前情提要:数据价值管理是指通过一系列管理策略和技术手段,帮助企业把庞大的、无序的、低价值的数据资源转变为高价值密度的数据资产的过程,即数据治理和价值变现。上一讲介绍了数据清洗标准设计的基本逻辑和思路。
上一讲介绍了其他的通用标准的基本逻辑和思路。
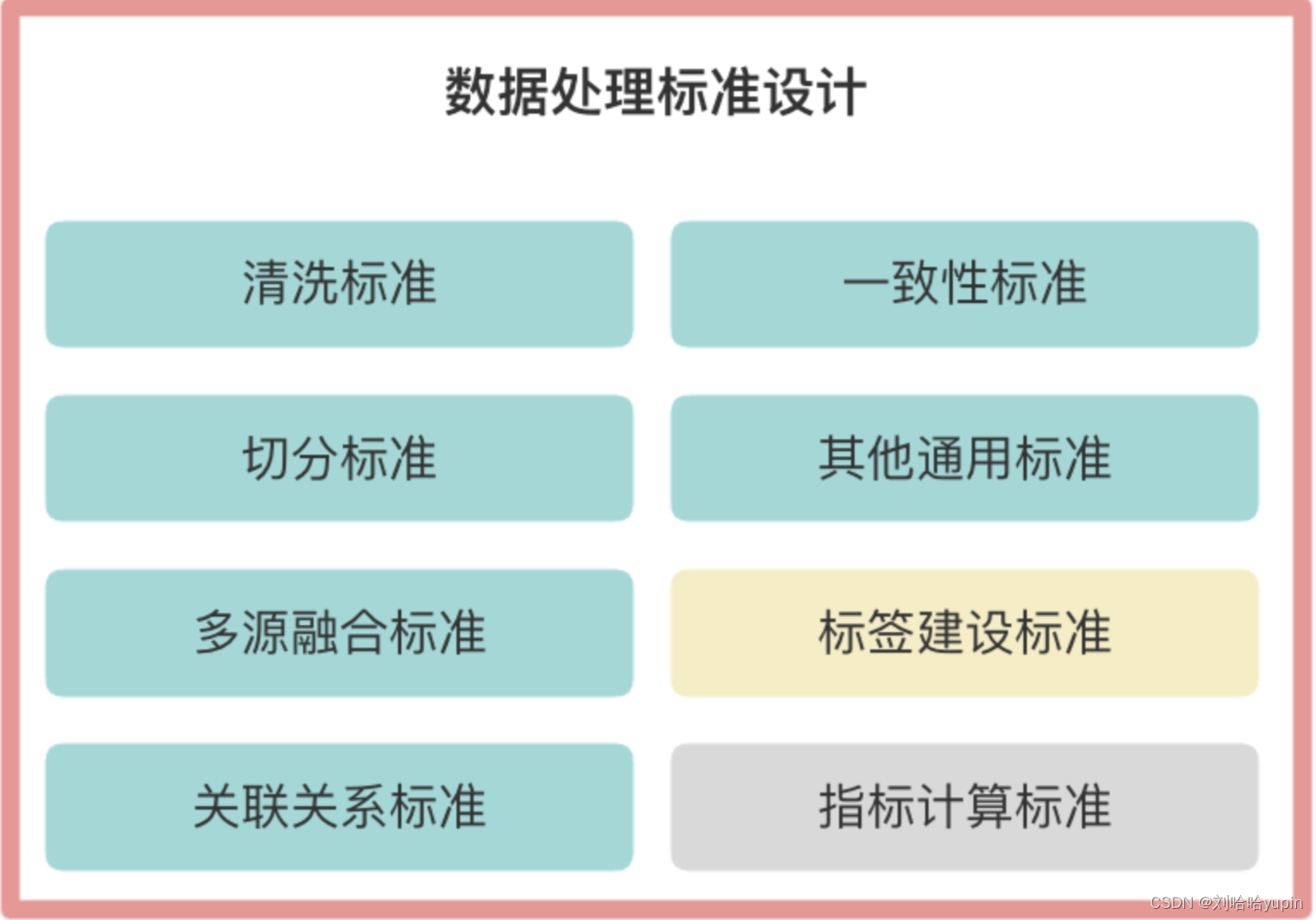 本章重点讲解标签建设标准设计
本章重点讲解标签建设标准设计
前面我们把明细数据的处理已经做了一个详细的讲解,明细数据经过上述的处理之后,数据质量达到了一定的标准,接下来需要基于场景提取特征进行聚合的环节。
定义
标签是实体的属性维度,是服务于业务场景,且能够为业务所用并产生数据价值的数据资源。
标签类型
按照标签产生路径:基于明细数据提取、基于标签的二次组合、基于分析数据的结论;
按照标签产生方式:事实标签、规则标签、模型标签;
按照标签产生路径
基于明细数据提取的标签:是基于清洗好的明细数据,将信息凝练成一个描述性标签的过程;例如公司明细信息中展示了企业的注册资本,按照企业的注册资本提炼企业的注册资本规模标签(一亿以上;5000万-一亿;);
基于标签的二次组合:是指基于其他维度产生的标签结果进行二次组合的标签;例如将中小企业划分为中型、小型、微型三种类型的标签建设,《中小企业划型标准规定》在认定企业规模的过程中需要界定企业的行业分类、营业收入规模、从业人员规模三个维度,那么企业的划型标签就有三个标签维度组合而成。
基于分析数据的结论:只是在基于一系列计算或者分析之后,基于分析的结果将实体进行分类的标签,还是以企业为例,例如要将企业划分为头部企业、腰部企业、踝部企业三个标签,那么基于一系列分析过程,对企业进行评分,最后基于评分结果划分档次,基于分数的档次将企业进行标签分类。
按照标签产生方式
事实标签:事实标签(Fact Tags)通常是指在文本分析、内容管理系统或数据组织中用于描述或分类信息的标签,它们基于客观事实或数据,而不是主观意见或情感。通常的事实标签包含时间标签、空间标签、统计标签(数值标签、金额标签);
规则标签:规则标签(Rule Tags)通常指的是通过一定的规则判断/过滤产生的标签。常见的规则标签包含 判断类标签、上述「中小企业划分标签」也属于规则标签;
模型标签:模型标签(Model Tags)是指通过复杂的统计学模型计算或者机器学习模型分析而产生的结论,基于分析结论进行标签分类的标签。
标签建设步骤
step1:梳理实体维度
step2:构建实体下的标签树(标签结构),制定标签参数;
step3:梳理标签定义(包括业务定义和建立依据);
step4:梳理标签来源表、字段、来源表更新频率(后续可以作为冷热标签存储区分依据);
step5:制定标签生产规则(包含来源表、来源字段、生产逻辑、标签刷新频率);
step6:回归标签使用的场景;
建设步骤拆解
step1梳理实体维度:标签建设过程中的实体梳理,是为了找到标签树的「树干」,所有的属性都是围绕实体展开,因此梳理实体维度至关重要,在关联关系标准中,介绍过5W1H方法论来梳理,这里不在赘述。
step2构建标签树:标签树的构建是打地基的重要环节,标签树构建的合理与否会直接影响后续标签的延展空间和标签使用的便利性。构建标签树的依据可参考的维度有两个:一个是官方规定;第二个是业务需求;
step3梳理标签定义:基于第二步构建的标签树,明确每个标签的业务定义和产生方式;
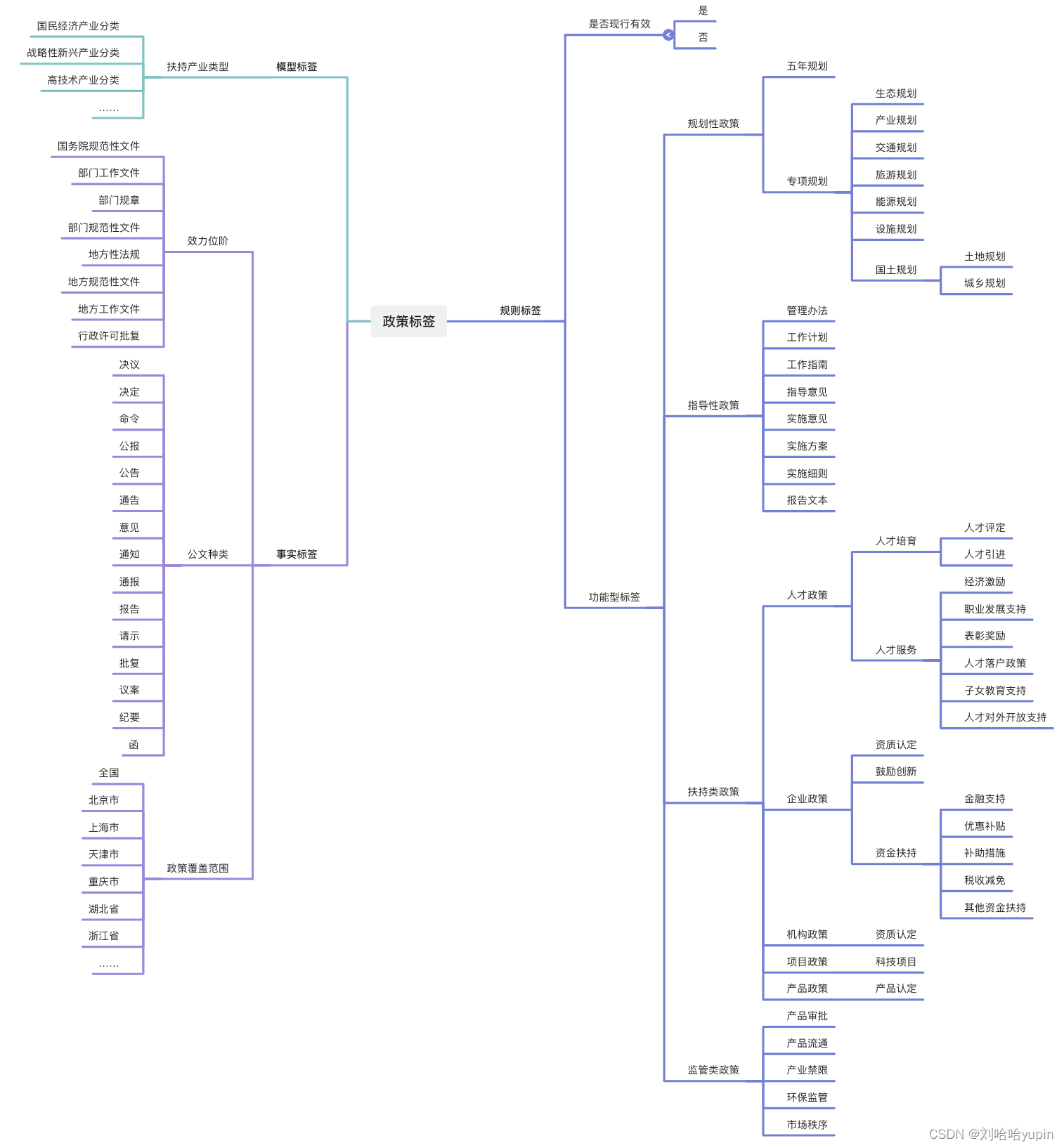
例如「规划性政策」是有关部门对全社会或某一领域(交通、医疗、各产业等)出台的阶段性发展规划;
建立依据:参考官方标准;
step4梳理标签来源表、字段、来源表更新频率(后续可以作为冷热标签存储区分依据)
step5制定标签生产规则(包含来源表、来源字段、生产逻辑、标签刷新频率);
step6:回归标签使用的场景;
最后形成标签清单
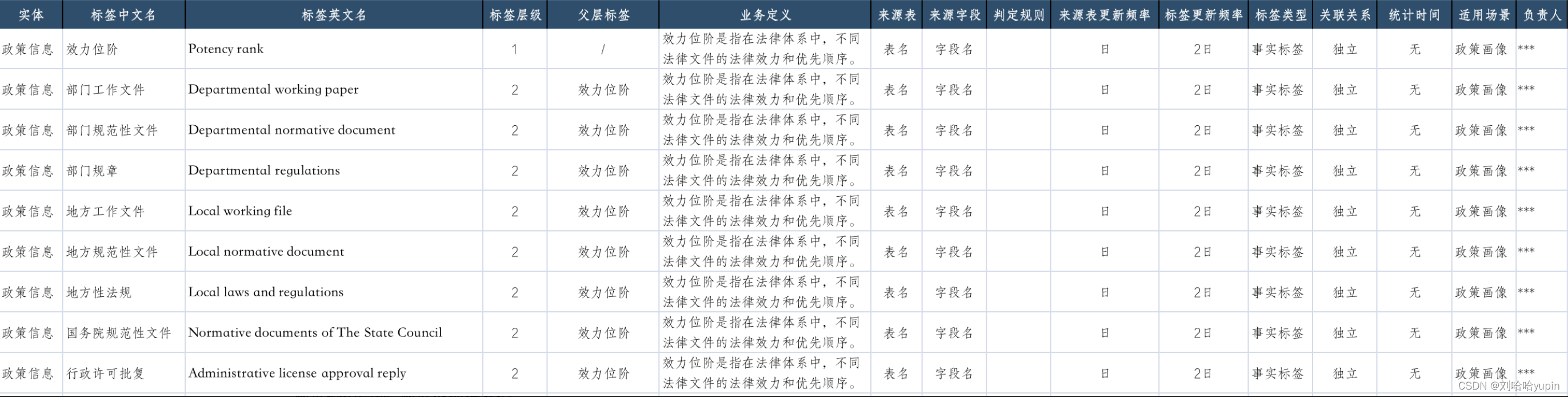
注意点:
标签的分类存储
在标签结果的存储上,尽可能将热数据(经常刷新的标签)和冷数据(不经常刷新的标签)分开存储,避免数据写入的压力;
标签的生命周期管理
标签从构建、开发、验收、上线、下线迭代、重新上线、废弃的过程中,需要重新调整定义和梳理,要保障尽可能不更改标签树的结构;
标签的元数据管理
标签的元数据管理尽可能详尽,确保标签尽可能避免重复建设;