大模型成本到底有多大,大到太平洋装不下。
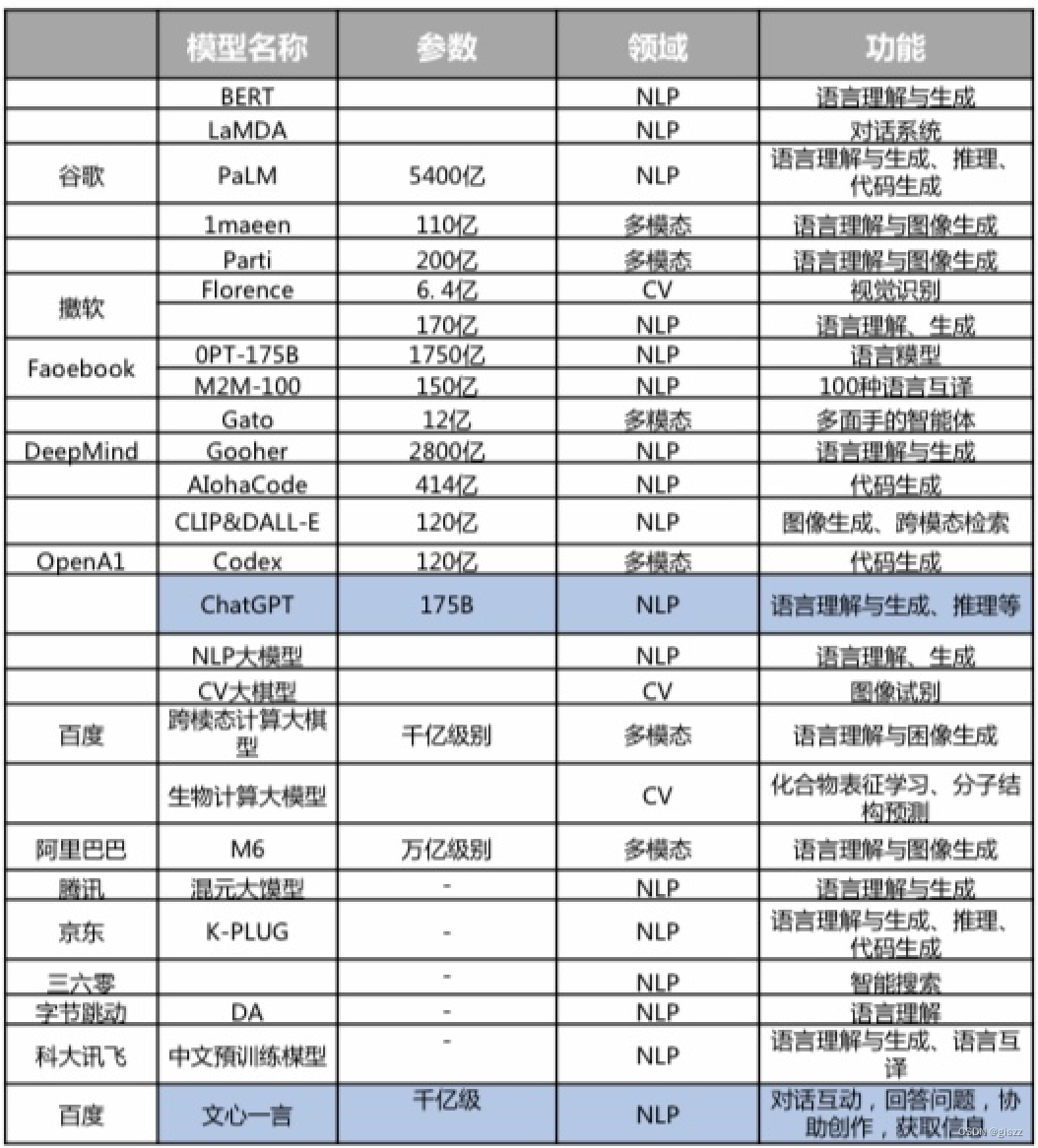
上图是早前统计的,目前比较流行的大模型的厂家、模型名称、参数级别和类型。
大模型的成本主要有三块,分别是训练成本、推理成本、储存成本。
大模型的成本确实主要涉及训练成本、推理成本和储存成本。以下是对这三块成本的详细阐述:
1. 训练成本
- 用途:训练成本主要用于大模型的学习过程。这包括通过大量数据进行模型的权重和参数的调整,以使模型能够准确地执行其设计任务,如语言理解、生成或推理等。
- 量级:训练成本通常非常高。例如,GPT-3的单次训练成本据估算高达140万美元,而对于更大的大型语言模型(LLM),训练成本可能介于200万美元至1200万美元之间。这些成本主要来自于强大的计算资源消耗,特别是GPU的使用,以及大量的电力消耗。GPT-3的训练耗电量高达1287兆瓦时。
2. 推理成本
- 用途:推理成本是指在模型部署后,使用模型进行预测或生成内容时的成本。这包括处理用户输入、运行模型以产生输出以及将结果返回给用户等过程。
- 量级:推理成本根据模型的大小和复杂度以及用户请求的频率而有所不同。对于大型模型,如GPT系列,由于其庞大的参数量和计算需求,推理成本可能相对较高。然而,具体的成本数据通常因应用场景和部署环境的差异而难以一概而论。
3. 储存成本
- 用途:储存成本涉及保存和维护大模型所需的数据存储资源。这包括保存模型的权重、参数、训练数据以及可能的中间结果等。
- 量级:随着模型规模的增大,存储需求也显著增加。例如,GPT-3等大型模型的参数量巨大,需要相应的存储空间来保存。此外,训练过程中产生的中间数据和实验结果也可能占用大量的存储空间。具体的储存成本取决于所使用的存储技术和规模,但通常是一个不可忽视的开支项。
比如
- GPT-3:作为一个具有1750亿参数的大型语言模型,GPT-3的训练成本高达140万美元(单次训练),并且其耗电量也非常惊人。在推理阶段,由于其庞大的模型大小,需要强大的计算资源来支持实时响应。同时,存储GPT-3的模型数据和相关训练数据也需要大量的存储空间。
- ChatGPT:作为基于GPT-3.5架构的生成式对话模型,ChatGPT同样面临高昂的训练、推理和存储成本。其训练成本可能与GPT-3相当或更高,因为它需要更多的数据和计算资源来优化对话生成能力。在推理阶段,ChatGPT需要实时处理用户输入并生成相应的回复,这同样需要强大的计算支持。同时,为了提供持续的服务和改进模型,ChatGPT还需要维护大量的用户对话数据和模型更新数据。
微软云服务,超过1万枚A100。
这里还有一个资料,分享给大家:
ChatGPT,每日需要30382个A100,需要3798个服务器,电费就要30万美元。
所以说,前几天有个朋友,拉着另外几个朋友,去做大模型创业了,据说也利用开源,跑起来一个大模型。后续也暂时找不到客户和场景。做别的更是不可能了。
PS,什么是A100,我替大家搜出来,收藏备用。
A100是英伟达(NVIDIA)推出的一款基于Ampere架构的高性能计算卡,主要面向数据中心和高性能计算领域。以下是关于A100芯片的详细介绍:
- 架构与制程:A100采用了英伟达的Ampere架构,这是全球首款基于7纳米工艺的数据中心GPU架构。
- 核心数量与性能:拥有高达6912个CUDA核心,为深度学习等计算密集型任务提供强大的计算能力。配备432个Tensor核心,支持Tensor Float 32(TF32)和混合精度(FP16)计算,显著提升深度学习训练和推理的速度。
- 显存容量与带宽:提供40GB、80GB甚至160GB的HBM2e高速显存选项,满足大规模数据集和高性能计算的需求。内存带宽高达2.5TB/s(部分版本为1.6 TB/s或2039 GB/s),有助于减少数据传输瓶颈,提升整体计算性能。
- 互联技术:支持第二代NVIDIA NVLink和PCIe 4.0,实现高速的GPU到GPU和GPU到CPU的数据传输。通过NVLink 3.0技术,可提供高达600GB/s的GPU间通信带宽,适用于大规模并行计算和分布式训练。
- 灵活性与扩展性:支持多GPU集群配置,可动态划分为多个GPU实例,根据实际需求进行调整。MIG技术允许将单个A100 GPU分割成最多7个独立的GPU实例,提高资源利用率。
- 软件生态系统支持:支持CUDA、cuDNN等深度学习优化库,以及TensorRT高性能推理库,为深度学习模型的训练和推理提供全面支持。