前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了 Transformer 的主要功能、总体架构、相关组件等。
目录
前言
一、Transformer
1、Transformer 的顶层设计
2、编码器与解码器的输入
3、自注意力
4、多头注意力
5、自注意力与 RNN、CNN 的异同
6、加深 Transformer 网络层
7、如何进行自监督学习
一、Transformer
Transformer 是 Google 在 2017 年的论文 Attention is all you need 中提出的一种新架构,它基于自注意力机制的深层模型,在包括机器翻译在内的多项 NLP 任务上效果显著,超过 RNN 且训练速度更快。不到一年时间,Transformer 已经取代 RNN 中成绩最好的模型,包括谷歌、微软、百度、阿里、腾讯等公司的线上机器翻译模型都替换为 Transformer 模型。它不但在自然语言处理方面刷新多项纪录,在搜索排序、推荐系统,甚至图形处理领域都非常活跃。Transformer 为何能如此成功?用了哪些神奇的技术或方法?背后的逻辑是什么?接下来我们详细说明。
1、Transformer 的顶层设计
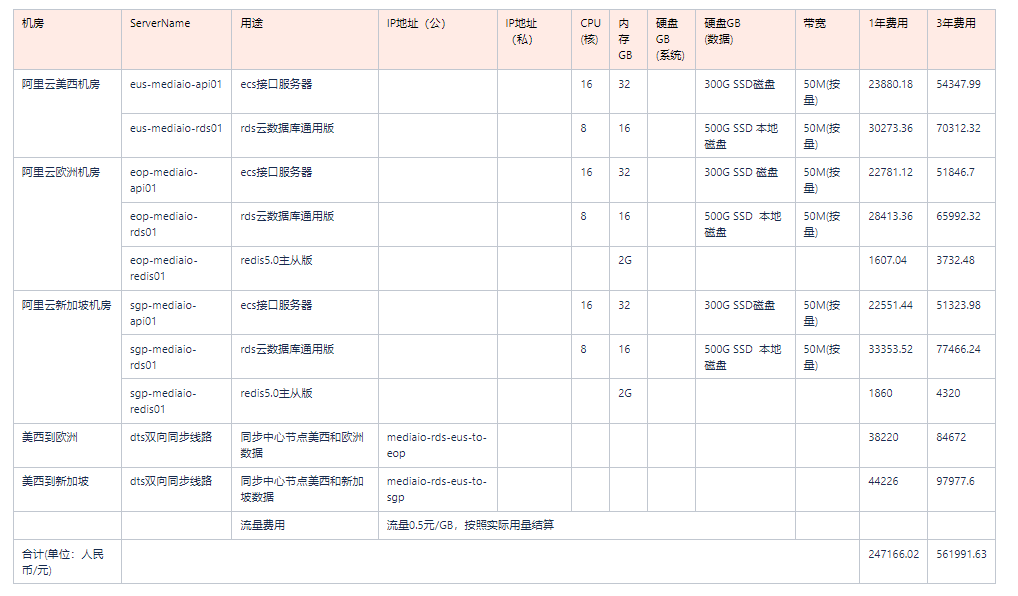
我们先从 Transformer 的功能说起,然后介绍其总体架构,再对各个组件进行分解,详细说明 Transformer 的功能及如何高效实现这些功能。如果我们把 Transformer 应用于语言翻译,比如把一句法语翻译成一句英语,实现过程如图 8-10 所示。

图 8-10 中的 Transformer 就像一个黑盒子,它接收一条语句,然后将其转换为另外一条语句。此外,Transformer 还可用于阅读理解、问答、词语分类等 NLP 问题。这个黑盒子是如何工作的呢?它由哪些组件构成?这些组件又是如何工作的呢?
我们进一步打开这个黑盒子。其实 Transformer 就是一个由编码器组件和解码器组件构成的模型,这与我们通常看到的语言翻译模型类似,如图 8-11 所示。以前我们通常使用循环神经网络或卷积神经网络作为编码器和解码器的网络结构,不过 Transformer 中的编码器组件和解码器组件既不用卷积神经网络,也不用循环神经网络。
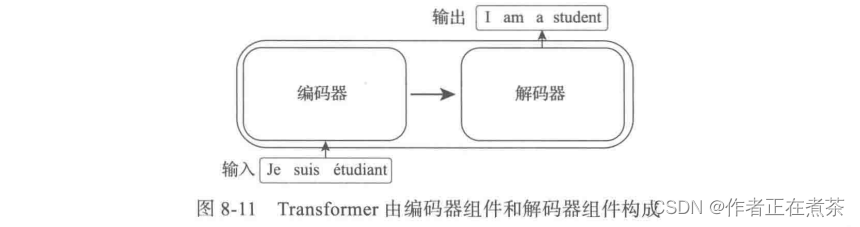
图 8-11 中的编码器组件由 6 个相同结构的编码器串联而成,解码器组件也是由 6 个相同结构的解码器串联而成,如图 8-12 所示。
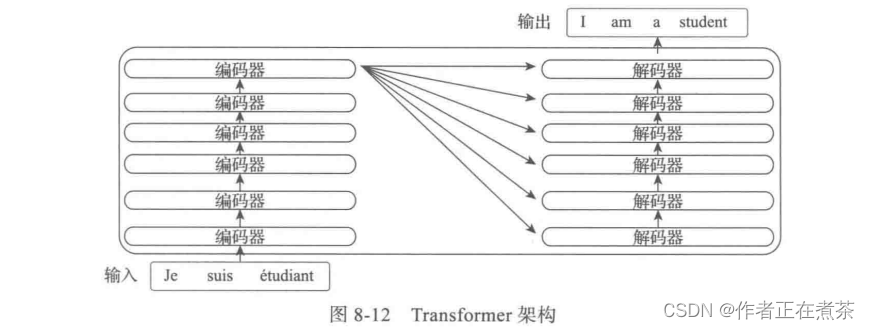
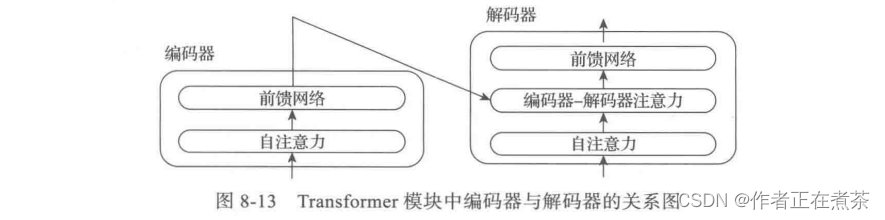
最后一层编码器的输出将传入解码器的每一层,再进一步打开编码器及解码器,每个编码器由一层自注意力和一层前馈网络构成,而解码器除了自注意力层、前馈网络层外,中间还有一层用来接收最后一个编码器的输出值,如图 8-13 所示。
到这里为止,我们已经对 Transformer 的大致结构进行了直观说明,接下来将从一些主要问题入手对各层细节进行说明。
2、编码器与解码器的输入
前面我们介绍了 Transformer 的大致结构,在构成其编码器或解码器的网络结构中,并没有使用循环神经网络和卷积神经网络。但是像语言翻译类问题,语句中各单词的次序或位置是非常重要的因素,单词的位置与单词的语言有直接关系。如果使用循环神经网络,一个句子中各单词的次序或位置问题能自然解决,那么在 Transformer 中是如何解决语句各单词的次序或位置关系的呢?
Transformer 使用位置编码 Position Encoding 方法来记录各单词在语句中的位置或次序,位置编码的值遵循一定模型(如由三角函数生成)、每个源单词(或目标单词)的词嵌入与对应的位置编码相加(位置编码向量与词嵌入的维度相同),如图 8-14 所示。
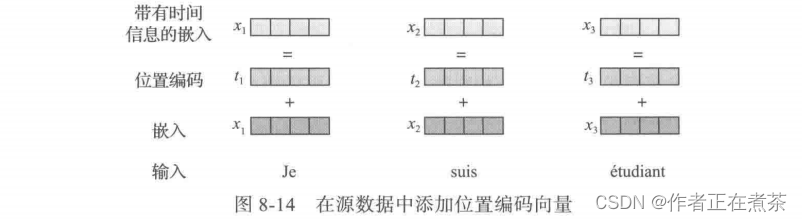
对解码器的输入(即目标数据)也需要做同样处理,即在目标数据基础上加上位置编码成为 带有时间信息的嵌入 。当对语料库进行批量处理时,可能会遇到 长度不一致的语句 。对于太短的语句,可以用填充的方法补齐,如用 0 填充;对于太长的语句,可以采用截尾的方法,如给这些位置赋予一个很大的负数,使之在进行 softmax 运算时为 0 。
3、自注意力
首先来看一下通过 Transformer 作用的效果图,那么对于输入语句 “ The animal didn't cross the street because it was too tired ” 该如何判断 it 是指 animal 还是指 street ?这个问题对人来说很简单,但对算法来说就不那么简单了。但 Transformer 中的自注意力能让机器把 it 和 animal 联系起来,其效果如图 8-15 所示。编码器组件中的顶层(即 #5 层,#0 表示第 1 层)it 单词对 the animal 的关注度明显大于对其他单词的关注度。这些关注度是如何获取的呢?接下来进行详细介绍。

8.1 节介绍的一般注意力机制计算注意力的方法与 Transformer 采用自注意力机制的计算方法基本相同,只是查询的来源不同。一般注意力机制中的查询来源于目标语句,而非源语句。自注意力机制的查询来源于源语句本身,而非目标语句(如翻译后的语句)。
编码器模块中自注意力的主要计算步骤如下(解码器模块中的自注意力计算步骤与此类似):
1)把输入单词转换为带时间(或时序)信息的嵌入向量;
2)根据嵌入向量生成 q 、k 、v 三个向量,这三个向量分别表示查询、键、值;
3)根据 q ,计算每个单词进行点积得到对应的得分 score = q · k ;
4)对 score 进行规范化、softmax 处理,假设结果为 a ;
5)a 点积对应的 v ,然后累加得到当前语句各单词之间的自注意力 z = ∑ a v 。
这部分是 Transformer 的核心内容,为了便于理解,对以上步骤进行可视化。假设当前待翻译的语句为:Thinking Machines。对单词 Thinking 进行预处理后用 表示,对单词 Machines 进行预处理后用
表示。计算单词 Thinking 与当前语句中各单词的注意力或得分,如图 8-16 所示。( 预处理 = 词嵌入 + 位置编码得到嵌入向量 Embedding )
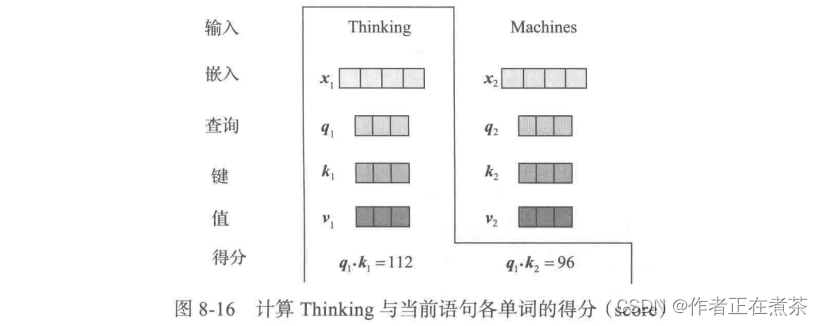
假设各嵌入向量的维度为 ,这个值通常较大,为 512 ;而 q 、k 、v 的维度比较小,通常满足:
其中,h 表示 h 个 head,后面将介绍 head 的含义,论文中 h = 8 , = 512 ,故
= 64 ,而
= 8。
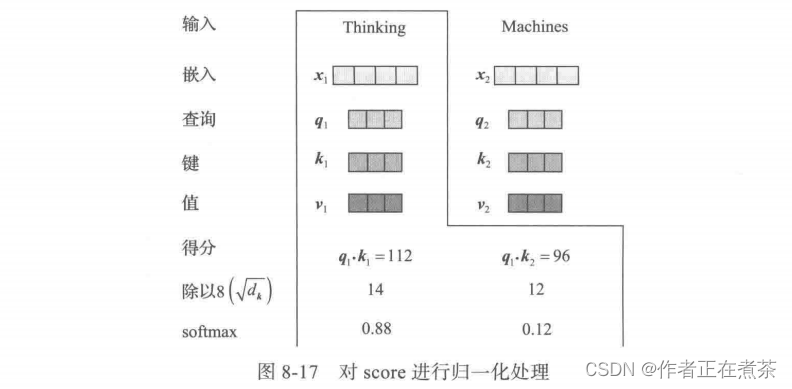
实际计算得到的 score 可能较大,为保证计算梯度时不因此影响其稳定性,需要进行归一化操作,即除以 ,如图 8-17 所示。
对归一化处理后的 a 与 v 相乘再累加,就得到 z ,如图 8-18 所示。
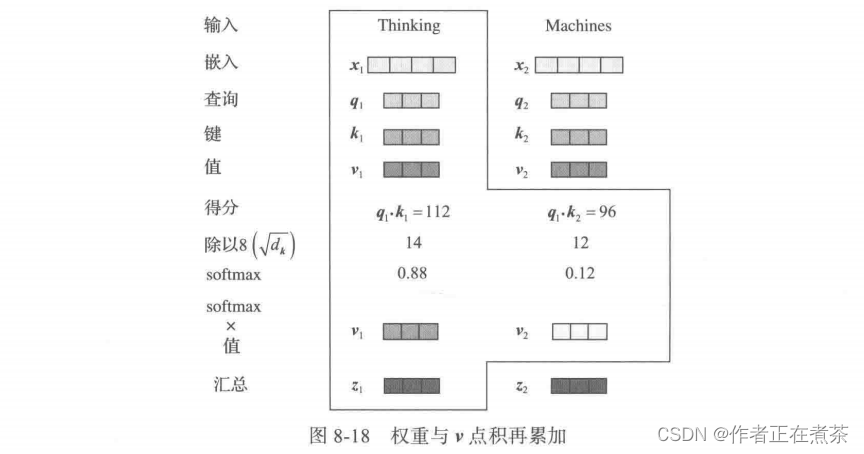
这样就得到单词 Thinking 对当前语句各单词的注意力或关注度 ,同样可以计算单词 Machines 对当前语句各单词的注意力
。
上面这些都是基于向量进行运算的,而且没有像循环神经网络中的左右依赖关系,如果把向量堆砌成矩阵,那就可以使用并发处理或 GPU 的功能,将自注意力转换为矩阵的计算过程如图 8-19 所示。
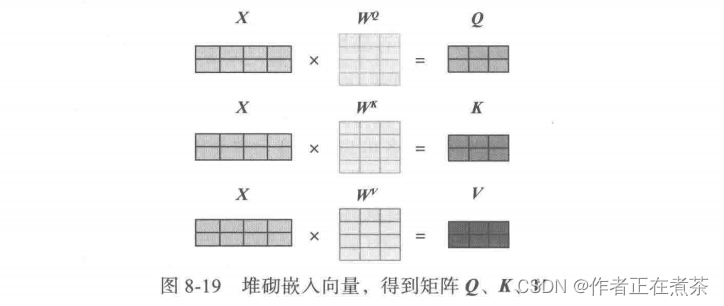
把嵌入向量堆叠成矩阵 X ,然后分别与矩阵 、
、
(可学习的矩阵,与神经网络中的权重矩阵类似)得到 Q 、K 、V 。
在此基础上,上面计算注意力的过程就可以简写为图 8-20 的格式。

整个计算过程也可以用图 8-21 表示,这个过程又称为 缩放的点积注意力(Scaled Dot-Product Attention)过程 。
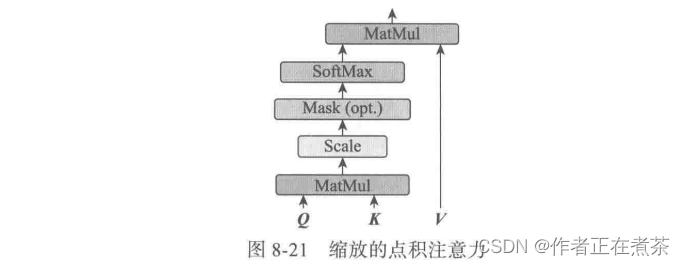
图 8-21 中的 MatMul 就是点积运算,Mask 表示掩码,用于对某些值进行掩盖,使其在参数更新时不产生效果。
Transformer 模型里面涉及两种 Mask ,分别是 Padding Mask 和 Sequence Mask 。
- Padding Mask 在所有缩放的点积注意力中都需要用到,用于处理长短不一的语句;
- Sequence Mask 只有在解码器的自注意力中需要用到,以防止解码器预测目标值时,看到未来的值。
在具体实现时,通过乘以一个上三角形矩阵实现,上三角的值全为 0 ,把这个矩阵作用在每一个序列上。
4、多头注意力
在图 8-15 中有 8 种不同颜色,它们分别表示什么含义呢?每种颜色都类似于卷积神经网络中的一种通道或一个卷积核,在卷积神经网络中,一种通道往往表示一种风格。受此启发,AI 科研人员在计算自注意力时也采用类似方法,这就是我们下面要介绍的 多头注意力(Multi-Head Attention),其架构如图 8-22 所示。
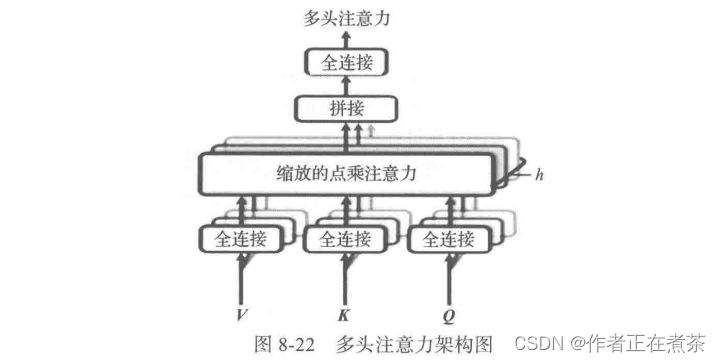
利用多头注意力机制可以从以下 3 个方面提升注意力层的性能:
1)它扩展了模型专注于不同位置的能力。
2)将缩放的点积注意力过程做 h 次,再把输出合并起来。
3)它为关注层 attention layer 提供了多个 “ 表示子空间 ” 。在多头注意力机制中,有多组查询、键、值权重矩阵,Transformer 使用 8 个关注头,因此每个编码器 / 解码器最终得到 8 组,这些矩阵都是随机初始化的。在训练之后,将每个集合用于输入的嵌入或来自较低编码器 / 解码器的向量投影到不同的表示子空间中。这个原理和使用不同卷积核把源图像投影到不同风格的子空间一样。
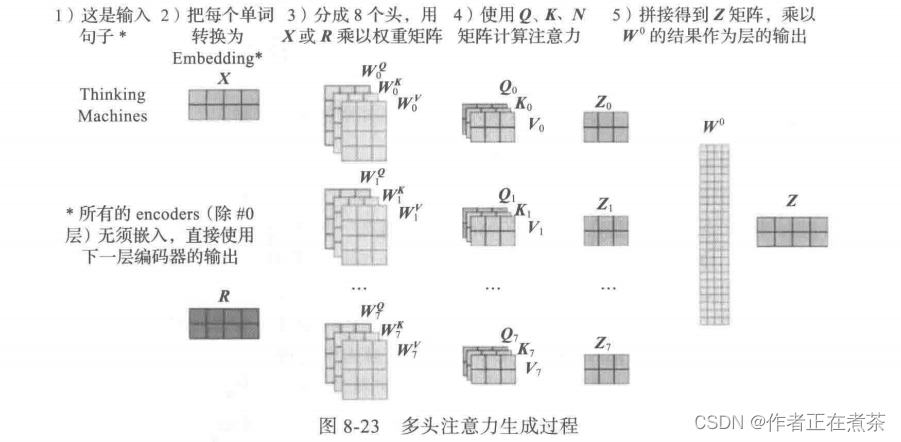
多头注意力机制的运算过程如下:
1)随机初始化 8 组矩阵:、
、
,
;
2)使用 X 与这 8 组矩阵相乘,得到 8 组 、
、
,
;
3)由此得到 8 个 ,
,然后把这 8 个
组合成一个大的
;
4)Z 与初始化的矩阵
相乘,得到最终输出值 Z 。
上面这些步骤可以用图 8-23 来直观表示。
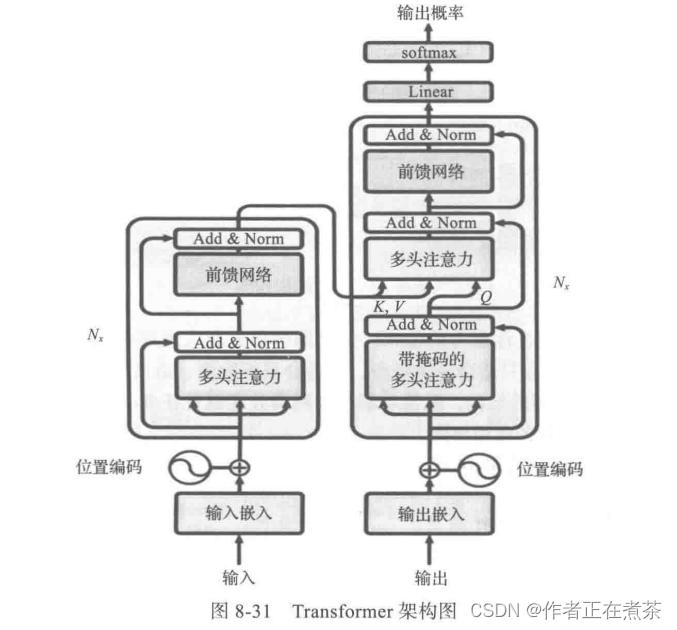
由前面的图 8-13 可知,解码器比编码器多了个 编码器-解码器注意力机制 。在编码器-解码器注意力中,Q 来自解码器的上一个输出,K 和 V 则来自编码器的最后一层输出,其计算过程和自注意力的计算过程相同。
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第 k 个特征向量时,我们只能看到第 k-1 个特征向量及其之前的解码结果,因此论文中把这种情况下的多头注意力叫做 带掩码的多头注意力(Masked Multi-Head Attention),即同时使用了 Padding Mask 和 Sequence Mask 两种方法。
5、自注意力与 RNN、CNN 的异同
从以上分析可以看出,自注意力机制没有前后依赖关系,可以基于矩阵进行高并发处理,除此之外,每个单词的输出与前一层各单词的距离都为 1 ,如图 8-24 所示,说明不存在梯度消失问题,因此 Transformer 就具备了高并发和长记忆的强大功能!
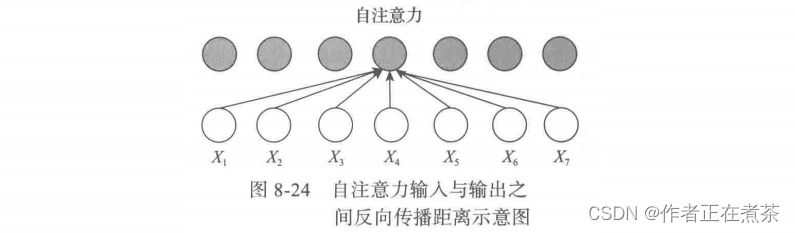
这是自注意力处理序列的主要逻辑:没有前后依赖,每个单词都通过自注意力直接连接到任何其他单词。因此,可以并行计算,且最大路径长度是 O(1) 。而循环神经网络处理序列的逻辑如图 8-25 所示。
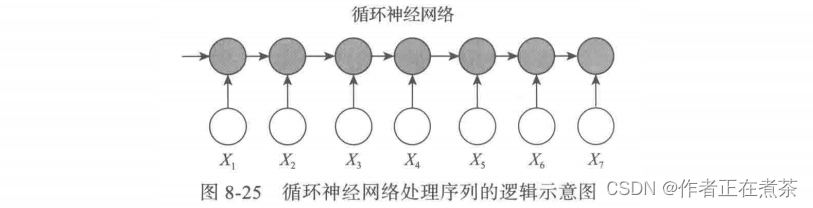
由图 8-25 可知,更新循环神经网络的隐状态时,需要依赖前面的单词,如处理单词 时,需要先处理单词
、
,因此循环神经网络的操作是顺序操作且无法并行化,其最大依赖路径长度是 O(n) ,n 表示时间步长。
卷积神经网络也可以处理序列问题,其处理逻辑如图 8-26 所示。
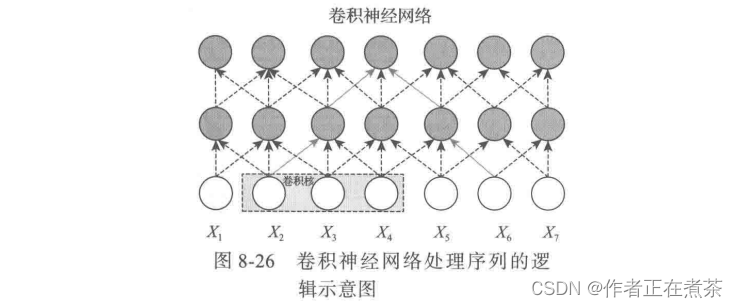
如图 8-26 所示,这是一个卷积核大小 K 为 3 的两层卷积神经网络,共有 O(1) 个顺序操作,其最大依赖路径长度为 O(n/k) ,n 表示序列长度,单词 和
处于卷积神经网络的感受野内。
6、加深 Transformer 网络层
从前面的图 8-12 可知,Transformer 的编码器组件和解码器组件分别有 6 层,有些应用中可能有更多层。随着层数的增加,网络的容量更大,表达能力也更强,但网络的收敛速度会更慢、更易出现梯度消失等问题,那么 Transformer 是如何克服这些不足的呢?
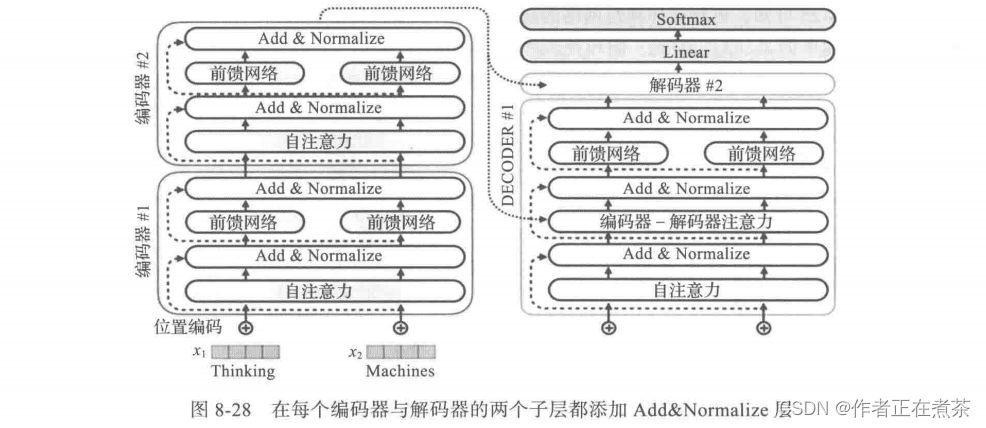
Transformer 采用了两种常用的方法: 残差连接(residual connection)和 归一化方法(normalization)。具体实现方法就是在每个编码器或解码器的两个子层,即自注意力层和前馈神经网络(FFMM),增加由残差连接和归一化组成的层,如图 8-27 所示。
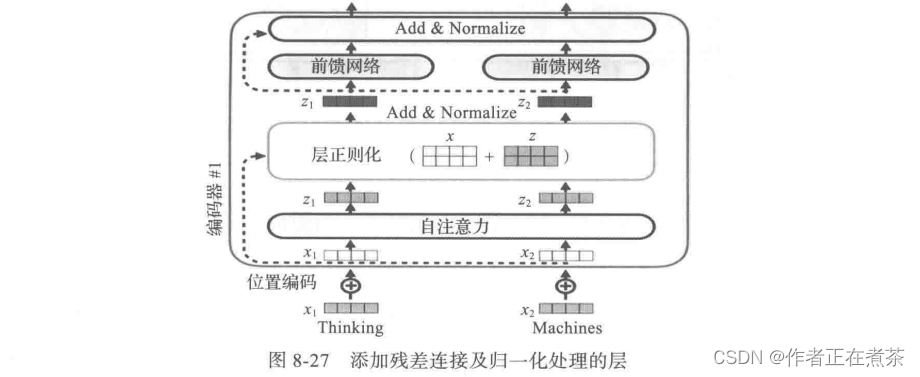
对每个编码器都做同样处理,对每个解码器也做同样处理,如图 8-28 所示。
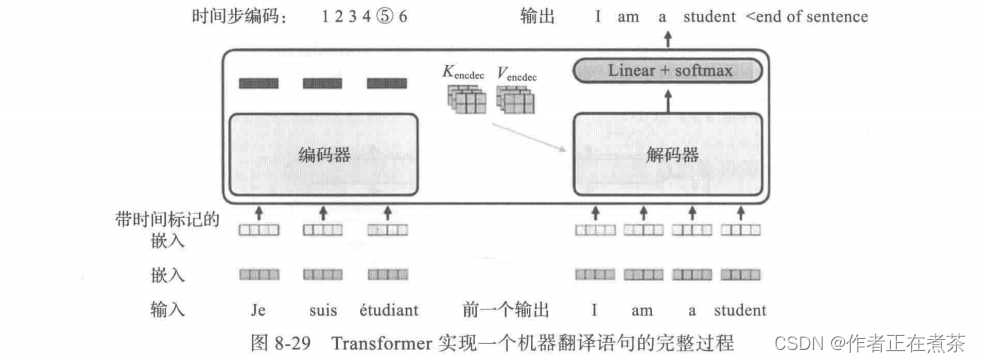
编码器与解码器如何协调完成一个机器翻译任务?其完整过程如图 8-29 所示。
7、如何进行自监督学习
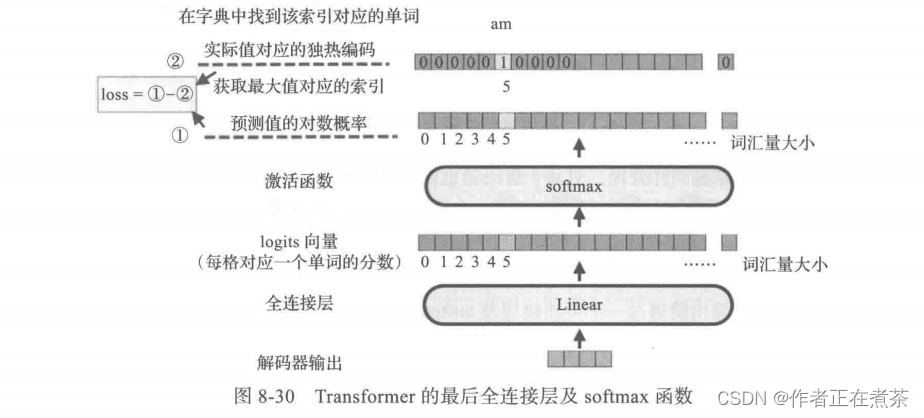
编码器最后的输出值通过一个全连接层及 softmax 函数作用后就得到预测值的对数概率,如图 8-30 所示,这里假设采用贪婪解码的方法,即使用 argmax 函数获取概率最大值对应的索引。预测值的对数概率与实际值对应的独热编码的差就构成模型的损失函数。
综上所述,Transformer 模型由编码器组件和解码器组件构成,每个编码器组件又由 6 个 EncoderLayer 组成,每个 EncoderLayer 包含一个自注意力 SubLayer 层和一个全连接 SubLayer 层。解码器组件也同样是由 6 个 DecoderLayer 组成,每个 DecoderLayer 包含一个自注意力 SubLayer 层、一个注意力 SubLayer 层和一个全连接 SubLayer 层。其完整架构如图 8-31 所示。