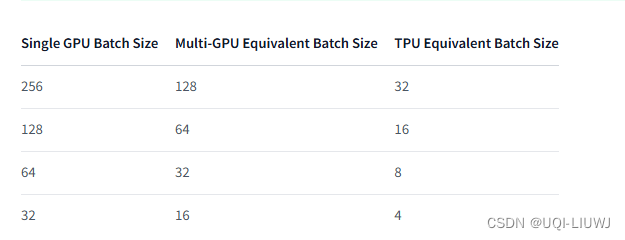
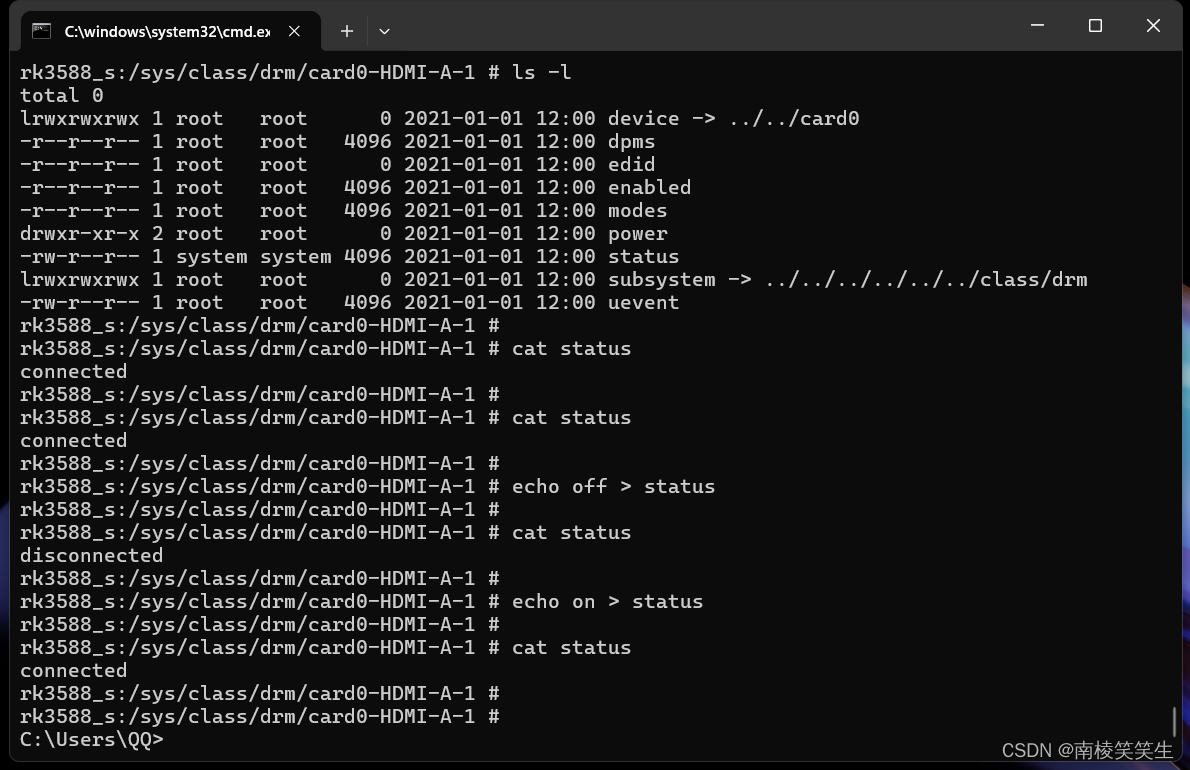
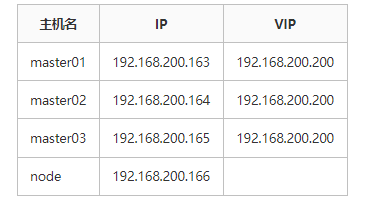
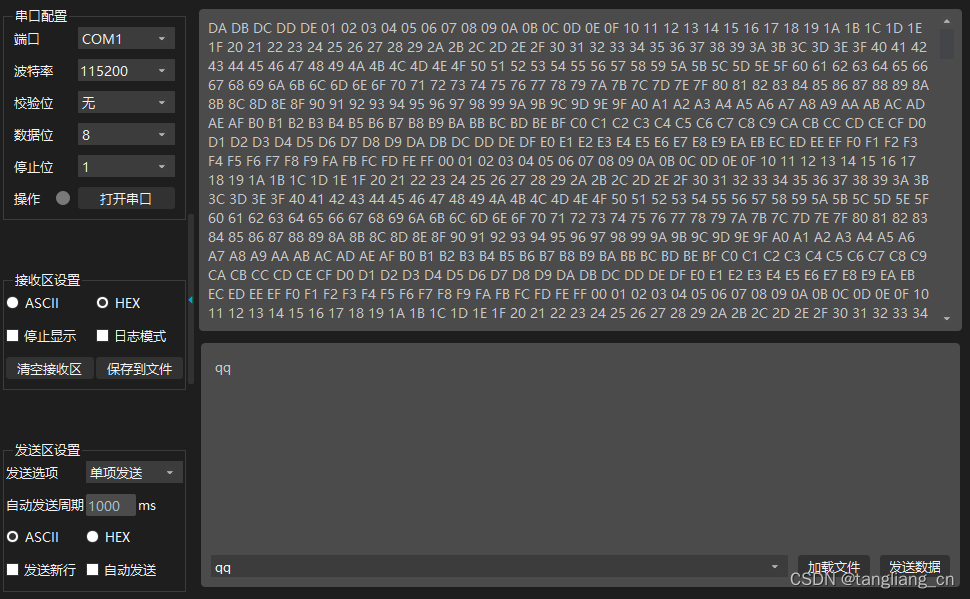
当使用Python来获取数据时,有许多不同的方法和库可以根据你的需求来选择。以下是一些常见的示例,说明如何使用Python来从各种来源获取数据。

1. 从网站或API获取JSON数据
你可以使用requests库从网站或API获取JSON格式的数据。例如,从某个API获取天气信息:
import requests
# API的URL
url = 'https://api.example.com/weather?city=NewYork'
# 发送GET请求到API
response = requests.get(url)
# 确保请求成功
if response.status_code == 200:
# 解析JSON数据
data = response.json()
# 打印获取到的数据
print(data)
else:
print(f"请求失败,状态码: {response.status_code}")2. 从数据库获取数据
你可以使用sqlite3、psycopg2(对于PostgreSQL)、pymysql(对于MySQL)等库从数据库中获取数据。以下是一个使用sqlite3从SQLite数据库获取数据的例子:
import sqlite3
# 连接到SQLite数据库(如果数据库不存在,将创建一个新数据库)
conn = sqlite3.connect('example.db')
# 创建一个游标对象
cursor = conn.cursor()
# 执行SQL查询
cursor.execute("SELECT * FROM my_table")
# 获取所有记录
rows = cursor.fetchall()
# 遍历并打印记录
for row in rows:
print(row)
# 关闭游标和连接
cursor.close()
conn.close()3. 从CSV文件读取数据
你可以使用Python内置的csv模块或pandas库来读取CSV文件中的数据。以下是一个使用pandas的例子:
import pandas as pd
# 读取CSV文件
data = pd.read_csv('data.csv')
# 显示数据的前几行
print(data.head())
# 对数据进行进一步处理或分析...4. 从Excel文件读取数据
使用pandas库也可以方便地读取Excel文件中的数据:
import pandas as pd
# 读取Excel文件
data = pd.read_excel('data.xlsx')
# 显示数据的前几行
print(data.head())
# 对数据进行进一步处理或分析...5. 从网页抓取数据(网络爬虫)
你可以使用BeautifulSoup和requests库来从网页中抓取数据。以下是一个简单的例子:
import requests
from bs4 import BeautifulSoup
# 目标网页的URL
url = 'https://example.com/some-page'
# 发送GET请求到网页
response = requests.get(url)
# 确保请求成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找并提取你想要的数据(例如,所有的段落文本)
paragraphs = soup.find_all('p')
for paragraph in paragraphs:
print(paragraph.text)
else:
print(f"请求失败,状态码: {response.status_code}")以上只是Python获取数据的几个常见示例。实际上,Python还有许多其他库和工具可以帮助你从各种来源获取数据,如RSS、XML、API等。你可以根据自己的需求选择适合的库和工具来完成任务。