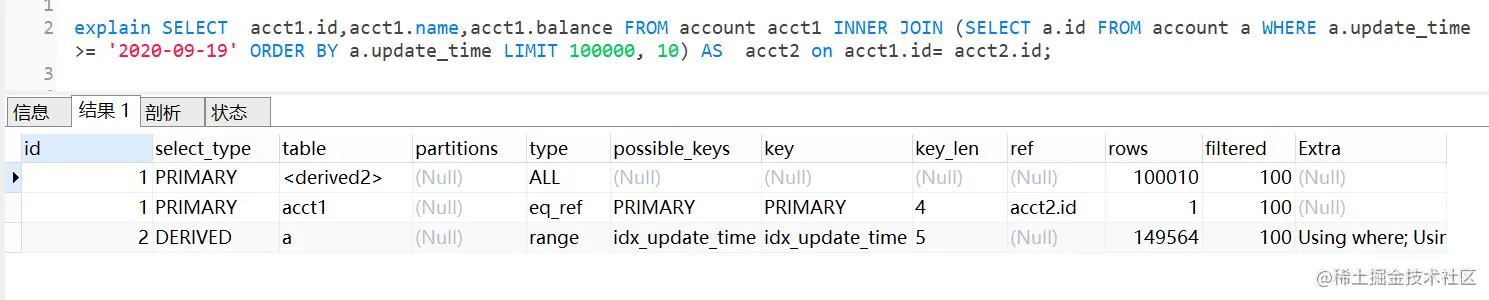
- 在TPU、多GPU和单GPU上使用accelerate运行相同的脚本和相同的batch_size,可能结果是不一样的
- 那应该怎么做呢?
1 设置正确的种子
确保在所有分布式情况下使用 utils.set_seed() 完全设置种子,以使训练可复现
from accelerate.utils import set_seed
set_seed(42)- acclerate的设置随机种子涵盖了5种不同的种子设置:
- 随机状态
- numpy的状态
- torch
- torch的cuda状态
- 如果TPUs可用,torch_xla的cuda状态
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# 即使cuda不可用,也可以安全地调用此函数
if is_torch_xla_available():
xm.set_rng_state(seed)2 batch_size
- 在使用Accelerate进行训练时,传递给数据加载器的批处理大小是每个GPU的批处理大小。
- 这意味着在两个GPU上的64的批处理大小实际上是128的批处理大小。
举例:假设我们有:两个GPU用于“多GPU”、一个带有8个工作站的TPU pod
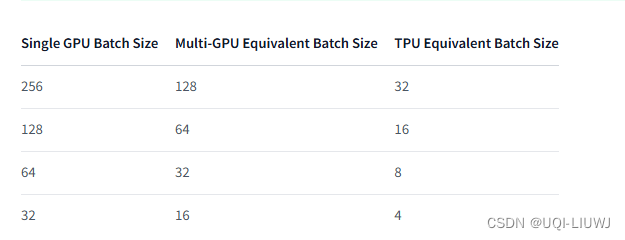
3 学习率
学习率应该根据设备的数量线性缩放
learning_rate = 1e-3
accelerator = Accelerator()
learning_rate *= accelerator.num_processes
optimizer = AdamW(params=model.parameters(), lr=learning_rate)
4 梯度累积和混合精度
- 使用梯度累积和混合精度时,由于梯度平均(累积)和精度损失(混合精度)的工作方式,预期会有一些性能下降。
- 这将在比较不同计算设置的批量损失时明显看到。
- 然而,训练结束时的总损失、指标和一般性能应该大致相同。