文章目录
- 前言
- 1. 删除公共字符
- 1.1 题目描述
- 1.2 解题思路
- 1.3 代码实现
- 2. 两个链表的第一个公共结点
- 2.1 题目描述
- 2.2 解题思路
- 2.3 代码实现
- 3. mari和shiny
- 3.1 题目描述
- 3.2 解题思路
- 3.3 代码实现
- 总结
前言
1. 删除公共字符
2. 两个链表的第一个公共结点
3. mari和shiny
1. 删除公共字符
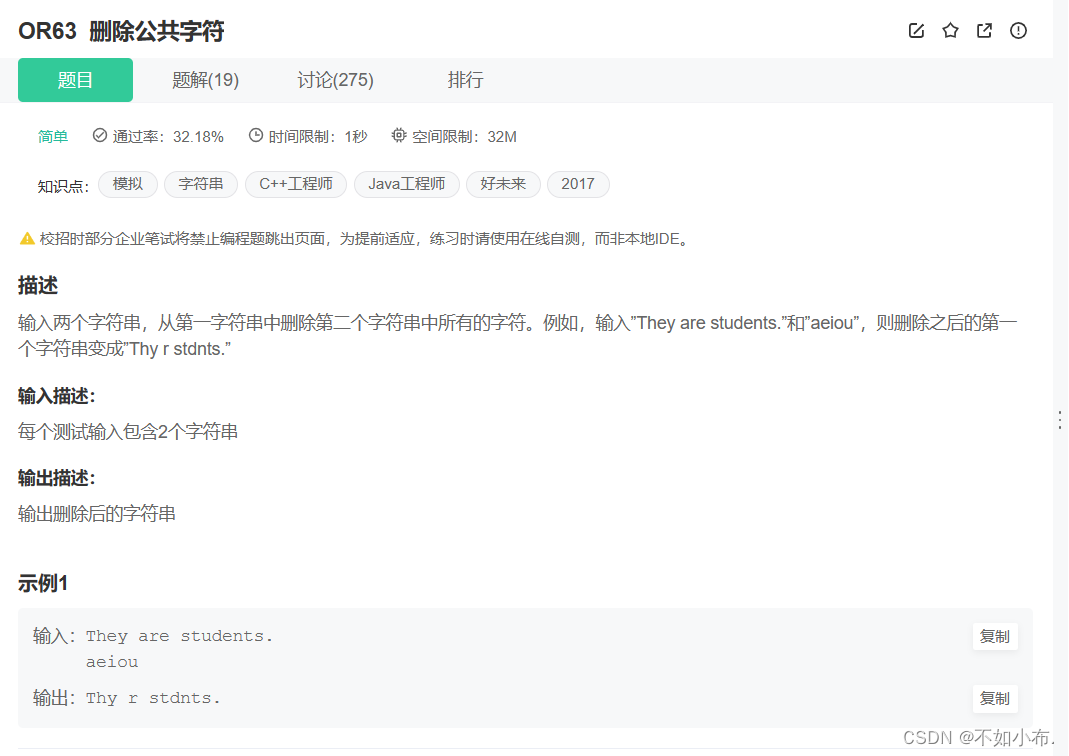
1.1 题目描述
1.2 解题思路
简单的哈希应用,方法一:可以先将字符串2放入一个哈希表中,然后遍历第一个字符串,如果哈希表中存在就删除。(需要注意如果当前字符需要被删除,并且下一个字符也要被删除的情况)
方法二:遍历第一个字符串,如果如果不存在哈希表中,就添加到返回子串中。
1.3 代码实现
#include <iostream>
using namespace std;
#include <unordered_set>
#include <string>
int main() {
int hash[300];
string s, s1;
getline(cin, s);
getline(cin, s1);
for (auto ch : s1)
{
hash[ch] = 1;
}
for (int i = 0; i < s.size(); i++)
{
if (hash[s[i]] == 1)
{
s.erase(i, 1);
i--;
}
}
if (s.size() == 0) cout << "";
else cout << s;
return 0;
}
2. 两个链表的第一个公共结点
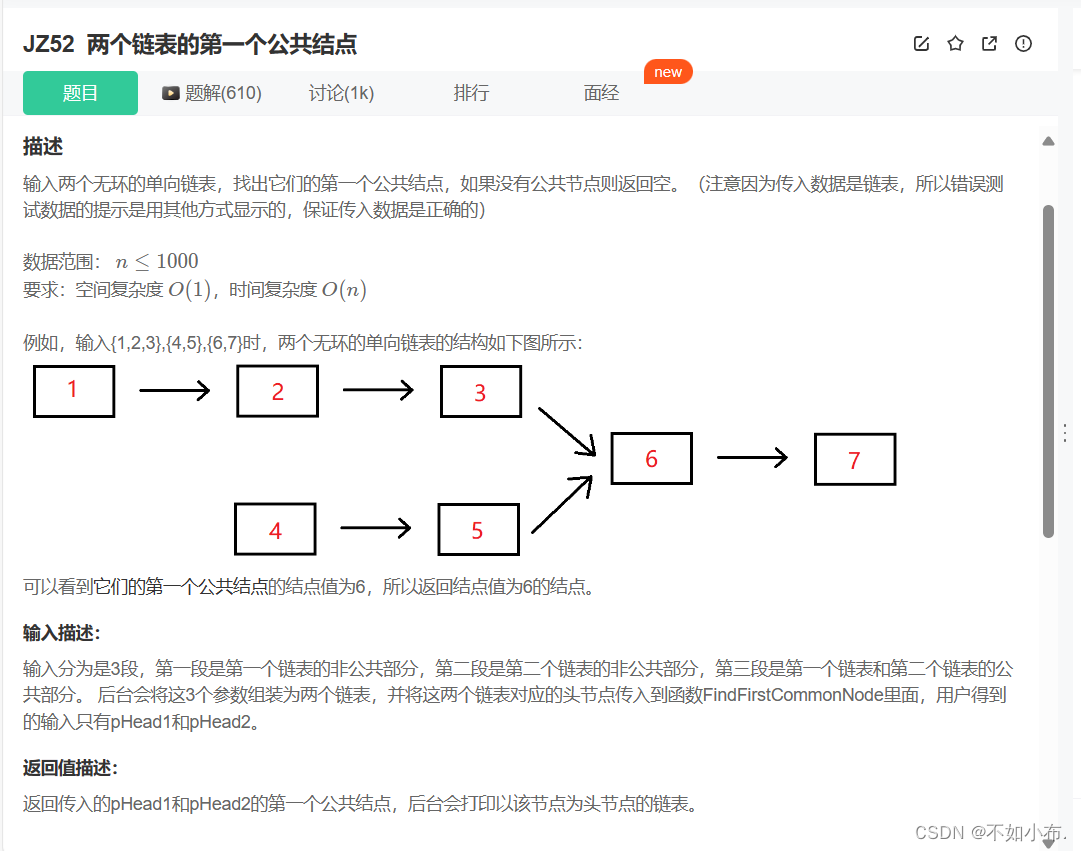
2.1 题目描述
2.2 解题思路
方法一:我们遇到的问题就是它们的路径长度并不一样,所以不知道该如何找到第一个相同结点。我们可以依次统计出两个路径的各自的总长度,然后让路径长的一方先走,一直走到后续的路径与第二个路径的长度相同,那么问题就转化成了两个长度相同的链表找第一个相同的结点,到这里相信大家都会写了。
2.3 代码实现
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2)
{
ListNode* cur1 = pHead1, *cur2 = pHead2;
int count1 = 0, count2 = 0;
while (cur1)
{
count1++;
cur1 = cur1->next;
}
while (cur2)
{
count2++;
cur2 = cur2->next;
}
cur1 = pHead1;
cur2 = pHead2;
if (count1 > count2)
{
int d = count1 - count2;
while (d--) cur1 = cur1->next;
} else
{
int d = count2 - count1;
while (d--) cur2 = cur2->next;
}
while (cur1 && cur2)
{
if (cur1->val == 6 && cur2->val == 6) printf("%p %p", cur1, cur2);
if (cur1 == cur2) return cur1;
cur1 = cur1->next;
cur2 = cur2->next;
}
return nullptr;
}
};
3. mari和shiny
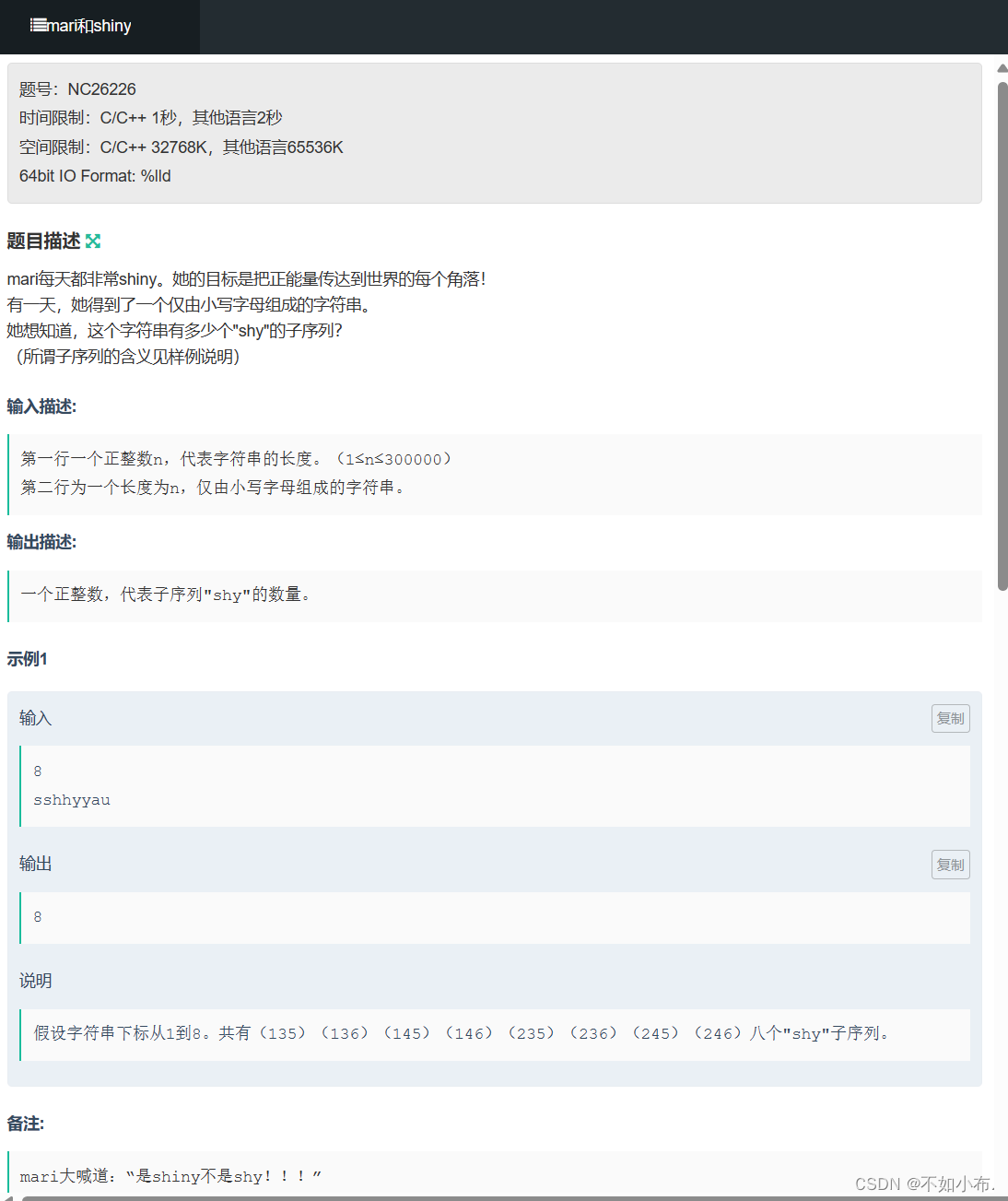
3.1 题目描述
3.2 解题思路
线性dp,我们要找shy,肯定是先找s,找h的话,如果需要合法,它的个数应该是它前面s的个数,如果是y的话,它的个数应该是前面sh也就是h合法的个数,我们只需要三个变量进行统计就可以了。
3.3 代码实现
#include <iostream>
using namespace std;
#include <string>
int main()
{
int n = 0; cin >> n;
string str; cin >> str;
long long s = 0, h = 0, y = 0;
for(auto ch : str)
{
if(ch == 's') s++;
else if(ch == 'h') h += s;
else if(ch == 'y') y += h;
}
cout << y;
return 0;
}
总结
今天的难度也是一般,希望大家能坚持练习。
那么第天七的内容就到此结束了,如果大家发现有什么错误的地方,可以私信或者评论区指出喔。我会继续坚持训练的,希望能与大家共同进步!!!那么本期就到此结束,让我们下期再见!!觉得不错可以点个赞以示鼓励!