🌈个人主页:人不走空
💖系列专栏:算法专题
⏰诗词歌赋:斯是陋室,惟吾德馨

目录
🌈个人主页:人不走空
💖系列专栏:算法专题
⏰诗词歌赋:斯是陋室,惟吾德馨
1.1 引言
1.2 什么是ChatGPT
1.3 发展历程
1.4 Transformer架构简介
1.5 自注意力机制
查询、键和值的定义
计算过程
多头自注意力机制
重要性和应用
1.6 预训练和微调
预训练
微调
作者其他作品:

1.1 引言
随着人工智能技术的不断发展,自然语言处理(NLP)领域取得了显著的进步。ChatGPT,作为一种先进的对话生成模型,展现了令人瞩目的语言理解和生成能力。本文将深入探讨ChatGPT的原理,从基础概念到技术细节,帮助读者全面了解这一革命性技术。
1.2 什么是ChatGPT
ChatGPT是由OpenAI开发的一种基于GPT(Generative Pre-trained Transformer)架构的对话生成模型。GPT系列模型的核心是Transformer,它是一种专门用于处理序列数据(如自然语言)的深度学习模型。通过自注意力机制,Transformer能够有效捕捉和理解上下文中的复杂关系。ChatGPT通过大量的文本数据进行预训练,学习语言的基本结构和模式,然后通过监督学习和强化学习进行微调,使其能够与用户进行自然且流畅的对话。这一过程包括了对特定任务的数据集进行调整,使模型能够在各种应用场景中表现出色。
1.3 发展历程
GPT模型的发展可以追溯到2018年发布的GPT-1。此后,GPT-2和GPT-3相继推出,模型的参数规模和性能也不断提升。每一代GPT模型都在前一代的基础上进行了改进,特别是在模型的规模、训练数据和算法优化等方面。
GPT模型的发展可以追溯到2018年发布的GPT-1。GPT-1模型拥有1.17亿个参数,通过展示Transformer在语言模型中的潜力,引起了广泛关注。此后,OpenAI相继推出了GPT-2和GPT-3,每一代模型的参数规模和性能都得到了显著提升。GPT-2模型的参数数量大幅增加到15亿个,表现出更强的文本生成能力,尽管由于潜在的滥用风险,最初仅限发布部分模型。2020年推出的GPT-3模型,其参数规模跃升至1750亿个,显著提升了对话质量和文本生成的多样性,成为目前广泛使用的版本之一。GPT-3的巨大成功不仅展示了语言模型的强大能力,还激发了对未来更大规模和更复杂模型的研究兴趣。
- GPT-1:拥有1.17亿个参数,展示了Transformer在语言模型中的潜力。
- GPT-2:大幅增加到15亿个参数,表现出更强的文本生成能力,但由于潜在的滥用风险,最初仅限发布部分模型。
- GPT-3:参数规模跃升至1750亿个,显著提升了对话质量和文本生成的多样性,成为目前广泛使用的版本之一。
1.4 Transformer架构简介
Transformer是由Vaswani等人在2017年提出的一种深度学习模型,专为处理序列数据而设计。与传统的循环神经网络(RNN)和长短时记忆网络(LSTM)不同,Transformer完全依赖于注意力机制(Attention Mechanism),显著提高了并行计算能力和训练效率。这一创新架构使得Transformer在处理长序列数据时表现出色,并在多个NLP任务中超越了传统模型的性能。
Transformer模型由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责将输入序列转换为一系列隐状态向量,这些向量包含了输入序列的语义信息。具体来说,编码器由多个相同的层叠堆组成,每层包括两个子层:多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feedforward Neural Network)。自注意力机制允许模型在处理每个单词时考虑上下文中的所有其他单词,从而捕捉到更丰富的语言信息。前馈神经网络则对每个位置的向量进行非线性变换,进一步提取特征。
解码器的结构与编码器类似,也由多个相同的层叠堆组成,但在每层中多了一个编码器-解码器注意力子层(Encoder-Decoder Attention),它通过注意力机制将编码器输出的信息引入到解码过程中。解码器根据这些隐状态向量生成输出序列。在生成序列的每一步,解码器会预测下一个单词,并将其作为输入用于生成下一个单词,直到完成整个序列的生成。
GPT模型仅使用了Transformer的解码器部分,通过自注意力机制(Self-Attention)和前馈神经网络(Feedforward Neural Network)来处理和生成文本。在GPT中,解码器使用了自回归方式,即每次生成一个单词,使用之前生成的单词作为上下文输入。自注意力机制在这里发挥了关键作用,使模型能够根据上下文生成连贯且符合语法规则的文本。
此外,Transformer架构的一个重要特点是多头注意力机制(Multi-Head Attention)。这种机制通过将注意力计算分成多个头,每个头在不同的子空间中进行独立的注意力计算,然后将结果拼接起来。这种方式允许模型捕捉到不同层次和维度的语义信息,从而提高了模型的表达能力。
1.5 自注意力机制
自注意力机制是Transformer的核心组件,它通过计算输入序列中各个位置之间的相似度来捕捉长期依赖关系。具体来说,自注意力机制通过查询(Query)、键(Key)和值(Value)三个向量来实现。
查询、键和值的定义
- 查询(Query):表示当前单词的特征向量,用于查询相关的信息。
- 键(Key):表示上下文中所有单词的特征向量,用于匹配查询向量。
- 值(Value):表示上下文中所有单词的特征向量,用于生成输出。
在实际操作中,查询、键和值向量都是通过对输入序列中的单词嵌入向量进行线性变换得到的。这些变换由训练期间学习到的权重矩阵实现。
计算过程
自注意力机制的计算过程可以分为以下几个步骤:
-
计算相似度:首先,计算查询向量与所有键向量之间的点积,以衡量它们之间的相似度。点积越大,表示查询向量和键向量之间的关系越紧密。
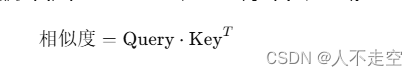 相似度=Query⋅KeyT
相似度=Query⋅KeyT -
归一化权重:将相似度值进行归一化处理,通常使用Softmax函数。这些归一化后的值即为权重,表示每个键对查询的重要程度。
权重=Softmax(相似度)
-
加权求和:用这些权重对所有值向量进行加权平均,从而得到当前查询位置的注意力表示。这一步将各个上下文单词的信息综合起来,生成一个新的表示。
注意力表示=∑(权重×Value)
多头自注意力机制
在Transformer中,自注意力机制不仅仅是单一的,而是通过多头自注意力机制(Multi-Head Attention)来实现。这意味着有多个独立的自注意力机制(即“头”)同时进行计算,每个头在不同的子空间中捕捉不同的上下文信息。具体步骤如下:
- 线性变换:对输入序列进行多个线性变换,生成多个查询、键和值向量。
- 并行计算:每个头独立地计算自注意力,得到多个注意力表示。
- 拼接和变换:将所有头的输出拼接起来,再通过线性变换生成最终的输出表示。
多头自注意力机制通过并行处理和综合不同头的信息,显著提高了模型的表达能力和捕捉复杂依赖关系的能力。
重要性和应用
自注意力机制的引入是Transformer架构的一大创新,解决了传统RNN和LSTM在处理长序列数据时的瓶颈问题。由于自注意力机制能够同时考虑输入序列中的所有位置,它有效地捕捉了长距离依赖关系,使模型在处理长文本、翻译、问答等任务中表现尤为出色。
通过自注意力机制,模型能够更好地理解上下文中的每个单词,并生成更为准确和连贯的输出。这一机制不仅提高了模型的性能,还为后续的改进和发展提供了坚实的基础。随着研究的深入,自注意力机制将在更多的应用场景中展现其独特的优势和潜力。
1.6 预训练和微调
ChatGPT的训练过程分为两个关键阶段:预训练和微调。每个阶段都在模型的性能和应用能力方面起着至关重要的作用。
预训练
预训练阶段是ChatGPT训练过程的基础,在这一阶段,模型在大规模的无监督文本数据上进行训练。预训练的目标是让模型学习语言的基本结构和规律,从而理解和生成自然语言。具体来说,预训练的目标是通过预测给定上下文中的下一个单词来进行学习。这种方法被称为自回归语言建模。
在预训练过程中,模型会处理大量的文本数据,这些数据来自互联网的各种来源,包括书籍、文章、网站内容等。模型通过连续阅读和分析这些文本,学习语言的语法、词汇和常见的句子结构。预训练阶段不需要人工标注的数据,利用的是无监督学习的方式,通过大量数据的训练,模型能够掌握语言的普遍规律。
预训练的步骤如下:
- 数据收集和清洗:收集大量的文本数据并进行清洗,去除噪声和不相关的信息。
- 词嵌入:将文本数据转换为词嵌入向量,这些向量表示文本中的每个单词。
- 自回归建模:训练模型预测每个单词在给定上下文中的概率,通过不断调整模型参数,使其预测更加准确。
通过预训练,模型获得了广泛的语言知识和基本的生成能力,为后续的微调奠定了坚实的基础。
微调
在预训练的基础上,微调阶段通过监督学习和强化学习进一步优化模型,使其在特定任务或领域中表现更为出色。微调的目的是让模型适应具体的应用场景,如对话生成、问答系统、文本摘要等。
微调的步骤如下:
- 任务数据集:收集与特定任务相关的标注数据集,这些数据通常由专家人工标注,包含输入和期望输出对。
- 监督学习:使用任务数据集对预训练模型进行监督学习,通过损失函数和梯度下降优化模型参数,使其在特定任务上的表现更好。
- 强化学习:有时,还会通过强化学习进一步优化模型,利用奖励信号来指导模型生成更符合预期的输出。例如,在对话生成任务中,模型可以通过用户反馈或人工评分来调整生成策略,提升对话的自然性和相关性。
微调过程的目标是使模型在特定领域内达到最佳性能,同时保持其在预训练阶段学到的语言知识。通过微调,模型能够更准确地理解特定任务的需求,并生成更加符合上下文的高质量文本。
作者其他作品:
【Java】Spring循环依赖:原因与解决方法
OpenAI Sora来了,视频生成领域的GPT-4时代来了
[Java·算法·简单] LeetCode 14. 最长公共前缀 详细解读
【Java】深入理解Java中的static关键字
[Java·算法·简单] LeetCode 28. 找出字a符串中第一个匹配项的下标 详细解读
了解 Java 中的 AtomicInteger 类
算法题 — 整数转二进制,查找其中1的数量
深入理解MySQL事务特性:保证数据完整性与一致性
Java企业应用软件系统架构演变史