在高可用的三大架构设计(基于数据层的高可用、基于业务层的高可用,以及融合的高可用架构设计)中。仅仅解决了业务连续性的问题:也就是当服务器因为各种原因,发生宕机,导致MySQL 数据库不可用之后,快速恢复业务。但对有状态的数据库服务来说,在一些核心业务系统中,比如电商、金融等,还要保证数据一致性。
这里的“数据一致性”是指在任何灾难场景下,一条数据都不允许丢失(一般也把这种数据复制方式叫作“强同步”)。
本篇文章我们就来看一看,怎么在这种最高要求(数据一致性)的业务场景中,设计 MySQL 的高可用架构。
一、复制类型的选择
在前面的文章中,我们已经知道银行、保险、证券等核心业务,需要严格保障数据一致性。那么要想实现数据的强同步,在进行复制的配置时,就要使用无损半同步复制模式。
在 MySQL 内部就是要把参数 rpl_semi_sync_master_wait_point 设置成 AFTER_SYNC 。
但是在高可用设计时,当数据库 FAILOVER 完后,有时还要对原来的主机做额外的操作,这样才能保证主从数据的完全一致性。
我们来看这样一张图:  从图中可以看到,即使启用无损半同步复制,依然存在当发生主机宕机时,最后一组事务没有上传到从机的可能。图中宕机的主机已经提交事务到 101,但是从机只接收到事务 100。如果这个时候 Failover,从机提升为主机,那么这时:
从图中可以看到,即使启用无损半同步复制,依然存在当发生主机宕机时,最后一组事务没有上传到从机的可能。图中宕机的主机已经提交事务到 101,但是从机只接收到事务 100。如果这个时候 Failover,从机提升为主机,那么这时: 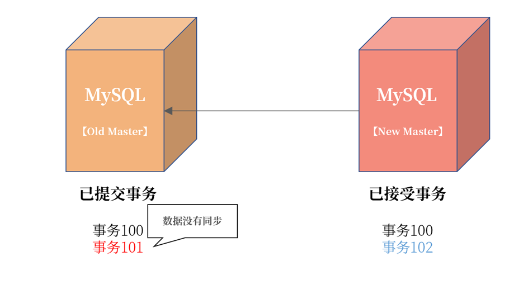 可以看到当主从切换完成后,新的 MySQL 开始写入新的事务102,如果这时老的主服务器从宕机中恢复,则这时事务 101 不会同步
可以看到当主从切换完成后,新的 MySQL 开始写入新的事务102,如果这时老的主服务器从宕机中恢复,则这时事务 101 不会同步










![Siemens-NXUG二次开发-创建倒斜角特征、边倒圆角特征、设置对象颜色、获取面信息[Python UF][20240605]](https://img-blog.csdnimg.cn/direct/c66932754f984fa9be468a8f2fcb403e.png#pic_center)

