计划
这应该是第3章的读书笔记,但是因为第3章读起来比较困难,所以先看了《CUDA并行程序设计编程指南》的第5章和第6章,感觉读起来顺畅多了,《CUDA并行程序设计编程指南》暂定精读第5、6、7章
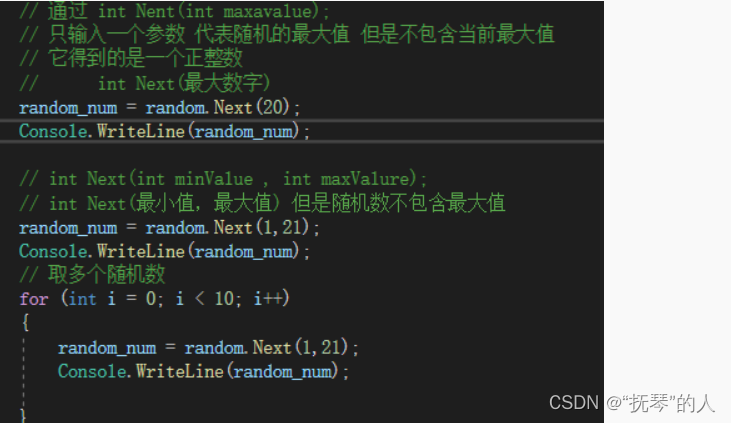
1.如何生成ptx文件
属性➔CUDA C/C++➔Common➔Keep Preprocess Files➔是(–keep)
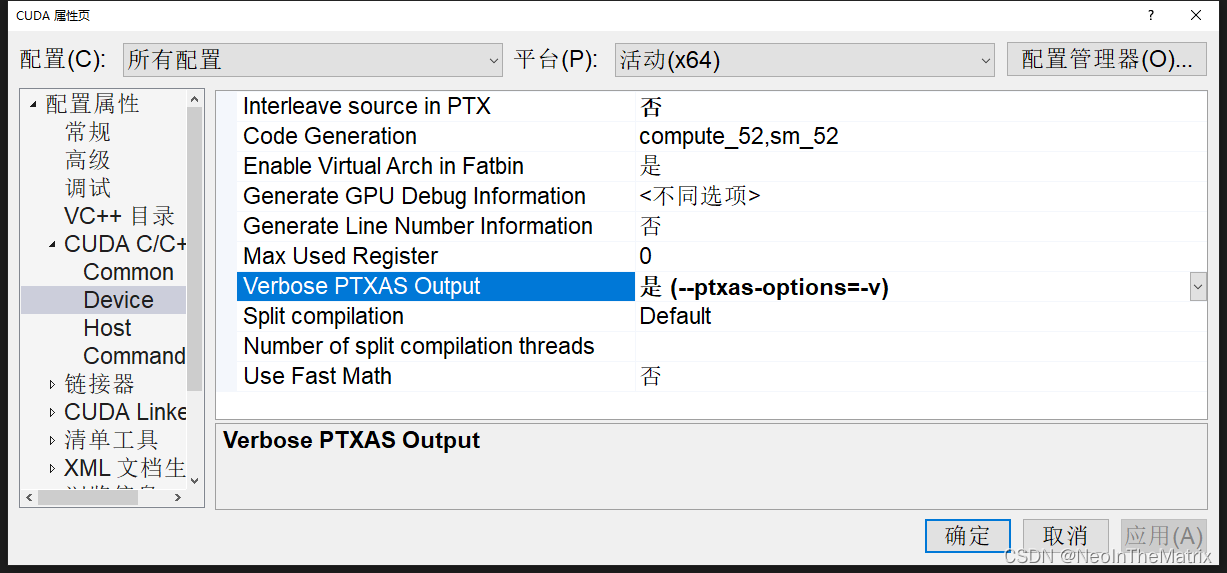
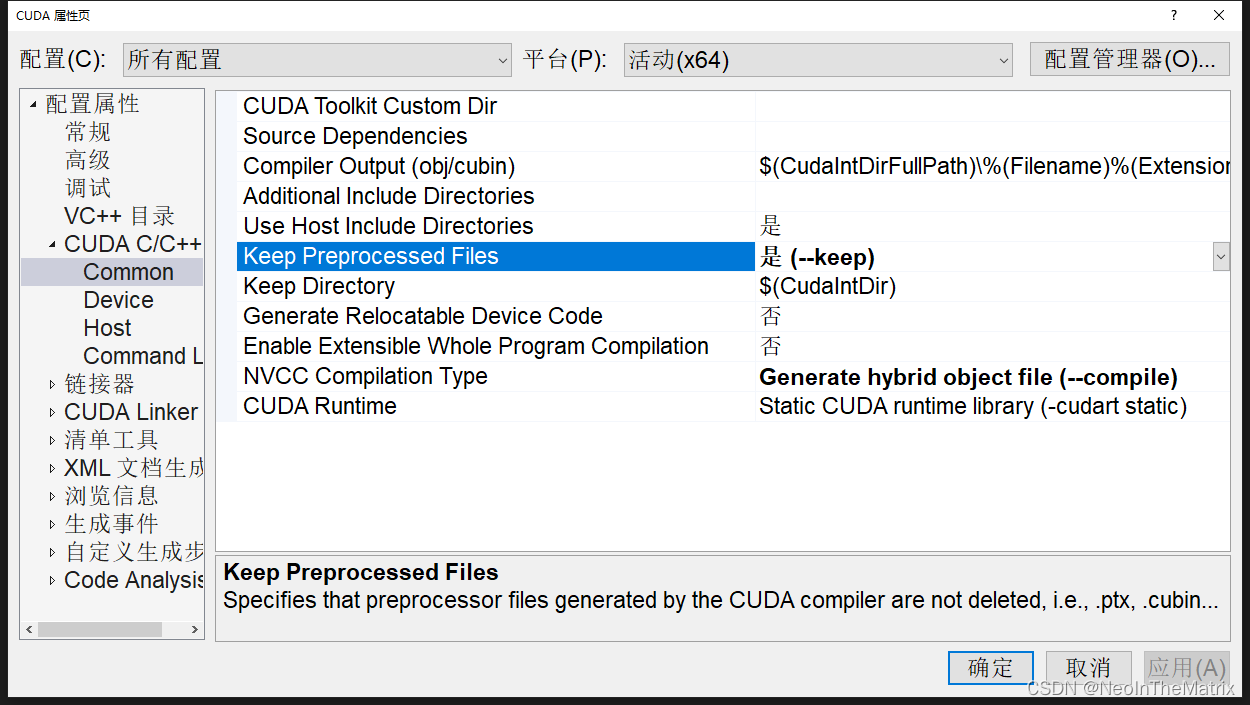 2.查看内核使用的寄存器数量;
2.查看内核使用的寄存器数量;
属性➔CUDA C/C++ ➔Device➔Verbose PTXAS Output➔是 (–ptxas-options=-v)
 # NVIDIA_CUDA_Programming_Guide_1.1_chs
# NVIDIA_CUDA_Programming_Guide_1.1_chs
4.2.2 同步函数
void __syncthreas();
在一个块内同步所有线程。一旦所有线程到达了这点,恢复正常执行。
__syncthreads()通常用于调整在相同块之间的线程通信。当在一个块内的有些线程访问相同的共享或全局内存时,对于有些内存访问潜在存在read-after-write,write-after-read,或者write-after-write的危险。
这些数据危险可以通过同步线程之间的访问得以避免。
__syncthreads()允许放在条件代码中,但只有当整个线程块有相同的条件贯穿时,否则代码执行可能被挂起或导致没想到的副作用。
注解:这是对__syncthreads()函数的解释
Professional CUDA C Programming
Chapter03 CUDA Execution Model
3.3 并行性的表现
注解:和书中使用的测试程序有所不同,偷个懒,后面看时间再同步
3.3.1 用nvprof检测活跃的线程数
一个内核的可实现占用率被定义为:
每周期内活跃线程束的平均数量与一个SM支持的线程束最大数量的比值。
nvprof --metrics achieved_occupany CUDA.exe
注解:–metrics后面需要跟一个指令
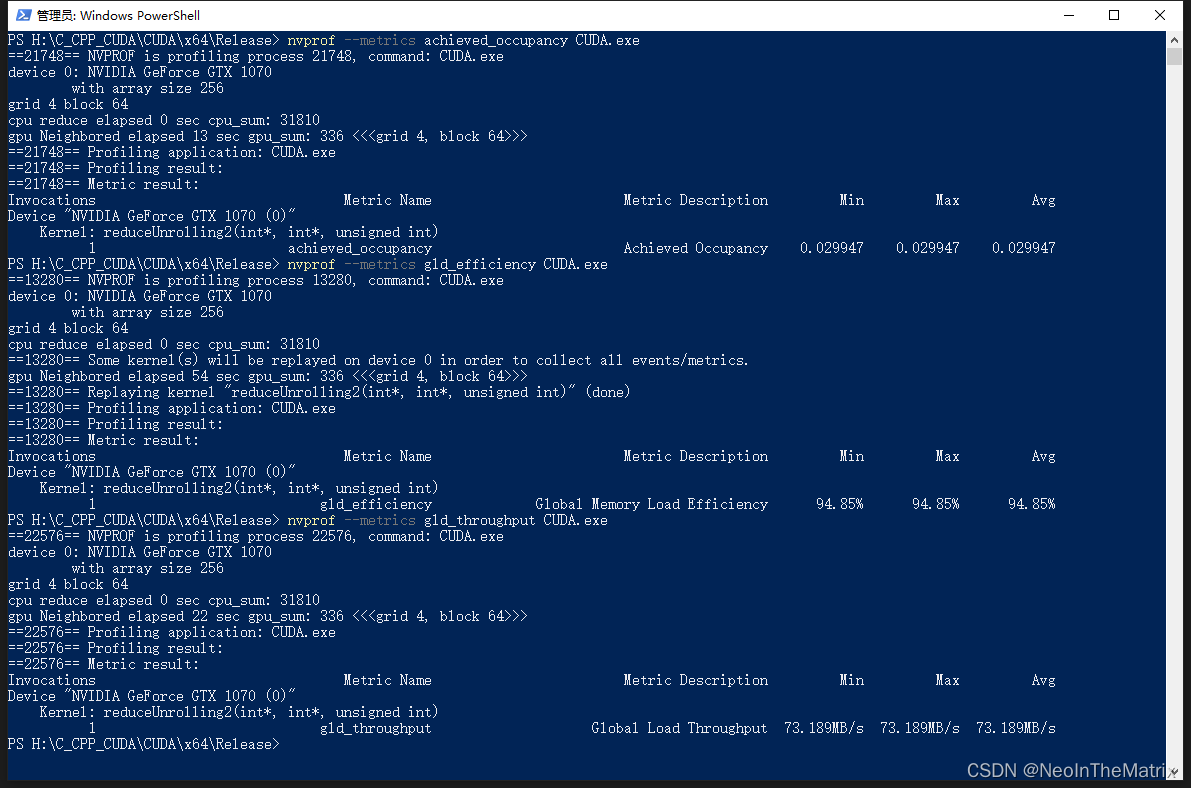
3.3.2 用nvprof检测内存操作
gld_throughput指标检查内核的内存读取效率
gld_efficiency指标检测全局加载效率,即被请求的全局加载吞吐量占所需的全局加载吞吐量的比值。它衡量了应用程序的加载操作利用设备内存带宽的程度。
3.3.3 增大并行性
指标与性能
▨ 在大部分情况下,一个单独的指标不能产生最佳的性能
▨ 与总体性能最直接相关的指标或事件取决于内核代码的本质
▨ 在相关的指标与事件之间寻求一个好的平衡
▨ 从不同角度查看内核以寻求相关指标间的平衡
▨ 网格/块启发式算法为性能调节提供了一个很好的起点
3.4 避免分支分化
3.4.1 并行规约问题
要对一个有N个元素的整数数组求和。
▨ 相邻配对:元素与它们直接相邻的元素配对
▨ 交错配对:根据给定的跨度配对元素
C语言利用递归实现的一个交错配对方法:
int recursiveReduce(int* data, int const size) {
if (size == 1)
return data[0];
int const stride = size / 2;
for (size_t i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
return recursiveReduce(data, stride);
}
在向量中执行满足交换律和结合律的运算,被称为归约问题。
3.4.2 并行归约中的分化
在这个内核里,有两个全局内存数组:一个大数组用来存放整个数组,进行归约;另一个小数组用来存放每个线程块的部分和。每个线程块在数组的一部分上独立地执行操作。
循环中迭代一次执行一个归约步骤。归约是在就地完成的,这意味着在每一步,全局内存的值都被部分和替代。
两个相邻元素间的距离被称为跨度,初始化均为。在每一次归约循环结束后,这个间隔就被乘以2。在第一次循环结束后,idata(全局数据指针)的偶数元素将被部分和替代。在第二次循环结束后,idata的每四个元素将会被新产生的部分和替代。
因为线程间无法同步,所以每个线程块产生的部分和被赋值回了主机,并且在哪儿进行串行求和。
3.4.3 改善并行归约的分化
3.4.3 交错配对的归约
3.5 展开循环
循环展开是一个尝试通过减少分支出现的频率和循环维护指令来优化循环的技术。
在循环展开中,循环主题在代码中药多次被编写,而不是只编写一次循环主题再使用另一个循环来反复执行的。
任何的封闭循环可将它的迭代次数减少或完全删除。
循环体的复制数量被称为循环展开因子,迭代次数就变为了原始循环迭代次数除以循环展开因此。
for (int i=0;i<100;i++)
a[i]=b[i]+c[i];
for (int i=0;i<100;i+=2){
a[i]=b[i]+c[i];
a[i+1]=b[i+1]+c[i+1];
}
3.5.1 展开的归约
3.5.2 展开线程的归约
3.5.3 完全展开的归约
3.5.4 模板函数的归约
#include "CUDA_Header.cuh"
int invokeKernel();
int recursiveReduce(int* data, int const size) {
if (size == 1)
return data[0];
int const stride = size / 2;
for (size_t i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
return recursiveReduce(data, stride);
}
__global__ void reduceNeighbored(int* g_idata, int* g_odata, unsigned int n) {
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
int* idata = g_idata + blockIdx.x * blockDim.x;
if (idx >= n)
return;
for (size_t stride = 1; stride < blockDim.x; stride *= 2)
{
int index = 2 * stride * tid;
if (index < blockDim.x)
idata[index] += idata[index + stride];
//if ((tid % (2 * stride)) == 0)
// idata[tid] += idata[tid + stride];
__syncthreads();
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceInterleaved(int* g_idata, int* g_odata, unsigned int n) {
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
int* idata = g_idata + blockIdx.x * blockDim.x;
if (idx >= n)
return;
int stride = blockDim.x / 2;
for (size_t i = stride; i > 0; i >>= 1)
{
if (tid < i)
idata[tid] += idata[tid + i];
__syncthreads();
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceUnrolling2(int* g_idata, int* g_odata, unsigned int n) {
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 2 + threadIdx.x;
//printf("tid %d , idx %d , blockIdx.x %d, blockDim.x %d , unrolling target %d \n",tid, idx, blockIdx.x, blockDim.x, idx + blockDim.x);
int* idata = g_idata + blockIdx.x * blockDim.x * 2;
if (idx + blockDim.x < n)
g_idata[idx] += g_idata[idx + blockDim.x];
__syncthreads();
//__syncthreads()语句可以保证,线程块中的任一线程在进入下一次迭代之前,在当前迭代里,每个线程的所有部分和都被保存在了全局内存中,进入下一次迭代的所有线程都使用上一步产生的数值。在最后一个循环以后,整个线程块的和被保存进全局内存中
//注解:__syncthreads()的意思应该是所有线程束中的
//write result for this block to global mem
//注解:当迭代结束后,结果保存在了idata的第一个元素里,idata是g_idata偏移后的地址
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceUnrollWarp8(int* g_idata, int* g_odata, unsigned int n) {
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
int* idata = g_idata + blockIdx.x * blockDim.x * 8;
//unrolling 8
if (idx + 7 * blockDim.x < n) {
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int b1 = g_idata[idx + 4 * blockDim.x];
int b2 = g_idata[idx + 5 * blockDim.x];
int b3 = g_idata[idx + 6 * blockDim.x];
int b4 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
for (size_t stride = blockDim.x / 2; stride > 32; stride >>= 1)
{
if (tid < stride)
idata[tid] += idata[tid + stride];
__syncthreads();
}
if (tid < 32) {
volatile int* vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceCompleteUnrollWarp8(int* g_idata, int* g_odata, unsigned int n) {
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
int* idata = g_idata + blockIdx.x * blockDim.x * 8;
if (idx + 7 * blockDim.x < n) {
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int b1 = g_idata[idx + 4 * blockDim.x];
int b2 = g_idata[idx + 5 * blockDim.x];
int b3 = g_idata[idx + 6 * blockDim.x];
int b4 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
if (blockDim.x >= 1024 && tid < 512)
idata[tid] += idata[tid + 512];
__syncthreads();
if (blockDim.x >= 512 && tid < 256)
idata[tid] += idata[tid + 256];
__syncthreads();
if (blockDim.x >= 256 && tid < 128)
idata[tid] += idata[tid + 128];
__syncthreads();
if (blockDim.x >= 128 && tid < 64)
idata[tid] += idata[tid + 64];
__syncthreads();
if (tid < 32) {
volatile int* vsmem = idata;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
template <unsigned int iBlockSize>
__global__ void reduceCompleteUnroll(int* g_idata, int* g_odata, unsigned int n) {
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
int* idata = g_idata + blockIdx.x * blockDim.x*8;
if (idx + 7 * blockDim.x < n) {
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int b1 = g_idata[idx + 4 * blockDim.x];
int b2 = g_idata[idx + 5 * blockDim.x];
int b3 = g_idata[idx + 6 * blockDim.x];
int b4 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
if (blockDim.x >= 1024 && tid < 512)
idata[tid] += idata[tid + 512];
__syncthreads();
if (blockDim.x >= 512 && tid < 256)
idata[tid] += idata[tid + 256];
__syncthreads();
if (blockDim.x >= 256 && tid < 128)
idata[tid] += idata[tid + 128];
__syncthreads();
if (blockDim.x >= 128 && tid < 64)
idata[tid] += idata[tid + 64];
__syncthreads();
if (tid < 32) {
volatile int* vsmem = idata;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
int main() {
invokeKernel();
}
static int invokeKernel() {
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("device %d: %s \n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
bool bResult = false;
long size = 1 << 24;
printf(" with array size %d \n", size);
int blockSize = 1024;
dim3 block(blockSize, 1);
dim3 grid((size + block.x - 1) / block.x, 1);
grid.x /= 8;
printf("grid %d block %d \n", grid.x, block.x);
size_t bytes = size * sizeof(int);
int* h_idata = (int*)malloc(bytes);
int* h_odata = (int*)malloc(grid.x * sizeof(int));
int* tmp = (int*)malloc(bytes);
for (size_t i = 0; i < size; i++)
{
h_idata[i] = (int)(rand() & 0xFF);
}
memcpy(tmp, h_idata, bytes);
clock_t iStart, iElaps;
int gpu_sum = 0;
int* d_idata = NULL;
int* d_odata = NULL;
CHECK(cudaMalloc((void**)&d_idata, bytes));
CHECK(cudaMalloc((void**)&d_odata, grid.x * sizeof(int)));
iStart = cpuSeconds();
int cpu_sum = recursiveReduce(tmp, size);
iElaps = cpuSeconds() - iStart;
printf("cpu reduce elapsed %d sec cpu_sum: %d \n", iElaps, cpu_sum);
//kernel 1: reduceNeighbored
CHECK(cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
iStart = cpuSeconds();
reduceCompleteUnroll<1024> << <grid.x, block >> > (d_idata, d_odata, size);
CHECK(cudaDeviceSynchronize());
iElaps = cpuSeconds() - iStart;
CHECK(cudaMemcpy(h_odata, d_odata, grid.x * sizeof(int), cudaMemcpyDeviceToHost));
gpu_sum = 0;
for (size_t i = 0; i < grid.x; i++)
{
gpu_sum += h_odata[i];
}
printf("gpu Kernel elapsed %d sec gpu_sum: %d <<<grid %d, block %d>>> \n", iElaps, gpu_sum, grid.x, block.x);
free(h_idata);
free(h_odata);
cudaFree(d_idata);
cudaFree(d_odata);
}
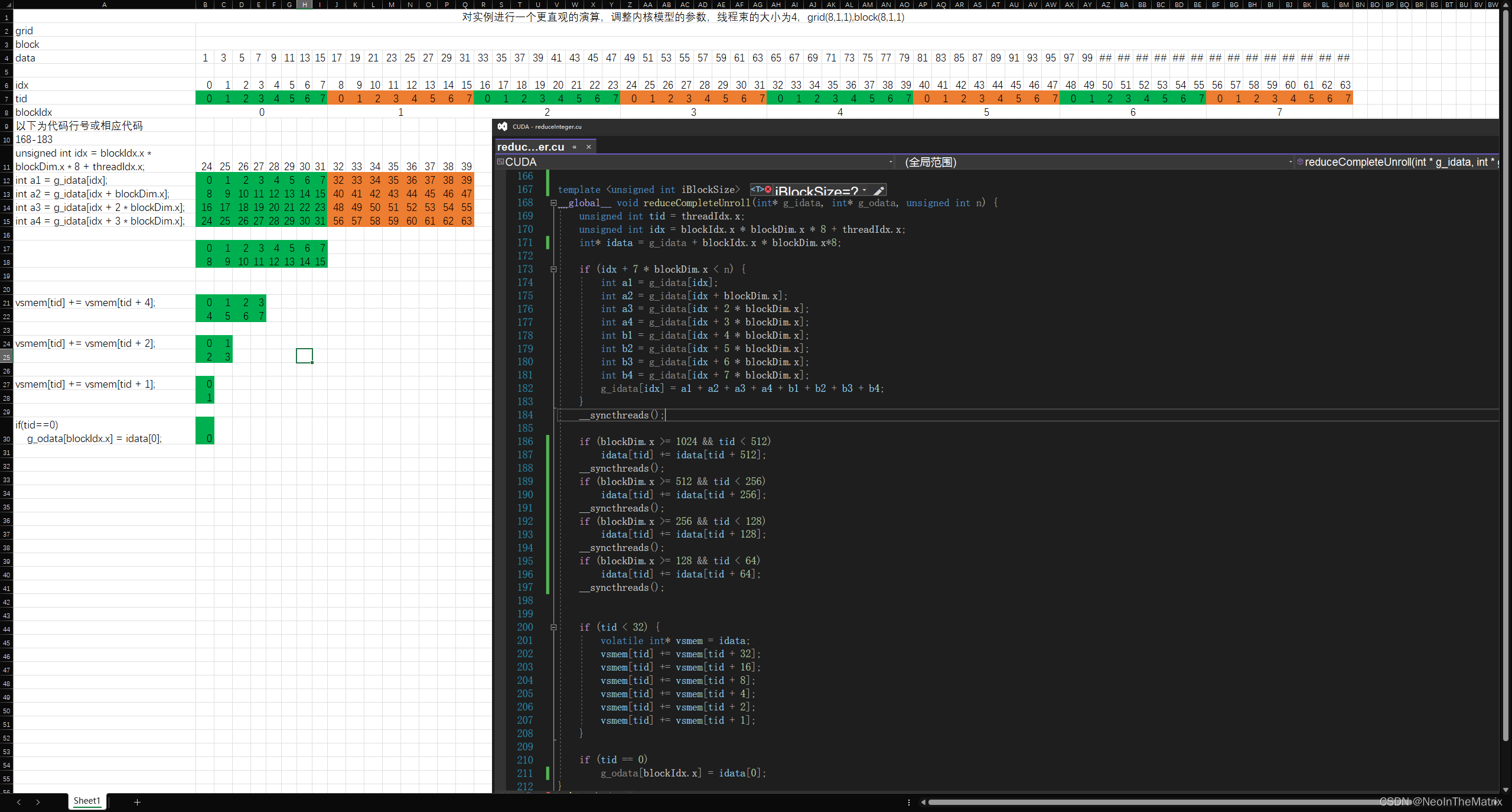
对于以上所讲的内容,使用Excel模拟了下内核的运算过程,应该更加容易理解了
带颜色的部分并非计算结果,而是处理的数据索引
严重性 代码 说明 项目 文件 行 禁止显示状态
错误 kernel launch from __device__ or __global__ functions requires separate compilation mode CUDA H:\C_CPP_CUDA\CUDA\CUDA\nestedHelloWorld.cu 15
属性➔CUDA C/C++ ➔Common➔Generate Relocatable Device Code➔ 是(-rdc=true)
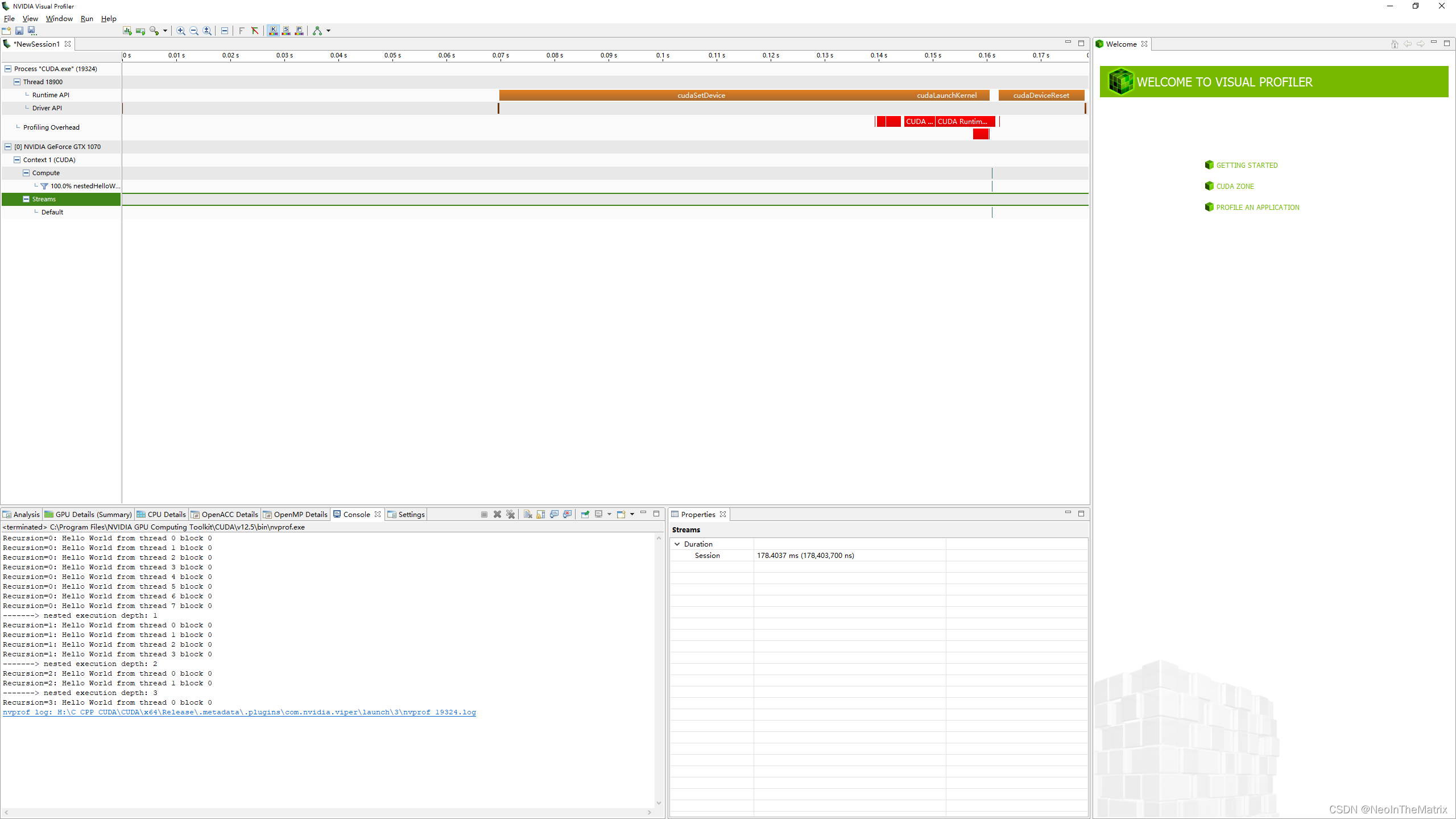
使用nvvp查看代码,NVIDIA Visual Profile在
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\bin
路径下有个nvvp.bat,双击可以打开这个窗口
从这个bat中也可以看到,nvvp.exe的路径是在
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\libnvvp
下


![Siemens-NXUG二次开发-创建倒斜角特征、边倒圆角特征、设置对象颜色、获取面信息[Python UF][20240605]](https://img-blog.csdnimg.cn/direct/c66932754f984fa9be468a8f2fcb403e.png#pic_center)