mmdetection的生物图像实例分割全流程记录
第二章 自定义数据集注册与模型训练
文章目录
- mmdetection的生物图像实例分割全流程记录
- 前言
- 一、数据集的注册
- 1.数据集的基本信息引入
- 2.数据集base路径的更改
- 3.数据集的评估
- 二、配置文件更改
- 1.数据集任务配置
- 2.模型配置
- 3.训练过程配置
- 4.训练计划配置
- 三、结果
前言
mmdetection是一个比较容易入门且上手的深度学习检测框架,其官网为https://github.com/open-mmlab/mmdetection,相关文档https://mmdetection.readthedocs.io/zh-cn/latest/overview.html。
我们默认机器上意见安装完成该框架,并能实现文档中的demo。我安装的版本是mmdetection 3.3.0.这里可供借鉴。

一、数据集的注册
1.数据集的基本信息引入
找到文件位置:mmdet/datasets/coco.py,复制为mmdet/datasets/ac3ac4.py,并进行如下更改,这里主要更改一下数据集的名称以及METAINFO信息:
# Copyright (c) OpenMMLab. All rights reserved.
import copy
import os.path as osp
from typing import List, Union
from mmengine.fileio import get_local_path
from mmdet.registry import DATASETS
from .api_wrappers import COCO
from .base_det_dataset import BaseDetDataset
@DATASETS.register_module()
class ac3ac4Dataset(BaseDetDataset):
"""Dataset for AC3AC4."""
METAINFO = {
'classes':
('synapse', ),
# palette is a list of color tuples, which is used for visualization.
'palette':
[(220, 20, 60), ]
}
COCOAPI = COCO
# ann_id is unique in coco dataset.
ANN_ID_UNIQUE = True
# No changes are made later...
找到 mmdet/datasets/_init_.py,添加ac3ac4Dataset,这里注意是两个地方,一个是刚刚更改的ac3ac4.py文件的调用,另一个是__all__的名称引用:
# Copyright (c) OpenMMLab. All rights reserved.
from .ade20k import (ADE20KInstanceDataset, ADE20KPanopticDataset,
ADE20KSegDataset)
from .base_det_dataset import BaseDetDataset
from .base_semseg_dataset import BaseSegDataset
from .base_video_dataset import BaseVideoDataset
from .cityscapes import CityscapesDataset
from .coco import CocoDataset
from .ac3ac4 import ac3ac4Dataset
from .coco_caption import CocoCaptionDataset
from .coco_panoptic import CocoPanopticDataset
from .coco_semantic import CocoSegDataset
from .crowdhuman import CrowdHumanDataset
from .dataset_wrappers import ConcatDataset, MultiImageMixDataset
from .deepfashion import DeepFashionDataset
from .dod import DODDataset
from .dsdl import DSDLDetDataset
from .flickr30k import Flickr30kDataset
from .isaid import iSAIDDataset
from .lvis import LVISDataset, LVISV1Dataset, LVISV05Dataset
from .mdetr_style_refcoco import MDETRStyleRefCocoDataset
from .mot_challenge_dataset import MOTChallengeDataset
from .objects365 import Objects365V1Dataset, Objects365V2Dataset
from .odvg import ODVGDataset
from .openimages import OpenImagesChallengeDataset, OpenImagesDataset
from .refcoco import RefCocoDataset
from .reid_dataset import ReIDDataset
from .samplers import (AspectRatioBatchSampler, ClassAwareSampler,
CustomSampleSizeSampler, GroupMultiSourceSampler,
MultiSourceSampler, TrackAspectRatioBatchSampler,
TrackImgSampler)
from .utils import get_loading_pipeline
from .v3det import V3DetDataset
from .voc import VOCDataset
from .wider_face import WIDERFaceDataset
from .xml_style import XMLDataset
from .youtube_vis_dataset import YouTubeVISDataset
__all__ = [
'XMLDataset', 'CocoDataset', 'ac3ac4Dataset', 'DeepFashionDataset', 'VOCDataset',
'CityscapesDataset', 'LVISDataset', 'LVISV05Dataset', 'LVISV1Dataset',
'WIDERFaceDataset', 'get_loading_pipeline', 'CocoPanopticDataset',
'MultiImageMixDataset', 'OpenImagesDataset', 'OpenImagesChallengeDataset',
'AspectRatioBatchSampler', 'ClassAwareSampler', 'MultiSourceSampler',
'GroupMultiSourceSampler', 'BaseDetDataset', 'CrowdHumanDataset',
'Objects365V1Dataset', 'Objects365V2Dataset', 'DSDLDetDataset',
'BaseVideoDataset', 'MOTChallengeDataset', 'TrackImgSampler',
'ReIDDataset', 'YouTubeVISDataset', 'TrackAspectRatioBatchSampler',
'ADE20KPanopticDataset', 'CocoCaptionDataset', 'RefCocoDataset',
'BaseSegDataset', 'ADE20KSegDataset', 'CocoSegDataset',
'ADE20KInstanceDataset', 'iSAIDDataset', 'V3DetDataset', 'ConcatDataset',
'ODVGDataset', 'MDETRStyleRefCocoDataset', 'DODDataset',
'CustomSampleSizeSampler', 'Flickr30kDataset'
]
2.数据集base路径的更改
在路径下复制configs/_base_/datasets/coco_instance.py为configs/_base_/datasets/ac3ac4_instance.py,并进行更改
# dataset settings
dataset_type = 'ac3ac4Dataset'
data_root = 'Path/to/your/DataCOCO/AC3AC4/'
# Example to use different file client
# Method 1: simply set the data root and let the file I/O module
# automatically infer from prefix (not support LMDB and Memcache yet)
# data_root = 's3://openmmlab/datasets/detection/coco/'
# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
# backend_args = dict(
# backend='petrel',
# path_mapping=dict({
# './data/': 's3://openmmlab/datasets/detection/',
# 'data/': 's3://openmmlab/datasets/detection/'
# }))
backend_args = None
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', scale=(1024, 1024), keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(type='PackDetInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='Resize', scale=(1024, 1024), keep_ratio=True),
# If you don't have a gt annotation, delete the pipeline
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=2,
num_workers=2,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=dict(type='AspectRatioBatchSampler'),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=train_pipeline,
backend_args=backend_args))
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/'),
test_mode=True,
pipeline=test_pipeline,
backend_args=backend_args))
test_dataloader = val_dataloader
val_evaluator = dict(
type='CocoMetric',
ann_file=data_root + 'annotations/instances_val2017.json',
metric=['bbox', 'segm'],
format_only=False,
backend_args=backend_args)
test_evaluator = val_evaluator
# inference on test dataset and
# format the output results for submission.
test_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file=data_root + 'annotations/instances_test2017.json',
data_prefix=dict(img='test2017/'),
test_mode=True,
pipeline=test_pipeline))
test_evaluator = dict(
type='CocoMetric',
metric=['bbox', 'segm'],
format_only=True,
ann_file=data_root + 'annotations/instances_test2017.json',
outfile_prefix='./work_dirs/ac3ac4_instance/test')
3.数据集的评估
在mmdet/evaluation/functional/class_names.py路径下加入:
def ac3ac4_classes() -> list:
"""Class names of AC3AC4."""
return [
'synapse',
]
同时,更改mmdet/evaluation/functional/_init_.py,加入文件调用以及字段引用:
# Copyright (c) OpenMMLab. All rights reserved.
from .bbox_overlaps import bbox_overlaps
from .cityscapes_utils import evaluateImgLists
from .class_names import (cityscapes_classes, coco_classes, ac3ac4_classes,
coco_panoptic_classes, dataset_aliases, get_classes,
imagenet_det_classes, imagenet_vid_classes,
objects365v1_classes, objects365v2_classes,
oid_challenge_classes, oid_v6_classes, voc_classes)
from .mean_ap import average_precision, eval_map, print_map_summary
from .panoptic_utils import (INSTANCE_OFFSET, pq_compute_multi_core,
pq_compute_single_core)
from .recall import (eval_recalls, plot_iou_recall, plot_num_recall,
print_recall_summary)
from .ytvis import YTVIS
from .ytviseval import YTVISeval
__all__ = [
'voc_classes', 'imagenet_det_classes', 'imagenet_vid_classes',
'coco_classes', 'ac3ac4_classes', 'cityscapes_classes', 'dataset_aliases', 'get_classes',
'average_precision', 'eval_map', 'print_map_summary', 'eval_recalls',
'print_recall_summary', 'plot_num_recall', 'plot_iou_recall',
'oid_v6_classes', 'oid_challenge_classes', 'INSTANCE_OFFSET',
'pq_compute_single_core', 'pq_compute_multi_core', 'bbox_overlaps',
'objects365v1_classes', 'objects365v2_classes', 'coco_panoptic_classes',
'evaluateImgLists', 'YTVIS', 'YTVISeval'
]
这样数据集就完成了注册。
二、配置文件更改
对于一个完整的训练,我们先看一下训练文件,将tools/train.py复制为tools/ac3ac4.py,并设置一下相关的配置。
这里我们使用Mask R-CNN为例,
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
import os.path as osp
from mmengine.config import Config, DictAction
from mmengine.registry import RUNNERS
from mmengine.runner import Runner
from mmdet.utils import setup_cache_size_limit_of_dynamo
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
def parse_a
rgs():
parser = argparse.ArgumentParser(description='Train a detector')
parser.add_argument('--config', default='/home/guojy2/share/guojy/ProjectCodes/openmmlab3/mmdetection/mmdet/configs/mask_rcnn/mask_rcnn_r50_fpn_2x_ac3ac4.py',
help='train config file path')
parser.add_argument('--work-dir', default='/home/guojy2/share/guojy/SynDet2024/DataLog/AC3AC4/MRCNN/', help='the dir to save logs and models')
# No changes are made later...
我们的配置文件是mmdet/configs/mask_rcnn/mask_rcnn_r50_fpn_2x_ac3ac4.py,这个我是复制了mmdet/configs/mask_rcnn/mask_rcnn_r50_fpn_2x_coco.py,具体内容如下:
# Copyright (c) OpenMMLab. All rights reserved.
# Please refer to https://mmengine.readthedocs.io/en/latest/advanced_tutorials/config.html#a-pure-python-style-configuration-file-beta for more details. # noqa
# mmcv >= 2.0.1
# mmengine >= 0.8.0
from mmengine.config import read_base
with read_base():
from .._base_.datasets.ac3ac4_instance import *
from .._base_.default_runtime_mrcnn import *
from .._base_.models.mask_rcnn_r50_fpn_syn import *
from .._base_.schedules.schedule_2x_300 import *
可以看到它包含了四个文件:数据集的任务配置,训练过程配置,模型配置以及训练计划配置,这里进行一一阐述:
1.数据集任务配置
将mmdet/configs/base/datasets/coco_instance.py复制为mmdet/configs/base/datasets/ac3ac3_instance.py
这里主要更改数据集的名称 dataset_type ,数据集的路径 data_root 以及图像大小尺寸(1024, 1024):
# Copyright (c) OpenMMLab. All rights reserved.
from mmcv.transforms.loading import LoadImageFromFile
from mmengine.dataset.sampler import DefaultSampler
# from mmdet.datasets.coco import CocoDataset
from mmdet.datasets.ac3ac4 import ac3ac4Dataset
from mmdet.datasets.samplers.batch_sampler import AspectRatioBatchSampler
from mmdet.datasets.transforms.formatting import PackDetInputs
from mmdet.datasets.transforms.loading import LoadAnnotations
from mmdet.datasets.transforms.transforms import RandomFlip, Resize
from mmdet.evaluation.metrics.coco_metric import CocoMetric
# dataset settings
dataset_type = 'ac3ac4Dataset'
data_root = 'Path/to/your/DataCOCO/AC3AC4/'
backend_args = None
train_pipeline = [
dict(type=LoadImageFromFile, backend_args=backend_args),
dict(type=LoadAnnotations, with_bbox=True, with_mask=True),
dict(type=Resize, scale=(1024, 1024), keep_ratio=True),
dict(type=RandomFlip, prob=0.5),
dict(type=PackDetInputs)
]
test_pipeline = [
dict(type=LoadImageFromFile, backend_args=backend_args),
dict(type=Resize, scale=(1024, 1024), keep_ratio=True),
# If you don't have a gt annotation, delete the pipeline
dict(type=LoadAnnotations, with_bbox=True, with_mask=True),
dict(
type=PackDetInputs,
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=2,
num_workers=2,
persistent_workers=True,
sampler=dict(type=DefaultSampler, shuffle=True),
batch_sampler=dict(type=AspectRatioBatchSampler),
dataset=dict(
type=ac3ac4Dataset,
data_root=data_root,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=train_pipeline,
backend_args=backend_args))
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type=DefaultSampler, shuffle=False),
dataset=dict(
type=ac3ac4Dataset,
data_root=data_root,
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/'),
test_mode=True,
pipeline=test_pipeline,
backend_args=backend_args))
test_dataloader = val_dataloader
val_evaluator = dict(
type=CocoMetric,
ann_file=data_root + 'annotations/instances_val2017.json',
metric=['bbox', 'segm'],
format_only=False,
backend_args=backend_args)
test_evaluator = val_evaluator
# inference on test dataset and
# format the output results for submission.
test_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type=DefaultSampler, shuffle=False),
dataset=dict(
type=ac3ac4Dataset,
data_root=data_root,
ann_file=data_root + 'annotations/instances_test2017.json',
data_prefix=dict(img='test2017/'),
test_mode=True,
pipeline=test_pipeline))
test_evaluator = dict(
type=CocoMetric,
metric=['bbox', 'segm'],
format_only=True,
ann_file=data_root + 'annotations/instances_test2017.json',
outfile_prefix='./work_dirs/ac3ac4_instance/test')
2.模型配置
这里主要更改模型的权重路径,以及num_classes。神经元突触的实例分割是单个类别,因此为1.
# Copyright (c) OpenMMLab. All rights reserved.
from mmcv.ops import RoIAlign, nms
from mmengine.model.weight_init import PretrainedInit
from torch.nn import BatchNorm2d
from mmdet.models.backbones.resnet import ResNet
from mmdet.models.data_preprocessors.data_preprocessor import \
DetDataPreprocessor
from mmdet.models.dense_heads.rpn_head import RPNHead
from mmdet.models.detectors.mask_rcnn import MaskRCNN
from mmdet.models.losses.cross_entropy_loss import CrossEntropyLoss
from mmdet.models.losses.smooth_l1_loss import L1Loss
from mmdet.models.necks.fpn import FPN
from mmdet.models.roi_heads.bbox_heads.convfc_bbox_head import \
Shared2FCBBoxHead
from mmdet.models.roi_heads.mask_heads.fcn_mask_head import FCNMaskHead
from mmdet.models.roi_heads.roi_extractors.single_level_roi_extractor import \
SingleRoIExtractor
from mmdet.models.roi_heads.standard_roi_head import StandardRoIHead
from mmdet.models.task_modules.assigners.max_iou_assigner import MaxIoUAssigner
from mmdet.models.task_modules.coders.delta_xywh_bbox_coder import \
DeltaXYWHBBoxCoder
from mmdet.models.task_modules.prior_generators.anchor_generator import \
AnchorGenerator
from mmdet.models.task_modules.samplers.random_sampler import RandomSampler
# model settings
model = dict(
type=MaskRCNN,
data_preprocessor=dict(
type=DetDataPreprocessor,
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_mask=True,
pad_size_divisor=32),
backbone=dict(
type=ResNet,
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type=BatchNorm2d, requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(
type=PretrainedInit, checkpoint='Path/to/your/pretrain/resnet50-0676ba61.pth')),
neck=dict(
type=FPN,
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type=RPNHead,
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type=AnchorGenerator,
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type=DeltaXYWHBBoxCoder,
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type=CrossEntropyLoss, use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type=L1Loss, loss_weight=1.0)),
roi_head=dict(
type=StandardRoIHead,
bbox_roi_extractor=dict(
type=SingleRoIExtractor,
roi_layer=dict(type=RoIAlign, output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type=Shared2FCBBoxHead,
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=1,
bbox_coder=dict(
type=DeltaXYWHBBoxCoder,
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type=CrossEntropyLoss, use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type=L1Loss, loss_weight=1.0)),
mask_roi_extractor=dict(
type=SingleRoIExtractor,
roi_layer=dict(type=RoIAlign, output_size=14, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type=FCNMaskHead,
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=1,
loss_mask=dict(
type=CrossEntropyLoss, use_mask=True, loss_weight=1.0))),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type=MaxIoUAssigner,
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type=RandomSampler,
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type=nms, iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type=MaxIoUAssigner,
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type=RandomSampler,
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
mask_size=28,
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type=nms, iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type=nms, iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5)))
3.训练过程配置
复制 mmdet/configs/base/default_runtime.py为mmdet/configs/base/default_runtime_mrcnn.py,这里可以添加hook,或者增加官网的预训练模型。我这里还设置了根据coco/bbox_mAP_50保存最佳模型。
# Copyright (c) OpenMMLab. All rights reserved.
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
LoggerHook, ParamSchedulerHook)
from mmengine.runner import LogProcessor
from mmengine.visualization import LocalVisBackend
from mmdet.engine.hooks import DetVisualizationHook
from mmdet.visualization import DetLocalVisualizer
default_scope = None
default_hooks = dict(
timer=dict(type=IterTimerHook),
logger=dict(type=LoggerHook, interval=50),
param_scheduler=dict(type=ParamSchedulerHook),
checkpoint=dict(type=CheckpointHook, interval=1,
max_keep_ckpts=1, save_best='coco/bbox_mAP_50'),
sampler_seed=dict(type=DistSamplerSeedHook),
visualization=dict(type=DetVisualizationHook))
env_cfg = dict(
cudnn_benchmark=False,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'),
)
vis_backends = [dict(type=LocalVisBackend)]
visualizer = dict(
type=DetLocalVisualizer, vis_backends=vis_backends, name='visualizer')
log_processor = dict(type=LogProcessor, window_size=50, by_epoch=True)
log_level = 'INFO'
load_from = 'Path/to/your/pretrain/mask_rcnn_r50_fpn_mstrain-poly_3x_coco_20210524_201154-21b550bb.pth'
resume = False
4.训练计划配置
复制mmdet/configs/base/schedules/schedule_2x.py为mmdet/configs/base/schedules/schedule_2x_300.py,这里主要更改了训练的epoch数量,这里改为了300。
# Copyright (c) OpenMMLab. All rights reserved.
from mmengine.optim.optimizer.optimizer_wrapper import OptimWrapper
from mmengine.optim.scheduler.lr_scheduler import LinearLR, MultiStepLR
from mmengine.runner.loops import EpochBasedTrainLoop, TestLoop, ValLoop
from torch.optim.sgd import SGD
# training schedule for 1x
train_cfg = dict(type=EpochBasedTrainLoop, max_epochs=300, val_interval=1)
val_cfg = dict(type=ValLoop)
test_cfg = dict(type=TestLoop)
# learning rate
param_scheduler = [
dict(type=LinearLR, start_factor=0.001, by_epoch=False, begin=0, end=500),
dict(
type=MultiStepLR,
begin=0,
end=300,
by_epoch=True,
milestones=[16, 22],
gamma=0.1)
]
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
optimizer=dict(type=SGD, lr=0.02, momentum=0.9, weight_decay=0.0001))
# Default setting for scaling LR automatically
# - `enable` means enable scaling LR automatically
# or not by default.
# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
auto_scale_lr = dict(enable=False, base_batch_size=16)
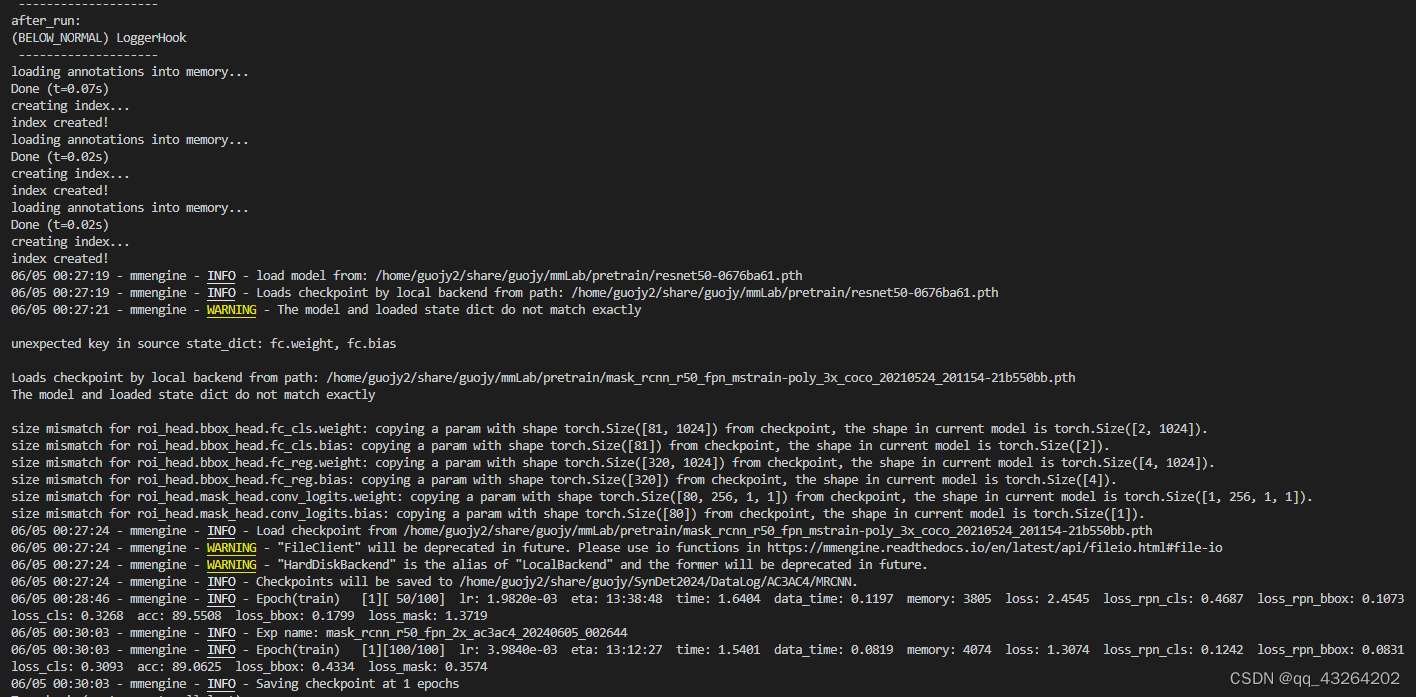
三、结果
成功训练: