大模型的基础模式是transformer,所以很多芯片都实现先专门的transformer引擎来加速模型训练或者推理。本文将拆解Transformer的算子组成,展开具体的数据流分析,结合不同的芯片架构实现,分析如何做性能优化。
Transformer结构
transformer结构包含两个过程,Encoder和Decoder。其中Decoder较Encoder结构相同,多了对于kv_cache的处理。
如下图经典的结构示意图,可以看到在Decoder阶段的Multi-Head Attentiond的三个输入箭头其中两个来自Encoderde输出,关于kv-cache对内容管理的优化也是一个很重要的研究方向。本文暂时重点关注与Transformer的Encoder阶段的优化分析。

Transformer的数据流图
下图对应上面transformer的左边Encoder阶段。不同颜色表示不同的算子,其中linear, 其实也是一种matmul算子,只不过它的两个输入一个来自tensor, 一个来自常量。蓝色标记的matmul算子则两个输入全部是tensor。
包含的算子为:linear, matmul, transpose, softmax, add_layernorm。
通过代入参数,了解具体的数据流执行过程,可以让我们更加直观的理解下面的优化之后,得到相同的输出数据的思路。

优化设计1:图优化
根据上面的数据流图可以发现,transpose算子只是对数据进行重排,并不需要计算,但是过多的transpose算子需要不停从内存搬移数据,消耗紧缺的带宽资源,所以一个简单的优化点就是通过硬件架构的设计,来减少transpose层。
对硬件来说,在实现GEMM算子是的时候,对两个矩阵取数过程,增加一个transpose的逻辑, 不会消耗很多的资源,所以可以对GEMM的两个输入数据,分别设计是否打开transpose的参数。
假设GEMM算子原始的数据存放排布矩阵A为(batch, M, K), 矩阵B为(batch, K, N)。得到的输出为(Batch, M , N)。下面对transpose的多头注意力模块进行优化,示例了两种方案,来减少单独的transpose算子开销。
transpose前置(A_transpose_en)
利用矩阵A的transpose开关,将q, k, v的transpose前置, 数据流图如下,这样可以将原本的5个transpose操作减小为2个。
注意图中用红色和蓝色标记了GEMM算子的矩阵A,矩阵B的设定,当一个linear或者matmul算子的两个输入中显示(Batch, K, M)时候,即认为打开了GEMM算子的A矩阵transpose开关

transpose内置(B_transpose_en)
当利用B矩阵的transpose_en功能,优化后的数据流图如下。在QV的matmul计算过程,逆向利用矩阵B的transpose开关,这样可以将原本的5个transpose操作减小为1个。
当一个linear或者matmul算子的两个输入中显示(Batch, N, K)时候,即认为打开了GEMM算子的B矩阵transpose开关
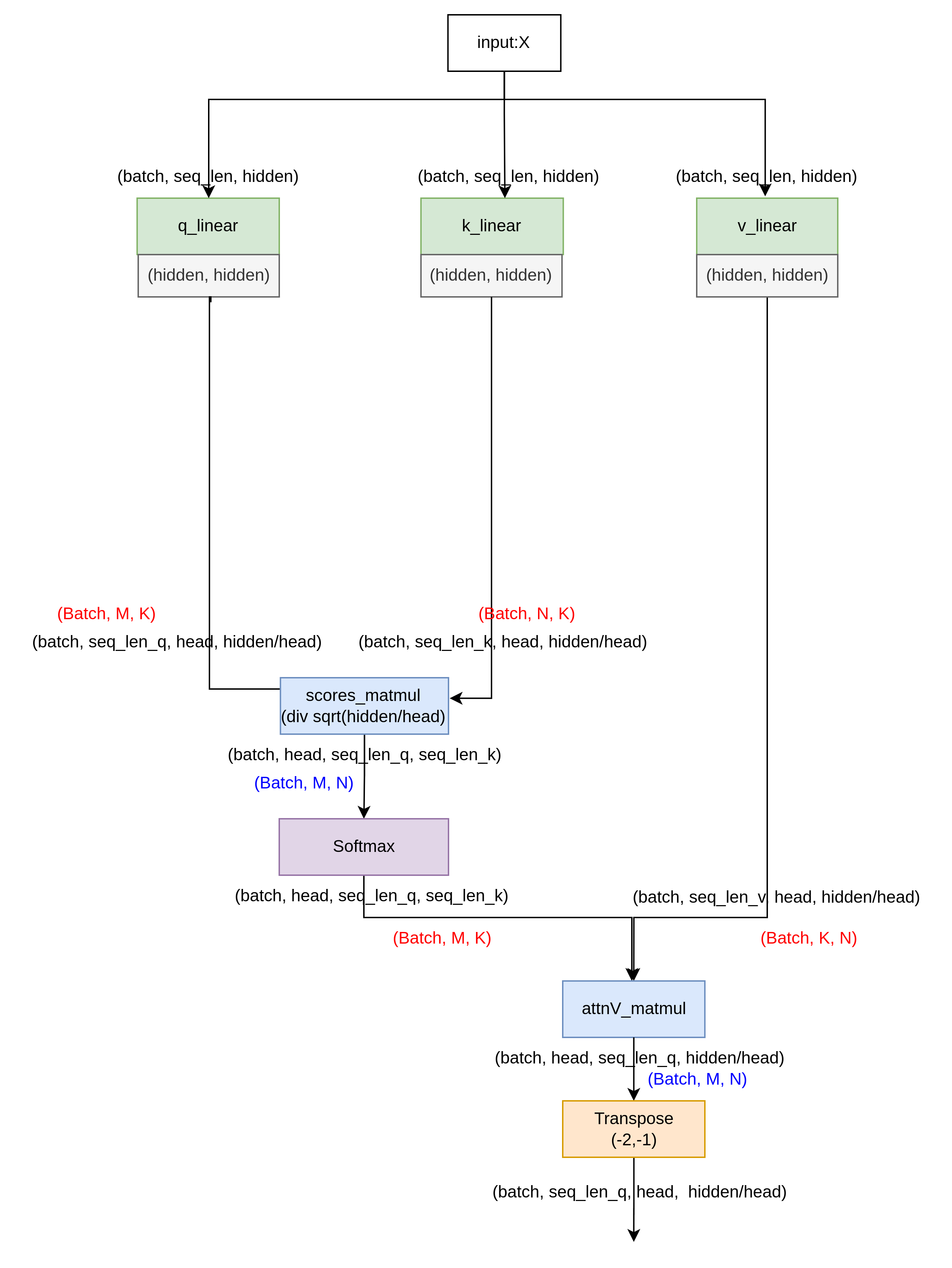
通过上面两个方案,大家可能会对attnV_matmul那一步的数据流关于head位置有点疑问,在这里我们不妨这样考虑,将head分给多个thread线程来做,只要thread的数据位置取的对,是可以将(batch, head,seq_len_q, seq_len_k)和(batch, seq_len_v, head, hidden/head)进行矩阵乘得到(batch, head, seq_len_q, hidden/head)的输出的。
优化设计2:任务并行拆解
模型的分布式并行策略有数据并行,张量并行,pipline 并行等,这些策略的一个要点就是合理利用集群资源,让更多的任务并行基础上,减少中间节点的数据通信。
当我们在一个有很多节点的集群上部署大模型时候,因为模型数据维度较大,往往需要将其拆解到不同的芯片(集群)运行,尤其是GEMM算子,不同的拆分方案对应不同的通信开销。下面我们来具体分析一个任务并行的拆解方案。
如图,首先针对attention模块的多头特征,选择在qkv_linear的weights的outZ方向切分为head份,假设有head个计算节点,每个节点计算1个head的matmul任务,因为没有在累加的维度拆分,所以这样每个节点可以顺序执行下一层任务,不需要交互数据。直到attnV_matmul之后,需要做fc0_linear的任务,要把所有的head合并起来累加运算,所以增加了all_gather的通信开销。接着为了避免通信开销,fc0和add_layernorm选择在seq维度拆分。当到达fc1_linear,对depth_hidden进行了拆分,但是fc2_linear需要对所有的depth_hidden进行累加,所以fc2_linear之前需要再一次的all_gather通信。

当然根据具体的硬件条件限制,还可以有其他的任务拆解方案,总之,需要具体场景具体分析。这里仅做简单的优化示例参考。
欢迎评论交流,如果觉得内容有帮助,需要您的点赞鼓励!