一、Hints
动态表选择:可以在查询表的时候动态修改表的参数配置
1、读取kafka的数据建表
CREATE TABLE students (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
2、假设此时查数据不是查询最早开始的,而是读取任务启动之后生产的数据,如果将上面的表删除重建便显得多余,此时我们就可以使用Hints解决
-- latest-offset: 读取任务启动之后生产的数据
select * from students /*+ OPTIONS('scan.startup.mode' = 'latest-offset') */; 二、WITH
WITH子句(也称为公用表表达式CTE)允许在SELECT语句中定义一个或多个临时命名的结果集,这些结果集可以在主查询中引用。当有一段sql逻辑重复时,可以定义在with语句中,减少代码量。
with tmp as (
select id,name,age,clazz
from students
)
select * from tmp where age=22
union all
select * from tmp where age>=22;
--UNION ALL
是一个集合操作符,用于合并两个或多个 SELECT 语句的结果集。
注意:
1、与 UNION 不同,UNION ALL 会保留所有行,包括重复的行。
2、在使用 UNION ALL 时,所有 SELECT 语句必须具有相同数量的列,并且这些列的数据类型也必须兼容。
三、SELECT DISTINCT
对于流处理的问题注意:
1、flink会将之前的数据保存在状态中,用于判断是否重复
2、如果表的数据量很大,随着时间的推移状态会越来越大,状态的数据时先保存在TM的内存中,时间长了可能会出问题
-- csv.ignore-parse-errors 解析 CSV 文件时是否忽略解析错误,就是遇到数据不匹配或者脏数据会跳过,而不是报错导致整个作业失败
-- distinct 给数据去重
select distinct * from students /*+ OPTIONS('csv.ignore-parse-errors' ='true','scan.startup.mode' = 'latest-offset') */;
# 创建kafka生产者输入重复数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500101000,符瑞渊,23,男,理科六班
1500101000,符瑞渊,23,男,理科六班
1500101000,符瑞渊,23,男,理科六班结果只有一条数据:

四、窗口函数(TVFs)
1、滚动窗口函数(TUMBLE)
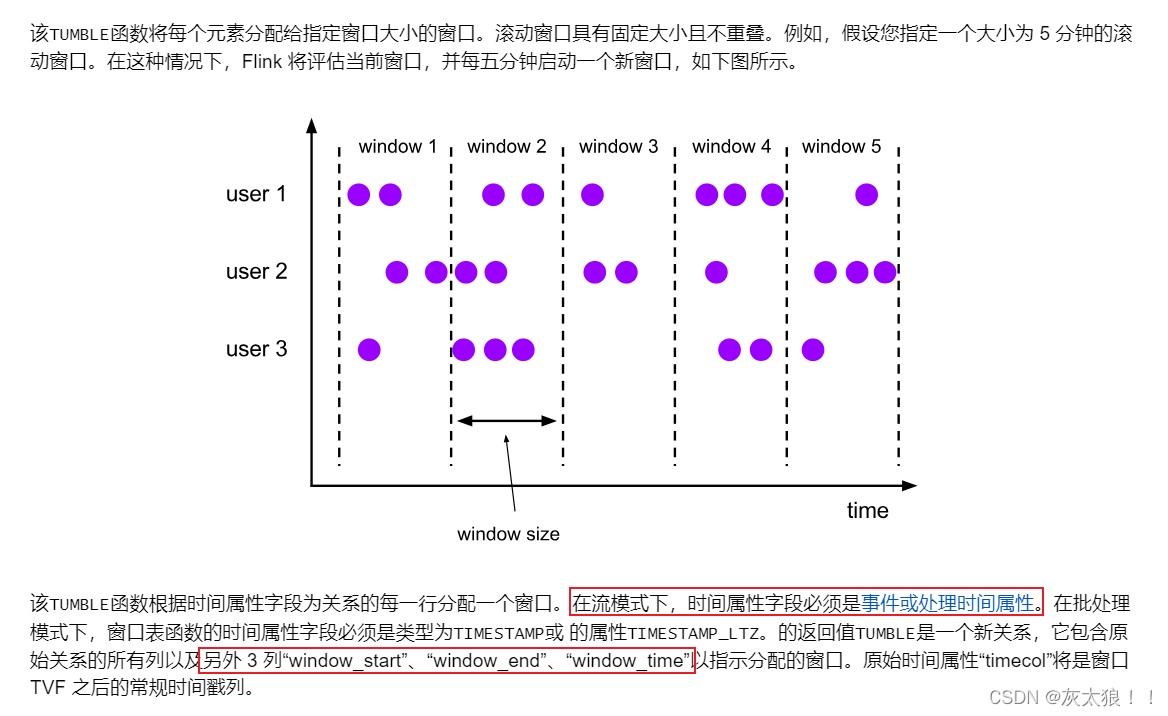
案例:事件时间为例
1、创建bid表
-- TIMESTAMP(3) 3表示小数秒的位数,即毫秒的精度。
CREATE TABLE bid (
item STRING,
price DECIMAL(10, 2),
bidtime TIMESTAMP(3),
WATERMARK FOR bidtime AS bidtime - INTERVAL '5' SECOND ---- 指定时间字段和水位线生成策略
) WITH (
'connector' = 'kafka',
'topic' = 'bid',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2、查询
-- TUMBLE:滚动窗口函数,在原表的基础上增加窗口开始时间,窗口结束时间,窗口时间
select item,price,bidtime,window_start,window_end,window_time from table(
TUMBLE(table bid,descriptor(bidtime),interval '10' seconds)
)
3、在kafka生产测试数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid
C,4.00,2020-04-15 08:05:01
A,2.00,2020-04-15 08:05:03
D,5.00,2020-04-15 08:05:05
B,3.00,2020-04-15 08:05:04
E,1.00,2020-04-15 08:05:11
F,6.00,2020-04-15 08:05:25结果:

窗口聚合计算
实时统计最近10秒所有商品的平均价格
SELECT
window_start,
window_end,
avg(price) as avg_price
FROM
TABLE(
TUMBLE(TABLE bid, DESCRIPTOR(bidtime), INTERVAL '10' SECONDS)
)
group by
window_start,
window_end;结果:

2、滑动窗口函数(HOP)

案例:以处理时间为例
1、建表
CREATE TABLE bid_proctime (
item STRING,
price DECIMAL(10, 2),
proctime AS PROCTIME() --proctime列是一个处理时间属性,系统会自动为每一行分配当前处理时间。
) WITH (
'connector' = 'kafka',
'topic' = 'bid_proctime',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2、查询 每隔五秒查询最近十秒的数据
-- HOP: 滑动窗口函数
SELECT item,price,proctime,window_start,window_end,window_time FROM TABLE(
HOP(TABLE bid_proctime, DESCRIPTOR(proctime), INTERVAL '5' SECOND, INTERVAL '10' SECOND)
);
3、kafka生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid_proctime
C,4.00
A,2.00
D,5.00
B,3.00
E,1.00
F,6.00
K,6.00
4、窗口聚合查询
SELECT
window_start,
window_end,
avg(price) as avg_price
FROM
TABLE(
HOP(TABLE bid_proctime, DESCRIPTOR(proctime), INTERVAL '5' SECOND, INTERVAL '10' SECOND)
)
group by
window_start,
window_end;3、累计窗口(CUMULATE )

CREATE TABLE bid_cumulate (
item STRING,
price DECIMAL(10, 2),
bidtime TIMESTAMP(3),
WATERMARK FOR bidtime AS bidtime - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'bid_cumulate',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2、每隔两分钟统计之前10分钟的数据
SELECT * FROM TABLE(
CUMULATE(TABLE bid_cumulate, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES)
);
3、生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid_cumulate
C,4.00,2020-04-15 08:05:01
A,2.00,2020-04-15 08:07:01
D,5.00,2020-04-15 08:09:01
F,6.00,2020-04-15 08:27:01结果:

4、会话窗口(SESSION)
隔一段时间没有数据开始sql逻辑
1、建表
CREATE TABLE bid_proctime_session (
item STRING,
price DECIMAL(10, 2),
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'bid_proctime_session',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2、实时统计每个商品的总的金额,隔5秒没有数据开始统计
select
item,
SESSION_START(proctime,INTERVAL '5' SECOND) as session_start,
SESSION_END(proctime,INTERVAL '5' SECOND) as session_end,
sum(price) as sum_price
from
bid_proctime_session
group by
item,
SESSION(proctime,INTERVAL '5' SECOND);
3、生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid_proctime_session
C,4.00
C,2.00
C,5.00
C,3.00
C,1.00
C,6.00结果:

五、OVER聚合
OVER聚合针对一系列有序行计算每个输入行的聚合值。与GROUP BY聚合相反,OVER聚合不会将结果行数减少到每组一行。相反,OVER聚合会为每个输入行生成一个聚合值。类似于hive中的聚合开窗函数。
1、sum、max、min、avg、count
1、建表
CREATE TABLE `order` (
order_id STRING,
amount DECIMAL(10, 2),
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
2、查询
-- 实时统计每个商品的累计总金额,将总金额放在每一条数据的后面
-- 流处理的问题
-- a、sum over必须按照时间升序排序,因为数据时一条一条过来的,只能做累加求和,不能做全局求和
-- b、只能按照时间升序排序,如果按照其他的字段排序,每来一条数据都需要重新排序,计算代价太大,影响性能
select
order_id,
amo unt,
product,
order_time,
sum(amount) over(
partition by product
order by order_time
)
from
`order`
;
-- 2.1、实时统计每个商品的累计总金额,将总金额放在每一条数据的后面,只统计最近10分钟的数据
select
order_id,
amount,
product,
order_time,
sum(amount) over(
partition by product
order by order_time
-- 统计10分钟前到当前行的数据
RANGE BETWEEN INTERVAL '10' MINUTES PRECEDING AND CURRENT ROW
)
from
`order`
;
-- 2.2、实时统计每个商品的累计总金额,将总金额放在每一条数据的后面,计算最近5条数据
select
order_id,
amount,
product,
order_time,
sum(amount) over(
partition by product
order by order_time
-- 从前4条数据到当前行,为5条数据
ROWS BETWEEN 4 PRECEDING AND CURRENT ROW
)
from
`order`
;
-- 2.3、实时统计每个商品的最大金额,将总金额放在每一条数据的后面,计算最近5条数据
select
order_id,
amount,
product,
order_time,
max(amount) over(
partition by product
order by order_time
-- 从前4条数据到当前行
ROWS BETWEEN 4 PRECEDING AND CURRENT ROW
)
from
`order`
;
3、生产数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic order
1,4.00,001,2020-04-15 08:05:01
2,2.00,001,2020-04-15 08:07:01
3,5.00,001,2020-04-15 08:09:01
4,3.00,001,2020-04-15 08:11:01
5,1.00,001,2020-04-15 08:13:01
6,6.00,001,2020-04-15 08:17:01
6,6.00,001,2020-04-15 08:20:01
6,6.00,001,2020-04-15 08:21:012.0 结果:

2.1 结果:

2.2 结果:

2.3 结果:

2、row_number
用于为窗口中的每一行分配一个唯一的序号。这个序号是根据指定的排序顺序生成的
-- 查询1:如果只是增加排名,只能按照时间字段升序排序
select
order_id,
amount,
product,
order_time,
row_number() over(partition by product order by order_time) as r
from
`order`
;
查询2:
-- 实时统计每个商品金额最高的前两个商品 -- TOPN
-- 去完topn之后需要计算的排名的数据较少了(where r <= 2),计算代价降低了,因此可以partition by product,否则只能按照时间字段升序排序
select *
from (
select
order_id,
amount,
product,
order_time,
row_number() over(partition by product order by amount desc) as r
from
`order`
)
where r <= 2查询1结果:

查询2结果:

六、ORDER BY
-- 子流处理模式中,order by 需要按照时间字段升序排序
select * from
`order`
order by
order_time,amount
-- 加上limit ,计算代价就不高了,就可以按照普通字段进行排序了
select * from
`order`
order by
amount
limit 2;七、模式检测(CEP)
搜索一组事件模式(event pattern)是一种常见的用例,尤其是在数据流情景中。Flink 提供复杂事件处理(CEP)库,该库允许在事件流中进行模式检测。
1、MATCH_RECOGNIZE 子句启用以下任务:
- 使用
PARTITION BY和ORDER BY子句对数据进行逻辑分区和排序。 - 使用
PATTERN子句定义要查找的行模式。这些模式使用类似于正则表达式的语法。 - 在
DEFINE子句中指定行模式变量的逻辑组合。 - measures 是指在
MEASURES子句中定义的表达式,这些表达式可用于 SQL 查询中的其他部分。
SQL 语义 #
2、每个 MATCH_RECOGNIZE 查询都包含以下子句:
- PARTITION BY - 定义表的逻辑分区;类似于
GROUP BY操作。 - ORDER BY - 指定传入行的排序方式;这是必须的,因为模式依赖于顺序。
- MEASURES - 定义子句的输出;类似于
SELECT子句。 - ONE ROW PER MATCH - 输出方式,定义每个匹配项应产生多少行。
- AFTER MATCH SKIP - 指定下一个匹配的开始位置;这也是控制单个事件可以属于多少个不同匹配项的方法。
- PATTERN - 允许使用类似于 正则表达式 的语法构造搜索的模式。
- DEFINE - 本部分定义了模式变量必须满足的条件。
3、允许使用类似于 正则表达式 的语法构造搜索的模式(具体使用):

4、案例1
实现报警程序,对于一个账户,如果出现满足一定条件的的交易,就输出一个报警信息
CREATE TABLE tran (
id STRING,
amount DECIMAL(10, 2),
proctime as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'tran',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
-- MATCH_RECOGNIZE(模式检测)
-- 在数据流上对数据进行匹配,当数满足我们定义的规则后,返回匹配的结果
-- 1、实现第一版报警程序,对于一个账户,如果出现小于 $1 美元的交易后紧跟着一个大于 $500 的交易,就输出一个报警信息。
SELECT *
FROM tran
MATCH_RECOGNIZE (
PARTITION BY id -- 分组字段
ORDER BY proctime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.amount as min_amount,
A.proctime as min_proctime,
B.amount as max_amount,
B.proctime as max_proctime
PATTERN (A B) -- 定义规则
DEFINE -- 定义条件
A as amount < 1,
B as amount > 500
) AS T
-- 2、实现第二版报警程序,对于一个账户,如果出现小于 $1 美元的交易后紧跟着一个大于 $500 的交易,就输出一个报警信,两次事件需要在10秒内出现
SELECT *
FROM tran
MATCH_RECOGNIZE (
PARTITION BY id -- 分组字段
ORDER BY proctime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.amount as min_amount,
A.proctime as min_proctime,
B.amount as max_amount,
B.proctime as max_proctime
PATTERN (A B) WITHIN INTERVAL '5' SECOND -- 定义规则,增加事件约束,需要在5秒内匹配出结果
DEFINE -- 定义条件
A as amount < 1,
B as amount > 500
) AS T;
-- 3、实现第三版(最终版)报警程序,对于一个账户,如果连续出现三次出现小于 $1 美元的交易后紧跟着一个大于 $500 的交易,就输出一个报警信息
SELECT *
FROM tran
MATCH_RECOGNIZE (
PARTITION BY id -- 分组字段
ORDER BY proctime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.amount as a_amount, -- 获取最后一条
min(A.amount) as min_a_amount, -- 取最小的
max(A.amount) as max_a_amount, -- 取最大的
sum(A.amount) as sum_a_amount, -- 求和
avg(A.amount) as avg_a_amount, -- 平均
FIRST(A.amount) AS first_a_amount, -- 取前面第一条
LAST(A.amount) AS LAST_a_amount, -- 取后面第一条
B.amount as b_amount
PATTERN (A{3} B) -- 定义规则
DEFINE -- 定义条件
A as amount < 1,
B as amount > 500
) AS T;
第一第二版数据来源
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic tran
1,4.00
1,2.00
1,5.00
1,0.90
1,600.00
1,4.00
1,2.00
1,0.10
1,200.00
1,700.00
最终版数据来源
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic tran
1,0.90
1,0.10
1,0.20
1,600.005、案例2
找出一个单一股票价格不断下降的时期
CREATE TABLE ticker (
symbol STRING,
rowtime TIMESTAMP(3), -- 时间字段
price DECIMAL(10, 2) ,
tax DECIMAL(10, 2),
-- 指定时间字段和水位线生成策略
WATERMARK FOR rowtime AS rowtime
) WITH (
'connector' = 'kafka',
'topic' = 'ticker',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
-- 找出一个单一股票价格不断下降的时期
select * from
ticker
MATCH_RECOGNIZE (
PARTITION BY symbol -- 分组字段
ORDER BY rowtime -- 排序字段,只能按照时间字段升序排序
MEASURES -- 相当于select
A.price as a_price,
FIRST(B.price) as FIRST_b_price,
LAST(B.price) as last_b_price,
C.price as c_price
AFTER MATCH SKIP PAST LAST ROW -- 从当前匹配成功止呕的下一行开始匹配
PATTERN (A B+ C) -- 定义规则
DEFINE -- 定义条件
-- 如果时第一个B,就和A比较,如果时后面的B,就和前一个B比较
B as (LAST(B.price,1)is null and B.price < A.price) or B.price < LAST(B.price,1),
C as C.price > LAST(B.price)
) AS T;
数据来源
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic ticker
ACME,2024-06-04 10:00:00,12,1
ACME,2024-06-04 10:00:01,17,2
ACME,2024-06-04 10:00:02,19,1
ACME,2024-06-04 10:00:03,21,3
ACME,2024-06-04 10:00:04,25,2
ACME,2024-06-04 10:00:05,18,1
ACME,2024-06-04 10:00:06,15,1
ACME,2024-06-04 10:00:07,14,2
ACME,2024-06-04 10:00:08,24,2
ACME,2024-06-04 10:00:09,25,2
ACME,2024-06-04 10:00:10,19,1