch.randn(5,6,3,2, 768)
t2 = f1(test2)
print(t2.shape)
输出:

3.chunk
把一个张量分成几份

4.向量相加
G1: 如果相加的两个张量维度不一致,那么首先把维度低的那个张量从右边和维度高的张量对齐
例如下面的代码,b的维度低一些,所以和a相加的时候b的维度就会先扩充为[1,1,5,6]。
a = torch.ones([8, 4, 5, 6])
print('a =',a.size())
b = torch.ones([5, 6])
print('b =',b.size())
c = a+b
print('c =',c.size())
G2:当两个张量维度相同时,对应轴的值需要一样,或者为1。
相加时,把所有为1的轴进行复制扩充,从而得到两个维度完全相同的张量。然后对应位置相加即可。
a = torch.ones([2, 2, 3])
b = torch.ones([1, 2, 3])
c = a+b
print(c)
a = torch.ones([2, 2, 3])
b = torch.ones([3])
c = a+b
print(c) 
a = torch.ones([2, 2, 3])
b = torch.ones([1, 1, 1])
c = a+b
print(c) 
还有不可相加的例子
1.由于4不等于2,因此不可以相加
a = torch.ones([8, 4, 5, 6])
print('a =',a.size())
b = torch.ones([1, 2, 1, 6])
print('b =',b.size())
c = a+b
print('c =',c.size())
2.由于3不等于6,不可以相加
a = torch.ones([8, 4, 5, 6])
print('a =',a.size())
b = torch.ones([1, 4, 1, 3])
print('b =',b.size())
c = a+b
print('c =',c.size())
5.张量的切片
取第几维,第几个元素
a = torch.randint(1, 24, (2, 3, 4))
print(a)
print(a[:,0])
print(a[:,0,0])输出: