这是Transformer的第二篇文章,上篇文章中我们了解了分词算法BPE,本文我们继续了解Transformer中的位置编码和核心模块——多头注意力。下篇文章就可以实现完整的Transformer架构。
位置编码
我们首先根据BPE算法得到文本切分后的子词标记,然后经过输入嵌入层将每个标记转换为对应的向量表示,但Transformer不再基于类似RNN循环的方式,而是可以一次为所有的标记进行建模,因此丢失了输入中单词之间的相对位置关系。
在真正喂给Transformer模型之前,一个重要的操作是为嵌入向量表示增加位置表示,即位置编码。位置编码可以通过学习得到也可以通过固定设置,这里介绍Transformer原始论文中使用的基于正弦函数和余弦函数的固定位置编码。
一个好的位置编码应该具有以下性质:
1. 每个时间步(位置)的编码应该唯一;
2. 任意两个时间步的距离应该与句子长度无关;
3. 取值应该是有界的;
我们从这几个方面来分析下Transformer中使用的位置编码:

其中pos表示标记所在的位置,假设取值从0~100;i代表维度,即位置编码的每个维度对应一个波长不同的正弦或余弦波,波长从2 π到10000 ⋅ 2 π成等比数列;d表示位置编码的最大维度,和词嵌入的维度相同,假设是512;
这里假设最长时间步(位置)为100,每个位置的编码都是一个512维度的向量。我们先来回顾下常规正余弦函数sin ( x )和cos ( x )的图像:
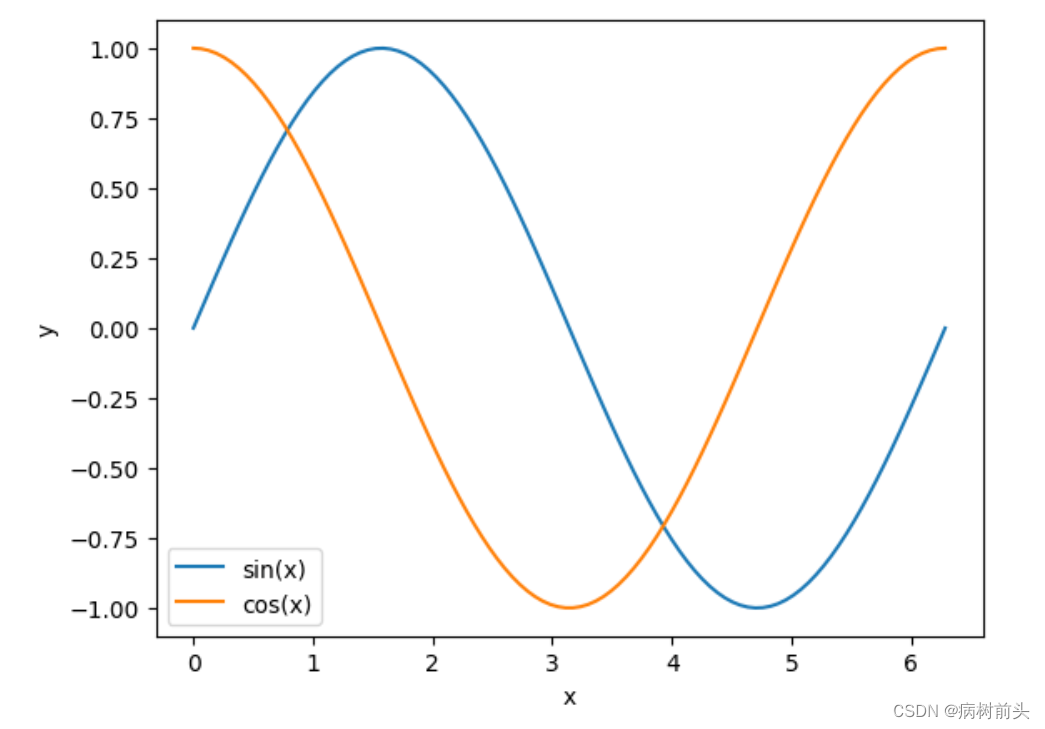
正余弦函数的图像如上图所示,显然它的取值是有界的,取值范围在[-1,+1]。但Transformer用的正弦函数的波长不同。
对于每个位置,由于我们有512个维度,因此我们有256对正弦值和余弦值,i的取值在[0,255]。假设考虑所有维度,计算位置pos处的位置编码向量每个元素(维度)的值:

对于位置0的编码为:
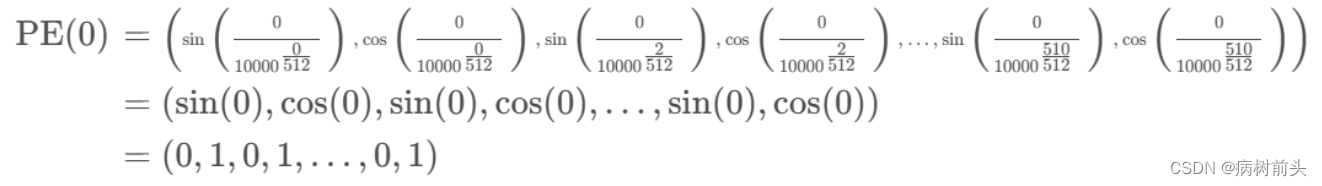
是一个交替0和1的向量;
对于位置1的编码为:
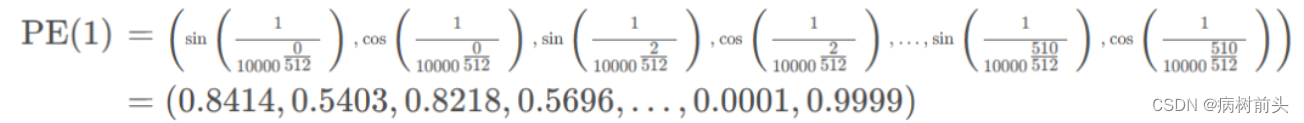

波长就是一个周期的距离,波长越长,走过一个周期越缓慢。单纯看这些数字没有意义,下面尝试可视化它们。
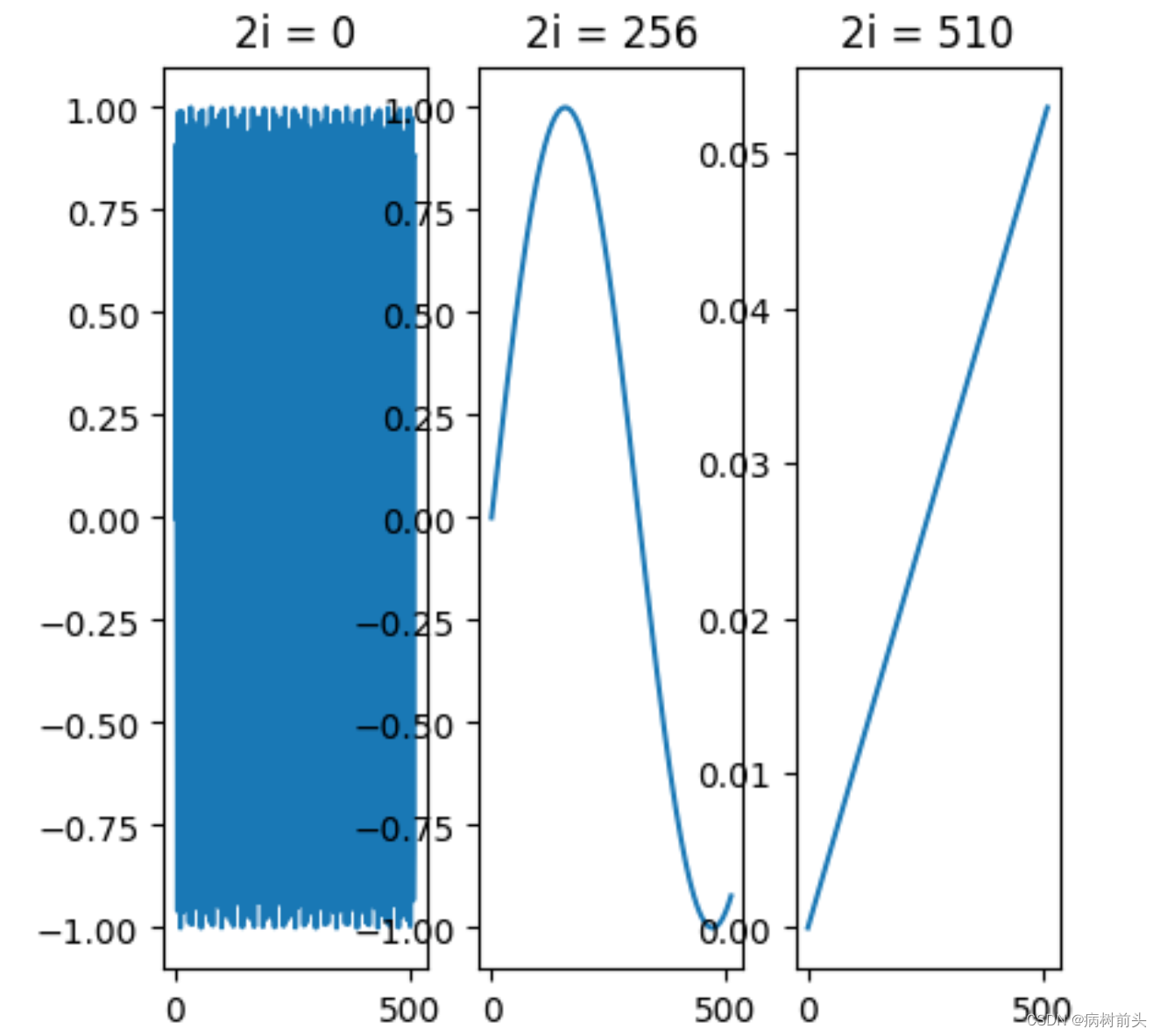
上图分别表示位置pos从0到512的过程中,不同波长的函数图像。上图左表示维度0波长2 π的图像,可以看到在0到1之间疯狂地变化;而上图右对应10000 ⋅ 2 π的波长,从0变化到0.06,波动非常小。
从这里我们可知满足了性质1和3,性质3好理解,取值在[-1,1]之间,是有界的。如果理解满足性质1呢?
假设我们想用二进制格式表示一个数字:

我们通过4位就可以表示最多到十进制15,我们可以发现不同位之间的变化率,第0位(红色)在每个数字上交替变化;第1位(蓝色)在每两个数字上重复;最高位(橙色)每八个数字上变化一次。
而Transformer不同波长(频率)的正余弦,所达到的效果是类似的。

或者可以理解为时钟上的指针(对应3个维度),波长(频率)对应指针的转速,秒针转速最快,就是第0位;时针转速最慢就是最高一位。在最高一位的周期内是不会重复的。所以性质3满足。
我们来看性质2,其实意思就是可以体现相对位置关系,pos + k的位置编码可以被位置pos \text{pos}pos(?)线性表示。这里需要用到三角函数公式:
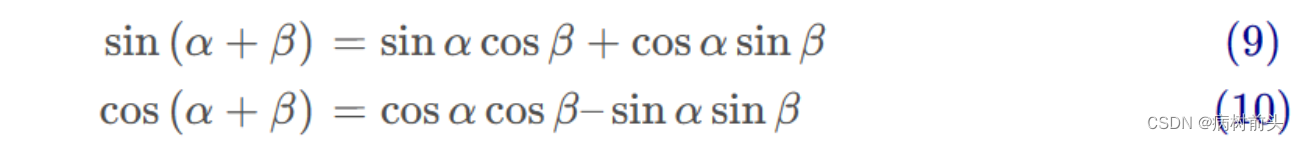
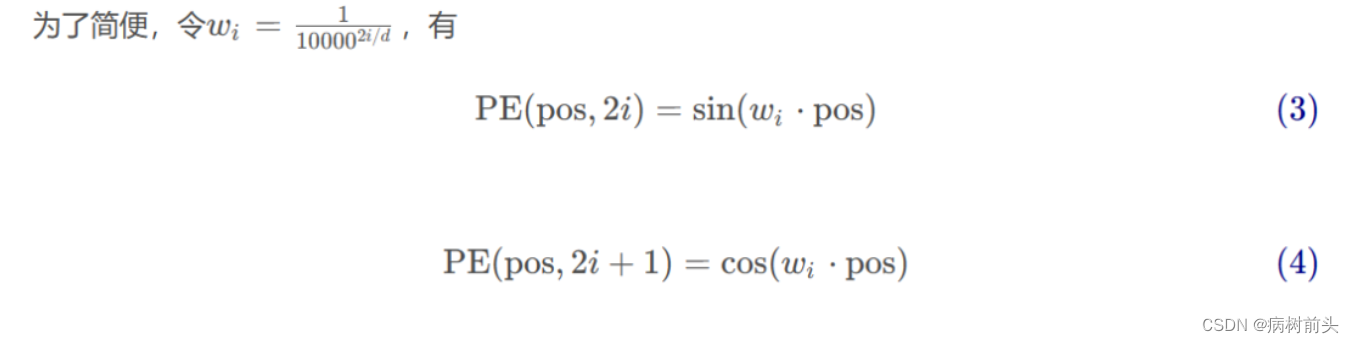
对于pos + k的位置编码:
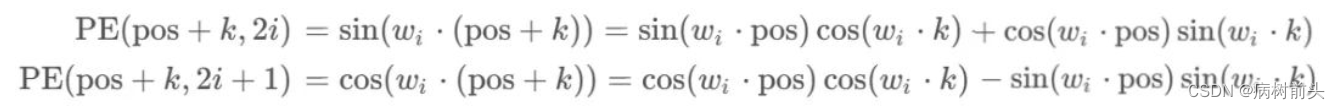
根据式( 3 )和( 4 )整理上式有:
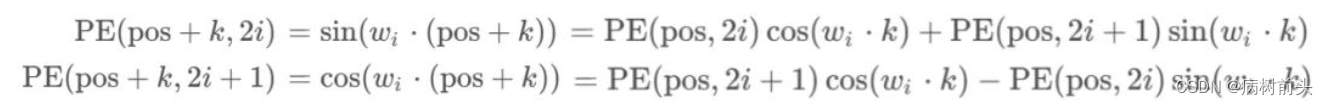

这也是为什么作者要交替使用正余弦函数,而不仅仅使用其中一个。???
pos处的位置嵌入可以表示为:
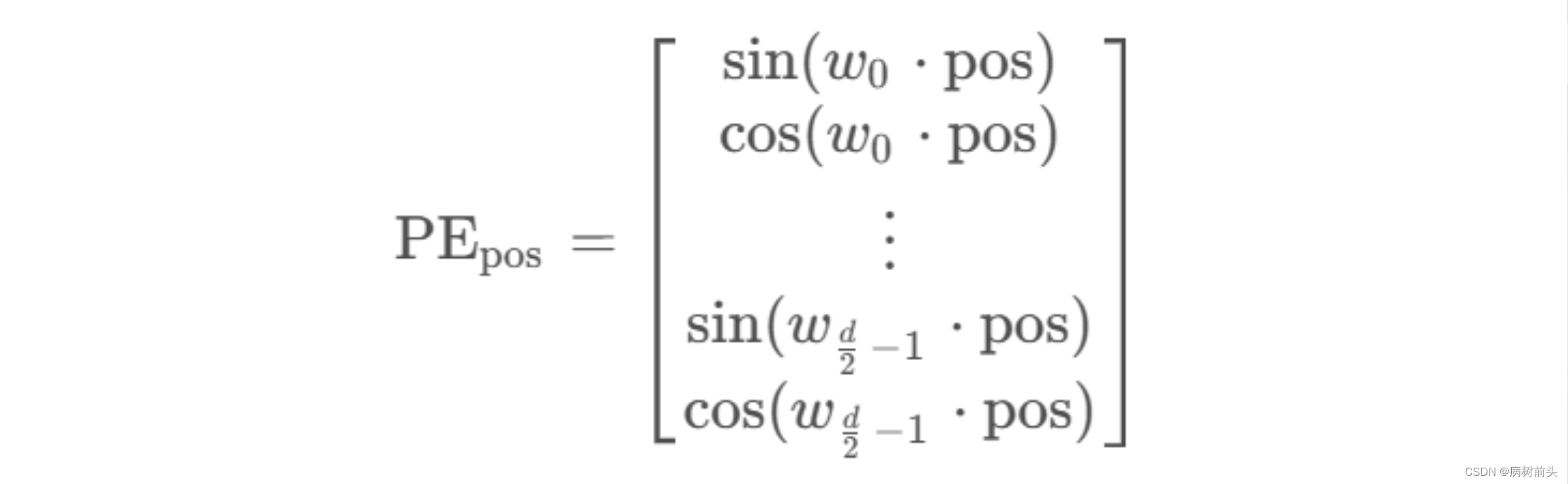

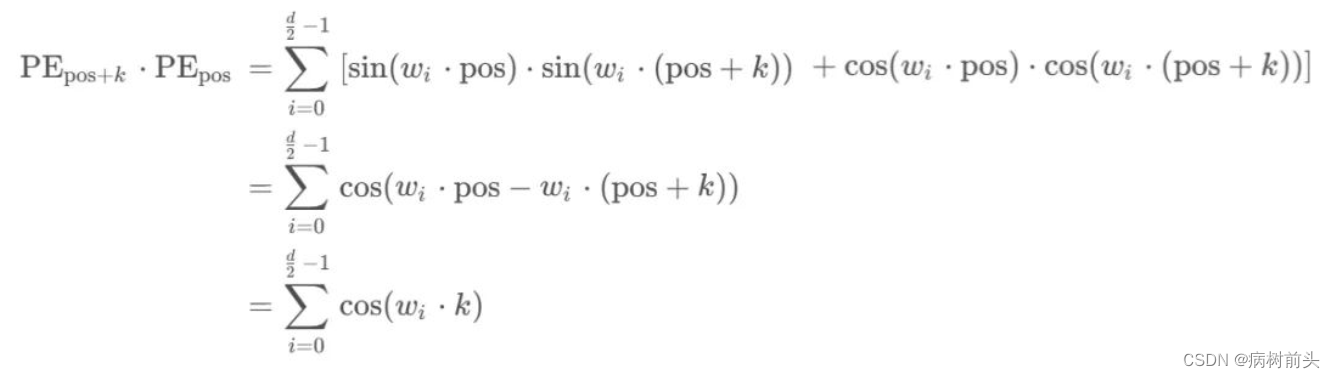

参考文章4给出位置之间内积的关系:
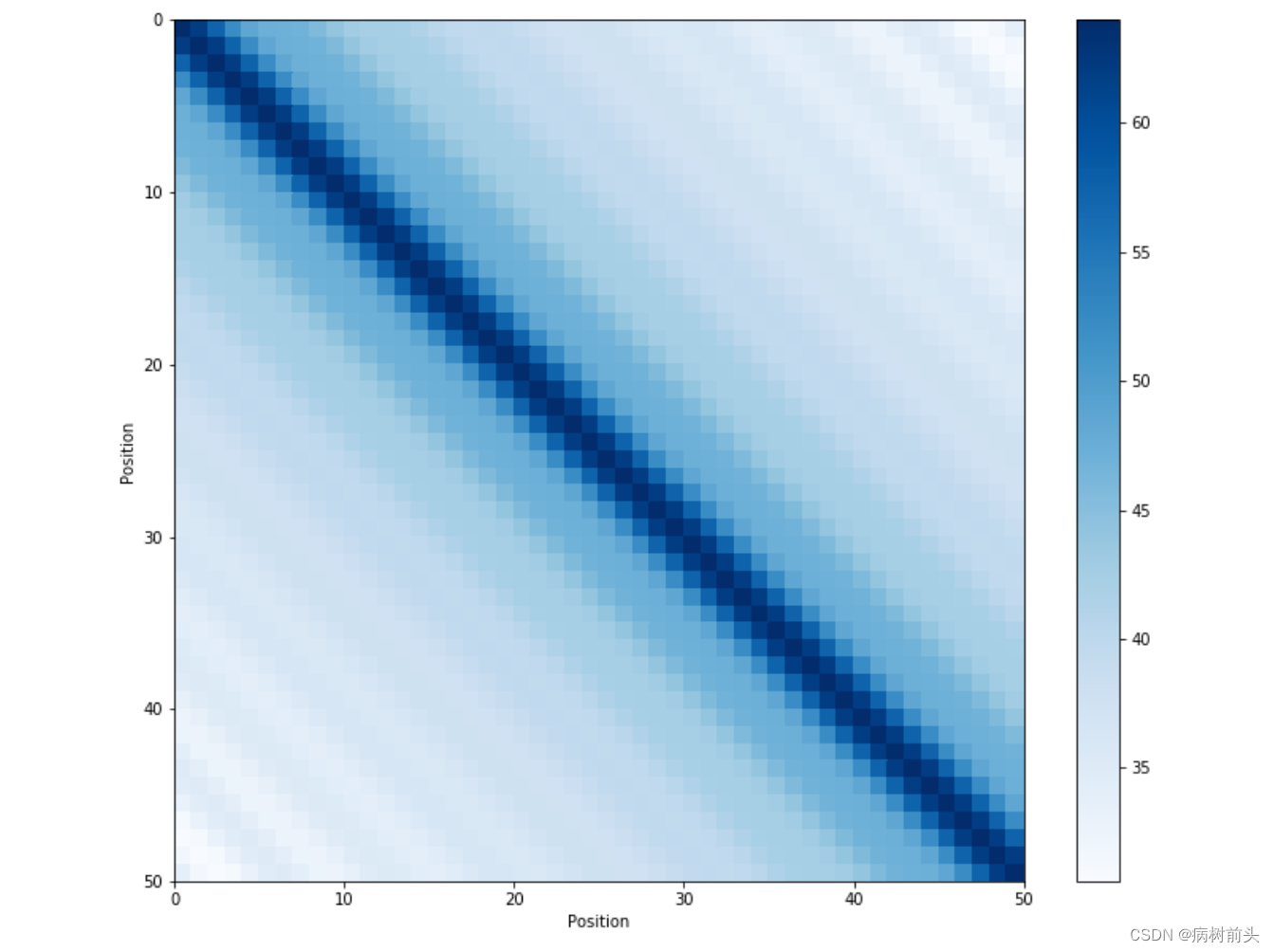
可以看到内积会随着相对位置的递增而减少,从而可以表示位置的相对距离。内积的结果是对称的,所以没有方向信息。
最后得到的位置编码需要和标记的词嵌入向量进行相加。
引用邱锡鹏老师关于问题为什么 Bert 的三个 Embedding 可以进行相加?的分析,来理解一下为什么可以相加。
文本可以看成是时序信号,一个时序的波可以用多个不同频率的正弦波叠加来表示,可能在神经网络中得到解耦,可能也不需要解耦。不管怎么,我们为词嵌入赋予了位置信息。下面先贴出代码实现:
class PositionalEncoding(nn.Module):
def __int__(
self, d_model: int = 512, dropout: float = 0.1, max_positions: int = 5000
) -> None:
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# pe (max_positions, d_model)
pe = torch.zeros(max_positions, d_model)
# position (max_positions, 1)
# create position column
position = torch.arange(0, max_positions).unsqueeze(1)
# div_term(d_model/2)
# calculate the divisor for positional encoding
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
#calculate sine values on even indices
#position * div_term will be broadcast to (max_positions, d_model/2)
pe[:, 0::2] = torch.sin(position * div_term)
#calculate cosine values on odd indices
pe[:, 1::2] = torch.cos(position * div_term)
#add a batch dimension: pe (1, max_positions, d_model)
pe = pe.unsqueeze(0)
#buffers will not be trained
self.register_buffer("pe", pe)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x (Tensor): (batch_size, seq_len, d_model)embeddings
Returns:
Tensor: (batch_size, seq_len, d_model)
"""
#x.size(1) is the max sequence length
x = x + self.pe[:, : x.size(1)]
return self.dropout(x)

最后一项就是代码的实现形式,14行代码得到一个d_model/2维度的行向量;position被定义成一个max_len维度的列向量,position * div_term会被广播成(max_len, d_model/2)。
然后根据公式(1)和(2),分别为偶数和奇数维度赋值正余弦项;最后扩充pe的维度使得维度个数和输入一致。
最后通过register_buffer将计算出来的pe保存成模型的buffer而不是parameter,buffer的特点就是不需要更新。
多头注意力
自注意力
首先回顾下注意力机制,注意力机制允许模型为序列中不同的元素分配不同的权重。而自注意力中的"自"表示输入序列中的输入相互之间的注意力,即通过某种方式计算输入序列每个位置相互之间的相关性。



缩放点积注意力
从文章注意力机制中我们知道有很多种计算注意力的方式,最高效的是点积注意力,即两个输入之间做点积。




这种计算注意力的方式和我们在seq2seq中遇到的不同,seq2seq是用解码器的隐状态与编码器所有时刻的输出计算,而自注意力是输入自己与自己进行计算。参与计算的只是输入本身。
但Transformer使用的是更加复杂一点的计算方式,来捕获更加丰富的信息。
在Transformer计算注意力的过程中,每个输入扮演了三种不同角色:
1. Query: 与所有的输入进行比较,为当前关注的点。
2. Key:作为与Query进行比较的角色,用于计算和Query之间的相关性。
3. Value:用于计算当前注意力关注点的输出,根据注意力权重对不同的Value进行加权和。

如果把注意力过程类比成搜索的话,那么假设在百度中输入"自然语言处理是什么",那么Query就是这个搜索的语句;Key相当于检索到的网页的标题;Value就是网页的内容。
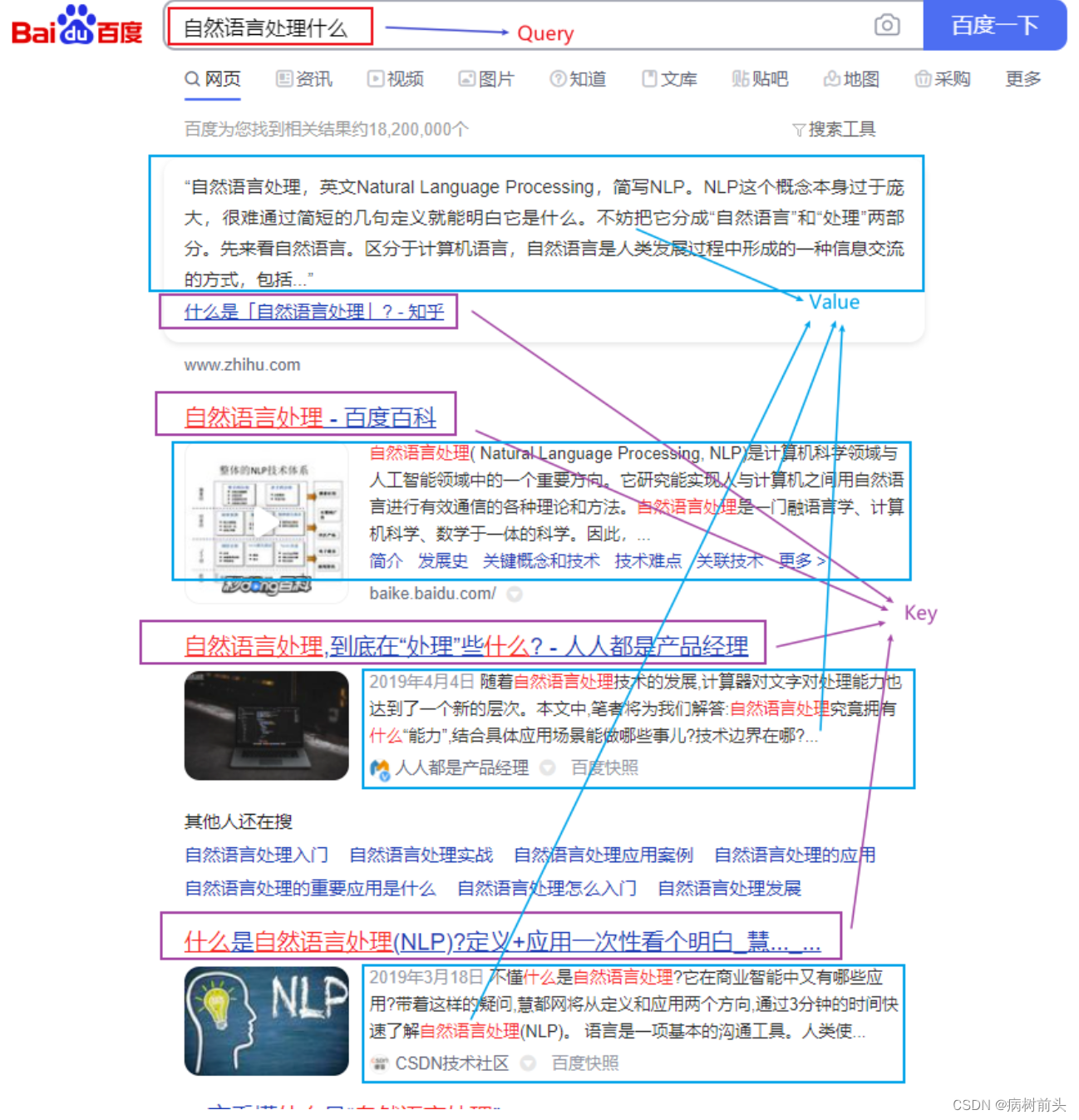
Query和Key是用于比较的,Value是用于提取特征的。通过将输入映射到不同的角色,使模型具有更强的学习能力。











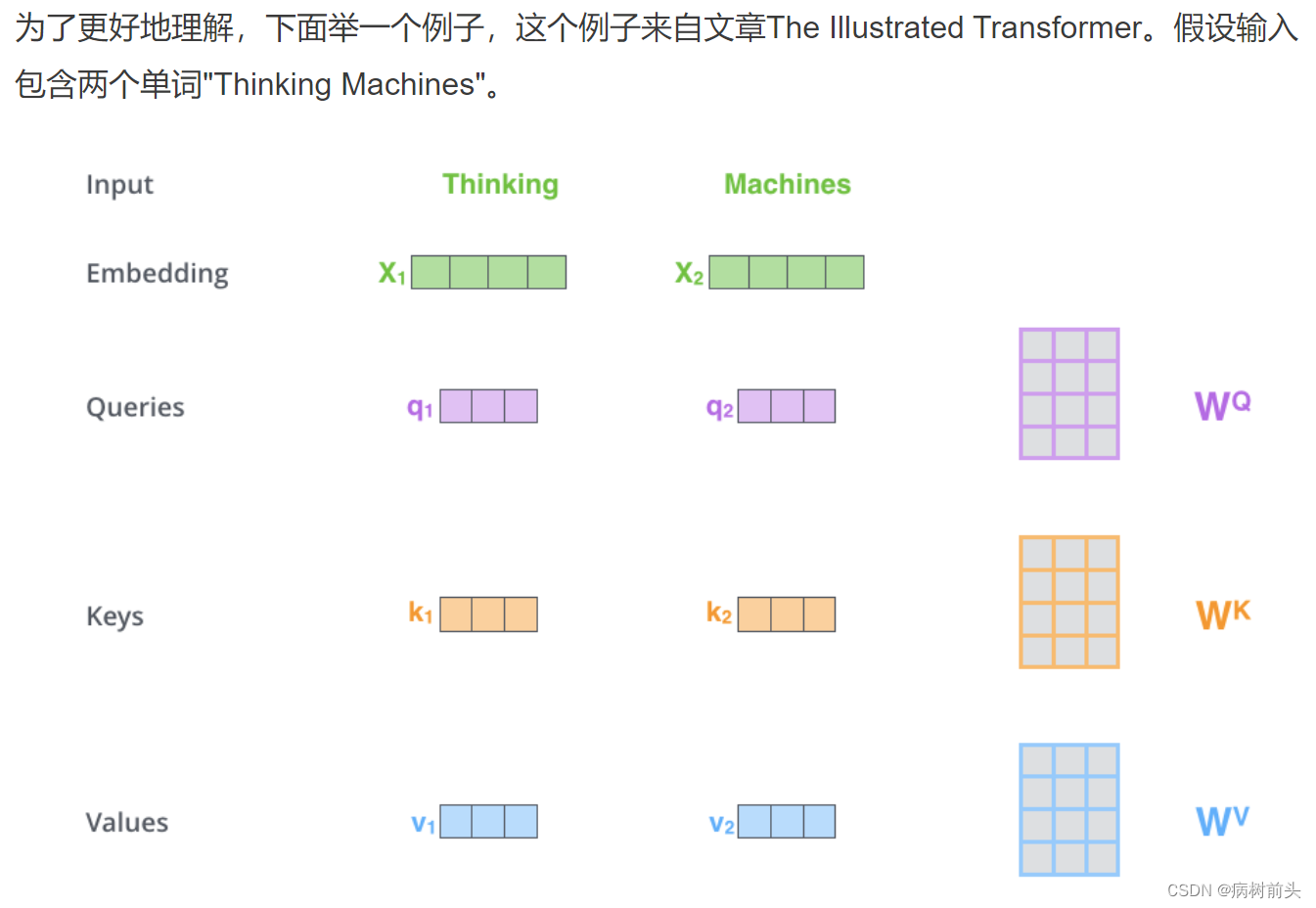
计算自注意力的第一步就是,为编码器层的每个输入,都创建三个向量,分别是query向量,key向量和value向量。正如我们上面所说,每个向量都是乘上一个权重矩阵得到的,这些权重矩阵是随模型一起训练的。进行线性映射的目的是转换向量的维度,转换成一个更小的维度。原文中是将512维转换为64 6464维。

第二步是计算注意力得分,假设我们想计算单词“Thinking”的注意力得分,我们需要对输入序列中的所有单词(包括自身)都进行某个操作。得到单词“Thinking”对于输入序列中每个单词的注意力得分,如果某个位置的得分越大,那么在生成编码时就越需要考虑这个位置。或者说注意力就是衡量q和k的相关性,相关性越大,那么在得到最终输出时,k对应的v在生成输出时贡献也越大。
那么这里所说的操作是什么呢?其实很简单,就是点乘。表示两个向量在多大程度上指向同一方向。类似余弦相似度,除了没有对向量的模进行归一化。
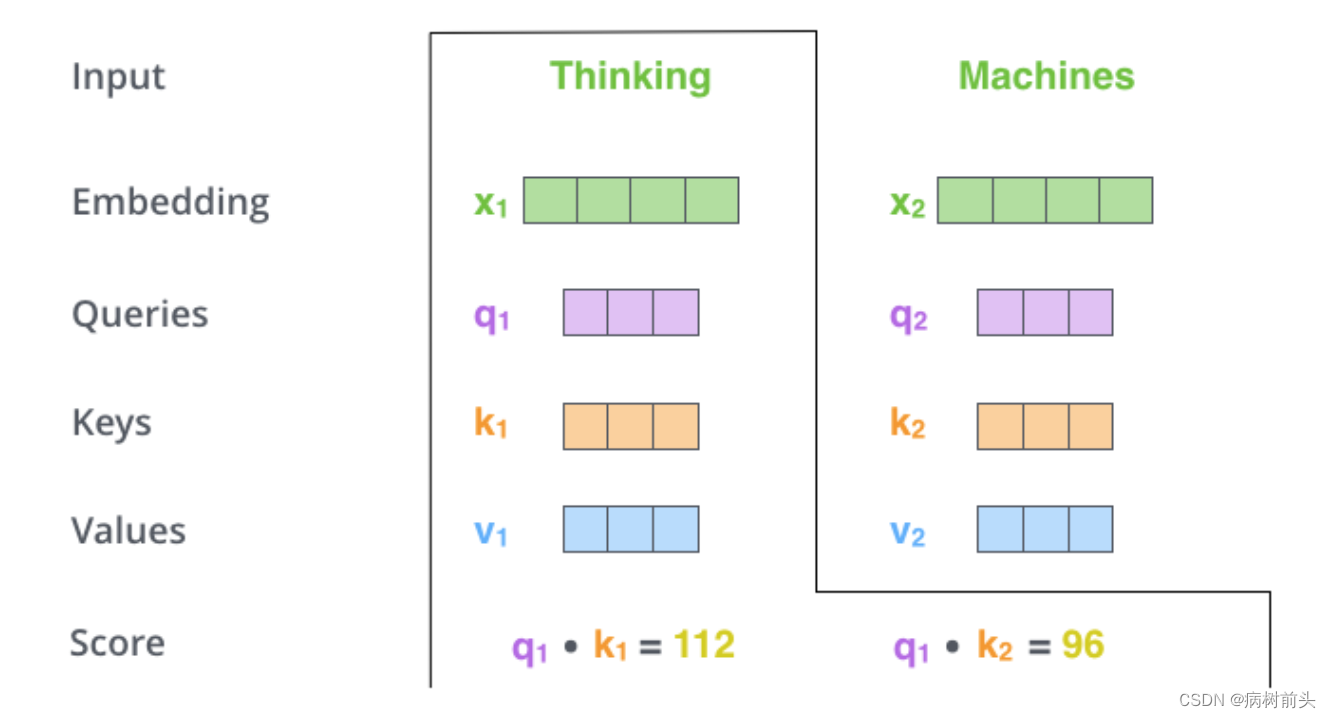

第三步和第四步 是进行进行缩放,然后经过softmax函数,使得每个得分都是正的,且总和为1。
经过Softmax之后的值就可以看成是一个权重了,也称为注意力权重。决定每个单词在生成这个位置的编码时能够共享多大程度。
第五步 用每个单词的value向量乘上对应的注意力权重。这一步用于保存我们想要注意单词的信息(给定一个很大的权重),而抑制我们不关心的单词信息(给定一个很小的权重)。
==第六步 累加第五步的结果,得到一个新的向量,也就是自注意力层在这个位置(这里是对于第一个单词“Thinking”来说)的输出。==举一个极端的例子,假设某个单词的权重非常大,比如是1,其他单词都是0,那么这一步的输出就是该单词对应的value向量。
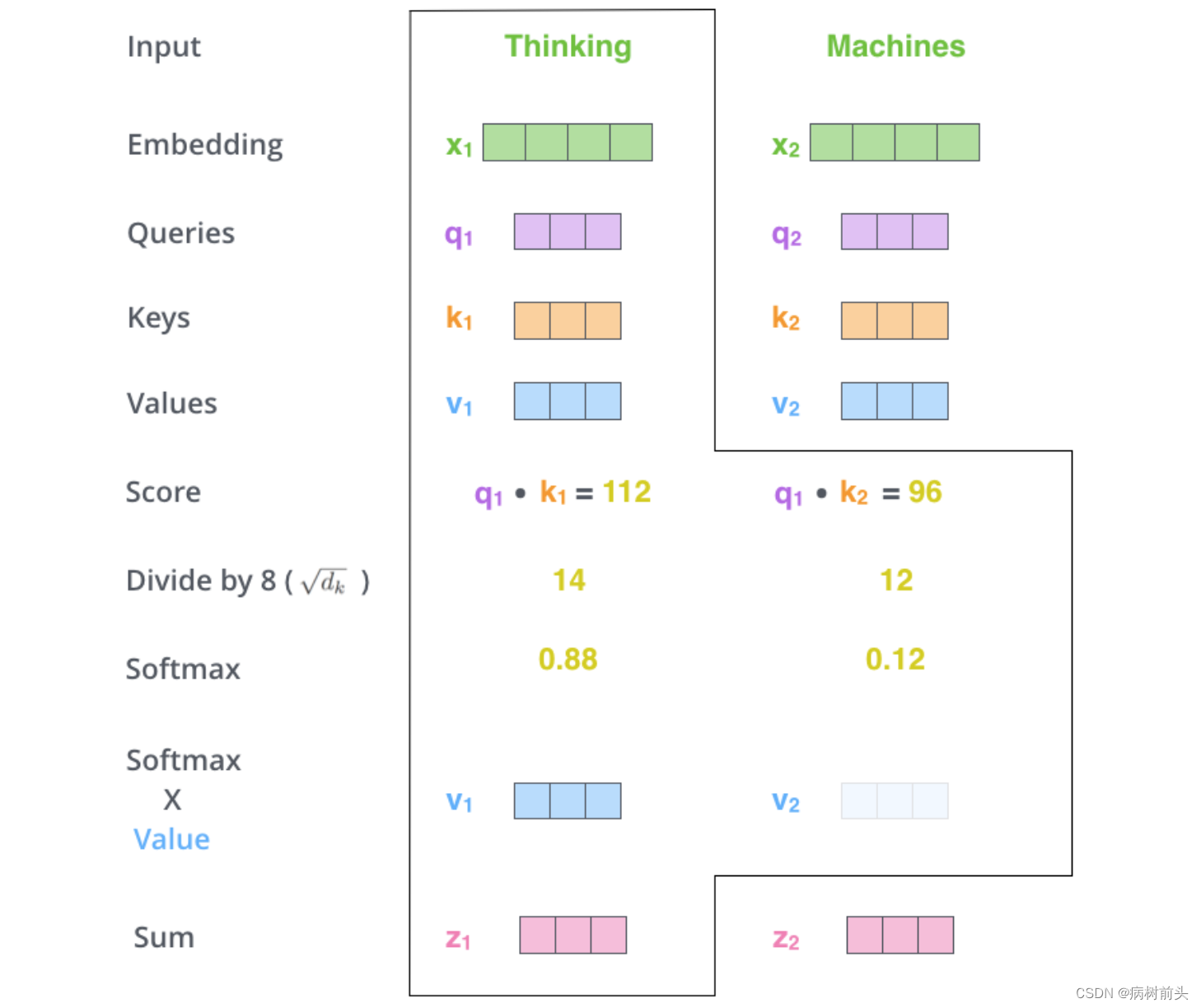
这就是计算第一个单词的自注意力输出完整过程。自注意力层的魅力在于,计算所有单词的输出可以通过矩阵运算一次完成。
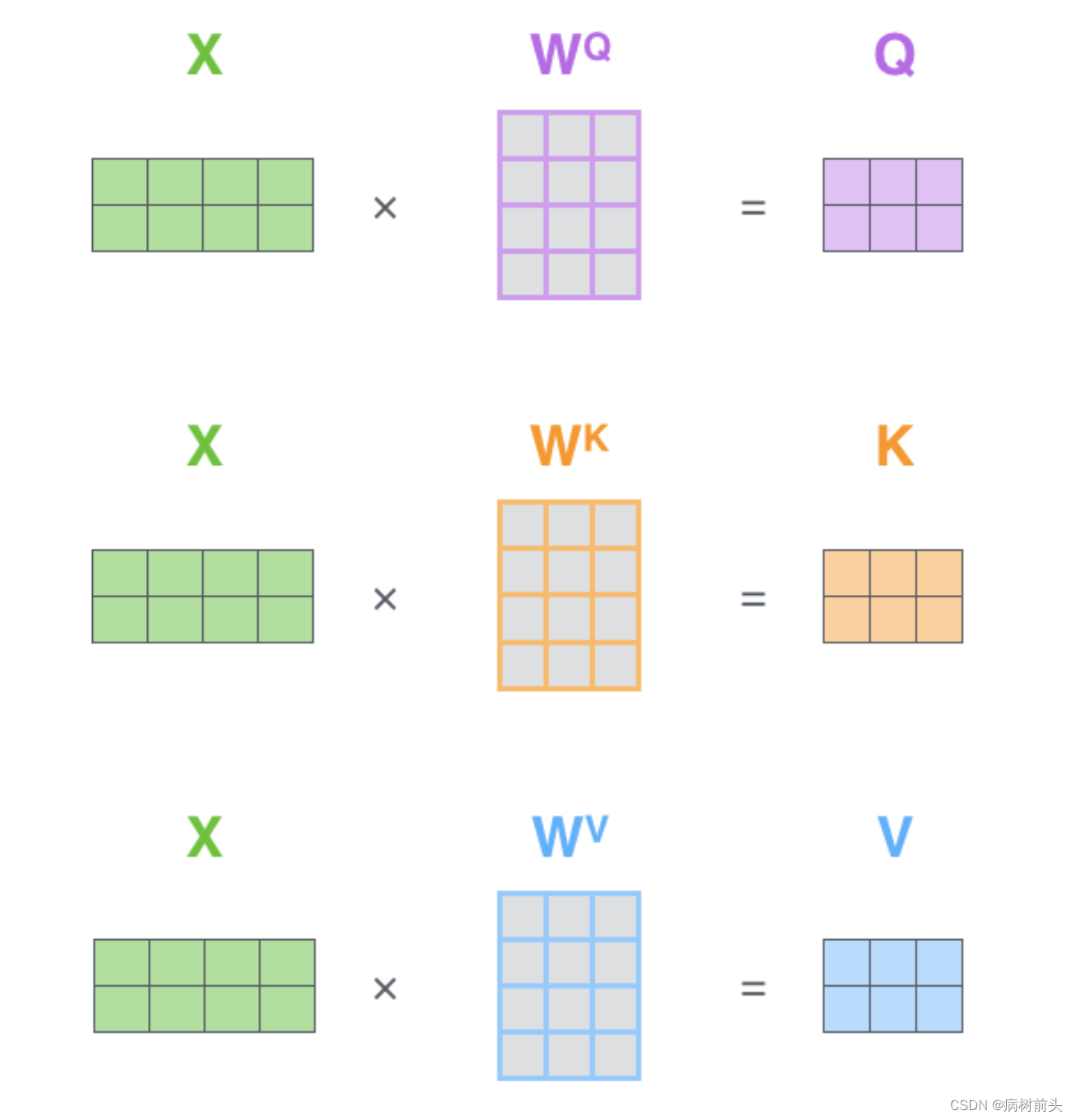

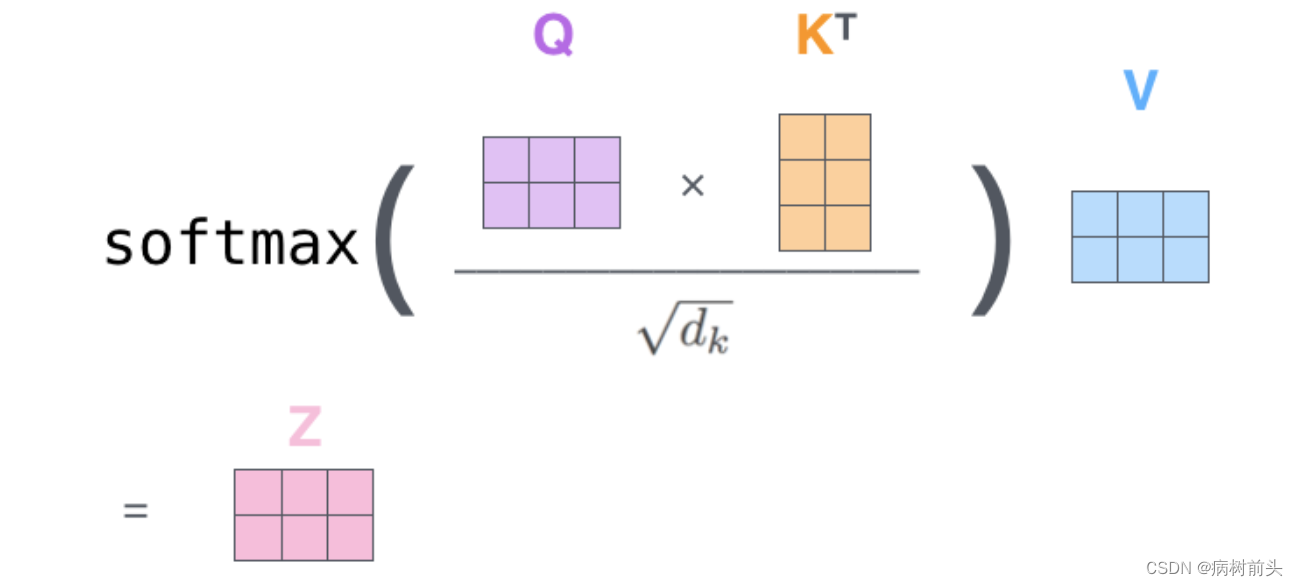

多头注意力
上面介绍的缩放点积注意力把原始的x映射到不同的空间后,去做注意力。每次映射相当于是在特定空间中去建模特定的语义交互关系,类似卷积中的多通道可以得到多个特征图,那么多个注意力可以得到多个不同方面的语义交互关系。可以让模型更好地关注到不同位置的信息,捕捉到输入序列中不同依赖关系和语义信息。有助于处理长序列、解决语义消歧、句子表示等任务,提高模型的建模能力。

得到这些多头注意力的组合以后,再把它们拼接起来,然后通过一个线性变化映射回原来的维度,保证输入和输出的维度一致。

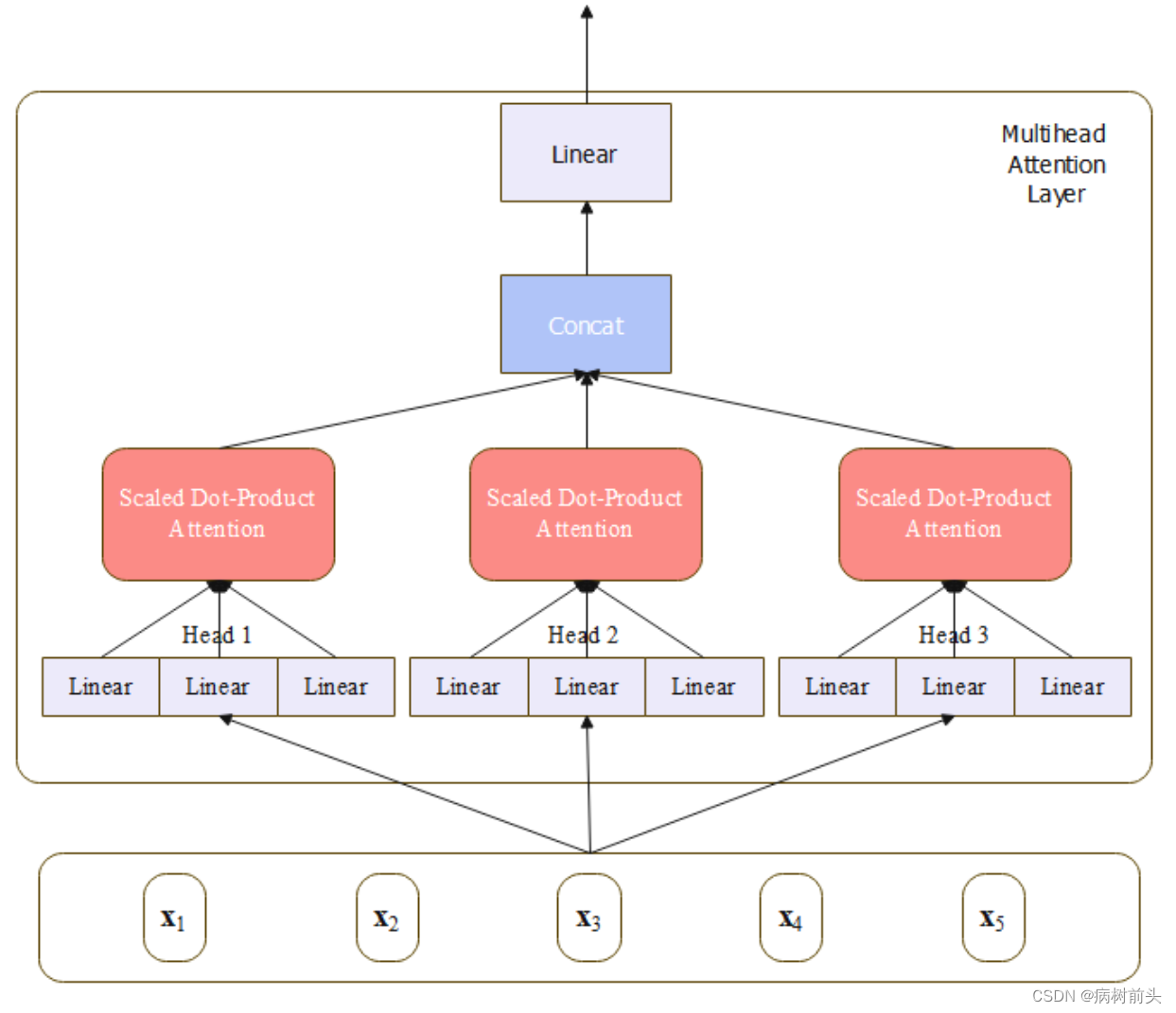

class MultiHeadAttention(nn.Module):
def __init__(
self,
d_model: int = 512,
n_heads: int = 8,
dropout: float = 0.1,
) -> None:
"""
Args:
d_model (int, optional): dimension of embeddings. Defaults to 512.
n_heads (int, optional): number of self attention heads. Defaults to 8.
dropout (float, optional): dropout ratio. Defaults to 0.1.
"""
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_keys = d_model // n_heads # dimension of every head
self.q = nn.linear(d_model, d_model) # query matrix
self.k = nn.linear(d_model, d_model) # key matrix
self.v = nn.linear(d_model, d_model) # value matrix
self.concat = nn.linear(d_model, d_model) #output
self.dropout = nn.Dropout(dropout)
def split_heads(self, x:Tensor, is_key:bool = False) -> Tensor:
batch_size = x.size(0)
# x(batch_size, seq_len, n_heads, d_key)
x = x.view(batch_size, -1, self.n_heads, self.d_keys)
if is_key:
# (batch_size, n_heads, d_key, seq_len)
return x.permute(0, 1, 2, 3)
# (batch_size, n_heads, seq_len, d_key)
return x.transpose(1, 2)
def merge_heads(self, x:Tensor) -> Tensor:
x = x.transpose(1, 2).contiguous().view(x.size(0), -1, self.d_model)
return x
def attention(
self,
query: Tensor,
key: Tensor,
value: Tensor,
mask: Tensor = None,
keep_attentions: bool = False,
):
scores = torch.matmul(query, key) / math.sqrt(self.d_key)
if mask is not None:
# Fill those positions of product as -1e9 where mask positions are 0, because exp(-1e9) will get zero.
# Note that we cannot set it to negative infinity, as there may be a situation where nagative infinity is divided by negative infinity.
scores = scores.masked_fill(mask == 0, -1e9)
# weights (batch_size, n_heads, q_length, k_length)
weights = self.dropout(torch.softmax(scores, dim=-1))
# (batch_size, n_heads, q_length, k_length) x (batch_size, n_heads, v_length, d_key) -> (batch_size, n_heads, q_length, d_key)
# assert k_length == v_length
# attn_ouput (batch_size, n_heads, q_length, d_key)
attn_ouput = torch.matmul(weights, value)
if keep_attentions:
self.weights = weights
else:
del weights
return attn_ouput
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
mask: Tensor = None,
keep_attentions: bool = False,
) -> Tuple[Tensor, Tensor]:
"""
Args:
query(Tensor): (batch_size, q_length, d_model)
key(Tensor): (batch_size, k_length, d_model)
value(Tensor): (batch_size, v_length, d_model)
mask(Tensor, optional): mask for padding or decoder. Defaults to None.
keep_attentions(bool): whether keep attention weigths or not. Defaults to Flase.
Returns:
output(Tensor): (batch_size, q_length, d_model) attention output
"""
query, key, value = self.q(query), self.k(key), self.v(value)
query, key, value =(
self.split_heads(query),
self.split_heads(key, is_key=True)
self.split_heads(value),
)
attn_output = self.attention(query, key, value, mask, keep_attentions)
del query
del key
del value
# Concat
concat_output = self.merge_heads(attn_output)
# the final linear
# output (batch_szie, q_length, d_model)
output = self.concat(concat_output)
return output
在forward()中,首先利用三个线性变换分别计算query,key,value矩阵(后续文章GPT实现中可以看到这个三个线性编变换也可以合并成一个)。接着拆分成多个头,传给attention()计算多头注意力,通过keep_attentions参数可以指定是否保存注意力权重,后续可以进行观察。然后合并多头注意力的结果。最后经过一个用作拼接的线性层。
注意力这里的拆分和合并其实都是reshape操作,在代码的最后删除掉不需要的引用,以帮助GC释放GPU缓存。
![[消息队列 Kafka] Kafka 架构组件及其特性(一)](https://img-blog.csdnimg.cn/direct/c8e30fa3f57e454c9bb945d71fc3dac8.png)