1)指定一个目录,扫描这个目录,找到当前目录下面所有文件的文件名是否包含了指定字符的文件,并提示这个用户是否要删除这个文件,根据用户的输入来决定是否删除;
1.1)需要进行输入一个目录,还需要进行输入一个要进行删除的文件名
1.2)不是说文件名一模一样,而是如果包含了我们所输入的文件名,就进行删除
package com; import java.io.*; import java.util.Arrays; import java.util.Scanner; import java.util.concurrent.TimeUnit; public class Solution { public static void main(String[] args) throws IOException { //案例1,实现查找文件并进行删除的效果 //1.先输入如要扫描的路径和要删除的文件的名字,只要这个目录里面包含的文件有这个名字,就进行删除 Scanner scanner=new Scanner(System.in); System.out.println("请您先进行输入要进行扫描的路径"); String PreFilePath=scanner.nextLine(); System.out.println("请再次输入你要进行删除文件的名字"); String DeleteName=scanner.nextLine(); //2.判断你所进行指定的目录是否存在,如果不存在,那么就直接进行返回 File f=new File(PreFilePath); if(!f.exists()){ System.out.println("当前您进行输入的扫描路径不存在,程序退出"); return; } //3.遍历目录,我们把这个目录下面的所有目录和子目录都给遍历一遍,从而找到要删除的文件,我们希望通过这个方法来进行实现递归并且进行删除文件的操作 scanDir(f,DeleteName); } private static void scanDir(File rootDir, String deleteName) { //1.先进行罗列出当前文件的子文件路径下面有哪些内容 File[] files=rootDir.listFiles(); if(files==null){ //当前的files是一个空目录 return; } //2.如果说不是空目录,那么我们就直接遍历当前目录下面的所有子文件(文件+目录) //如果是普通文件我们就直接检测文件名字是否是要删除的文件,如果是目录就地柜的进行遍历 for(File f:files){ if(f.isDirectory()){ //如果是目录直接进行地柜 scanDir(f,deleteName); }else{ //这是普通文件 if(f.getName().contains(deleteName)){ deleteFile(f); } } } } private static void deleteFile(File f) { System.out.println("确认要删除这个文件吗?Y"+f.getAbsolutePath()); Scanner scanner=new Scanner(System.in); String choice=scanner.next(); if(choice.equals("Y")||choice.equals("y")){ f.delete(); System.out.println("文件删除成功"); }else{ System.out.println("文件放弃删除"); } } }
2)复制一个文件,我们需要让用户指定两个文件路径
一个是原路径,也就是说被复制的文件,输入的是一个文件路径,包含普通文件
一个是目标路径,也就是说复制之后的文件,输入的是一个文件路径,包含普通文件
也就是说打开原路径的文件,读取里面的内容,并且写入到目标文件;
public class Solution{
public static void main(String[] args) {
//1.输入两个路径
Scanner scanner=new Scanner(System.in);
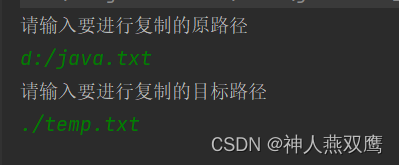
System.out.println("请输入要进行复制的原路径");
String ResourcePath=scanner.nextLine();
//1.1如果说我们上面输入的文件路径不是一个普通文件或者是一个目录或者压根不存在,直接返回
File Father=new File(ResourcePath);
if(!Father.exists()||!Father.isFile()){
System.out.println("当前您输入的路径不是一个普通文件");
return;
}
System.out.println("请输入要进行复制的目标路径");
String ResultPath=scanner.nextLine();
//1.2如果说我们上面输入的文件路径不是一个目录,或者不存在或者是一个普通路径,但是没有什么事情,我们写文件的时候会自动进行创建
//此处我们不算太需要检查目标目录是否存在只是说写文件的时候OutPutStream会自动的进行创建
File Child=new File(ResultPath);
//2.进行写文件的操作
WriteFile(Father,Child);
}
private static void WriteFile(File father, File child) {
try(OutputStream outputStream=new FileOutputStream(child,true)) {
try(InputStream inputStream=new FileInputStream(father)){
Scanner scanner=new Scanner(inputStream,"UTF-8");
PrintWriter writer=new PrintWriter(outputStream);
while(scanner.hasNext()){
String line=scanner.nextLine();
if(line==null||line.equals("")){
break;
}
writer.write(line.toString());
writer.flush();
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}private static void WriteFile(File father, File child) { try(OutputStream outputStream=new FileOutputStream(child,true)) { try(InputStream inputStream=new FileInputStream(father)){ //我们这里面是把InputStream中的内容读出来,写到OutputStream里面 byte[] buffer=new byte[1024]; while(true){ //先进行读取 int len=inputStream.read(buffer); if(len==-1){ System.out.println("文件读取完毕"); break; } //在进行写入,我们在进行写入的时候,是不可以把整个buffer都写进去,毕竟在最后的时候buffer只有一部分才是有效数据 outputStream.write(buffer,0,len); } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }请输入要进行复制的原路径 d:/tomact.zip 请输入要进行复制的目标路径 d:/lijiawei.zip 文件读取完毕但是我们需要注意,我们再进行读取文件内容的时候,如果文件很多或者文件内容很大,那么效率就会比较低;
3)输入一个目录,查找文件名字和文件内容中出现特定字符的文件;
1)我们还是说主要进行文件内容的查找,先进行输入一个路径,再输入一个要进行查找的文件内容的关键词;
2)我们就开始进行递归的进行遍历这个文件,查找哪一个文件里面的内容包含了关键词,就把对应的文件路径存入进去
3)我们先进行递归的进行遍历文件,针对每一个文件都打开,并读取文件内容,然后进行字符串的查找即可
//遍历整个文件 public static void research(List list,String str1,File file)throws IOException { File[] arr1=file.listFiles(); if(arr1==null){ return; } for(File file2:arr1) { System.out.println(file2); } for (File file1:arr1) { if(file1.isFile()) { if(file1.getName().contains(str1)||scanlll(list,str1,file1)) list.add(file1); } else{ research(list,str1,file1); } } } //专门进行扫描文件内容 public static boolean scanlll(List list,String str1,File file)throws IOException { StringBuffer stringBuffer=new StringBuffer(); try(InputStream inputStream=new FileInputStream(file)) { Scanner scanner=new Scanner(inputStream,"UTF-8"); while(scanner.hasNextLine()) { String line=scanner.nextLine(); stringBuffer.append(line+"\n"); } }catch(IOException e) { e.printStackTrace(); } return stringBuffer.indexOf(str1)!=-1; } public static void main(String[] args) throws IOException{ Scanner scan=new Scanner(System.in); //1.要进行输入要扫描的工作路径 System.out.println("请输入你想查询的工作目录,绝对路径"); String str=scan.next(); File file=new File(str); //2.请输入你要进行查询的关键词 System.out.println("请输入你要查询的字符串也就是关键词"); String str1=scan.next(); //3.如果说你进行传递的工作目录不存在,那么就直接返回 if(file.isFile()) { System.out.println("你输入的文件路径错误,是普通文件,请重新输入"); return; } List list=new ArrayList<>(); //4.调用方法,把符合要求的文件名字和文件内容出现关键词的文件放到list里面 research(list,str1,file); System.out.println(list); }1)indexOf 方法返回一个整数值,指出 String 对象内子字符串的开始位置,如果没有找到子字符串,则返回-1;
2)nextline 是一次读取一行数据,每次读取的时候都是遇到了换行符,才读取完毕;
3)我们当然还是可以使用contains方法来进行判断当前字符串中是否包含指定字符串
4)我们这个代码效率还是很低,因为如果说要是扫描整个D盘,那么效率会变的非常低下
5)在我们上面的那些代码中,我们来进行使用多线程,是可以很好的来进行提高效率的,我们可以进行创建一个线程池,每一次遍历到这个文件,我们就把这个文件交给线程池,我们在线程池里面增加线程的个数,增加并发性,我们是由线程池来进行负责打开文件,读文件,并且进行indexOf的操作;
那为什么要关闭文件呢?
1)这就涉及到文件描述符的问题了,每当创建一个进程的时候进程的PCB就会创建出一个文件描述符表,类似于一个数组,数组中的每一个元素就是structFile类型,那么每当进程打开一个文件,就会产生一个具体的文件描述符,然后就把他放到文件描述表中。
2)每次打开文件,就会在文件描述表中申请一项,每当关闭文件时,就会把这个表项放掉;如果一直持续不断的打开文件,又不关闭,很快就会把文件描述符给耗尽,此时如果再打开文件,就会失败;
flush 是刷新缓冲区,计算机读取内存的速度是比读写磁盘要快很多的,所以有时候为了提高效率,就可以直接减少访问磁盘的次数,使用缓冲区就可以很好地解决这个问题,当我们用write来写文件的时候,并不是真的直接写到磁盘中了,而是先放到缓冲区中,如果缓冲区满了,或者手动调用flush(),才会真的把数据写到磁盘上面,这样我们就可以进行解决频繁访问磁盘上面的缓冲区的问题
缓冲区:降低访问磁盘的次数,降低总体访问磁盘的开销:
1)咱们的缓冲区存在的意义就是为了说提高效率,这个观念在我们的计算机中特别重要,因为我们的CPU的读取内存的速度往往是高于读取磁盘的速度的
2)比如说我们需要把数据写到磁盘上面,与其一次写一点,不如就是说把这些数据攒一堆,某一次直接写完,这一堆数据就是在内存中进行保存的,这块内存就叫做缓冲区
3)咱们的读操作也是类似的,与其一次读一点,频繁访问磁盘,也没什么必要,不如就是说一次性的读取一堆数据,然后再进行慢慢的消化,这一块内存也是缓冲区
推荐一首歌:此生不换
例如说我们以前在进行写数据的时候,有时候需要把数据写到缓冲区里面,然后再来进行统一写硬盘的操作:
1)如果说当前缓冲区已经满了,我们就会直接触发写硬盘的操作
2)如果说当前缓冲区还没有满,但是我们还是想要提前写硬盘,我们就直接可以用过flush()来进行刷新缓冲区
3)有些代码没有涉及到flush操作是因为有些代码是很快的涉及到flush操作,因为一旦触发了close操作,那么就会导致触发缓冲区刷新
就是类似于咱们嗑瓜子一样:
输出缓冲区:放瓜子皮的手,与其一个瓜子皮一个瓜子皮的扔,不如攒到一起扔
输入缓冲区:放瓜子的手,与其一个瓜子一个瓜子的拿,不如说一次拿一大把
2.回顾IO流
一:IO流的描述:
定义:
I表示input,我们负责把硬盘文件中的数据读入到内存的过程,称之为输入,负责读取
O表示output,我们把内存中的数据写入到硬盘文件的过程,称之为输出,负责写;
二:按流的数据的最小单位来分:
IO流 字节流 字符流 操作所有类型的文件(包括音频,视频,文件) 只能操作纯文本文件(比如说Java文件,txt文件)三:按照流的方向上来分:输入流和输出流
1)字节输入流(读字节数据的)/字符输入流(读字符数据)-----InputStream/Reader
定义:以内存为基准,来自磁盘文件/网络中的数据以字节/字符的形式读入到内存里面的流,称之为字节输入流
2)字节输出流(写字节数据的)/字符输出流------OutputStream/Writer
定义:以内存为基准,把内存中的数据以字节/字符的形式写入到磁盘文件或者到网络中的流称为字节输出流
字节流:
一:字节输入流:每次读取一个字节
以内存为基准,将磁盘文件中的数据以字节的形式读取到内存中去
构造器:(构造方法)
1)public FileInputStream(File file)-----它的作用是创建字节输入流管道与源文件对象接通 2)public FileInputStream(String pathname)----创建字节输入流管道和源文件路径接通方法:public int read()------它的功能是每次读取一个字节返回,如果字节没有可读的就返回-1
缺点:性能较慢,况且读取中文字符我们是无法避免乱码问题的
二:字节输入流:每次读取一个字节数组
以内存为基准,将磁盘文件中的数据以字节的形式读取到内存中去
1.方法:public int read(byte[] buffer)我们每一次读取一个字节数组进行返回,如果字节没有可读的数据我们就返回-1
2.缺点:我们读取的性能确实得到了提升,但是我们读取中文字符仍然会出现乱码问题
注意:我们使用字节流读取中文会出现乱码,但是我们如何使用字节输入流可以进行保证读取中文输出不乱吗呢?
我们可以定义一个和文件一样大的字节数组,一次性读完文件的所有字节,但是文件如果过大的话,字节数组就可能会引起内存溢出
三:字节输入流:读取文件的所有字节:
方式一:我们可以向上述过程中定义一个字节数组和文件的大小一样大,然后使用读取字节数组的方法,进行一次性读取完成,调用public int read(byte[] arr1),每一次读取一个字节数组返回,如果字节没有可读的就返回-1;
方式二:我们官方提供了一组API:我们直接可以将当前字节输入流对应的文件对象的字节数据封装到一个字节数组返回:public byte[] readAllBytes() throw IOException
四:字节输出流:写字节数据到文件里面
是以内存为基准,将内存中的数据以字节的方式写出到磁盘文件里面的流
构造器 说明 public FileOutputStream(File file) 创建字节输出流管道与源文件对象接通 public FileOutputStream(File file,boolean append) 创建字节输出流管道 public FileOutputStream(File file,boolean append) 创建字节输出流管道和源文件路径接通 public FileOutputStream(String FilePath,boolean append) 创建字节输出流管道和源文件路径接通 常用方法:
1.API方法:直接将文件字节输出流写数据出去的API
1)public void write()--------写一个字节出去
2)public void write(byte[] arr1)-------写一个字节数组出去
3)public void write(byte[] arr1,int pos int len)------写一个字节数组的一部分出去
2.流的关闭和刷新
1)close()关闭流对象,但是先刷新一次缓冲区,关闭之后,流对象不可以继续再使用了。将缓冲区的数据刷到目的地中后,流就关闭了,该方法主要用于结束调用的底层资源。这个动作一定做。
2)flush()仅仅是刷新缓冲区(一般写字符时要用,因为字符是先进入的缓冲区),流对象还可以继续使用。将缓冲区的数据刷到目的地中后,流可以使用
字符流:
我们在进行使用字节流读取中文输出的时候,会造成乱码或者内存溢出,所以说当我们使用读取中文输出的时候,我们还是需要使用字符流是更合适的
文件字符输入流:Reader
作用:将以内存为基准,把磁盘文件中的数据以字符的方式读取到内存里面
构造器 说明 public FileReader(File file) 创建字符输入流管道与源文件对象接通 public FileReader(String pathname) 创建字符输入流管道和源码文件互通 常用方法:
方法名称 说明 public int read() 每次读取一个字符返回,如果没有可读的字符那么就返回-1 public int read(char[] buffer) 每次读取一个字符数据,返回读取的字符个数,如果说没有可读的字符那么就会返回-1 注意:
1.ASCII码:一个中文(含繁体)占两个字节,一个中文标点占三个字节,一个英文字母占一个字节的,一个英文标点占一个字节。
2.UTF-8编码:一个中文(含繁体)占三个字节,一个中文标点占三个字节。一个英文字母占一个字节,一个英文标点占一个字节。
3.Unicode编码:一个中文(含繁体)占两个字节,一个中文标点占两个字节。一个英文占两个字节,一个英文标点占一个字节
字符输出流:FileWriter
一:文件字符输出流:
作用:以内存为基准,把内存中的数据以字符的方式来写入到磁盘文件里面的流
常用构造器:
常用构造器 构造器说明 public FileWriter(File file) 创建字符输出流管道和文件对象接通 public FileWriter(File file,boolean append) 创建字符输出流管道文件对象接通,可以进行添加数据) public FileWriter(String pathname) 创建字符输出流管道和文件路径接通 public FileWriter(String pathname,boolean append) 创建字符输出流管道和文件路径接通,可以进行追加数据 文件字符输出流(FileWriter)写数据出去的API
方法名称 说明 void write(int c) 写入一个字符 void write(char[] arr1,int off,int len) 写入字符数组的一部分 void write(String str) 写入一个字符串 void write(char[] arr1) 写一个·字符数组 void write(String str,int off,int len) 写入字符串的一部分) 流的关闭与刷新:
刷新:flush(),刷新流,close(),关闭流
字节流,字符流的使用场景总结:
字节流适合用于一切文件数据的拷贝(音视频,文本)
字节流不适合用于读取中文内容的输出
字符流适用于文本文件的操作
转换流:
1.什么是缓冲流:
之前咱们写的字节流称之为原始流,现在我们来进行学习一下缓冲流,缓冲流又被称之为高效流,或者高级流,我们的缓冲流是自带缓冲区的,可以有效地提高原始字节流,字符流读写数据的性能
2.缓冲流的实现原理:缓存流之所以高效是因为在内存中开闭空间用来存尽可能多的数据,来减少使用io资源的次数,以达到性能提升
字节缓冲流输入流自带了8KB缓冲池,以后我们就可以直接从缓冲池里面读取数据,所以性能比较好
字节缓冲输出流自带了8KB缓冲池,数据就直接写到缓冲池里面,写的性能就提高了
字节缓冲输入流
字节缓冲输入流:BufferedInputStream,提高字节输入流读取数据的性能
字节缓冲输出流:BufferedOutputStream,提高字节输出流读取数据的技能
常用的构造器:
构造器 说明 public BufferedInputStream(InputStream inputStream) 我们可以把低级的字节输入流包装成一个高级的缓冲字节输入流管道,从而提高字节输入流读取数据的性能 public BufferedOutputStream(OutputStream
outputStream)
我们可以把低级的字节输出流包装成一个高级的缓冲字节输出流,从而提高写数据的性能) 字符缓冲流:
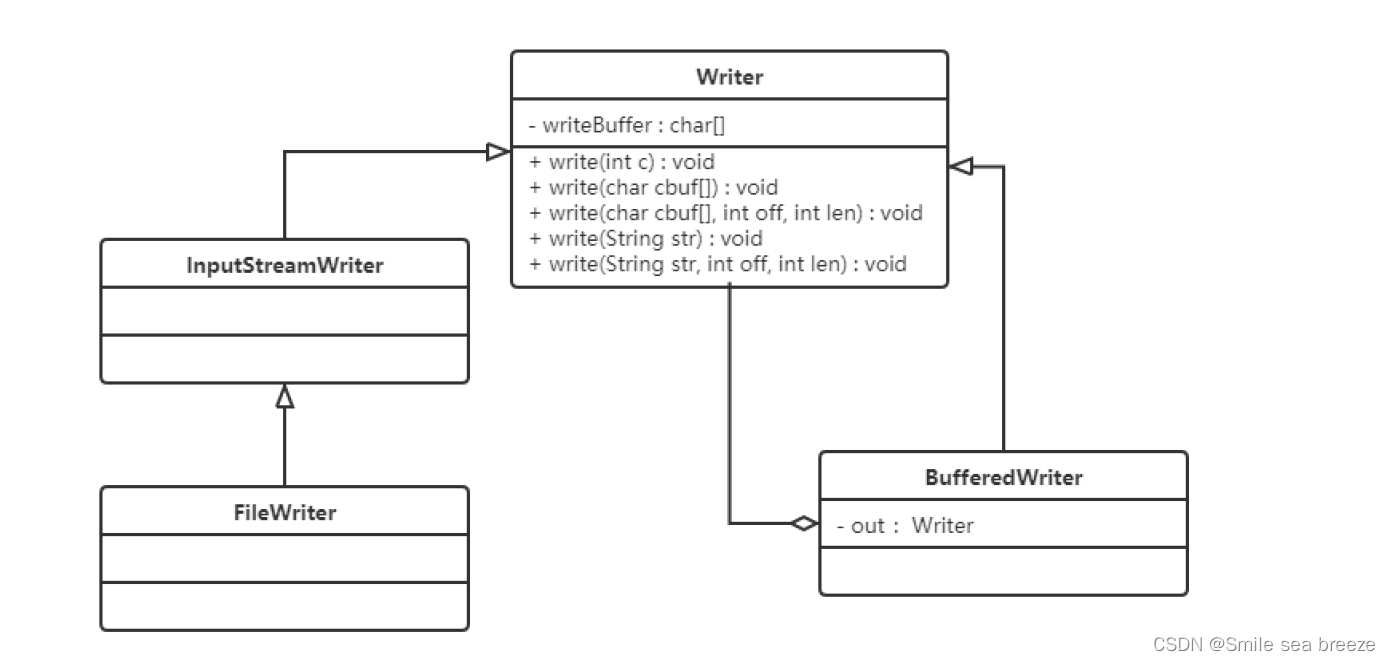
1.字符缓冲输入流:BufferedReader.
作用:提高字符输入流读取数据的性能,除此之外多了按照行读取数据的功能
构造器:public BufferedReader(Reader reader)将一个低级的字符输入流包装成一个高级的缓冲字符输入流管道,从而提高字符输入流读数据的性能
方法:public String readLine(),读取一行数据返回
2.字符缓冲输出流:BufferedWriter
作用:可以提高字符输出流读写数据的性能,除此之外多了换行功能;
public BufferedWriter(Writer w)可以将一个低级的字符输出流包装成一个高级的缓冲字符输出流
换行操作: public void newLine() 换行操作,我们写着写着的时候如果想要换行那么就要刷新一下缓冲区
意思是当你调用BufferedWriter的write方法时候。数据是先写入到缓冲区里,并没有直接写入到目的文件里。你必须调用BufferedWriter的flush()方法。这个方法会刷新一下该缓冲流,也就是会把数据写入到目的文件里
BufferedWriter bufferedWriter=new BufferedWriter(new FileWriter("d:\\test1.txt")); BufferedReader bufferedReader=new BufferedReader(new FileReader("d:\\test1.txt")); String line=bufferedReader.readLine(); System.out.println(line); line="生命在于运动"; bufferedWriter.write(line); bufferedWriter.newLine(); bufferedWriter.newLine(); String str="生命在于吃饭"; bufferedWriter.write(str); bufferedWriter.flush();下面我们来想一下我们为什么会出现乱码问题:
read(),是每次读取一个字节,但中文一个字符占2个字节(GBK)或者3个字节(UTF-8)
所以它读的时候,只读到了一半就没了,所以会产生类似于乱码的符码
字符转换输入流和字符转换输出流
字符输入转换流:我们可以把原始的字节流按照指定编码转换成字符输入流:
字符输出转换流:我们可以把字节输出流进行指定编码转换成字符输出流
InputStreamReader inputStreamReader=new InputStreamReader(new FileInputStream("d://test1.txt"),"UTF-8"); char[] arr1=new char[4096]; while(true) { int ch=inputStreamReader.read(arr1); if(ch==-1) { System.out.println("当前您已经读取文件读取完毕"); break; } } String str=new String(arr1); System.out.println(str);7)我们先写一个简单的示例,使用字节流,将一个文件的内容进行读取出来,写入到另一个文件当中
8)当我们在main方法上面加上java.IOException的声明的时候,FileNotFoundException就不见了,是因为FileNotFoundException也是一种特殊类型的IOException,是它的子类
public static void main(String[] args) throws IOException { String path1="d:/test1.txt"; String path2="d:/test2.txt"; //我们再进行读写文件的时候,一定要进行先打开文件的操作 //这个代码打开了第一个用来读的数据的文件 FileInputStream file1=new FileInputStream(path1); //这个代码打开了第二个用来写数据的文件,打开文件打不开,硬盘损害 FileOutputStream file2=new FileOutputStream(path2); //这里是受查异常,是不可以进行忽略的,在方法前进行声明,通过throws交给上级调用者进行处理,或者运用try cathch进行包裹,提醒上级调用者多多注意 //我们来进行循环的降低一个文件的内容读取出来,依次写到第二个文件里面 while(true) { byte[] arr1=new byte[4096]; int len=file1.read(arr1); if(len==-1) { System.out.println("第一个文件读取结束"); break; } file2.write(arr1); } //文件操作完毕之后,进行关闭; file1.close(); file2.close(); }9)一个进程能够同时打开的文件个数是存在上限的,在这里面是受限于操作系统中内核的实现,对于linux来说,进程中PCB里面存在着一个属性,叫做文件描述符表,它的大小是存在上限的,我们在linux里面可以通过ulimit命令来进行查看/修改进程可以进行支持的最大文件个数;
输出汉字:如果字母和汉字进行混合,那么打印出来的结果就会出现问题
还可用scan的方式,在Java的标准库里面,已经对字符集有了内置的解决方案,不需要在这里进行实现,在文件中读取文字,可以读文字和字符的混合;
为什么读汉字和读字符不一样呢? 中文的编码方式和英文是不太一样的,英文的编码方式是Ascli码,就会比较简单。
如果是中文的话,就需要使用UTF-8或者GBK,因为一个汉字在UTF-8中,是由三个字节构成的,把每三个字节打印在一起,作为一个整体;
代码中的c%其实就是按照ascii的,方式来进行打印,这个时候读取到的字节,只是UTF-8或者GBK编码的一个部分,这个结果不是一个合法的ascil值,于是就会出现异常了

![[ 云原生 | 容器 ] 虚拟化技术之容器与 Docker 概述](https://img-blog.csdnimg.cn/a6330914572c40c88416eae2c2a4df59.png)

![【学习笔记】[AGC022F] Checkers](https://img-blog.csdnimg.cn/a9fabf67af544384ac6acd004d366ae4.png)