目录
SpringCache 缓存
环境配置
1)依赖如下
2)配置文件
3)设置缓存的 value 序列化为 JSON 格式
4)@EnableCaching
实战开发
@Cacheable
@CacheEvict
@CachePut
@Caching
@CacheConfig
SpringCache 的优势和劣势
读操作(优势)
写操作(劣势)
总结
SpringCache 缓存
环境配置
1)依赖如下
父依赖 SpringBoot 3.2.5
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
2)配置文件
spring:
cache:
type: redis
redis:
time-to-live: 3600000
# key-prefix: CACHE_
use-key-prefix: true
cache-null-values: true
- time-to-live: 3600000 -> 缓存过期时间,单位毫秒,此处相当于 1 小时(实际上也就解决了雪崩问题,因为一般设置每一个缓存时的时间线不一样)
- key-prefix: CACHE_ -> 缓存 key 前缀(一般不用这个属性,而是使用分区名作为 key 前缀)
- use-key-prefix: true -> 是否使用缓存分区名作为 key 前缀(分区名在 @Cacheable 中指定),建议为 true
- cache-null-values: true -> 是否缓存空值(解决缓存穿透问题),建议为 true
3)设置缓存的 value 序列化为 JSON 格式
import org.springframework.boot.autoconfigure.cache.CacheProperties
import org.springframework.boot.context.properties.EnableConfigurationProperties
import org.springframework.cache.annotation.EnableCaching
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.data.redis.cache.RedisCacheConfiguration
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer
import org.springframework.data.redis.serializer.RedisSerializationContext
import org.springframework.data.redis.serializer.StringRedisSerializer
@Configuration
@EnableConfigurationProperties(CacheProperties::class) //让配置文件中的配置生效
@EnableCaching // 开启 SpringCache 缓存功能(如果这里不写这个注解,启动类上也一定要有!!!)
class MyCacheConfig {
@Bean
fun redisCacheConfiguration(
cacheProperties: CacheProperties
): RedisCacheConfiguration {
//这里源码怎么写,咱们咱们写(只需要改一下缓存 value 的序列化方式即可)
var config = RedisCacheConfiguration.defaultCacheConfig()
//设置 key value 的序列化方式
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(StringRedisSerializer()))
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(GenericJackson2JsonRedisSerializer()))
val redisProperties = cacheProperties.redis
//将配置文件中的所有配置都生效
redisProperties.timeToLive?.let {
config = config.entryTtl(it)
}
redisProperties.keyPrefix?.let {
config = config.prefixCacheNameWith(it)
}
if (!redisProperties.isCacheNullValues) {
config = config.disableCachingNullValues()
}
if (!redisProperties.isUseKeyPrefix) {
config = config.disableKeyPrefix()
}
return config
}
}
4)@EnableCaching
@EnableCaching 表示开启 SpringCache 缓存功能,加在 启动类 或者 配置类 上都可以.
实战开发
@Cacheable
a)使用说明:
@Cacheable 用来将方法的返回值数据保存到缓存中.
常用属性如下:
- value:表示将当前缓存数据放到哪个 缓存组 中(可以理解为放到哪个文件夹下).
- 例如 @Cacheable(value = ["user"])
- key:指定 key 是什么. 接受一个 SpEL 表达式,例如如下表格中的示例
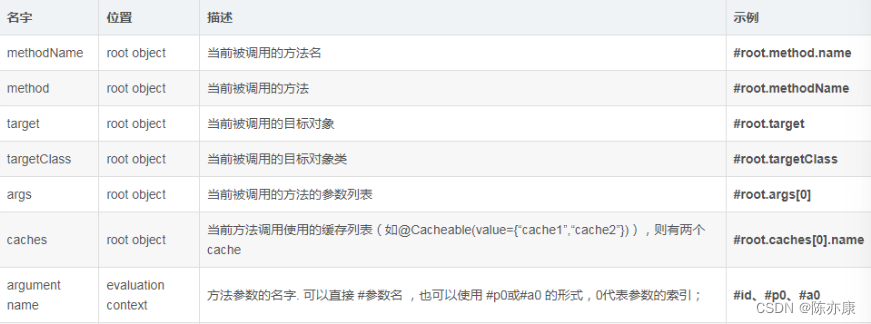
- 例如方法名作为 key:@Cacheable(value = ["user"], key = "#root.method.name")
- 另外,如果不想使用 SpEL 表达式,可以直接在双引号内加上一对单引号,例如 key 为 "userinfo":@Cacheable(value = ["user"], key = "'userinfo'")
- condition:条件判断属性,只有符合条件才可以被缓存.
- 例如方法参数中的 id > 0 返回值才能被缓存 @Cacheable(value = ["user"], key = "#root.method.name", condition = "#id > 0")
- sync:是否为同步执行. 如果设置为 true,会加锁(本地锁),可以用来解决击穿问题.
b)案例如下:
例如通过 SpEL表达式设置 缓存的 key 为 动态的id + "userinfo" ,
@Cacheable(value = ["user"], key = "#id + 'userinfo'")
override fun getUserinfo(id: Long): UserinfoVo {
//业务逻辑...
println("查询数据库...")
return UserinfoVo( // 这里的 UserinfoVo 必须要有无参构造才行,否则缓存将来读取的时候会报错
id = id,
name = "cyk",
age = 21,
)
}
第一查询之后,就可以看到 Redis 上面已经存在该数据. 之后的只要缓存未过期,都会直接查缓存.
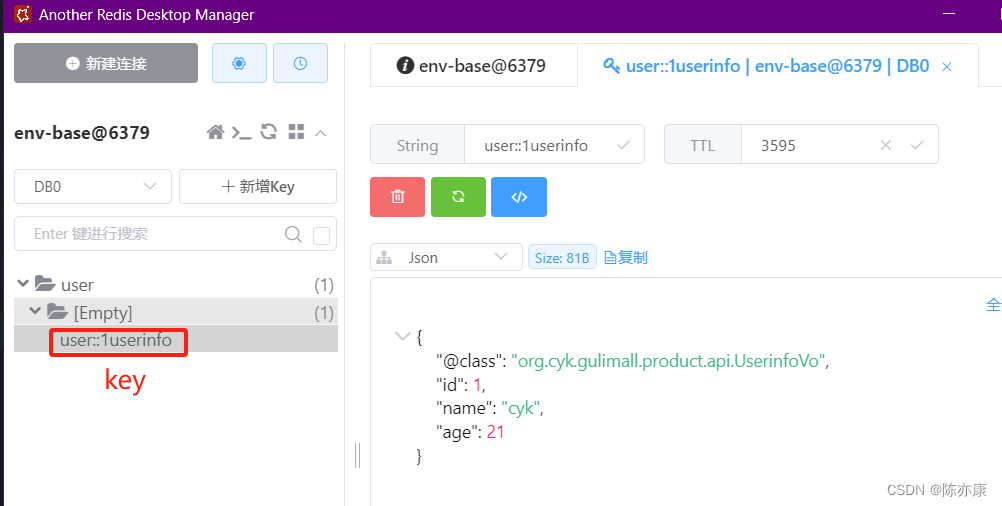
@CacheEvict
a)使用说明
@CacheEvict 用来将数据从缓存中删除.
他常常被用来实现 “失效模式” 来解决缓存一致性问题(数据库中的数据被更新之后,直接删除缓存上的数据即可,下次查询的时候,自动同步到缓存上).
常用属性和 @Cacheable 差不多,这里不再赘述.
b)案例如下
例如实现缓存失效:现在要进行用户信息的修改,那么为了保证缓存和数据库中数据一致,修改完数据库之后的就直接删除对应的缓存数据即可~ 下次查询时,再更新缓存.
这里通过 SpEL 表达式设置要删除的缓存的 key 为 动态的id + "userinfo" ,
/**
* 通过 @CacheEvict 实现缓存失效,下次查询时,再更新缓存
*/
@CacheEvict(value = ["user"], key = "#dto.id + 'userinfo'")
override fun updateUserinfo(dto: UserinfoDto) {
//业务逻辑...
println("修改数据库数据...")
}
另外,还可以通过 属性,删除同一个分区下的所有缓存(慎用)
@CacheEvict(value = ["user"], allEntries = true)@CachePut
a)使用说明
@CachePut 用来更新缓存数据.
与 @Cacheable 不同的是,使用 @CachePut 标注的方法在执行前不会检查缓存中是否存在这个数据,而是每次都会执行这个方法,并将返回值写入到缓存中.
属性上和 @Cacheable 是一样的,这里不再赘述.
b)案例如下
@CachePut(value = ["user"], key = "#dto.id + 'userinfo'")
override fun putUserinfo(dto: UserinfoDto): UserinfoVo {
//业务逻辑
println("更新数据库...")
return with(dto) {
UserinfoVo(
id = id,
name = name,
age = age,
)
}
}
@Caching
@Caching 用来组合以上多个操作.
例如删除同时删除多个缓存数据
@Caching(evict = [
CacheEvict(value = ["user"], key = "#dto.id + 'userinfo'"),
CacheEvict(value = ["user"], key = "#dto.id + 1 + 'userinfo'"),
])
override fun updateUserinfo(dto: UserinfoDto) {
//业务逻辑...
println("修改数据库数据...")
}
@CacheConfig
如果一个类中有很多一样的 cacheName、keyGenerator、cacheManager、cacheResolver,可以直接使用 @CacheConfig 在类上声明,那么这个类中的所有标记了 Cache 相关注解的方法都会共享 @CacheConfig 属性
@Service
//@CacheConfig(cacheNames = ["aaa", "bbb"]) 会创建两个缓存分区, aaa 和 bbb
@CacheConfig(cacheNames = ["user"])
class CacheServiceImpl: CacheService {
@Cacheable(key = "#id + 'userinfo'")
override fun getUserinfo(id: Long): UserinfoVo {
//业务逻辑...
println("查询数据库...")
return UserinfoVo( // 这里的 UserinfoVo 必须要有无参构造才行,否则缓存将来读取的时候会报错
id = id,
name = "cyk",
age = 21,
)
}
/**
* 通过 @CacheEvict 实现缓存失效,下次查询时,再更新缓存
*/
@CacheEvict(key = "#dto.id + 'userinfo'")
override fun updateUserinfo(dto: UserinfoDto) {
//业务逻辑...
println("修改数据库数据...")
}
@CachePut(key = "#dto.id + 'userinfo'")
override fun putUserinfo(dto: UserinfoDto): UserinfoVo {
//业务逻辑
println("更新数据库...")
return with(dto) {
UserinfoVo(
id = id,
name = name,
age = age,
)
}
}
}
SpringCache 的优势和劣势
读操作(优势)
SpringCache 在读操作上的处理的还是很到位的:
- 缓存穿透:配置文件中设置 cache-null-values: true,这样就会将查询为 null 也缓存起来.
- 缓存击穿:配置文件中设置 sync=true,这样就可以对方法进行加锁,解决击穿问题.
- 缓存雪崩:配置文件中设置 time-to-live=3600000 用来设置过期时间(虽然设置的时间是统一的,但是一般情况下情况下触发的时机是不同的,也就相当于是有了随机因子).
写操作(劣势)
- 对于读写并发高,或者写并发高的场景不太好应对.
- 针对于一些特殊的写场景,还是要定制化一下的
总结
对于读多写少,一致性要求不高的数据,完全可以使用 SpringCache 来简化开发(只要缓存的数据有过期时间就可以).
对于一致性要求高的场景,也没必要引入引入缓存,直接对数据库进行读写即可.
特殊数据特殊处理.


![因子区间[牛客周赛44]](https://img-blog.csdnimg.cn/direct/f300350137934aec8749f3360c6921b7.png#pic_center)