文章目录
- 一、wandb简介
- 二、wandb注册与登陆(网页) —— 若登录,则支持在线功能
- 三、wandb安装与登陆(命令行) —— 若不登录,则只保留离线功能
- 四、函数详解
- 4.1、wandb.init() —— 初始化一个新的 wandb 实验,并开始记录实验的信息和结果。
- 4.2、wandb.config.update() —— 更新实验的配置参数
- 4.3、wandb.log() —— 记录实验指标和日志信息。
- 4.4、wandb.finish() —— 结束实验记录。
- 五、项目实战
- 5.1、入门教程
- 5.1.1、在Pycharm中可视化结果
- 5.1.2、在仪表盘中可视化结果(网页)
- 5.2、简单的 Pytorch 神经网络
wandb指南(视频教程 - 入门必看):https://docs.wandb.ai/guides
wandb教程(示例代码):W&B Tutorials
wandb教程(示例代码 - Jupyter):Intro_to_Weights_&_Biases.ipynb
一、wandb简介
wandb(Weights&Biases, W&B):用于跟踪、可视化和协作机器学习实验的工具,支持在线和离线。它提供了一个简单的 Python API,可以轻松地将实验数据发送到云端,并通过 Web 应用程序进行访问和可视化。
实验跟踪和记录:自动跟踪机器学习实验,包括超参数、指标、模型架构等,并将这些信息保存在云端,以便后续查看和比较。结果可视化:提供丰富的可视化功能,包括曲线图、散点图、直方图等,以帮助用户更好地理解实验结果和模型性能。模型检查点和版本控制:可以保存模型检查点,并生成唯一的版本号,以便回溯和比较不同的实验结果。协作和共享:可以邀请团队成员参与实验、查看结果,并进行讨论和反馈。还可以将实验和结果与其他人共享,使其可以在不同的环境中重现和使用您的工作。集成多种框架:支持与各种机器学习框架(如 TensorFlow、PyTorch、Keras 等)和机器学习工具(如 scikit-learn)集成,并提供了方便的 API,方便进行实验管理和结果跟踪。
备注:若登陆(在线版本),则在个人主页的Profile - Projects中保存实验记录,且每运行一次都将新增一条可视化数据,而不是只保留最近一次的运行结果。
备注:若不登陆(离线版本);
备注:无论是否登录,都将在当前路径下自动新建一个wandb文件夹,且每运行一次都将新增一个保存实验记录的文件夹。
二、wandb注册与登陆(网页) —— 若登录,则支持在线功能
若需要wandb在线功能,则执行以下步骤。
- 账号注册(SING UP):https://wandb.ai/site
- 注册并登陆账号后,将获取一个与账号绑定的的身份码(
API key)。- 在 Python 项目中,可以绑定指定的项目名称用于保存实验数据。若项目不存在,则自动创建。
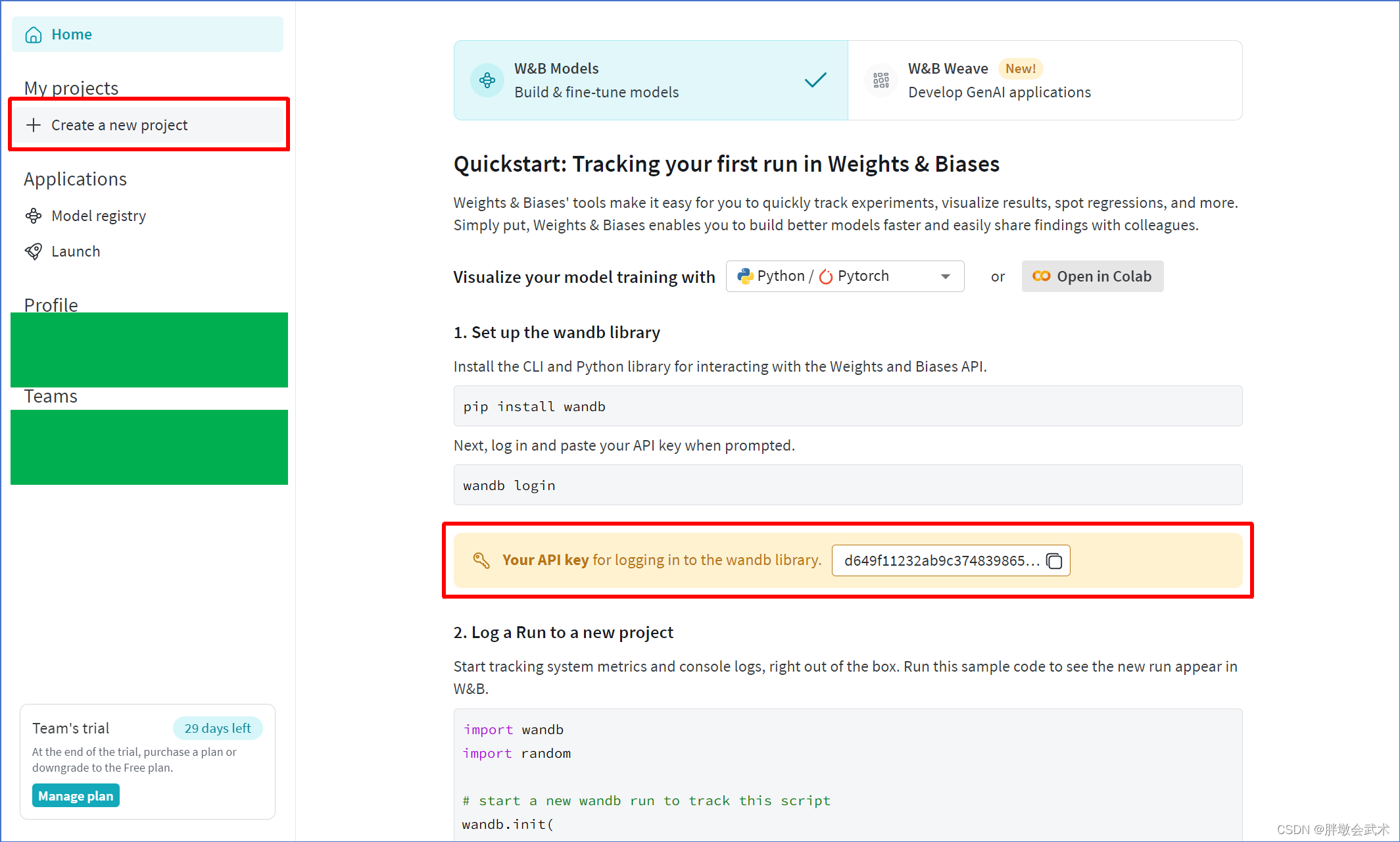
- 新建项目:(在跳转界面的左上角)
create a new project,该项目可以选择私有(Private)、公开(Public)、开放(Open)。
三、wandb安装与登陆(命令行) —— 若不登录,则只保留离线功能
- wandb安装:
pip install wandb。安装成功之后,将在当前虚拟环境下(py39)显示安装包如下:
若需要wandb在线功能,则执行以下步骤。
- wandb登录:
wandb login
(1)若显示如下,则输入命令行:wandb login --relogin。用于更换账号
"""
wandb: Currently logged in as: anony-moose-837920374001732497. Use `wandb login --relogin` to force relogin
"""
(2)若显示如下,则点击第二个链接获取API key(在个人主页的User settings中也可以获取),复制后并在命令行中粘贴(此时命令行没有显示),无需理会直接回车。
"""
wandb: Logging into wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server)
wandb: You can find your API key in your browser here: https://wandb.ai/authorize
wandb: Paste an API key from your profile and hit enter, or press ctrl+c to quit:
"""
(3)若显示如下,登录成功(在C:\Users\Administrator\.netrc路径下可以查看或添加API key)。
"""
wandb: Appending key for api.wandb.ai to your netrc file: C:\Users\Administrator\.netrc
"""
(4)若显示如下,是由于API key失效或丢失,需重新登录。
"""
wandb: W&B API key is configured. Use `wandb login --relogin` to force relogin
wandb: ERROR Error while calling W&B API: user is not logged in (<Response [401]>)
wandb: ERROR The API key you provided is either invalid or missing. If the `WANDB_API_KEY` environment variable is set, make sure it is correct. Otherwise, to resolve this issue, you may try running the 'wandb login --relogin' command. If you are using a local server, make sure that you're using the correct hostname. If you're not sure, you can try logging in again using the 'wandb login --relogin --host [hostname]' command.(Error 401: Unauthorized)
"""

四、函数详解
wandb - Python Library(函数详解 + 参数详解) —— https://docs.wandb.ai/ref/python/
最常用的函数/对象:wandb.init + wandb.config.update() + wandb.log + wandb.finish()。
wandb.init() :初始化一个新的 wandb 实验,并开始记录实验的信息和结果。
wandb.config.update() :更新实验的配置参数。
wandb.log() :记录实验指标和日志信息。
wandb.finish() :结束实验记录。
wandb.save() :保存实验结果和模型文件。
wandb.restore :从 wandb 云存储中恢复实验记录的模型参数或文件。
wandb.watch() :监视模型的梯度和参数。
wandb.Api() :访问 wandb 云服务的 API。
wandb.Table() :创建一个表格对象,用于显示数据。
wandb.plot() :创建并显示图表。
wandb.Image() :创建并显示图像。
wandb.Video() :创建并显示视频。
wandb.Audio() :创建并播放音频。
4.1、wandb.init() —— 初始化一个新的 wandb 实验,并开始记录实验的信息和结果。
"""#########################################################################
函数功能:用于初始化一个新的 wandb 实验,并开始记录实验的信息和结果。
函数说明:wandb.init(project=None, entity=None, group=None, job_type=None, config=None,
tags=None, resume=False, dir=None, name=None, notes=None, id=None,
magic=None, anonymous=None, allow_val_change=False, reinit=False, settings=None,)
参数说明:
project:实验所属的项目名称。
entity:实验所属的实体(例如,团队或用户)。
group:实验的分组名称。
job_type:实验的类型(例如,训练、评估等)。
config:实验的配置参数,可以是一个字典或 Namespace 对象。
tags:实验的标签,可以是一个字符串列表。
resume:如果为 True,则尝试恢复先前的实验。默认为 False。
dir:存储实验数据和日志的目录路径。
name:实验的名称。
notes:实验的说明或注释。
id:实验的唯一标识符。
magic:用于指定特殊功能的魔法命令。
anonymous:如果为 True,则匿名上传实验结果。默认为 False。
allow_val_change:如果为 True,则允许修改已存在的配置参数。默认为 False。
reinit:如果为 True,则重新初始化实验,忽略先前的配置。默认为 False。
settings:一个字典,用于设置实验的其他参数。
返回参数:
一个 wandb.Run 对象,代表当前的实验运行。
#########################################################################"""
4.2、wandb.config.update() —— 更新实验的配置参数
"""#########################################################################
函数功能:用于更新当前实验的配置参数。 ———— 配置参数是在 wandb.init() 函数中指定的,并且可以在实验的整个运行过程中进行更新。
函数说明:wandb.config.update(new_config=None, allow_val_change=None, **kwargs)
参数说明:
new_config:一个字典或 Namespace 对象,包含要更新的配置参数。
allow_val_change:如果为 True,则允许修改已存在的配置参数。默认为 False。
**kwargs:关键字参数,用于更新配置参数。
#########################################################################"""
4.3、wandb.log() —— 记录实验指标和日志信息。
"""#########################################################################
函数功能:用于记录实验中的指标、损失、评估结果、日志信息等,并将它们保存到 Weights & Biases(wandb)平台上,以便后续分析和可视化。
函数说明:wandb.log(data, step=None, commit=True, sync=True)
参数说明:
data:要记录的数据,可以是一个字典、列表、数字、字符串等。通常用于记录指标、损失等信息。
step:可选参数,表示记录的步骤或轮数。如果不提供,则默认为当前步骤或轮数。
commit:可选参数,表示是否立即提交记录。默认为 True,表示立即提交。
sync:可选参数,表示是否同步记录到云端。默认为 True,表示同步记录。
#########################################################################"""
4.4、wandb.finish() —— 结束实验记录。
"""#########################################################################
函数功能:用于结束当前的实验记录,并将记录的数据保存到 wandb平台上。
函数说明:wandb.finish(exit_code: Optional[int] = None, quiet: Optional[bool] = None)
参数说明:
exit_code 设置为 0 以外的值将运行标记为失败
quiet 设置为 true 以最小化日志输出
#########################################################################"""
五、项目实战
wandb教程(示例代码):W&B Tutorials
wandb教程(示例代码 - Jupyter):Intro_to_Weights_&_Biases.ipynb
5.1、入门教程
5.1.1、在Pycharm中可视化结果
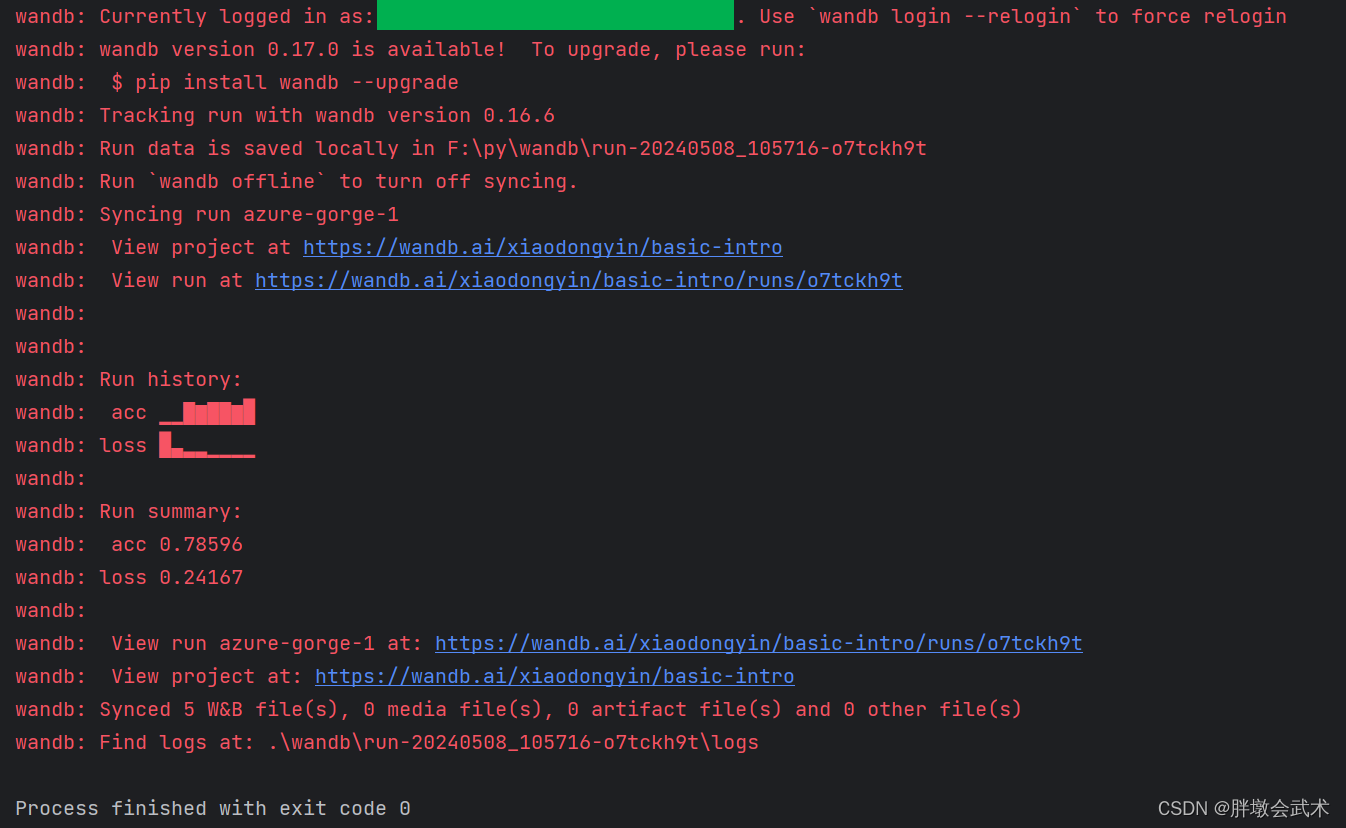
import wandb
import random
# 🐝 1️⃣ Start a new run to track this script
wandb.init(
# Set the project where this run will be logged
project="basic-intro",
# We pass a run name (otherwise it’ll be randomly assigned, like sunshine-lollypop-10)
name=f"experiment",
# Track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
# This simple block simulates a training loop logging metrics
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# 🐝 2️⃣ Log metrics from your script to W&B
wandb.log({"acc": acc, "loss": loss})
# Mark the run as finished
wandb.finish()
5.1.2、在仪表盘中可视化结果(网页)
仪表盘(Dashboard):是 wandb 提供的一个可视化界面,用户可以在网页浏览器中访问,并通过它查看、分析和管理实验结果。在仪表盘上,用户可以看到实验的指标、损失曲线、模型参数、日志信息等,并可以进行比较、筛选、筛选和导出等操作。
- 备注:若登陆(在线版本),则在个人主页的Profile - Projects中保存实验记录,且每运行一次都将新增一条可视化数据,而不是只保留最近一次的运行结果。
- 备注:若不登陆(离线版本);
- 备注:无论是否登录,都将在当前路径下自动新建一个wandb文件夹,且每运行一次都将新增一个保存实验记录的文件夹。
运行三次后的显示结果如下:
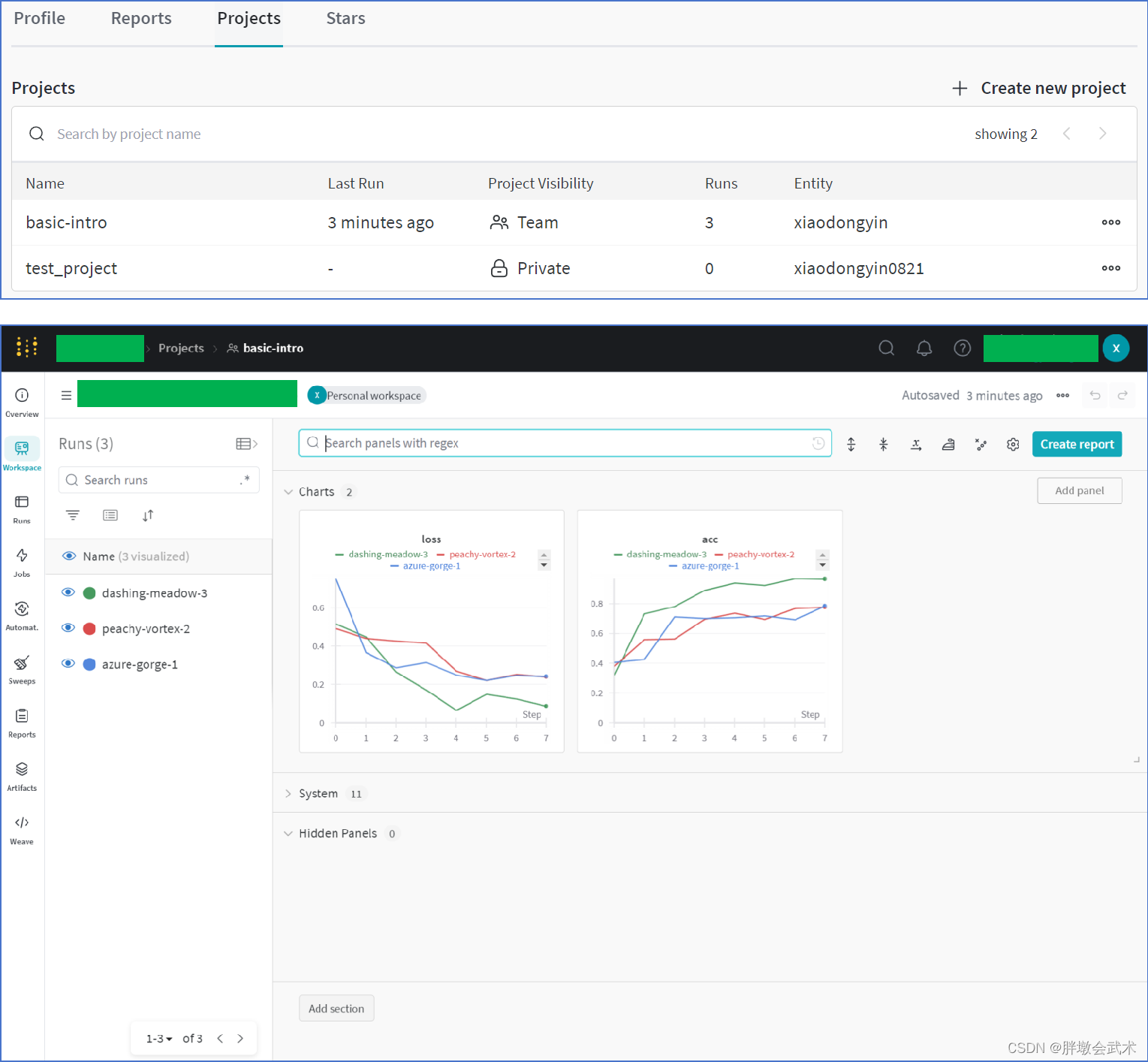
5.2、简单的 Pytorch 神经网络
wandb教程(示例代码):W&B Tutorials
wandb教程(示例代码 - Jupyter):Intro_to_Weights_&_Biases.ipynb
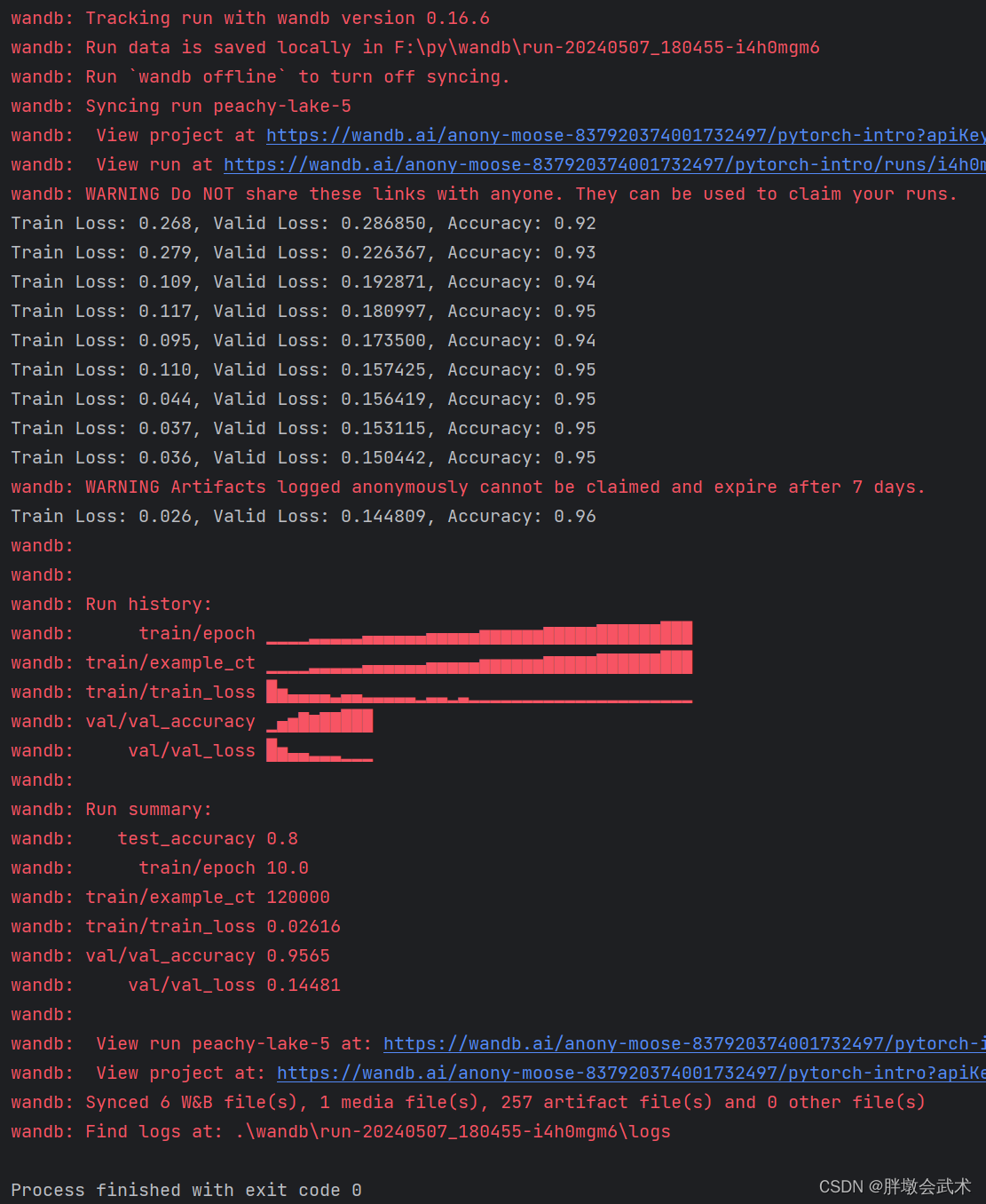
import wandb
import math
import random
import torch, torchvision
import torch.nn as nn
import torchvision.transforms as T
device = "cuda:0" if torch.cuda.is_available() else "cpu"
def get_dataloader(is_train, batch_size, slice=5):
"Get a training dataloader"
full_dataset = torchvision.datasets.MNIST(root=".", train=is_train, transform=T.ToTensor(), download=True)
sub_dataset = torch.utils.data.Subset(full_dataset, indices=range(0, len(full_dataset), slice))
loader = torch.utils.data.DataLoader(dataset=sub_dataset,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True, num_workers=2)
return loader
def get_model(dropout):
"A simple model"
model = nn.Sequential(nn.Flatten(),
nn.Linear(28*28, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(256,10)).to(device)
return model
def validate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0):
"Compute performance of the model on the validation dataset and log a wandb.Table"
model.eval()
val_loss = 0.
with torch.inference_mode():
correct = 0
for i, (images, labels) in enumerate(valid_dl):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
val_loss += loss_func(outputs, labels)*labels.size(0)
# Compute accuracy and accumulate
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
# Log one batch of images to the dashboard, always same batch_idx.
if i==batch_idx and log_images:
log_image_table(images, predicted, labels, outputs.softmax(dim=1))
return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset)
def log_image_table(images, predicted, labels, probs):
"Log a wandb.Table with (img, pred, target, scores)"
# 🐝 Create a wandb Table to log images, labels and predictions to
table = wandb.Table(columns=["image", "pred", "target"]+[f"score_{i}" for i in range(10)])
for img, pred, targ, prob in zip(images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu")):
table.add_data(wandb.Image(img[0].numpy()*255), pred, targ, *prob.numpy())
wandb.log({"predictions_table":table}, commit=False)
if __name__ == "__main__":
# Launch 5 experiments, trying different dropout rates
for _ in range(5):
# 🐝 initialise a wandb run
wandb.init(
project="pytorch-intro",
config={
"epochs": 10,
"batch_size": 128,
"lr": 1e-3,
"dropout": random.uniform(0.01, 0.80),
})
# Copy your config
config = wandb.config
# Get the data
train_dl = get_dataloader(is_train=True, batch_size=config.batch_size)
valid_dl = get_dataloader(is_train=False, batch_size=2 * config.batch_size)
n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size)
# A simple MLP model
model = get_model(config.dropout)
# Make the loss and optimizer
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)
# Training
example_ct = 0
step_ct = 0
for epoch in range(config.epochs):
model.train()
for step, (images, labels) in enumerate(train_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss_func(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
example_ct += len(images)
metrics = {"train/train_loss": train_loss,
"train/epoch": (step + 1 + (n_steps_per_epoch * epoch)) / n_steps_per_epoch,
"train/example_ct": example_ct}
if step + 1 < n_steps_per_epoch:
# 🐝 Log train metrics to wandb
wandb.log(metrics)
step_ct += 1
val_loss, accuracy = validate_model(model, valid_dl, loss_func, log_images=(epoch == (config.epochs - 1)))
# 🐝 Log train and validation metrics to wandb
val_metrics = {"val/val_loss": val_loss,
"val/val_accuracy": accuracy}
wandb.log({**metrics, **val_metrics})
print(f"Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}")
# If you had a test set, this is how you could log it as a Summary metric
wandb.summary['test_accuracy'] = 0.8
# 🐝 Close your wandb run
wandb.finish()