最近我负责的系统出了一次生产事故,这次事故竟然是因为流水号重复导致的。今天来给大家分享一下。
1.问题背景
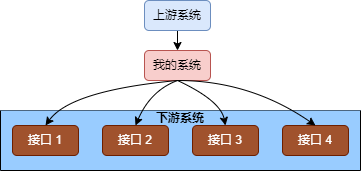
这个流水号的使用场景是上游系统调用下游接口时传入一个唯一 ID,流水号这个参数在联调或定位问题时很方便。
我们系统中的流水号是一个 32 位的字符串,为了能让上下游系统联动,下游系统接到上游传过来的这个 ID 后,会取前 23 位,再自己拼接剩下 9 位,传到自己要调用的下游系统,这样整个调用链通过请求 ID 就可以快速串起来。

2.流水号使用
在我的系统中,自己定义流水号的后 9 位,为了能够更清晰地从流水号中看到请求链上的系统调用关系,我们把流水号后 9 位定义成了系统编号(3位) + 子系统编号(2位) + 自增序列(4 位) 。
如下图,我的系统生成的流水号前 23 位来自上游,后 9 位是 001(系统编码) + 01(子系统编码) + (0 ~ 9999自增)。
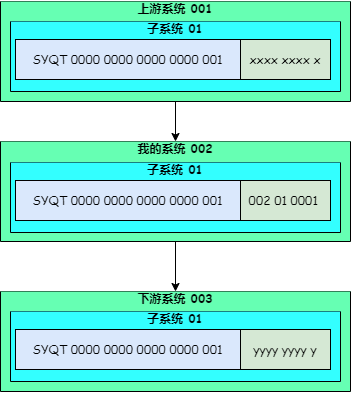
在我们的业务场景中,上游系统调用我的系统,我的系统有 10000 个流水号,支撑 10000 笔交易,理论上足够使用了。
不幸的,系统中的业务开发同事并没有注意到流水号生成规则,因为流水号生成工具是一个成熟的 util 类,大家直接调用获取流水号。
而这一次的事故中,我们的业务是一个批量业务,收到上游系统的请求后,我们的处理逻辑是读取合作方推送的文件,然后对每一个文件调用下游接口进行处理。每一个文件处理需要调用下游四个接口,每一个接口都需要新的流水号。
这样我们就能看到流水号生成工具的瓶颈了,如果超过 2500 个文件,10000 个流水号就会被用完。而流水号生成工具的逻辑是如果流水号用完,就会从 0 开始重新生成,造成了流水号重复。
下游系统会对流水号进行判断,收到重复的流水号,直接返回接口调用失败。因为失败的调用比较多,触发了生产告警。
3.事故处理
比较庆幸的是,这次事故并没有造成交易阻断、现金损失、客户体验差等问题。还有一点幸运是正好赶在上线窗口前发现了,没有走紧急上线流程。要知道,紧急上线对团队和个人的绩效考核都会产生影响。
但交易失败的三方文件会影响合规检查,必须进行交易补偿。
我们团队做的修复工作是及时修改了流水号生成规则,我们把后面 6 为定义成自增的序列,这样足够满足所有场景的使用了,而我们保留系统编码,对系统交易链路追踪是非常必要的。
上线后,请上游系统再次触发接口调用,对之前失败的三方文件进行补偿处理。
4.聊聊事故
无论在国企、银行还是互联网公司上班,生产事故的出现,都可能会影响到公司正常业务的开展,甚至让业务遭受损失。严重的,事故当事人会收到严格处罚,甚至被淘汰掉。
除了对考核的影响,解决故障的过程也是非常耗时的。
4.1 应急措施
在没有定位到问题之前,必须先采取紧急措施接触生产告警,以免造成大的业务损失。应急措施包括但不限于重启服务、执行应急脚本、业务降级等。
4.2 定位问题
采用应急手段解决故障后,就要开始定位问题了。有的问题可能不太好定位,尤其是一些老代码,作者已经离职,也没有留下什么详细的文档。接手人可能之前看过代码,但是过了很长时间又记不清了。
4.3 评估业务影响
再复杂的问题,最终肯定能定位到原因。接着就是评估业务影响,这一步也是必须要做的,因为多数情况下,对业务的影响大小决定了这次事故的级别,这项工作一般会有业务参与。
比如我过往的一家公司规定,故障超过 15 分钟,影响超过 100 笔订单的故障定义为一级故障。
4.4 向上汇报
接着就是给领导汇报,甚至需要层层汇报。这一步可以说是最难做的。
首先需要明确问题责任人或者责任团队,因为故障可能会影响到绩效考核,所以很多时候会遇到扯皮或帅锅的情况,没有一个领导愿意让自己的团队背锅。有时候把锅甩给中间件,数据库或其他底层组件,也是一个选择。
撰写事故报告也是非常耗时的一个工作,领导不可能像技术人员一样通过看代码了解事故原因,他们需要故障报告能够清晰易懂,甚至几句话就能讲明白。
4.5 复盘
事故复盘是为了让团队能够了解到故障的根本原因,作为经验教训,防止再犯。
5 总结
今天分享了我在工作中遇到的一次生产事故。生产事故除了影响业务正常运转,处理事故的过程也是非常花费时间和精力的。完全不出事故是不可能的,如果能对历史故障吸取教训,多花心思研究自己的系统,可以有效降低故障率。