原文链接:(更好排版、视频播放、社群交流、最新AI开源项目、AI工具分享都在这个公众号!)
Verba:终极 RAG 引擎 - 语义搜索、嵌入、矢量搜索等!
🌟在本文中,我们将深入探讨 Verba,这是一款革命性的开源 rag 引擎。
使用 Verba,通过简单的几步操作,您可以轻松探索您的数据集并提取见解,无论是在本地使用 HuggingFace 和 Ollama,还是通过
OpenAI、Cohere 和 Google 等LLM提供商进行操作。

pip install goldenverba
什么是 Verba?
Verba
是一个完全可定制的个人助手,用于查询和与您的数据交互,无论是在本地还是通过云部署。解决文档中的问题,交叉引用多个数据点,或从现有知识库中获取见解。Verba
结合了最先进的 RAG 技术与 Weaviate 的上下文感知数据库。根据您的个人使用情况,在不同的 RAG 框架、数据类型、分块与检索技术以及 LLM
提供商之间进行选择。
功能列表
| 🤖 模型支持 | 实现情况 | 描述 |
|---|---|---|
| Ollama(如Llama3) | ✅ | 由 Ollama 提供的本地嵌入和生成模型 |
| HuggingFace(如MiniLMEmbedder) | ✅ | 由 HuggingFace 提供的本地嵌入模型 |
| Cohere(如Command R+) | ✅ | 由 Cohere 提供的嵌入和生成模型 |
| Google(如Gemini) | ✅ | 由 Google 提供的嵌入和生成模型 |
| OpenAI(如GPT4) | ✅ | 由 OpenAI 提供的嵌入和生成模型 |
| 📁 数据支持 | 实现情况 | 描述 |
| — | — | — |
| PDF 导入 | ✅ | 将 PDF 导入 Verba |
| CSV/XLSX 导入 | ✅ | 将表格数据导入 Verba |
| 多模态 | 计划中 ⏱️ | 将多模态数据导入 Verba |
| UnstructuredIO | ✅ | 通过 Unstructured 导入数据 |
| ✨ RAG 功能 | 实现情况 | 描述 |
| — | — | — |
| 混合搜索 | ✅ | 语义搜索与关键词搜索相结合 |
| 语义缓存 | ✅ | 基于语义意义保存和检索结果 |
| 自动补全建议 | ✅ | Verba 提供自动补全建议 |
| 过滤 | 计划中 ⏱️ | 执行 RAG 之前应用过滤器(如文档、文档类型等) |
| 高级查询 | 计划中 ⏱️ | 基于 LLM 评估的任务委派 |
| 重新排名 | 计划中 ⏱️ | 基于上下文重新排名结果以改进结果 |
| RAG 评估 | 计划中 ⏱️ | 用于评估 RAG 管道的界面 |
| 可自定义元数据 | 计划中 ⏱️ | 对元数据的自由控制 |
| 🆒 额外功能 | 实现情况 | 描述 |
| — | — | — |
| Docker 支持 | ✅ | Verba 可通过 Docker 部署 |
| 可定制前端 | ✅ | Verba 的前端完全可定制 |
| 🤝 RAG 库 | 实现情况 | 描述 |
| — | — | — |
| Haystack | 计划中 ⏱️ | 实现 Haystack RAG 管道 |
| LlamaIndex | 计划中 ⏱️ | 实现 LlamaIndex RAG 管道 |
| LangChain | 计划中 ⏱️ | 实现 LangChain RAG 管道 |
缺少什么内容?欢迎创建新问题或讨论您的想法!

Verba入门指南
您有三种部署 Verba 的选项:
-
• 通过 pip 安装
pip install goldenverba
-
• 从源码构建
git clone https://github.com/weaviate/Verba
pip install -e .
-
• 使用 Docker 进行部署
前提条件 :如果您不使用 Docker,请确保您的系统上安装了 Python >=3.10.0 。
如果您不熟悉 Python 和虚拟环境,请阅读 python 教程指南 。
API密钥
在启动 Verba 之前,您需要根据所选技术配置对各组件的访问,例如通过 .env 文件配置 OpenAI、Cohere 和 HuggingFace
的访问权限。在您要启动 Verba 的目录中创建此 .env 文件。您可以在 goldenverba 目录中找到 .env.example 文件。
请确保仅设置您打算使用的环境变量,缺少或不正确的环境变量值可能会导致错误。
以下是您可能需要的 API 密钥和变量的综合列表:
| 环境变量 | 值 | 描述 |
|---|---|---|
| WEAVIATE_URL_VERBA | 您的 Weaviate 集群的 URL | 连接到您的 WCS 集群 |
| WEAVIATE_API_KEY_VERBA | 您的 Weaviate 集群的 API 凭证 | 连接到您的 WCS 集群 |
| OPENAI_API_KEY | 您的 API 密钥 | 获取对 OpenAI 模型的访问权限 |
| OPENAI_BASE_URL | OpenAI 实例的 URL | 模型 |
| COHERE_API_KEY | 您的 API 密钥 | 获取对 Cohere 模型的访问权限 |
| OLLAMA_URL | 您的 Ollama 实例的 URL(例如:http://localhost:11434 ) | 获取对 Ollama |
| 模型的访问权限 | ||
| OLLAMA_MODEL | 模型名称(例如:llama) | 获取对特定 Ollama 模型的访问权限 |
| UNSTRUCTURED_API_KEY | 您的 API 密钥 | 获取对 Unstructured 数据导入的访问权限 |
| UNSTRUCTURED_API_URL | Unstructured 实例的 URL | 获取对 [Unstructured](https |
😕/docs.unstructured.io/welcome) 数据导入的访问权限 | | HUGGINGFACEHUB_API_TOKEN | 您的
API 密钥 | 获取对 HuggingFace 模型的访问权限 | | HUGGINGFACEHUB_BASE_URL | HuggingFace
实例的 URL(例如:https://api-inference.huggingface.co/)| 获取对特定 HuggingFace 模型的访问权限
| | GOOGLE_APPLICATION_CREDENTIALS | JSON 文件路径或直接的 JSON 字符串(例如:JSON 字符串) | 获取对
Google 模型的访问权限 |
如何通过pip部署
在安装了 Python >=3.10.0 的系统上执行以下步骤:
- 1. 安装
goldenverba包:
pip install goldenverba
- 1. 在 Verba 项目目录中创建
.env文件。您可以使用示例文件.env.example来设置环境变量。最少需要设置以下环境变量:
OPENAI_API_KEY=您在 OpenAI 注册的 API 密钥
- 1. 启动 Verba:
verba
如何从源码构建
在安装了 Python >=3.10.0 的系统上执行以下步骤:
- 1. 克隆 Verba 仓库并导航到该目录:
git clone https://github.com/weaviate/Verba
cd Verba
- 1. 安装
goldenverba包:
pip install -e .
- 1. 在 Verba 项目目录中创建
.env文件。您可以使用示例文件.env.example来设置环境变量。最少需要设置以下环境变量:
OPENAI_API_KEY=您在 OpenAI 注册的 API 密钥
- 1. 启动 Verba:
verba
如何通过Docker安装Verba
在安装了 Docker 的系统上执行以下步骤:
- 1. 在 Verba 项目目录中创建
.env文件。您可以使用示例文件.env.example来设置环境变量。最少需要设置以下环境变量:
OPENAI_API_KEY=您在 OpenAI 注册的 API 密钥
- 1. 运行 Docker 容器:
docker run --rm -it --env-file .env goldenverba
您可以通过
docker-compose文件来简化此过程。请参考 docker-compose 示例文件 。
💾 Verba演练
在成功安装 Verba 后,您可以通过以下步骤快速开始:
- 1. 访问 Verba 的 web 界面,默认为 http://localhost:8080。

-
2. 导入您的数据,例如上传一个 PDF 文件或 CSV 文件。

-
3. 开始查询您的数据,通过 Verba 的检索增强生成技术获取见解。
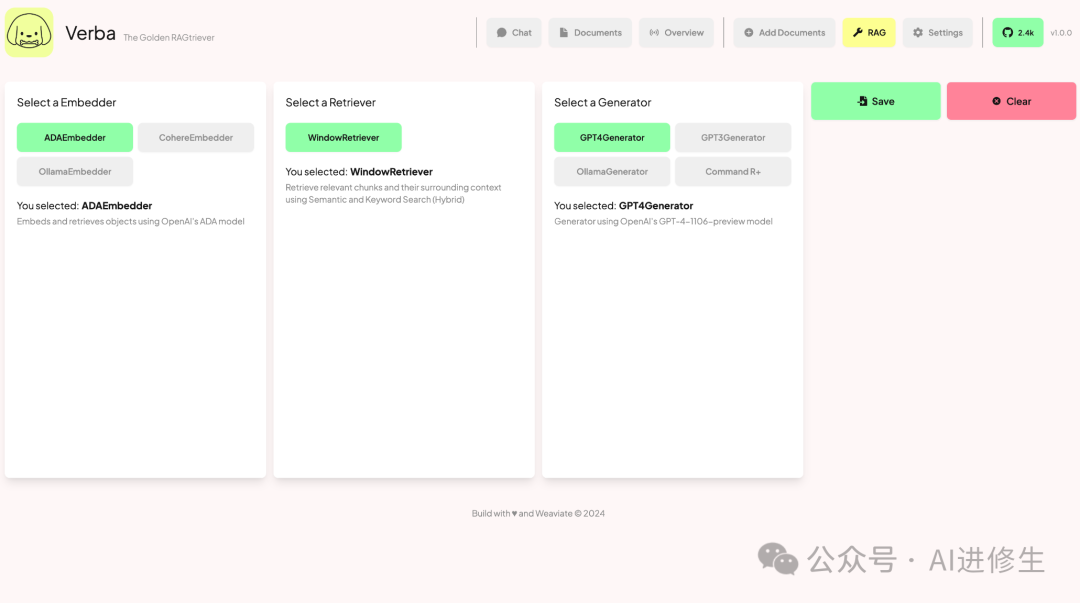
您可以参考 快速开始视频 了解更多。
🚩 已知问题
-
• 某些模型在特定数据集上表现不佳。
-
• 高并发请求可能导致响应时间较慢。
参考链接:
[1]https://github.com/weaviate/Verba
知音难求,自我修炼亦艰
抓住前沿技术的机遇,与我们一起成为创新的超级个体
(把握AIGC时代的个人力量)

— 完 —
** 点这里👇关注我,记得标星哦~ **
**
**
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

预览时标签不可点
微信扫一扫
关注该公众号
轻触阅读原文

AI进修生
收藏