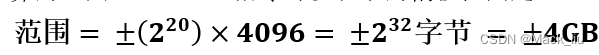前言
KV-Cache是一种加速Transformer推理的策略,几乎所有自回归模型都内置了KV-Cache,理解KV-Cache有助于更深刻地认识Transformer中注意力机制的工作方式。
自回归推理过程知识准备
自回归模型采用shift-right的训练方式,用前文预测下一个字/词,并且前文中的最后一个词经过解码器的表征会映射为其下一个待预测词的概率分布。在训练阶段,句子完整输入给网络,所有位置下的token并行计算。
同理,在预测推理阶段也可以将前文prompt完整输入给训练好的模型,取最后一个位置的表征作为下一个token的概率分布,再通过采样策略确认下一个token,最终将token拼接到前文prompt的末尾准备下一次推理。

GPT自回归工作方式
KV-Cache简要介绍
每步推理都将前文整句输入模型是一种效率低下的方式,原因是存在相同结果的重复推理。令前一次待推理的文本长度为S,下一次为S+1,由于网络中的各项参数已经固定,因此两次推理对于前S个token的计算结果是完全相同的, 包括Embedding映射,每一层、每一个注意力头下的KQV映射,注意力权重,以及后续的FFN层都在重复计算。
根据shift-right的性质,下一个token是由当前最后一个token的网络输出所决定的,那能不能仅输入最后一个token来进行推理?答案是否定的,虽然在结果层仅由最后一个token来决定,但是中间的注意力过程它依赖于前文所提供的Key、Value向量来携带前文信息,因此也不能抛弃前文不管。

next token计算依赖
结合以上结论,S+1位置token的推理依赖于两个要素,首先是当前第S个token在网络中完整forward一遍,其次是除最后一个token以外,之前所有的S-1位置的token在每一层、每个注意力头下的Key,Value信息。又已知S-1的每个token的Key,Value信息都是在重复计算,每次计算的结果是相同的,在之前的推理中都计算过但在结果层丢弃了,因此完全可以将Key,Value信息在内存中存储起来,使得它们可以在之后的每步推理中进行复用,这种策略就是KV-Cache。这种方式避免了重复计算,大幅减少了参数的计算量,提高了推理效率。
KV-Cache推理效率提升统计
本例采用GPT-2作为实验对象,测试开启/关闭KV-Cache对推理效率的影响。在HuggingFace实现的GPT2LMHeadModel模型类中,推理阶段内置了KV-Cache选项,通过use_cache来开启和关闭KV-Cache,当use_cache为true时,模型在推理过程中会初始化past_key_values来存储Key、Value向量,并且每一步推理会对它进行维护,如果use_cache为false则past_key_values不生效。GPT2LMHeadModel的推理阶段参数如下
class GPT2LMHeadModel(GPT2PreTrainedModel):
...
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
...
use_cache: Optional[bool] = None,
...
) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:
给到prompt为“明天降温了”,设置最大推理步长从10到1000不等,采用最简单的贪婪搜索Greedy Search方式,分别将use_cache设置为true和false两种模式,查看CPU和GPU推理下耗时,代码如下
import time
import torch
from transformers import BertTokenizer, GPT2LMHeadModel
tokenizer = BertTokenizer.from_pretrained("./gpt2-chinese-cluecorpussmall")
model = GPT2LMHeadModel.from_pretrained("./gpt2-chinese-cluecorpussmall").to("cuda")
text = "明天降温了"
input_ids = torch.LongTensor([tokenizer.convert_tokens_to_ids(list(text))]).to("cuda")
max_length = list(range(10, 1101, 100))
for i in max_length:
res = model.generate(input_ids=input_ids, max_length=i, do_sample=False, use_cache=True)
其中CPU下开启/关闭KV-Cache的推理耗时差距更加明显,各步长下推理耗时(秒)统计如下表
| 推理步长 | 关闭KV-Cache | 开启KV-Cache |
|---|---|---|
| 10 | 0.17 | 0.18 |
| 110 | 8.71 | 3.11 |
| 310 | 40.93 | 9.31 |
| 510 | 92.43 | 15.84 |
| 710 | 178.22 | 21.82 |
| 910 | 332.96 | 29.22 |
随着步长的增长,关闭KV-Cache的推理总耗时呈现出指数级增长,而开启KV-Cache的耗时线性增长,当步长达到900时,前者的耗时已经是后者的十倍以上,通过可视化能够直观感受到两者的效率差距

CPU下开启和关闭KV-Cache的推理随着步长的耗时
进一步计算平均每个token的推理速度,用总耗时除以推理步长,统计图如下,当关闭KV-Cache时,随着步长从10增长到1000,推理一个token从17ms增长到426ms,推理步长越大,效率越来越低,而当开启KV-Cache时,推理一个token的耗时基本稳定维持在30ms左右,只呈现出小数点后第三位上的略微增长趋势,推理长度几乎没有对推理效率产生负面影响。

KV-Cache推理一个token的耗时对比
根据以上实验初步得到结论,随着推理步长的增长,关闭KV-Cache推理效率会越来越低,而开启KV-Cache推理效率基本恒等不变。
KV-Cache工作流程简述
KV-Cache会在模型连续推理的过程中持续调用和更新past_key_values,特别的,当模型首次推理时,past_key_values为空,需要对past_key_values进行初始化,首次推理需将全部文本一齐输入,将中间过程的所有Key,Value添加到past_key_values中。
从第二次推理开始,仅需要输入当前最后一个token,单独对该token做Q,K,V映射,将past_key_values中前文所有的K,V和该token的K,V进行拼接得到完成的Key、Value向量,最终和该token的Query计算注意力,拼接后的Key、Value也同步更新到past_key_values。

KV-Cache的代码实现流程图
past_key_values存储结构分析
KV-Cache会将截止当前各个token在每一层、每个头的Key向量和Value向量存储在内存中,在HuggingFace的代码实现中使用past_key_values变量进行存储,past_key_values是一个矩阵,其维度为**[n, 2, b, h, s, d]**,类似一个六维的矩阵,每个维度的含义如下
- 第一维 num_layers:在外层是以每一个堆叠的Block为单位,例如堆叠12层,则一共有12组Key、Value信息
- 第二维 2:代表Key和Value这两个信息对象,索引0取到Key向量,索引1取到Value向量
- 第三维 batch_size:代表batch_size,和输入需要推理的文本条数相等,如果输入是一条文本,则b=1
- 第四维 num_heads:代表注意力头的数量,例如每层有12个头,则h=12
- 第五维 seq_len:代表截止到当前token为止的文本长度,在每一个历史token位置上该token在每一层每个头下的Key,Value信息
- 第六维 d:代表Key、Value向量的映射维度,若token总的映射维度为768,注意力头数为12,则d=768/12=64

past_key_values结构示意图
past_key_values的结构如上图所示,随着模型推理步长的增长,past_key_values在每一步也同步更新,上一个past_key_values和下一个past_key_values的差异仅仅产生在seq_len这个维度上,具体的,seq_len维度大小会加1,它是由新推理的那一个token所对应的Key,Value拼接到上一个past_key_values的seq_len维度中所导致的,如果除开这个加1的因素,上一个past_key_values和下一个past_key_values在seq_len这个维度上的向量完全相同。
用公式可以更清晰的表达出past_key_values前后的变化,令第一次推理Seq_len等于5,12层每层12个头,Key、Value维度为64,则有

past_key_values前后公式对比
KV-Cache内存占用、FLOPs下降分析
KV-Cache本质上是用空间换时间,存储的Key、Value矩阵会额外占用内存,假设以float16精度来存储,每个token的存储占用公式如下

KV-Cache占用内存计算
公式代表每一层、每一个头下的向量维度之和,乘以2代表Key、Value两者只和,再乘以2代表float16占用两个字节。以LLaMa-7B为例,模型加载占用显存14GB,向量维度4096,堆叠32层,最大推理步长4096,若推理一个batch为2,长度为4096的句子,KV-Cache占用的存储空间为2×2×32×4096×2×4096=21474836480字节,约等于4GB,随着推理的batch增大,推理长度变长,KV-Cache占用的存储空间可能超过模型本身。

KV-Cache和模型自身参数的显存占用示意图
另一方面KV-Cache极大地降低了FLOPs(浮点计算量),表面上KV-Cache省去了之前每个token的Key、Value的计算量,每个token在所有层下计算Key、Value的FLOPs公式如下

每个token计算Key、Value的FLOPs
其中d平方代表从token Embedding到Key或者Value向量的过程,乘以2是矩阵相乘中逐位相乘再相加导致有两个操作,再乘以2代表Key、Value各一个。还是以LLaMa-7B为例,推理一个batch为2,长度为4096的句子,光计算KV一共节省了2×2×32×4096×4096×4096×2=17592186044416 FLOPs的计算量,额外的,不仅省去了前文所有token的Key、Value的映射,由此导致后续这些token的注意力权重计算,注意力的MLP层,FFN前馈传播层也都不需要再计算了,相当于推理阶段的计算复杂度永远等于只对一个token进行完整的forward推理,因此计算量大幅降低。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】